[AI Agent] Cost Optimization Preview (9주차)
AI Agent의 LLM 비용이 커지는 원인을 LLM, 애플리케이션, 인프라 관점에서 정리하고 비용 최적화 기준을 제시합니다.
![[AI Agent] Cost Optimization Preview (9주차)](https://images.unsplash.com/photo-1723095469034-c3cf31e32730?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDI3fHxDb3N0fGVufDB8fHx8MTc3ODgzMzc1OXww&ixlib=rb-4.1.0&q=80&w=1200)
0. 개요
LLM은 코드보다는 비싸지만 사람보다는 저렴한 자원처럼 보입니다.
문제는 Agent가 한 번의 호출로 끝나지 않는다는 점입니다. 하나의 사용자 요청을 처리하는 동안 model을 여러 번 호출하고, tool 결과를 다시 prompt에 넣고, 검색 context를 붙이고, 실패하면 재시도합니다.
그래서 Agent 비용은 보통 다음 식으로 커집니다.
요청 비용
= model 호출 횟수
x (input token 비용 + output token 비용)
+ caching / storage / infra 비용무서운 점은 이 과정이 설계에 따라 계속 반복된다는 데 있습니다. Multi Agent 구조를 잘못 잡으면 사람이 한 건 확인하고 처리하는 비용보다 더 비싸질 수도 있습니다.
8주차 Preview에서는 Observability를 붙여 과하게 설계된 부분을 줄이고, workflow 구조와 Agent 패턴을 나누어 봤습니다.
이번 주차에는 안정된 AI 시스템에서 비용을 줄이는 방법을 살펴보겠습니다.
1. LLM 비용 최적화 방안
LLM 비용 최적화는 크게 세 층으로 나눠 볼 수 있습니다.
- LLM을 어떻게 사용할 것인가
- 애플리케이션에서 어떤 입력과 호출을 만들 것인가
- 시스템과 인프라를 어떻게 운영할 것인가
먼저 LLM 사용 방식에서 바로 확인할 수 있는 대표 패턴부터 보겠습니다.
1.1 LLM 비용은 어떻게 계산되는가
| 비용 항목 | 의미 | 확인할 것 |
|---|---|---|
| Input token | model에 전달한 prompt, context, 대화 이력, tool schema | 반복되는 긴 입력 |
| Cached input token | prompt caching으로 재사용된 입력 token | cache hit 여부 |
| Output token | model이 생성한 답변 token | 답변 길이 |
| Reasoning token | 일부 reasoning model의 내부 추론 token | 모델별 과금 정책 |
| Batch discount | 비동기 batch 처리 할인 | 즉시 응답이 필요한 작업인지 |
| Cache storage | cache 저장 시간에 따른 비용 | TTL, 재사용 횟수 |
기본 계산식은 단순합니다.
하지만 가격표만 보고 판단하면 어긋납니다. 같은 입력도 모델마다 token 수가 다르고, 반복되는 입력은 caching을 받을 수 있습니다. 실시간 응답이 필요 없는 작업은 batch로 보낼 수도 있습니다.
1.2 LLM에서 비용을 최적화하기
가장 먼저 볼 것은 tokenization 차이입니다.
모델을 바꾸는 것만으로도 비용이 달라질 수 있습니다. 예를 들어 LangChain 같은 추상화 계층을 쓰고 있다면 호출 구조를 크게 바꾸지 않고도 모델을 교체해 비교할 수 있습니다.
한국어, 일본어, 중국어처럼 CJK 비중이 높은 입력은 모델별 tokenizer 차이가 비용 차이로 이어질 수 있습니다.
아래 문장을 예시로 보겠습니다.
