[AI/ML] 어휘와 토크나이저
LLM이 텍스트를 처리하는 기본 단위인 토큰과 어휘집의 개념을 살펴보고, 토크나이저가 문장을 모델 입력으로 변환하는 과정을 단계별로 정리합니다.
![[AI/ML] 어휘와 토크나이저](https://images.unsplash.com/photo-1671739250895-1d57d6095a05?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDEwfHxUb2tlbnxlbnwwfHx8fDE3Nzg2MzA1MjZ8MA&ixlib=rb-4.1.0&q=80&w=1200)
개요
언어를 배우기 위해선, 언어의 어휘를 습득하고 어휘력을 확장해야합니다.
- 어휘: 특정 개인이 이해하는 언어 내 모든 단어
데이터를 잘 이해하는게 언어 모델의 핵심인 만큼 핵심 구성 요소 “어휘”에 대해 정리해보겠습니다.
어휘란
평균 영어 원주민의 경우 20,000 ~ 35,000개의 단어 어휘 학습합니다. 언어 모델도 어휘를 알고있습니다. 대부분 5,000개에서 500,000개를 가지고 있으며 더 자세히 확인해보겠습니다.
Google Gemma-4-31B 모델의 어휘를 확인해보면 “vocab”을 검색했을 때 모델의 어휘가 담긴 사전이 표시됩니다. 하지만 사전에서 확인하는 단어들과 완전히 1:1로 매핑되지 않습니다. 이렇게 단어와 유사한 단위를 “토큰”이라고 하며 자세한 내용은 뒤에서 확인하겠습니다.
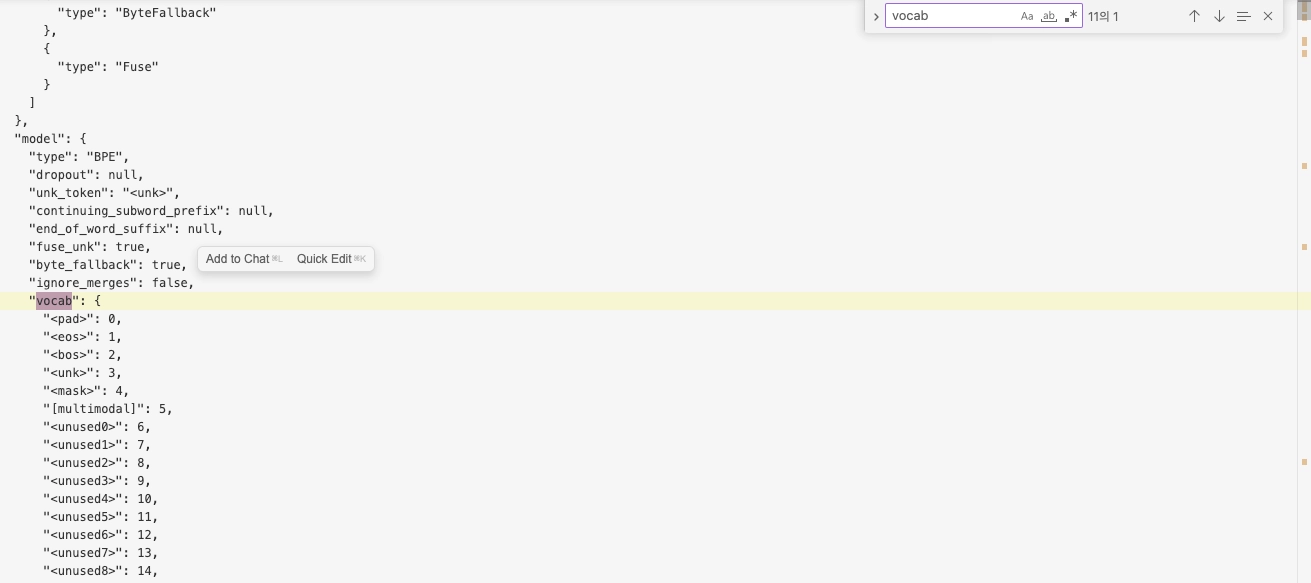
동시에 어휘 파일을 보면 토큰 옆에 숫자가 표시되는데, 이건 입력 ID, 토큰 인덱스라고 하며 Gemma 31B 모델에는 대략 26만 개의 토큰이 존재합니다. 토큰을 더 자세히 확인하면 앞 부분 몇개의 토큰은 단일 문자로 구성되어있습니다. 특수 문자, 숫자, 대문자, 악센트로 구성되어있습니다. 뒷 부분으로 가면 긴 단어로 구성됩니다.
