[AI Agent] LLM Training Preview (11주차)
LLM의 Pre-training과 Post-training 차이를 정리하고 Fine-tuning의 목적, 데이터 구조와 설계 방법을 정리했습니다.
![[AI Agent] LLM Training Preview (11주차)](https://images.unsplash.com/photo-1725289339928-06ee31684df5?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDZ8fEVuZ2luZXxlbnwwfHx8fDE3ODA2MjQzNDl8MA&ixlib=rb-4.1.0&q=80&w=1200)
개요
지금까지는 LLM을 활용할 때 필요한 주변 구조를 주로 살펴봤습니다.
RAG, Advanced RAG, AI Agent가 대표적입니다.
이 흐름은 모델의 가중치를 바꾸기보다, 모델 바깥의 입력과 시스템 구조를 조정하는 방식에 가깝습니다.
하지만 모든 문제가 RAG나 Prompt Engineering으로 해결되지는 않습니다.
같은 의미라도 늘 정해진 형식으로 답해야 할 때가 있습니다. 특정 말투를 유지해야 하거나, 반복되는 업무 판단을 같은 기준으로 처리해야 하는 경우도 생깁니다.
예를 들어 고객 문의를 정해진 카테고리로 분류하거나, 답변을 항상 JSON 형식으로 만들거나, 서비스 톤에 맞는 존댓말 응답을 유지해야 하는 경우입니다.
이런 상황에서 Fine-tuning을 사용합니다.
이번 글에서는 LLM 학습 과정을 Pre-training과 Post-training으로 나누고, Fine-tuning이 그 안에서 어디에 위치하는지 살펴봅니다. 이어서 Fine-tuning 데이터를 만들 때 Tokenization, Chat Template, Assistant Label Masking을 왜 알아야 하는지 정리합니다. 마지막에는 고객 문의 분류와 금융 뉴스 구조화 출력 예제로 학습 데이터 설계 방식을 보겠습니다.
Pre-training
Pre-training은 모델이 대규모 텍스트, 코드, 이미지 데이터를 보며 기본 패턴과 지식을 익히는 단계입니다.
언어를 이해하고 생성하는 능력, 일반 지식, 기초적인 추론 능력도 이 단계에서 만들어집니다.
비용과 시간이 많이 들기 때문에 보통 foundation model이나 base model을 만들 때 쓰입니다.
- Pre-training
- 대규모 데이터로 base model을 처음 학습하는 단계
- 언어, 코드, 이미지 패턴과 일반 지식을 익힘
- Continued Pre-training
- 이미 학습된 base model에 추가 데이터를 더 학습시키는 방식
- 특정 도메인 지식이나 표현을 보강할 때 사용
- Domain-adaptive Pre-training, DAPT
- 법률, 의료, 금융, 개발 문서처럼 특정 도메인 데이터로 추가 학습
- 도메인 용어와 문맥 이해를 높이는 데 유리
- Task-adaptive Pre-training, TAPT
- 특정 작업과 가까운 입력 데이터로 추가 학습
- 분류, 검색, 요약 등 특정 태스크에 맞는 언어 패턴을 보강
Pre-training은 모델의 기본 지식과 언어 능력을 만드는 단계입니다.
예를 들어 “환불”, “배송”, “불만”, “요청” 같은 단어와 문맥의 일반적인 의미를 익히는 과정에 가깝습니다.
Post-training
Post-training은 이미 만들어진 base model을 실제 사용 목적에 맞게 다듬는 단계입니다.
모델이 지시를 더 잘 따르게 만들고, 답변 스타일이나 안전성, 특정 작업 수행 능력을 조정합니다.
Fine-tuning, Instruction Tuning, RLHF, DPO 같은 방식이 여기에 들어갑니다.
