[AI Agent] RAG overview(3주차)
토큰 제한과 할루시네이션 문제를 해결하는 RAG(검색-증강-생성)의 개념과 구조를 소개합니다. 청킹, 임베딩, 벡터 저장소를 통한 의미론적 검색과 LangChain, LlamaIndex 등 주요 프레임워크를 다룹니다.
![[AI Agent] RAG overview(3주차)](https://images.unsplash.com/photo-1766162357668-d41a4af974df?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDE5fHxDb250ZXh0fGVufDB8fHx8MTc3NDYxNzU3OXww&ixlib=rb-4.1.0&q=80&w=1200)
개요
3주차 RAG(Retrieval-Augmented Generation)의 개념과 구조를 다룹니다.
2주차에서 사용한 수동 Context 방식의 한계를 짚고 외부 지식을 자동으로 검색하여 LLM에 제공하는 RAG가 이를 어떻게 구성되는지 확인합니다. Indexing(청킹, 임베딩, 벡터 저장소)과 Retrieval+Generation 파이프라인의 각 단계를 간략히 다뤄보고 실제 활용 사례와 주요 프레임워크(LangChain, LlamaIndex)를 소개합니다.
왜 RAG가 필요한가
2주차 과제에서 의료급여 본인부담률 표 데이터를 system prompt에 직접 넣어 LLM에게 질문했다. 이 방식은 데이터가 작을 때는 동작하지만, 근본적인 한계가 있다.
토큰 제한: 참조 데이터가 커지면 모델의 context window를 초과한다. Claude 4.6 Sonnet 기준 200K 토큰이다. 의료급여 본인부담률 표 하나는 들어가지만, 관련 법령 전체나 건강보험 심사기준 문서 수백 건을 모두 넣을 수는 없다.
- 최근엔 1 Milion 모델 또한 존재합니다.
200K를 넘을 시 Context window overflow가 발생한다.
- 시스템 입력, 클라이언트 입력, 모델 출력을 모두 포함한 총 토큰 수가 모델에 미리 정의된 컨텍스트 윈도우 크기를 초과할 때 발생
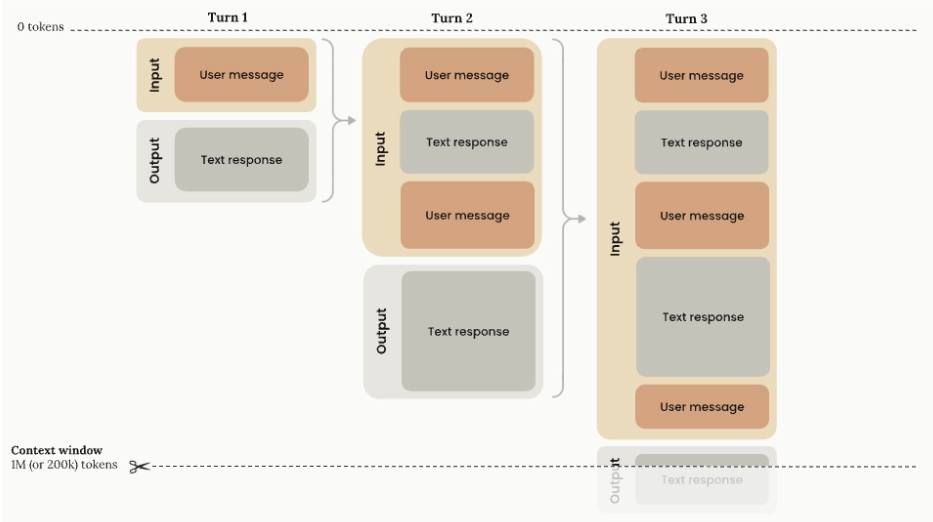
확장성: 문서가 수백, 수천 건으로 늘어나면 모든 내용을 프롬프트에 넣는 것은 불가능하다. 비용도 토큰 수에 비례해 증가한다.
최신성: LLM은 학습 데이터의 지식 컷오프(knowledge cutoff) 이후에 발생한 정보를 알 수 없다.
할루시네이션: LLM은 학습 데이터에 없는 내용을 그럴듯하게 지어내는 경향이 있다. 도메인 전문 지식이 필요한 질문에서 이 문제가 두드러진다.
이를 해결하기 위해 외부 지식을 검색해서 LLM에 제공하는데, 이것이 RAG의 파이프라인이다.