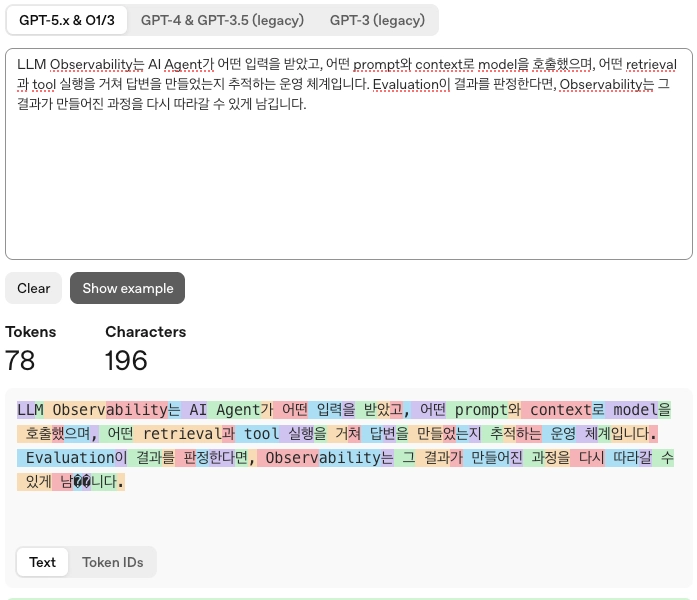
LLM Observability는 AI Agent가 어떤 입력을 받았고, 어떤 prompt와 context로 model을 호출했으며, 어떤 retrieval과 tool 실행을 거쳐 답변을 만들었는지 추적하는 운영 체계입니다. Evaluation이 결과를 판정한다면, Observability는 그 결과가 만들어진 과정을 다시 따라갈 수 있게 남깁니다.| 모델 계열 | 측정 token 수 | 관찰 |
|---|---|---|
| GPT-5.x / o 계열 tokenizer | 78 | 한국어와 영어 용어가 섞인 문장을 비교적 적은 token으로 나눔 |
| Gemini tokenizer | 87 | GPT 계열보다 조금 더 많은 token으로 계산됨 |
| Claude Opus 4 tokenizer | 150 | 같은 문장이 훨씬 많은 token으로 계산됨 |
실제 API로 측정하는 편이 가장 정확합니다. 여기서는 빠르게 확인할 수 있는 웹 도구로 먼저 점검했습니다.
- Claude → Bedrock

- Gemini → Web

이 숫자만으로 어떤 모델이 항상 싸다고 말할 수는 없습니다. 실제 비용은 token 단가, input/output 비율, caching 여부, 품질 요구사항에 따라 달라집니다.
그래도 한 가지는 분명합니다.
같은 한국어 입력도 모델마다 token 수가 다르다.
가격표만 보면 실제 비용을 잘못 판단할 수 있다.Agent에서는 system prompt, tool description, observation, retrieval context가 여러 step에서 반복됩니다. 단일 질문에서는 78 token과 150 token의 차이가 작아 보여도 step이 늘고 RAG context가 붙고 평가 데이터가 쌓이면 차이가 금방 커집니다.
그래서 모델을 고를 때는 실제 입력부터 재봐야 합니다.
1. 우리 서비스의 한국어 입력이 모델별로 몇 token인지 측정한다.
2. input token과 output token 중 어디에서 비용이 많이 나는지 나눈다.
3. 같은 품질을 낸다면 token 수와 caching 조건까지 포함해 다시 비교한다.1.3 Prompt Caching
Prompt caching은 반복되는 긴 prefix를 재사용해 비용과 latency를 줄이는 방식입니다. Model Provider에서 제공하는 방식으로, Memory 구조와는 조금 다릅니다.
- 접두사가 동일해야합니다.
같은 앞부분을 계속 보내는 서비스라면 먼저 검토할 만합니다.
긴 system prompt가 반복된다.
긴 문서나 정책을 여러 질문에서 반복 사용한다.
같은 tool schema와 instruction이 많은 요청에서 공유된다.
사용자별 고정 context가 반복된다.반대로 아래 경우에는 효과가 제한적입니다.