- Supervised Fine-tuning, SFT
- 입력과 정답 응답 예시를 학습시키는 방식
- 모델이 원하는 형식과 행동을 따라 하도록 만듦
- Instruction Tuning
- 다양한 지시문과 응답 예시로 학습
- 모델이 사용자 명령을 더 잘 따르게 만드는 데 사용
- Fine-tuning
- 특정 작업, 말투, 출력 형식에 맞게 모델을 조정하는 방식
- 실무에서는 SFT 형태로 쓰이는 경우가 많음
- Preference Tuning
- 좋은 답변과 덜 좋은 답변의 차이를 학습
- 답변 품질, 선호도, 안전성을 맞추는 데 사용
- RLHF
- 사람의 피드백을 바탕으로 보상 모델을 만들고, 그 보상에 맞게 모델을 조정
- 모델을 사람의 선호와 안전 기준에 맞추는 데 사용
- RLAIF
- 사람 대신 AI 피드백을 활용해 모델을 조정
- RLHF보다 비용을 줄일 수 있지만 평가 품질 관리가 중요
- DPO
- 선호되는 답변과 선호되지 않는 답변 쌍을 직접 학습
- RLHF보다 구조가 단순해 많이 쓰임
- Safety Alignment
- 유해하거나 위험한 답변을 줄이도록 학습
- 정책 준수, 거절 응답, 안전한 표현을 다듬는 단계
Post-training은 모델이 실제 사용 목적에 맞게 말하고 행동하도록 다듬는 단계입니다.
예를 들어 “환불하고 싶어요”라는 문장을 고객지원 상황에서 refund 카테고리로 분류하게 만들거나, 항상 존댓말로 응답하도록 맞추는 작업이 여기에 들어갑니다.
Fine-tuning
Fine-tuning은 Post-training 안에서 특정 작업, 말투, 응답 규칙을 학습시키는 방법입니다.
Fine-tuning은 Pre-training처럼 언어와 세계 지식을 대규모로 새로 학습하는 방식이 아닙니다. 실무에서 Fine-tuning은 지식 주입보다 행동 조정에 가깝습니다.
새로운 사실을 많이 외우게 하기보다는, 아래와 같은 행동을 반복해서 학습시키는 데 더 잘 맞습니다.
- 고객 문의를 정해진 카테고리로 분류하기
- 답변을 항상 정해진 JSON schema로 출력하기
- 회사 서비스 톤에 맞는 말투 유지하기
- 같은 기준으로 긍정, 부정, 중립 판단하기
- 특정 업무 절차에 맞춰 응답 순서 지키기
이 차이를 이해하려면 먼저 모델이 문장을 받아들이는 단위인 token부터 봐야 합니다.
Tokenization
Tokenization은 텍스트를 모델이 처리할 수 있는 token 단위로 나누는 과정입니다.
- OpenAI Tokenizer
- LLM Tokenizer와 Vocabulary 정리
- 같은 문장이라도 tokenizer에 따라 token 수가 달라짐
- Token 수가 많아질수록 연산량과 비용이 늘어남
- 단어를 더 작은 조각으로 나누면 희귀 단어, 신조어, 여러 언어를 기존 token 조합으로 표현하기 쉬움
- Continued Pre-training은 token 단위에서 의미와 표현을 더 익히는 쪽에 가깝고, Fine-tuning은 의미 자체보다 응답 행동을 맞추는 쪽에 가까움
입력과 출력 가능한 token 수는 모델마다 다릅니다.
이 범위를 context length 또는 context window라고 부르며, config.json에서 확인할 수 있습니다.

