[AI Agent] AI Engineering Review (12주차)
AI Agent 과정을 정리합니다. LLM 기초와 프롬프트 엔지니어링에서 시작해 RAG, Evaluation, Agent 설계, Observability, Cost, Security, Fine-tuning까지 운영 가능한 AI 시스템을 만들기 위해 필요한 흐름을 되짚습니다.
![[AI Agent] AI Engineering Review (12주차)](https://images.unsplash.com/photo-1531262951893-05a0ffb31b27?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDN8fGZpbmFsfGVufDB8fHx8MTc4MTkxNDI0MXww&ixlib=rb-4.1.0&q=80&w=1200)
1. 개요
이번 AI Agent 과정은 단순히 LLM API를 호출해보거나 챗봇을 하나 만들어보는 데 목적이 있지 않았습니다. 더 중요한 목표는 LLM을 실제 서비스와 운영 환경에 넣으려면 무엇을 함께 설계해야 하는지 익히는 것이었습니다.
이 흐름은 다음 순서로 쌓아갔습니다.
- LLM의 기본 동작 방식 이해
- 프롬프트 엔지니어링으로 모델 출력 제어
- RAG로 Agent가 참고할 외부 지식 연결
- Evaluation으로 품질을 판단할 기준 설정
- Agent를 설계하고 구현하면서 LLM이 tool을 선택하고 실행하는 구조
- Observability로 Agent의 실행 과정 추적
- Cost 관점에서 Agent 운영 비용을 최적화 하는 방법
- AI 특히 LLM 서비스를 신뢰성있고 안전하게 구성하는 방법
- Fine-tuning으로 반복되는 판단과 출력 형식을 데이터로 학습시키는 방법
이 과정에서 가져가야 할 가장 중요한 관점은 다음과 같습니다.
AI Agent는 모델 하나로 완성되지 않습니다.
프롬프트, 검색, 평가, tool, trace, 비용, 보안, 학습 데이터...
운영 가능한 AI 시스템
2.전체 내용 정리
1. LLM 구성 요소
가장 먼저 알아봤던 내용은 AI 모델. 특히 LLM 모델의 출력 특성을 이해하고, 출력 형식과 프롬프트 구조를 확인했습니다.
LLM이란 무엇을 의미하는지부터, 토큰이라는 모델의 어휘(단어), 모델 선택 기준, 구조화된 출력을 통한 로직 통합, system/user message 분리, temperature 파라미터나 autoregressive한 성격을 이해하고 정리했습니다.
참고자료



2. 프롬프트 엔지니어링
내용을 기반으로 프롬프트 엔지니어링을 정리했습니다.
프롬프트 엔지니어링은 모델에게 말을 예쁘게 거는 기술이 아닙니다.
모델이 어떤 기준으로 판단하고, 어떤 형식으로 답해야 하는지 결정하는 첫 번째 제어 수단입니다. Zero-shot, Few-shot, Chain-of-Thought, Self-Consistency를 통해 같은 모델이라도 프롬프트 구성에 따라 성능이 달라진다는 점을 확인했습니다.
- 예시를 많이 주는 것
- 출력을 다시 입력으로 넣어 논리적인 추론을 하는 것
특히 의료급여 본인부담률처럼 조건이 여러 개 겹치는 문제에서는 프롬프트 구조, 예시 품질, 출력 형식이 정답률에 영향을 준다는 것을 확인하셨을겁니다.
다만 여기서 같이 짚어야 할 한계도 있습니다. 프롬프트만으로 모든 문제를 해결할 수는 없습니다. 문서가 길어지고, 최신 정보가 필요하고, 출처가 중요해지면 다음 단계인 RAG로 넘어가야 합니다.
참고자료
최신 모델은 Thinking, 프레임워크 구성, 모델의 발전으로 통합되었습니다.
3. RAG(Retrieval-Augmented Generation)
LLM이 한 번에 받을 수 있는 양(Context)의 한계와 최신 지식 부재. Closed AI 모델의 특성으로 외부의 저장소를 구현해 모델이 참고할 수 있는 지식을 저장했습니다.
이를 구성하기 위해 검색을 수행하는 방법(Keyword, Vector Search) 방식을 알아보았고 그걸 벡터로 변환하여 검색 품질을 확인하는 것까지 구성했습니다.
참고자료