요청마다 prefix가 자주 바뀐다.
긴 내용이 prompt 뒤쪽에 붙고 앞쪽이 매번 달라진다.
cache TTL 안에 재사용되지 않는다.
output token 생성 시간이 대부분이다.Provider마다 방식도 다릅니다.
| Provider / Serving | 방식 | 핵심 기준 |
|---|---|---|
| OpenAI | 지원 모델에서 자동 prompt caching | 긴 동일 prefix, cached token 확인 |
| Claude | cache_control 기반 prompt caching | cache write/read 비용, 5분/1시간 TTL |
| Gemini | implicit / explicit context caching | 비용 절감 보장 여부, TTL, storage 비용 |
| vLLM | automatic prefix caching | self-host에서 shared prefix, prefill 절감 |
Caching을 쓴다고 항상 싸지는 것은 아닙니다. 앞부분이 자주 반복되어야 합니다.
cache write 비용 + TTL 비용 < 반복해서 원문을 보내는 비용예를 들어 모든 요청에 긴 회사 정책, 환불 약관, tool schema, system instruction이 들어간다면 prompt caching 후보가 됩니다.
반복되는 앞부분
-> system instruction
-> tool schema
-> 공통 정책 문서
요청마다 달라지는 뒷부분
-> user question
-> 현재 주문 정보
-> 이번 retrieval 결과반대로 요청마다 앞부분이 계속 바뀌면 caching 효율이 떨어집니다.
나쁜 구조:
user question
-> system instruction
-> policy
-> tool schema
좋은 구조:
system instruction
-> policy
-> tool schema
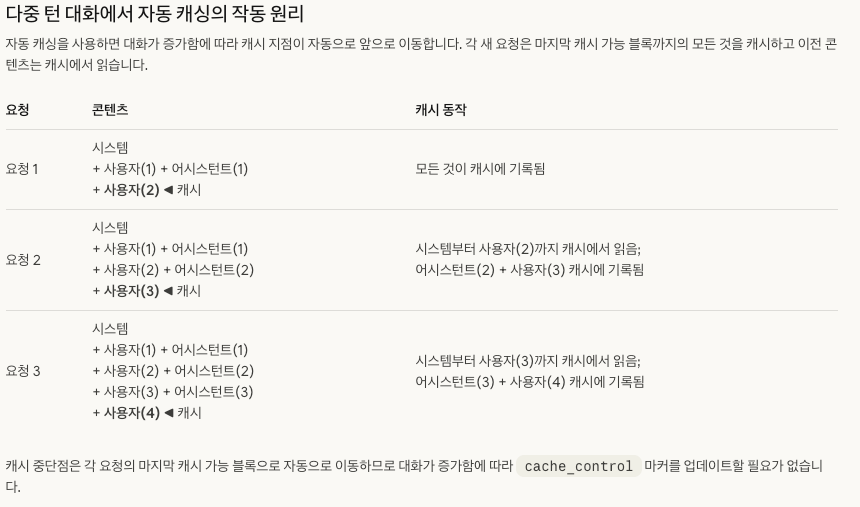
-> user questionPrompt caching을 볼 때는 trace에서 cached tokens, input tokens, latency, request pattern을 확인합니다. 긴 prompt를 쓴다고 비용이 바로 줄어들지는 않습니다. 반복되는 prefix가 안정적으로 유지되어야 효과가 납니다.
1.4 Batch 처리
즉시 응답이 필요 없는 작업은 batch로 보낼 수 있습니다.
적합한 작업은 다음과 같습니다. Batch의 핵심은 가격과 응답 시간의 교환입니다.
실시간 요청:
지금 답을 받아야 하므로 일반 API 호출 사용
비동기 작업:
나중에 받아도 되므로 batch 사용 가능다만 대부분의 Runtime AI Agent 동작에는 batch가 맞지 않습니다.