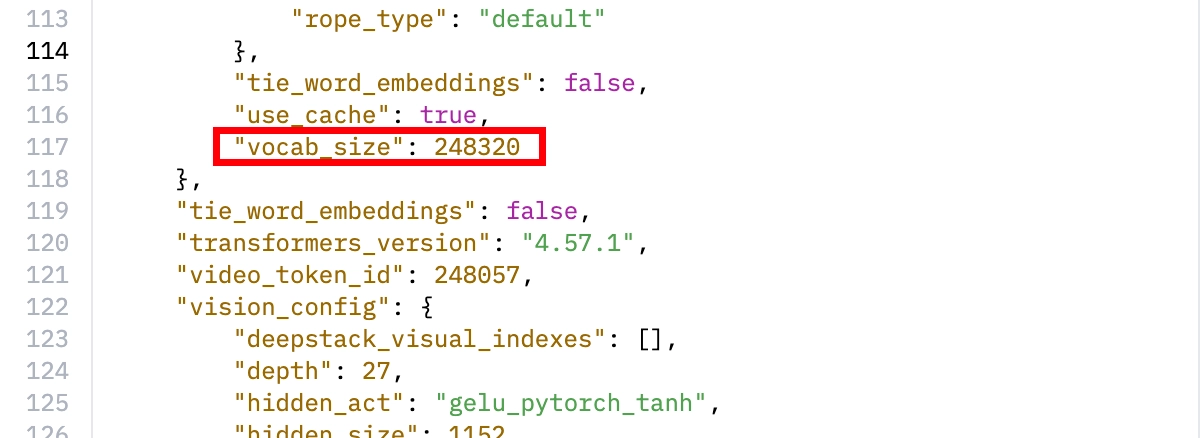
Fine-tuning 데이터도 결국 token으로 변환되어 학습됩니다. 그래서 학습 데이터는 사람이 읽기 좋은 문서가 아니라, 모델이 반복해서 볼 입력과 정답의 묶음으로 설계해야 합니다.
Chat Template
Chat Template은 system, user, assistant 메시지를 모델이 읽을 수 있는 하나의 문자열로 바꾸는 규칙입니다.
대화형 LLM은 문장 하나만 받지 않습니다. 역할이 나뉜 메시지 목록을 입력으로 받습니다.
[
{
"role": "system",
"content": "당신은 인공지능 어시스턴트입니다. 묻는 말에 친절하고 정확하게 답변하세요."
},
{
"role": "user",
"content": "은행의 기준 금리에 대해서 설명해줘"
}
]
이 메시지는 실제 학습이나 추론 과정에서 모델별 special token 규칙에 맞춰 하나의 텍스트로 펼쳐집니다.
<|im_start|>system
당신은 인공지능 어시스턴트입니다. 묻는 말에 친절하고 정확하게 답변하세요.<|im_end|>
<|im_start|>user
은행의 기준 금리에 대해서 설명해줘<|im_end|>
<|im_start|>assistant
여기서 봐야 할 부분은 Chat Template이 모델마다 다르다는 점입니다.
어떤 모델은 <|im_start|> 같은 token을 사용하고, 어떤 모델은 다른 turn token을 사용합니다.
<bos><|turn>system
당신은 ** 고객센터의 챗봇입니다. 묻는 말에 친절하고 정확하게 답변하세요.<turn|>
<|turn>user
당신이 누군지 설명해주십시오<turn|>
<|turn>model
Fine-tuning 데이터를 만들 때 “대화 데이터가 있다”에서 끝내면 안 됩니다. 학습하려는 모델이 어떤 Chat Template을 쓰는지 확인하고, 그 형식에 맞춰 system, user, assistant 메시지를 넣어야 합니다.
Assistant Label Masking
SFT에서는 모델이 system과 user 메시지를 보고 assistant 응답을 생성하도록 학습합니다.
여기서 전체 대화 텍스트를 모두 정답으로 보지는 않습니다. system과 user는 모델에게 주어지는 입력 조건이고, 모델이 실제로 맞춰야 하는 정답은 assistant 응답입니다.