PDF 표를 어떻게 잘라야하는지 불필요한 데이터는 제거하는 작업이 필요했죠. 따라서 RAG는 단순히 문서 검색을 붙인 챗봇이 아닙니다.
핵심은 LLM에 들어가는 context를 제어하는 방법론이었습니다.
LLM / AI Agent 서비스 중 현재 가장 범위가 큰 서비스는 Chatbot입니다
4. Advanced RAG
하지만 RAG도 만능은 아닙니다.
벡터 검색은 다양한 의미를 포괄할 수 있습니다. 키워드가 명확함에도 의미만 같은 불필요한 자료가 검색되거나 사용자들이 익숙하지 않은 방식으로 검색될 수 있습니다.
또는 불필요한 정보들, 검색된 결과의 순서, 표 & 수식 & 이미지 등은 AI가 처리하기 어려운 정보로 인해 In context Hallucination이 발생할 수 있습니다.
따라서 Reranker, Hybrid Search(Ensemble Search), Metadata 등 다양한 전/후처리 방법들을 통해 제어했습니다.
참고자료

5. Evaluation
AI 답변은 정성적이라 시스템 품질을 감으로 판단하는 경우가 많습니다.
PoC, 데모에서 동작과 운영에서안정적으로 동작하는 것은 전혀 다른 문제입니다.
그래서 평가를 진행했고 RAG 평가에서는 검색이 근거를 잘 가져왔는지, 답변이 근거에 기반하는지, 최종 답변이 기대 답변과 맞는지 확인했습니다.
LLM-as-a-Judge나 RAGAS로 평가했습니다. 하지만 지표 하나로만 해석하는 것은 주의해야합니다. 상황에 따라 지표는 다르게 해석될 수 있습니다.
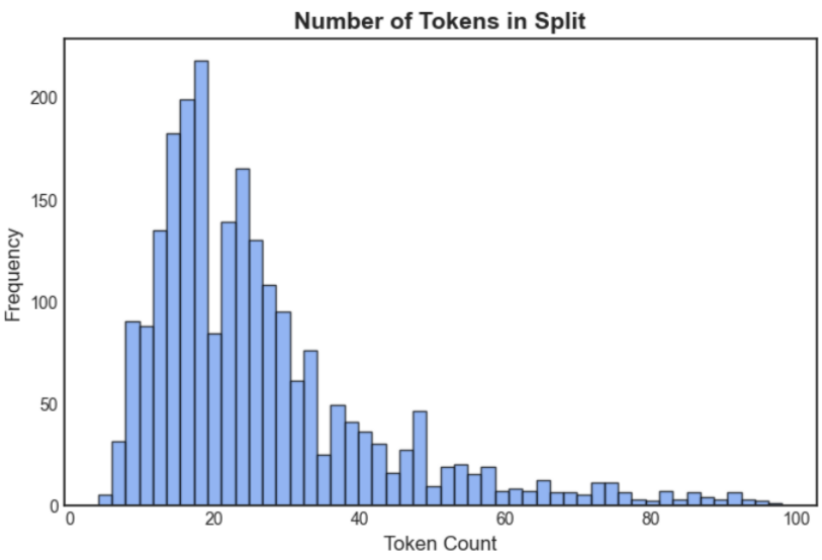
Precision과 Recall 관계
| 경우 | 전체 정답 | 검색 결과 수 | 검색된 정답 수 | Precision | Recall |
|---|---|---|---|---|---|
| 검색 결과 50개 중 정답 10개 | 10 | 50 | 10 | 10/50 = 20% | 10/10 = 100% |
| 검색 결과 10개 중 정답 10개 | 10 | 10 | 10 | 10/10 = 100% | 10/10 = 100% |
| 검색 결과 10개 중 정답 5개 | 10 | 10 | 5 | 5/10 = 50% | 5/10 = 50% |
반복적으로 실패 패턴과 비즈니스에 맞는 지표를 세우는게 중요합니다.
6. AI Agent 설계
사용자 목표를 달성하기 위해 상황을 판단과 거기에 필요한 tool을 선택하고observation을 바탕으로 다음 행동을 결정하는 실행 시스템입니다.
AI Agent는 Tool에 따라 모든 로직을 처리할 수 있을만큼 강하지만 비싸고 확률적으로 동작합니다.
따라서 AI Agent가 정말 필요한 문제인지 확인해야합니다
- 단일 LLM 호출
- RAG
- AI Workflow 혹은 코드
요청마다 실행 경로가 달라지거나 tool 여러 개를 조합해야 할 때 Agent를 고려합니다.
따라서 AI Agent를 만들기 위해선 문제 정의, 사용자 시나리오, tool 명세, 정상 흐름, 예외 흐름, 종료 조건, 성공 판정 기준을 가장 우선시해야합니다.
그래야만 원하는 동작 범위에서 의도한 목표를 수행 가능합니다.
참고자료