Batch는 단순히 싸게 호출하는 기능이 아닙니다. 작업을 실시간 처리와 비동기 처리로 나누는 설계 방식입니다.
1.5 LLM 사용 방식 최적화 체크리스트
여기까지는 다음 순서로 확인하면 됩니다.
1. 실제 입력 샘플을 모은다.
2. 모델별 token 수를 측정한다.
3. input / output / cached token을 나눠 본다.
4. 반복되는 긴 prefix가 있는지 확인한다.
5. 실시간 처리와 비동기 처리 대상을 나눈다.
6. 같은 품질 기준에서 비용을 다시 계산한다.목표는 제일 싼 모델을 찾는 데 있지 않습니다. 같은 품질을 더 적은 token, 더 많은 cache hit, 적절한 처리 방식으로 달성하는 것 입니다.
따라서 모든 상황에 적합하진 않을 수 있으니, 장단점을 확인해보시는 것을 권장드립니다.
2. 애플리케이션 최적화
앞에서는 모델과 provider가 제공하는 비용 최적화 방법을 봤습니다. 이제 애플리케이션 레벨에서 줄일 수 있는 비용을 봐야 합니다.
같은 모델을 쓰더라도 애플리케이션이 매번 어떤 입력을 만들고, history를 얼마나 붙이고, tool을 몇 개 노출하고, 실패 시 몇 번 재시도하는지에 따라 비용이 크게 달라집니다.
핵심 질문은 단순합니다.
이번 호출에 꼭 필요한 정보만 넣었는가?
이번 요청이 정말 multi turn이어야 하는가?
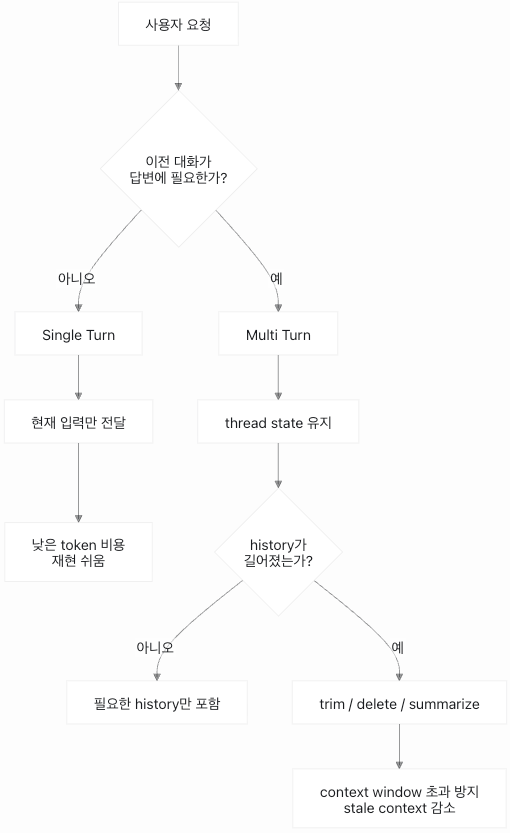
LLM이 봐야 할 tool과 context를 최소화했는가?2.1 Single Turn과 Multi Turn을 먼저 나눈다
모든 요청이 대화형일 필요는 없습니다.
분류, 추출, 라우팅, 짧은 요약처럼 입력 하나로 답을 낼 수 있는 작업은 single turn으로 처리하는 편이 낫습니다.
이전 대화 history를 붙이지 않기 때문에 token 비용이 작고 재현도 쉽습니다. 이런 작업에서는 대화 상태보다 입력과 출력 스키마가 더 중요합니다.
반대로 고객 상담, 요구사항 정리, 다단계 Agent 작업처럼 이전 발화와 결정이 다음 판단에 영향을 주는 작업은 multi turn이 필요합니다.