예를 들어 이런 학습 데이터가 있다고 가정해보겠습니다.
system: 고객 문의를 category와 reply를 가진 JSON으로 분류하라.
user: 주문한 상품이 언제 배송되는지 알고 싶어요.
assistant: {"category": "delivery", "reply": "배송 상태를 확인해드리겠습니다."}
학습 관점에서는 역할이 이렇게 나뉩니다.
| 구간 | 역할 |
|---|---|
| system | 출력 규칙과 판단 기준을 제공하는 입력 조건 |
| user | 분류해야 할 실제 사용자 입력 |
| assistant | 모델이 생성해야 하는 정답 |
Assistant Label Masking은 system과 user 부분을 손실 계산에서 제외하고, assistant가 생성해야 하는 응답만 학습 대상으로 남기는 처리입니다.
모델은 대화 전체를 외우지 않습니다. “이런 입력과 지시가 들어오면 이런 assistant 응답을 만들어야 한다”는 패턴을 학습합니다.
학습 데이터 설계
Fine-tuning의 핵심은 모델에게 어떤 행동을 반복해서 보여줄지 정하는 일입니다.
코드는 한 번 작성하면 데이터만 바꿔 여러 실험에 다시 쓸 수 있습니다. 반대로 데이터 기준이 흔들리면 학습 설정을 아무리 바꿔도 원하는 결과가 나오기 어렵습니다.
실무에서는 LoRA의 r, alpha, target_modules 같은 설정값을 몇 개 조정하는 것보다, 모델이 반복해서 볼 데이터의 형식과 판단 기준을 일관되게 만드는 일이 더 중요합니다.
학습 데이터는 보통 이런 구조로 생각하면 됩니다.
{
"messages": [
{
"role": "system",
"content": "모델이 따라야 할 역할, 출력 형식, 판단 기준"
},
{
"role": "user",
"content": "실제 사용자가 입력할 질문이나 문장"
},
{
"role": "assistant",
"content": "모델이 생성해야 하는 정답 응답"
}
]
}
실제 JSONL 데이터에서는 assistant.content도 문자열로 저장되는 경우가 많습니다.
그래서 JSON 응답을 학습시킬 때는 사람이 보기 좋은 예시만 보면 부족합니다. 실제 저장 형식에서 따옴표, 중괄호, 리스트, 빈 값이 깨지지 않는지도 확인해야 합니다.
고객 문의 분류 JSON 예제
고객 문의 분류는 Fine-tuning이 지식 주입이 아니라 행동 조정이라는 점을 보여주기 좋은 예제입니다.
모델이 “배송”, “환불”, “불만”이라는 단어의 의미를 전혀 몰라서 Fine-tuning을 하는 것이 아닙니다.
이미 알고 있는 표현을 고객지원 업무 기준에 맞춰 정해진 카테고리와 JSON 응답으로 바꾸도록 학습시키는 쪽입니다.
{
"messages": [
{
"role": "system",
"content": "고객 문의를 읽고 category와 reply를 가진 JSON으로만 답변하라. category는 delivery, refund, complaint, product_question 중 하나를 사용하라."
},
{
"role": "user",
"content": "주문한 상품이 아직 안 왔는데 배송이 어디까지 됐나요?"
},
{
"role": "assistant",
"content": "{\"category\": \"delivery\", \"reply\": \"배송 상태를 확인해드리겠습니다.\"}"
}
]
}
이 예제에서 모델이 배워야 하는 것은 세 가지입니다.
- 고객 문의를 업무 카테고리로 분류하는 판단 기준
- 정해진 JSON 형식으로만 응답하는 출력 규칙
- 고객에게 전달할 짧고 일관된 응답 톤
금융 뉴스 구조화 출력 예제
금융 뉴스 예제는 금융 도메인 지식을 설명하려고 넣은 예제가 아닙니다.
복잡한 system 지시, 긴 user 입력, 구조화된 assistant 응답이 하나의 학습 데이터로 어떻게 묶이는지 보여주는 사례입니다.
{
"messages": [
{
"role": "system",
"content": "주어진 뉴스가 특정 종목에 영향을 주는지 판별하고, 정해진 JSON 형식으로만 답변하라."