7. Multi-Agent
AI Agent의 목적과 문제를 이해했다면 Multi Agent를 만드는 것도 문제없습니다.
고객센터 Chatbot이나 자주 사용하는 Claude Code/Codex 혹은 AI 서비스들 또한 Tool 로직과 목적에 따른 차이만 있을 뿐 설계 방식은 동일합니다.
핵심을 기반으로 단일 AI Agent를 확장하는 방법에 대해 말씀드렸습니다.
참고자료

8. LLM Observability
AI Agent의 동작은 블랙박스입니다.
Tool이 많이지면 많아질수록, 컨텍스트가 길어지면 길어질수록, LLM이 생성하는 응답 자체가 왜 이렇게 생성됐는지 판단하기 매우 어렵습니다.
Observability는 그 과정을 다시 볼 수 있게 남기는 일입니다.
Agent는 최종 답변만 보면 디버깅하기 어렵습니다.
어떤 prompt를 사용했는지, 어떤 retrieval query를 날렸는지, 어떤 문서가 검색됐는지, 어떤 tool을 어떤 인자로 호출했는지, token과 latency가 어디서 발생했는지 trace로 남겨야 합니다.
Observability가 있어야 비용 최적화도 가능하고, 보안 사고 분석도 가능하며, 실패 사례를 regression dataset으로 만들 수 있다는 걸 확인했습니다.
참고자료


9. Cost Optimization
LLM 비용 최적화는 단순히 싼 모델을 고르는 일이 아닙니다.
비용은 모델 단가가 아닌
- 채팅 서비스의 history 길이
- RAG의 retrieval context
- AI Agent의 tool result, retry 횟수, tool 목록 노출 방식
- Multi Agent의 model routing 등
- LLM as a Judge Evaluation
다양한 구성으로 발생할 수 있습니다.
따라서 비용 최적화는 trace에서 시작했습니다.
어디서 token이 많이 쓰이는지, 어떤 tool 결과가 너무 긴지, 같은 정보를 반복해서 보낸다면 개선할 수 있었습니다.
단순 요청은 작은 모델로 보내고, 고정 prompt는 caching하고, retrieval과 tool result에는 Threshold 혹은 Budget을 설정해야합니다.
변경을 확인하기 위해선 한 번의 하나씩만 개선 후 평가해야합니다.
참고자료



10. AI Security & Aligenment
AI 보안은 모델에게 "위험한 요청은 거절해"라고 작성한다고 해결되지 않습니다.
사용자 입력, 외부 문서, memory, tool 결과, system prompt가 context 안에서 섞이면서 악성 데이터가 주입될 수 있습니다.
OWASP Top 10을 for LLM Application으로 다양한 패턴을 확인했습니다.
Prompt Injection를 LLM 호출 계층에서 대표적으로 말씀드렸습니다.
- 외부 context는 명령이 아니라 참고자료
- 위험한 tool에는 권한 확인이나 사용자 확인
- 입력과 출력에서 민감정보를 탐지하고 Guardrail의 종류
- 모델에서 해결 방안 (Aligentment, 안전한 학습 방안)
하지만 LLM 호출 계층의 보안은 확률적인 동작으로 인해 신뢰하기 어려울 수 있다고 말씀드렸습니다.
따라서 전체 보안 시스템을 잘 갖추는 것이 가장 중요하다는 것을 강조드렸습니다.
- 안전한 프롬프트 작성, Safeguard 모델의 도입
참고자료