다만 이때도 전체 대화 기록을 매번 넣으면 비용이 계속 커집니다.
| 구분 | 적합한 작업 | 비용 관점 |
|---|---|---|
| Single Turn | 분류, 추출, 라우팅, 단건 요약, batch 평가 | history가 없어 입력이 작고 예측 가능함 |
| Multi Turn | 상담, 개인화, 요구사항 조율, 다단계 Agent | 맥락을 유지하지만 history 비용이 누적됨 |

chat history는 token 수나 message 수 기준으로 줄일 수 있고, system message를 유지하거나 최근 message를 남기는 전략을 선택할 수 있습니다.
대화 기록은 그대로 넣지 않는 편이 좋습니다. 오래된 대화 전체를 prompt에 계속 붙이는 방식과 인삿말은 가장 흔한 비용 누수입니다.
LangChain에서는 message history가 길어질 때 다음 패턴을 제안합니다.
| 방식 | 의미 | 비용 효과 | 주의점 |
|---|---|---|---|
| Trim messages | 최근 N개 message 또는 token budget 안의 message만 유지 | 즉시 token 감소 | 오래된 중요 정보가 사라질 수 있음 |
| Delete messages | 필요 없는 message를 state에서 제거 | 불필요한 context 제거 | tool call/result 순서가 깨지면 안 됨 |
| Summarize messages | 오래된 대화를 요약으로 대체 | 맥락 유지와 비용 절감의 중간점 | 요약 비용과 정보 손실이 생김 |
| Custom filtering | 메시지 유형, 중요도, 권한 기준으로 선별 | 서비스 요구에 맞게 최적화 | 기준이 없으면 디버깅이 어려움 |
여기서 중요한 것은 "얼마나 기억할까"가 아닙니다.
다음 행동에 필요한 상태만 남긴다.예를 들어 사용자가 처음에 말한 배송지, 환불 사유, 금지 조건은 남길 수 있습니다.
하지만 인사말, 중복 확인, 이미 해결된 tool result를 계속 넣을 필요는 없습니다.
2.2 Tool을 전부 보여주지 않는다
Tool이 많아질수록 tool description도 prompt 비용이 됩니다. 비슷한 tool이 많으면 LLM의 선택 오류도 늘어납니다.
LangChain agents 문서는 static tools와 dynamic tools를 나눕니다.
모든 tool을 미리 등록할 수도 있지만 state, 권한, feature flag, conversation stage에 따라 model에 노출되는 tool을 동적으로 줄일 수 있습니다.
비용 관점에서는 다음 원칙이 좋습니다.
지금 단계에서 쓸 수 없는 tool은 보여주지 않는다.
권한이 없는 tool은 보여주지 않는다.
읽기 전용 요청에는 write/delete tool을 보여주지 않는다.
초기 대화에서는 고급 검색 tool을 숨긴다.
이 방식은 보안에도 도움이 됩니다. 다만 이번 주차에서는 보안보다 비용 관점에서 봅니다. tool 목록이 줄면 tool description token이 줄고, 잘못된 tool 선택으로 생기는 재시도 비용도 줄어듭니다.

2.3 Retrieval과 tool result에도 예산을 둔다
RAG나 tool을 쓰는 Agent에서는 LLM 호출보다 retrieval context와 tool result가 더 큰 입력이 될 때가 있습니다.
따라서 애플리케이션에는 다음 budget이 필요합니다.
| Budget | 조절 대상 |
|---|---|
| history budget | 몇 turn 또는 몇 token까지 유지할지 |
| retrieval budget | top-k, chunk 길이, score threshold |
| tool result budget | tool 결과 중 어떤 field만 넘길지 |
| retry budget | 실패 시 몇 번까지 재시도할지 |
| step budget | Agent loop를 몇 step에서 멈출지 |
예를 들어 주문 조회 tool이 내부적으로 50개 field를 반환하더라도 LLM에는 환불 판단에 필요한 purchase_date, product_category, opened, policy_flags 정도만 넘기면 됩니다.