},
{
"role": "user",
"content": "현대차 노조 4년 만에 파업 나설까... 현대자동차 노조가 올해 임금협상에서 난항을 겪자 파업을 가결했다..."
},
{
"role": "assistant",
"content": "{\"is_stock_related\": true, \"negative_impact_stocks\": [\"현대자동차\"], \"negative_keywords\": [\"파업\", \"임금협상\", \"생산 차질\"], \"positive_impact_stocks\": [], \"positive_keywords\": [], \"summary\": \"현대자동차 노조의 파업 가능성이 커지고 있다.\"}"
}
]
}
이 예제에서 중요한 것은 뉴스 전문이 아니라 데이터 구성입니다.
system에는 역할, 판단 기준, 출력 schema가 들어감user에는 실제 입력 데이터가 들어감assistant에는 모델이 따라 해야 할 정답 출력이 들어감
assistant 응답에 불필요한 reasoning 블록이나 중간 생각이 들어 있으면, 모델은 그것까지 출력 패턴으로 학습할 수 있습니다.
학습 데이터의 assistant 응답에는 실제 서비스에서 모델이 생성해야 하는 결과만 남겨야 합니다.
좋은 학습 데이터의 기준
Fine-tuning 데이터는 양보다 기준이 중요합니다.
데이터를 많이 넣는 것보다, 모델이 반복해서 배워야 할 행동이 일관되게 담겨 있는지가 더 중요합니다.
형식 일관성
출력 형식은 흔들리면 안 됩니다.
고객 문의 분류를 JSON으로 학습시킨다면 어떤 샘플은 category, 어떤 샘플은 type, 어떤 샘플은 label을 쓰면 안 됩니다. 모델은 세 표현을 모두 가능한 출력으로 받아들일 수 있습니다.
나쁜 예시는 다음과 같습니다.
{"type": "배송", "answer": "배송 확인이 필요합니다."}
좋은 예시는 다음과 같습니다.
{"category": "delivery", "reply": "배송 상태를 확인해드리겠습니다."}
형식 일관성은 단순히 보기 좋은지의 문제가 아닙니다.
Fine-tuning에서는 형식 자체가 모델이 배워야 하는 행동입니다.
판단 기준 일관성
같은 의미의 입력은 같은 기준으로 분류되어야 합니다.
예를 들어 “상품이 아직 안 왔어요”를 어떤 샘플에서는 delivery, 다른 샘플에서는 complaint로 분류하면 모델은 어떤 기준을 따라야 할지 배우기 어렵습니다.
실제 업무에서는 하나의 문의가 여러 카테고리에 걸칠 수 있습니다.
이 경우 우선순위 규칙을 정해야 합니다.
예를 들어 기준을 이렇게 둘 수 있습니다.
- 배송 위치나 도착 예정일을 묻는 경우는
delivery - 환불이나 취소를 명시적으로 요청하는 경우는
refund - 서비스 불만과 항의 표현이 중심인 경우는
complaint - 제품 사용법이나 사양을 묻는 경우는
product_question
중요한 것은 정답이 하나라고 단정하는 일이 아닙니다. 데이터 안에서 판단 기준이 반복 가능해야 합니다.
엣지케이스 포함
좋은 데이터에는 쉬운 예시만 넣으면 안 됩니다.
실제 서비스에서 자주 흔들리는 경계 사례도 들어가야 합니다.
고객 문의 분류에서는 이런 케이스가 필요합니다.
- 배송 문의처럼 보이지만 실제로는 환불을 요청하는 문장
- 불만 표현이 있지만 제품 사용법 질문이 핵심인 문장
- 카테고리를 판단하기 어려운 짧은 문장
- JSON 값이 빈 문자열이나 빈 리스트가 되어야 하는 경우
금융 뉴스 구조화 출력에서도 마찬가지입니다.