11/12. Fine-tuning
Fine Tuning은 모르는 것을 학습시키고 최신 지식을 외우게하는 작업이 아닙니다.
반복되는 판단 기준과 출력 형식을 안정적으로 맞추는 데 더 적합합니다.
- Continuous Pre-Training (CPT) - Pre training과 동일한 학습 방식
- Fine Tuning - Post training으로 모델의 출력 선호도 조정
예를 들어 고객 문의 분류, 보안 입력 분류, Agent 실패 원인 분류, 뉴스 구조화처럼 label과 schema가 명확한 작업이 Fine-tuning 후보가 됩니다.
반대로 최신 지식 답변, 문서 기반 Q&A, 긴 문맥 검색은 RAG나 Prompt Engineering을 먼저 검토해야 합니다.
다양한 학습 방식이 존재하지만 중요한 건 학습하기 위한 system, user, assistant 데이터셋이 필요합니다. 여기에 필요한 데이터를 확보하는 것이 가장 중요합니다.
Dataset을 확보했다면 모델 입력에 맞는 구조로 변환(Chat Template)하고 필요한 부분만 구성하는 Masking과 학습 방식에 필요한 파라미터 조정이 필요합니다.
SFT 방식으로 LoRA 가중치를 만들었고, vLLM 배포 흐름을 정리했습니다.
- LoRA는 가중치 커스텀으로 얻을 수 있는 성능 개선이 적음
- SFT Train은 학습 환경, 반복 횟수에 따라 달라지는 부분으로 가장 중요
최신 모델 성능을 보면 Fine Tuning이 정답은 아니라는 것을 확인할 수 있습니다.
데이터가 부족하거나, 작업이 지식 검색에 가깝거나, 유지 비용이 크다면 RAG, Prompt Engineering, Rule 기반 접근이 훨씬 더 좋을 수 있죠.
참고자료


최종 정리
과정을 진행한 순서가 시스템을 설계하는 순서는 아닙니다.
아직까지도 RAG는 주도적으로 사용하고, 특정 도메인 같은 경우 파인튜닝부터 접근하는 경우도 존재합니다. (이미지, 수식/텍스트 패턴인 경우)
특히나 빠르게 발전하는 AI 시스템 상에서 언제든지 중요도는 바뀔 수 있습니다.
또 AI의 발전으로 안되던 로직이 될 수도 있습니다.
- 4월 - Anthropic
Claude Opus 4.7공개 / OpenAIGPT-5.5/ChatGPT Images 2.0공개 - 5월 - Anthropic
Claude Opus 4.8공개 / GeminiGemini 3.5 Flash - 6월 - Anthropic
Claude Fable 5,Claude Mythos 5공개 / 접근 중단- ... OpenAI
GPT-5.6출시 예정
- ... OpenAI
과정에서는 기술도 중요하지만 접근 방식, 기술 목적을 주로 강조드리고 싶었습니다.
정리하면 모델을 잘 쓰는 것에서 끝나지 않고 모델이 들어간 시스템을 끝까지 책임질 수 있어야합니다.
![[AI Agent] LLM Training Preview (11주차)](https://images.unsplash.com/photo-1725289339928-06ee31684df5?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDZ8fEVuZ2luZXxlbnwwfHx8fDE3ODA2MjQzNDl8MA&ixlib=rb-4.1.0&q=80&w=960)
![[AI Agent] AI Security Preview (10주차)](https://images.unsplash.com/photo-1762340916350-ad5a3d620c16?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDU1fHxBSSUyMFNlY3VyaXR5fGVufDB8fHx8MTc3OTk3MDU0Mnww&ixlib=rb-4.1.0&q=80&w=960)
![[AI Agent] Cost Optimization Preview (9주차)](https://images.unsplash.com/photo-1723095469034-c3cf31e32730?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDI3fHxDb3N0fGVufDB8fHx8MTc3ODgzMzc1OXww&ixlib=rb-4.1.0&q=80&w=960)
![[AI Agent] LLM Observability Preview (8주차)](https://images.unsplash.com/photo-1641054373027-8f492aeb1f80?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDR8fFRyYWNlfGVufDB8fHx8MTc3ODI0NjcyMnww&ixlib=rb-4.1.0&q=80&w=960)