나쁜 방식:
tool result 전체 JSON을 그대로 observation에 넣는다.
좋은 방식:
다음 판단에 필요한 field만 observation으로 만든다.2.4 애플리케이션 정리
애플리케이션 레벨의 비용 최적화는 모델을 싸게 바꾸는 문제가 아닙니다. LLM에 무엇을 보여줄지, 무엇을 숨길지, 무엇을 state로 관리할지 결정하는 문제입니다.
single turn이면 history를 붙이지 않는다.
multi turn이면 trimming 또는 summarization을 둔다.
state와 prompt를 분리한다.
tool은 필요한 것만 노출한다.
retrieval과 tool result에도 token budget을 둔다.
retry와 step 수를 제한한다.Observability에서 본 비용 누수를 실제 애플리케이션 구조로 줄일 수 있습니다.
3. 시스템과 인프라 운영 방안
마지막 층은 시스템과 인프라입니다. 앞의 두 단계가 "무슨 모델을 어떻게 호출할 것인가"와 "애플리케이션이 어떤 입력을 만들 것인가"였다면, 여기서는 실행 기반을 봅니다.
GPU를 직접 운영할지, memory/cache 계층 여부 등 시스템 부하를 줄이고 최적화하는 방식입니다.
핵심 질문은 다음과 같습니다.
직접 GPU를 운영할 만큼 트래픽이 안정적인가?
반복 질문을 LLM까지 보내지 않고 cache에서 처리할 수 있는가?
Agent orchestration을 직접 구현할 것인가, managed service에 맡길 것인가?3.1 GPU utilization이 핵심이다
Self-hosted LLM은 token 단가만 보면 매력적으로 보일 수 있습니다.
하지만 실제 비용은 GPU 가격보다 GPU utilization에 더 크게 흔들립니다.
GPU 서버를 띄워두고 요청이 적으면 사용하지 않는 시간에도 비용이 나갑니다. 반대로 요청이 충분히 많고 batching과 KV cache를 잘 활용하면 API 호출보다 유리해질 수 있습니다.
| 항목 | 비용에 미치는 영향 |
|---|---|
| 모델 크기 | 큰 모델일수록 GPU memory와 latency가 증가 |
| context length | 긴 context는 KV cache memory를 크게 사용 |
| 동시 요청 수 | throughput과 queue latency를 동시에 결정 |
| batching | GPU utilization을 높이지만 응답 지연이 늘 수 있음 |
| quantization | memory 사용량을 줄이지만 품질 확인이 필요 |
| prefix/KV cache | 반복 prefix의 prefill 비용을 줄일 수 있음 |
GPU의 적절한 요청 수, 부하를 관리하는게 상당히 어렵습니다.
GPU를 계속 바쁘게 만들 수 있는가?
latency SLA를 지키면서 batch를 묶을 수 있는가?
긴 context 때문에 memory가 먼저 터지지 않는가?이 질문에 답하기 어렵다면 처음부터 self-hosted로 가기보다 managed API나 Bedrock 기반 구성이 더 안전할 수 있습니다. GPU를 사용한다면 모델 구성에 맞는 VRAM을 가진 GPU를 골라야 합니다.
- https://instances.vantage.sh/aws/ec2/g6e.xlarge?currency=USD
- https://instances.vantage.sh/aws/ec2/p5.48xlarge?currency=USD
3.2 AI Agent Memory
일반 cache는 정확히 같은 key가 들어왔을 때만 hit이 납니다.
LLM 서비스에서는 질문 문장이 조금 달라도 의미가 같을 때가 많습니다.
"환불 가능해요?"
"이 상품 반품할 수 있나요?"
"지난주에 산 이어폰 환불되나요?"이런 요청을 매번 LLM에 보내면 비용이 반복됩니다. semantic cache는 query를 embedding으로 바꾸고, 이전 query와 의미가 충분히 비슷하면 저장된 답변을 재사용합니다.