RAG란 무엇인가
검색(Retrieval)으로 찾은 외부 지식을 LLM의 주입(Augmented)하여 응답을 생성(Generation)하는 방법
원본 논문
RAG는 Facebook AI Research(현 Meta AI)에서 Lewis et al. (2020)이 제안했다.
- 논문: "Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks" (NeurIPS 2020)
- BART seq2seq 모델과 Dense Passage Retriever(DPR)를 결합
- 개방형 QA, 팩트 검증, Jeopardy 질문 생성 등에서 당시 SOTA 달성
핵심 기여: 파라메트릭 메모리(LLM 가중치)와 논파라메트릭 메모리(외부 문서)를 결합하는 구조를 제시
출처: Lewis et al., "Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks", NeurIPS 2020 (arXiv:2005.11401)
Naive RAG 아키텍처

2주차와의 비교
| 구분 | 2주차 (수동 Context) | RAG (자동 검색) |
|---|---|---|
| 데이터 제공 방식 | 사람이 직접 system prompt에 삽입 | 시스템이 질문에 맞는 문서를 자동 검색 |
| 확장성 | 문서 수 증가 시 한계 | 수백만 문서까지 확장 가능 |
| 관련성 | 전체 데이터를 넣으므로 노이즈 포함 | 질문과 관련된 부분만 선별 |
| 최신성 | 수동 업데이트 필요 | 문서 저장소 갱신으로 자동 반영 |
RAG 파이프라인 상세
RAG 파이프라인은 크게 Indexing(색인)과 Retrieval + Generation(검색 + 생성) 두 단계로 나뉜다.
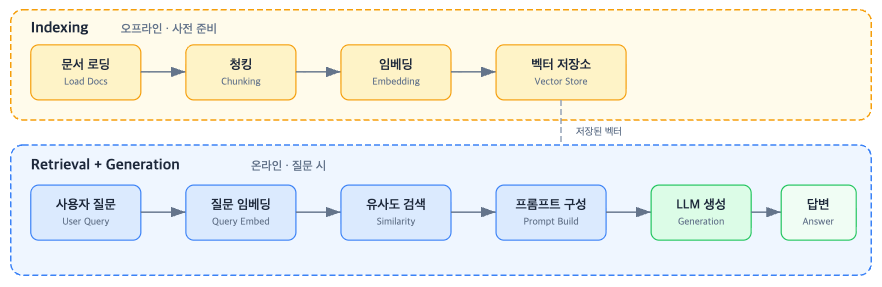
Indexing 단계
Indexing의 핵심 목적은 **의미론적 검색(Semantic Search)**을 가능하게 하는 것이다.
일반적인 키워드 검색(TF-IDF, BM25)은 문서에 포함된 정확한 단어를 매칭하는 방식이다. 반면 RAG의 Indexing은 텍스트를 임베딩 벡터로 변환하여, 단어가 달라도 의미가 유사한 문서를 찾아내는 의미 기반 유사도 검색을 수행한다.
| 구분 | 키워드 검색 (BM25/TF-IDF) | 의미론적 검색 (Semantic Search) |
|---|---|---|
| 매칭 방식 | 정확한 단어 일치 (term frequency 기반) | 임베딩 벡터 간 유사도 (cosine similarity 등) |
| "당뇨병 치료" 검색 시 | "당뇨병", "치료" 단어가 포함된 문서만 반환 | "혈당 관리", "인슐린 요법" 등 의미적으로 관련된 문서도 반환 |
| 동의어/유의어 | 처리 못함 | 자동 처리 |
| 한계 | 어휘 불일치(vocabulary mismatch) 문제 | 임베딩 모델의 품질에 의존 |
이 의미론적 검색을 가능하게 하기 위해 Indexing은 청킹 → 임베딩 → 벡터 저장의 세 단계를 거친다.
Chunking (청킹)
긴 문서를 적절한 크기의 조각(chunk)으로 분할하는 과정이다.
왜 중요한가: 청크 크기가 검색 품질에 직접 영향을 준다.
| 청크가 너무 크면 | 청크가 너무 작으면 |
|---|---|
| 무관한 정보(노이즈)가 포함됨 | 문맥이 손실됨 |
| 임베딩이 여러 주제를 혼합 반영 | 질문에 대한 완전한 답이 한 청크에 없음 |
일반적인 청크 크기는 200~1000 토큰이며, 인접 청크 간 overlap(겹침)을 두어 문맥 손실을 줄인다.