대부분의 토큰을 확인하면 단어 전체가 아닌 부분 단어 형태로 구성됩니다.
"▁한국": 50413,
"▁문서": 162745,
"▁작성": 107854,
- 여기서
_는 공백을 나타냅니다.- GPT-2/RoBERTa 계열은
Ġ. 모델 별로 다른 토큰화 흐름을 가집니다.
- GPT-2/RoBERTa 계열은
영어라면 다음과 같을 수 있습니다.
"ork": 802, # w + ork 또는 work 혹은 net + work / net + w + ork
"ear": 803,
"ition": 804,
"ata": 805,
"ous": 806,
일반적으론 대소문자를 구분하는 어휘 체계가 훨씬 뛰어난 성능을 보여줍니다.
NotFound/not found
마지막으로 숫자 토큰입니다. 모든 숫자가 자체가 같은 토큰을 가질 수는 없습니다. 또한 현실적이지도 않습니다. 이렇게 토큰과 토큰 크기가 어떻게 결정되는지는 뒤에서 확인하겠습니다.
236770 1
236771 0
236778 2
236800 3
236810 5
보통 고유한 이름, 장소, 기호는 자체 토큰을 가집니다. 서울 , 한국 은 있어도 강남 , 도봉 은 없습니다.
이런 토큰도 존재할 수 있죠. 이는 프로그래밍 언어도 처리 가능하다는 점을 보여줍니다.
"']))": 36083
"\\"};": 37324
이렇게 토큰을 구성한다면 영어 사전의 모든 단어, 한국 사전의 모든 단어를 포함한다면 간단해보입니다.
하지만 사람들이 사용하는 어휘는 그렇게 단순하지 않습니다. 새로운 언어들은 계속 만들어지고, 단어의 형태는 다양하며 여러 단어가 하나로 결합되기도 합니다. 이건 단순 언어의 문제가 아니라 특정 도메인으로 갈 수록 더 심화됩니다.
초기에는 이런 단어들이 OOV(Out Of Vocabulary)로 처리됐습니다.
이를 <UNK> 토큰으로 표현했지만, 실제 활용되긴 어려웠습니다. OOV를 해결하기 위해선 모든 문자를 1:1로 매칭해야하는데, 한 가지 문장을 표현하기에 사용되는 토큰 수가 훨씬 많아집니다.
<UNK> 텍스트를 출력합니다. <UNK>는 갈색입니다.
문자 단위로 토큰화하면 어휘 수는 줄어들지만, 한 문장을 표현하는 토큰 수가 크게 늘어나 훈련과 추론 비용이 증가합니다.
또 제한된 컨텍스트에 담을 수 있는 실제 내용도 줄어듭니다. 반대로 단어 단위로 토큰화하면 자주 쓰이는 단어는 효율적으로 표현할 수 있습니다. 하지만 새로운 단어나 드문 단어를 처리하기 어렵습니다.
따라서 두 방식의 절충안으로 “부분 단어(Subword)”를 사용합니다.
자주 등장하는 단어는 하나의 토큰에 가깝게 표현하고, 낯선 단어나 복합어는 더 작은 단위로 나누어 표현하는 방식입니다.
Tokenizer
토크나이저는 토큰 정보를 가지고 사람과 모델 사이의 인터페이스 역할을 합니다.
2가지 주요 역할을 수행합니다.