기존 exact match cache와 달리 vector embedding 기반으로 유사한 query를 찾는 방식입니다. vector search를 지원하며 semantic caching, RAG, personalization 같은 use case에 사용할 수 있습니다.
- https://docs.aws.amazon.com/AmazonElastiCache/latest/dg/semantic-caching-overview.html
- https://docs.aws.amazon.com/AmazonElastiCache/latest/dg/vector-search.html
semantic cache가 잘 맞는 경우는 다음입니다.
| 상황 | 이유 |
|---|---|
| 반복 문의가 많다 | 비슷한 질문을 LLM까지 보내지 않아도 됨 |
| 답변이 자주 바뀌지 않는다 | cache stale 위험이 낮음 |
| latency가 중요하다 | memory 기반 vector search로 빠르게 응답 가능 |
| FAQ, 정책, 가이드성 답변이 많다 | 의미 유사도가 높은 요청이 반복됨 |
주의할 점도 있습니다.
threshold가 낮으면 엉뚱한 답을 재사용할 수 있다.
정책이 바뀌면 stale answer를 반환할 수 있다.
사용자별 권한이나 개인정보가 섞이면 tenant 분리가 필요하다.
cache hit 답변도 trace에 남겨야 한다.대부분 AWS 프로젝트를 진행하다 보니 이 영역에서는 AgentCore Memory도 같이 보게 됩니다.
3.3 어떤 구성을 선택할 것인가
| 구성 | 적합한 상황 | 주의점 |
|---|---|---|
| Managed API | 트래픽이 작거나 변동이 큼, 빠른 개발이 중요 | token 단가와 호출 횟수 관리 필요 |
| Self-hosted GPU | 사용량이 크고 안정적이며 운영 역량이 있음 | GPU utilization, memory, 장애 대응 필요 |
1. Managed API로 시작한다.
2. Observability로 비싼 요청 유형을 찾는다.
3. 반복 질문은 semantic cache로 줄인다.
4. 트래픽이 충분히 크고 안정적이면 self-hosted GPU를 계산한다.참고 자료
- LLM 한국어 토큰 사용량과 모델 간 토큰 사용량 차이 정리
- OpenAI Prompt Caching
- OpenAI Batch API
- Claude Prompt Caching
- Claude Pricing
- Gemini Context Caching
- Gemini Batch API
- vLLM Automatic Prefix Caching
- LangChain Short-term memory
- LangChain Agents
- LangChain trim_messages
- Amazon ElastiCache Vector Search
- Amazon ElastiCache Semantic Caching
- Implementing semantic cache with ElastiCache for Valkey
- Amazon Bedrock Agents
![[AI Agent] AI Engineering Review (12주차)](https://images.unsplash.com/photo-1531262951893-05a0ffb31b27?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDN8fGZpbmFsfGVufDB8fHx8MTc4MTkxNDI0MXww&ixlib=rb-4.1.0&q=80&w=960)
![[AI Agent] LLM Training Preview (11주차)](https://images.unsplash.com/photo-1725289339928-06ee31684df5?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDZ8fEVuZ2luZXxlbnwwfHx8fDE3ODA2MjQzNDl8MA&ixlib=rb-4.1.0&q=80&w=960)
![[AI Agent] AI Security Preview (10주차)](https://images.unsplash.com/photo-1762340916350-ad5a3d620c16?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDU1fHxBSSUyMFNlY3VyaXR5fGVufDB8fHx8MTc3OTk3MDU0Mnww&ixlib=rb-4.1.0&q=80&w=960)
![[AI/ML] 어휘와 토크나이저](https://images.unsplash.com/photo-1671739250895-1d57d6095a05?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDEwfHxUb2tlbnxlbnwwfHx8fDE3Nzg2MzA1MjZ8MA&ixlib=rb-4.1.0&q=80&w=960)