- 특정 회사가 언급되지만 주가 영향과 관련 없는 뉴스
- 긍정과 부정 영향이 함께 있는 뉴스
- 종목명이 별칭이나 약어로 표현된 뉴스
- 관련 종목이 없어 빈 리스트를 반환해야 하는 뉴스
엣지케이스는 모델을 괴롭히려고 넣는 데이터가 아닙니다.
서비스에서 자주 흔들리는 판단 경계를 모델에게 보여주기 위한 데이터입니다.
Fine-tuning이 필요한 경우와 필요 없는 경우
Fine-tuning은 강력한 방법이지만 항상 정답은 아닙니다.
새로운 지식이 필요하다면 먼저 RAG를 검토하는 편이 좋습니다.
예를 들어 사내 정책, 최신 문서, 제품 매뉴얼처럼 계속 바뀌는 정보를 답변해야 한다면 모델을 학습시키기보다 검색 가능한 context로 넣는 방식이 더 적합합니다.
프롬프트를 조금 더 명확히 쓰는 것으로 해결되는 문제라면 Prompt Engineering이 먼저입니다.
입력 예시 몇 개와 출력 형식을 prompt에 넣는 것만으로 충분히 안정적인 경우도 많습니다.
Fine-tuning이 필요한 경우는 보통 다음과 같습니다.
- 같은 작업을 반복적으로 수행해야 함
- 출력 형식이 자주 깨짐
- 카테고리 판단 기준을 일관되게 맞춰야 함
- 서비스 말투나 응답 패턴을 유지해야 함
- prompt가 너무 길어지고 few-shot 예시를 계속 넣기 부담스러움
반대로 다음 경우에는 Fine-tuning이 우선순위가 아닐 수 있습니다.
- 최신 지식이나 외부 문서 참조가 핵심인 경우
- 데이터가 충분히 정리되어 있지 않은 경우
- 무엇을 정답으로 볼지 팀 안에서도 합의되지 않은 경우
- 몇 개의 prompt 예시로 이미 충분히 해결되는 경우
- 학습 후 평가할 기준이 준비되어 있지 않은 경우
Fine-tuning은 모델을 더 똑똑하게 만드는 마법이 아닙니다.
모델에게 반복해서 보여줄 정답 행동을 데이터로 정리하고, 그 행동을 더 안정적으로 따르게 만드는 방법입니다.
정리
이번 글에서는 Fine-tuning의 이론적인 부분을 정리했습니다.
다음 글에서는 과제에서 설계한 dataset을 실제 학습 과정으로 연결해보겠습니다.
LoRA, SFTConfig, batch size, gradient accumulation, collate function, label masking이 실제 코드에서 어떻게 연결되는지 살펴보고, 학습 결과를 기존 RAG, Prompt Engineering, Agent 개선 방식과 비교해보겠습니다.
![[AI Agent] AI Engineering Review (12주차)](https://images.unsplash.com/photo-1531262951893-05a0ffb31b27?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDN8fGZpbmFsfGVufDB8fHx8MTc4MTkxNDI0MXww&ixlib=rb-4.1.0&q=80&w=960)
![[AI Agent] AI Security Preview (10주차)](https://images.unsplash.com/photo-1762340916350-ad5a3d620c16?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDU1fHxBSSUyMFNlY3VyaXR5fGVufDB8fHx8MTc3OTk3MDU0Mnww&ixlib=rb-4.1.0&q=80&w=960)
![[AI Agent] Cost Optimization Preview (9주차)](https://images.unsplash.com/photo-1723095469034-c3cf31e32730?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDI3fHxDb3N0fGVufDB8fHx8MTc3ODgzMzc1OXww&ixlib=rb-4.1.0&q=80&w=960)
![[AI Agent] LLM Observability Preview (8주차)](https://images.unsplash.com/photo-1641054373027-8f492aeb1f80?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDR8fFRyYWNlfGVufDB8fHx8MTc3ODI0NjcyMnww&ixlib=rb-4.1.0&q=80&w=960)