- 훈련을 위한 대규모 텍스트에 토크나이저 알고리즘으로 어휘집 생성
(tokenizer.json)
- 훈련과 추론 단계에서 원시 데이터를 토크나이저 처리
인코딩 과정 확인하기
아래 토큰화하는 과정을 확인해보겠습니다.
google/gemma-4-E2B-it
토크나이저 라이브러리를 사용하면 tokenizer.convert_ids_to_tokens(token_ids) 를 통해 토큰을 확인할 수 있습니다.
import os
from transformers import AutoTokenizer
HF_TOKEN = ""
if HF_TOKEN:
os.environ["HF_TOKEN"] = HF_TOKEN
model_id = "google/gemma-4-E2B-it"
text = "나는 밥을 먹었다."
tokenizer = AutoTokenizer.from_pretrained(model_id)
token_ids = tokenizer.encode(text, add_special_tokens=False)
tokens = tokenizer.convert_ids_to_tokens(token_ids)
list(zip(tokens, token_ids))
출력입니다.
[('나는', 80232),
('▁', 236743),
('밥', 242152),
('을', 237293),
('▁먹', 56916),
('었다', 28479),
('.', 236761)]
문장을 조금만 바꿔서 다시 확인해보겠습니다.
text = "너는 밥을 먹었니?"
token_ids = tokenizer.encode(text, add_special_tokens=False)
tokens = tokenizer.convert_ids_to_tokens(token_ids)
list(zip(tokens, token_ids))
[('너', 239298),
('는', 237170),
('▁', 236743),
('밥', 242152),
('을', 237293),
('▁먹', 56916),
('었', 238520),
('니', 237397),
('?', 236881)]
숫자입니다.
text = "9478 + 2512가 뭐야?"
token_ids = tokenizer.encode(text, add_special_tokens=False)
tokens = tokenizer.convert_ids_to_tokens(token_ids)
list(zip(tokens, token_ids))
[('9', 236819),
('4', 236812),
('7', 236832),
('8', 236828),
('▁+', 900),
('▁', 236743),
('2', 236778),
('5', 236810),
('1', 236770),
('2', 236778),
('가', 237272),
('▁뭐야', 163694),
('?', 236881)]
일부러 오타를 냈습니다.
text = "너 바블 먹었니!!!"
token_ids = tokenizer.encode(text, add_special_tokens=False)
tokens = tokenizer.convert_ids_to_tokens(token_ids)
list(zip(tokens, token_ids))
[('너', 239298),
('▁바', 19342),
('블', 239744),
('▁먹', 56916),
('었', 238520),
('니', 237397),
('!!!', 11145)]
[('너', 239298),
('▁바', 19342),
('블', 239744),
('▁먹', 56916),
('었', 238520),
('니', 237397),
('!!!!!!!', 208128)]
아예 다른 토큰이 들어가는데 이는 부분 단어 토큰화의 취약한 부분입니다. 또한 특수 기호는 한 토큰으로 묶여 들어가지만 토큰 값이 달라지는 걸 확인할 수 있습니다. 분명한 건 느낌표 3개와 5개가 있는 건 의미가 달라질 수 있다는 점 입니다.
- 상용화된 거대 언어 모델들은 오타에 대해 강한점을 보입니다.
- 다양한 철자 오류들을 이미 포함하고 있습니다.
['gpt2',
'r50k_base',
'p50k_base',
'p50k_edit',
'cl100k_base',
'o200k_base',
'o200k_harmony']
더 크고 최신 모델일 수록 큰 토크나이저를 사용하는 경향이 있습니다. 또한 LLM이 입력의 일부에서 이상한 동작을 수행할 때 해당 입력이 어떻게 생겼는지 확인해보는게 도움이 될 수 있습니다. → Glitch Token
Tokenization Pipeline
토크나이저가 수행하는 단계입니다.

| 단계 | 결과 |
|---|---|
| 원시 텍스트 | 나는 밥을 먹었다. |
| 정규화 | backend normalizer: Replace(pattern=String(" "), content="▁") |
| 사전 토큰화 | [('나는 ', (0, 3)), ('밥을 ', (3, 6)), ('먹었다.', (6, 10))] |
| 토큰화 | [('나는', 80232, (0, 2)), ('▁', 236743, (2, 3)), ('밥', 242152, (3, 4)), ('을', 237293, (4, 5)), ('▁먹', 56916, (5, 7)), ('었다', 28479, (7, 9)), ('.', 236761, (9, 10))] |
| 후처리 | backend post_processor: TemplateProcessing(single=[Sequence(id=A, type_id=0)], pair=[Sequence(id=A, type_id=0), Sequence(id=B, type_id=1)], special_tokens={}) |
| 복원 | 나는 밥을 먹었다. |
정규화
텍스트를 일관된 형식으로 변환하는 과정입니다.
- 소문자 변환(대소문자 미구분시)
- 문자에서 악센트 제거
- 유니코드 정규화
backend normalizer: Replace(pattern=String(" "), content="▁")
사전 토큰화
일반적으로 단어 토큰화를 먼저 수행한 다음 그 출력을 다시 세부적인 부분 토큰화 알고리즘에 입력합니다. 단순히 공백으로 분할하는 것 외에도 구두점, 숫자 등을 처리하기 위한 규칙이 필요합니다. 허깅 페이스에서는 이를 처리할 때 공백을 기준으로 단순 텍스트 분리를 수행합니다
[('나는 ', (0, 3)), ('밥을 ', (3, 6)), ('먹었다.', (6, 10))]
단어 토큰과 함께 문자 위치 정보도 함께 반환됩니다.
토큰화
실제 토큰화 단계를 수행합니다.
중요한 알고리즘으로는 BPE(Byte Paier Encoding)이 있으며 사전 훈련 데이터셋을 사용하는 사전 훈련 단계에서 학습된 규칙 세트로 구성됩니다. 알고리즘에 대해 자세히 들어가보겠습니다
바이트 페어 인코딩(BPE)
가장 많이 사용되는 토큰화 알고리즘입니다. 반대로 워드피스 토큰화가 존재하는데 정확히 반대로 동작합니다.
훈련 단계
단어가 이렇게 존재한다고 해보겠습니다
corpus = ["bat", "cat", "cap", "sap", "map", "fan"]- 초기 어휘는 모두 분해합니다. b, a, t, c, a, t, s….
- 가장 빈번한 쌍을 병합합니다.
- 다음으로 빈번항 쌍을 병합합니다.
- 이 과정은 원하는 어휘 크기에 도달할 떄까지 반복합니다.
| Step | 현재 단어 분해 | 인접 pair 빈도 | 선택된 merge |
|---|---|---|---|
| 1 | b a tc a tc a ps a pm a pf a n | a + p: 3a + t: 2c + a: 2b + a: 1s + a: 1m + a: 1f + a: 1a + n: 1 |
a + p -> ap (3회) |
| 2 | b a tc a tc aps apm apf a n | a + t: 2b + a: 1c + a: 1c + ap: 1s + ap: 1m + ap: 1f + a: 1a + n: 1 |
a + t -> at (2회) |
| 결과 | b atc atc aps apm apf a n | b + at: 1c + at: 1c + ap: 1s + ap: 1m + ap: 1f + a: 1a + n: 1 |
- |
이렇게 하면 아주 작은 구성 바이트부터 자주 나오는 입력들까지 구성할 수 있습니다.
추론(토큰화) 단계
토크나이저가 완료되었다면 텍스트를 적절한 부분의 단어 토큰으로 나누고 모델에 입력할 때 사용합니다.
훈련 단계와 유사하게 입력 텍스트가 정규화되고 사전 토큰화를 거친 뒤 개별 문자와 병합 규칙 순서대로 구성합니다. 이렇게 토큰이 생성되었다면 모델에 입력할 준비가 완료됩니다. 아까 저희가 확인했던 토큰화입니다.
[('너', 239298),
('는', 237170),
('▁', 236743),
('밥', 242152),
('을', 237293),
('▁먹', 56916),
('었', 238520),
('니', 237397),
('?', 236881)]
후처리
모델 별 특수 토큰이 추가되는 단계입니다. 많은 언어 모델에서 사용하는 [CLS] , [SEP] 구분자 토큰이 존재합니다.
- <PAD>: 입력의 크기가 최대 길이보다 작을 때 사용
- <EOS>: 시퀀스의 끝으로 해당 토큰을 출력한 뒤 종료합니다.
- <UNK>: 어휘 용어를 나타냅니다.
- <TOOL_CALL></TOOL_CALL_>: API 호출이나 데이터베이스 질의 같은 외부 도구의 입력으로 사용
- <TOOL_RESULT></TOOL_RESULT>: 앞서 언급한 도구 호출 결과를 나타내는데 사용
이 외에도 특정 도메인과 목적에 따라 특수 토큰화 규칙이 존재합니다.
토크나이저 성능 평가 방식
- 토크나이저 비옥도 (Tokenizer Fertility) → 토크나이저에 의해 몇 개로 분할되는지
- 1에 가까울수록 단어를 쪼개지 않습니다(단어 단위 토크나이저) → Vocab 크기가 커집니다.
- 0에 가까울수록 단어를 매우 세분화합니다(문자 단위 토크나이저) → 문장이 길어져 연산 효율과 의미 전달이 떨어집니다
- 비옥도를 적절히 조절하여 OOV를 해결하는게 핵심입니다.
- 토크나이저 동등성 (Tokenizer Equivalence)
- 다른 토크나이저 방식이 동일한 텍스트에 대해 동일하거나 유사한 수준의 정보량을 제공하는지 평가
- 모델의 목적에 따라 효율적인 분할 방식이다릅니다.
- 형태소 분석 기반 토크나이저는 의미를 잘 전달하지만, 딥러닝 기반의 BPE가 더 범용적인 동등성을 가집니다.
특정 도메인 데이터에 범용적인 토크나이저를 사용하면 압축률이 상대적으로 낮아집니다. 도메인 용어 자체가 토큰으로 존재하지 않고 여러 토큰으로 나눠지기 때문입니다. 결국 특수 도메인을 위해선 모델이 도메인 별 용어에 대한 좋은 벡터와 표현을 가져오도록 하는 것 입니다.
새로운 토큰 추가하기
기존 토크나이저에 새로운 토큰을 추가합니다.
from transformers import AutoModelForCausalLM
domain_tokens = ["전세", "월세"]
num_added = tokenizer.add_tokens(domain_tokens)
model = AutoModelForCausalLM.from_pretrained(model_id)
model.resize_token_embeddings(len(tokenizer))
[('강남3구', 262144), ('전세가율', 262145), ('매매거래량', 262146)]}
하지만 이건 토큰만 추가된 내용일 뿐 해당 토큰은 실제 아무런 정보도 없기 때문에 pre training을 수행해야합니다. 관련 데이터와 훈련 과정이 필요합니다.
text = "강남3구 전세가율과 매매거래량을 비교한다."
token_ids = tokenizer.encode(text, add_special_tokens=False)
tokens = tokenizer.convert_ids_to_tokens(token_ids)
list(zip(tokens, token_ids))
[('강남3구', 262144),
('▁', 236743),
('전세가율', 262145),
('과', 237842),
('▁', 236743),
('매매거래량', 262146),
('을', 237293),
('▁비교', 103944),
('한다', 24888),
('.', 236761)]
정리
언어 모델의 핵심 구성 요소를 Google Gemma Toknizer를 통해 확인해봤습니다.
어휘라는게 무엇인지부터 토큰호와 BPE, 워드 피스 같은 알고리즘을 확인했고 토큰 시퀀스로 변환되는 파이프라인을 정리했습니다.
본격적으로 모델 아키텍처를 정리해보겠습니다.
![[AI Agent] Cost Optimization Preview (9주차)](https://images.unsplash.com/photo-1723095469034-c3cf31e32730?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDI3fHxDb3N0fGVufDB8fHx8MTc3ODgzMzc1OXww&ixlib=rb-4.1.0&q=80&w=960)
![[AI Agent] Advanced RAG 리뷰(4주차)](https://images.unsplash.com/photo-1605701250441-2bfa95839417?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDI5fHxSZWluZm9yY2V8ZW58MHx8fHwxNzc2NDMxODE2fDA&ixlib=rb-4.1.0&q=80&w=960)
![[AI Agent] RAG Preview(3주차)](https://images.unsplash.com/photo-1766162357668-d41a4af974df?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDE5fHxDb250ZXh0fGVufDB8fHx8MTc3NDYxNzU3OXww&ixlib=rb-4.1.0&q=80&w=960)
![[AI Agent] Prompt Engineering 리뷰(2주차)](https://images.unsplash.com/photo-1704965021000-dab5ec30ac7e?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDN8fFByb21wdHxlbnwwfHx8fDE3NzQ2MTc0ODJ8MA&ixlib=rb-4.1.0&q=80&w=960)