- Fixed-size chunking(고정 길이)
- Hierarchical chunking(계층적 청킹)
- Sementic chunking(의미론적 청킹)
- No chunking(청킹 안함)
청킹의 핵심은 "이 청크만으로 질문에 답할 수 있는가?”이다. 사용자의 요청 혹은 관련있는 Context를 불러와 LLM에게 전달하는 것이 목적이기 때문이다.
이 외에도 표, 수식과 형식 데이터 활용 방식에 따라 청킹 방식은 달라질 수 있다.
Embedding (임베딩)
왜 임베딩이 필요한가?
컴퓨터는 텍스트의 "의미"를 직접 이해할 수 없다. "당뇨병 치료"와 "혈당 관리"는 사람이 보면 비슷한 말이지만, 글자만 비교하면 완전히 다른 문자열이다. 텍스트의 의미를 숫자로 바꿔야 컴퓨터가 "이 두 문장이 비슷하다"를 계산할 수 있다. 이 변환 과정이 임베딩이다.
임베딩이란?
텍스트의 의미를 숫자 목록(리스트)으로 표현하는 것이다. 지도에서 위치를 (위도, 경도) 두 숫자로 표현하듯, 텍스트도 여러 숫자의 조합으로 표현할 수 있다. 이 숫자 목록을 수학에서는 "벡터"라고 부르고, 숫자의 개수를 "차원"이라고 한다.
실제 임베딩은 1,536개에서 3,072개의 숫자로 구성된다. 차원이 많을수록 의미를 더 세밀하게 표현할 수 있지만, 저장 공간과 계산 비용이 늘어난다.
핵심 원리: 의미가 비슷한 텍스트 → 비슷한 숫자 목록 → 가까운 위치
직관적 비유: 도서관에서 책의 위치를 좌표로 표현한다고 생각하자. 비슷한 주제의 책은 가까운 좌표에 배치된다.
- "당뇨병 치료"와 "혈당 관리"는 가까운 좌표를, "당뇨병 치료"와 "자동차 정비"는 먼 좌표를 갖는다.
- “왕” - “남자” = “여왕” 이라는 수치적인 계산이 가능해진다
현재 주요 임베딩 모델 (2026년 3월 기준):
| 모델 | 제공처 | 차원 | 비고 |
|---|---|---|---|
| gemini-embedding-2 | 3072 | 멀티모달(텍스트/이미지/비디오/오디오/PDF), MTEB 1위 | |
| text-embedding-3-large | OpenAI | 3072 | 차원 축소 지원, 텍스트 전용 최저가($0.13/1M tokens) |
| text-embedding-3-small | OpenAI | 1536 | 비용 효율적 ($0.02/1M tokens) |
| voyage-4-large | Voyage AI (MongoDB) | - | MoE 아키텍처, RTEB 1위, 공유 임베딩 공간 |
| voyage-4 | Voyage AI (MongoDB) | - | voyage-3-large 수준 품질, 중형 모델 효율 |
| Jina Embeddings v4 | Jina AI | - | 멀티모달(텍스트/이미지/문서), 30+ 언어 |
Google Gemini Embedding 2 — 멀티모달 임베딩의 등장(참고)
Google이 2026년 3월 10일 공개 프리뷰로 출시한 최초의 네이티브 멀티모달 임베딩 모델이다. 텍스트뿐 아니라 이미지, 비디오, 오디오, PDF를 하나의 벡터 공간에 매핑한다.
- 5가지 모달리티 지원: 텍스트, 이미지, 비디오, 오디오, PDF를 단일 3,072차원 벡터 공간에 임베딩
앞서 다룬 RAG의 한계 중 "멀티모달 한계"를 극복할 수 있는 핵심 기술로, 이미지·표·차트가 포함된 문서의 RAG 파이프라인에 활용
출처: OpenAI Embeddings Guide (https://platform.openai.com/docs/guides/embeddings)
출처: Google — Gemini Embedding 2 (https://blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-embedding-2/)
출처: Voyage AI — Voyage 4 (https://blog.voyageai.com/2026/01/15/voyage-4/)
Vector Store (벡터 저장소)
임베딩 벡터를 저장하고, 주어진 쿼리 벡터와 가장 유사한 벡터를 빠르게 찾아주는 전문 데이터베이스다.
핵심 연산은 ANN(Approximate Nearest Neighbor) 검색이다. 정확한 최근접 이웃을 찾는 대신, 근사치를 구해 속도를 획기적으로 높인다. Facebook AI Research의 FAISS 라이브러리가 이 분야의 기반 연구다.
주요 벡터 저장소 비교:
| 저장소 | 특징 | 적합한 용도 |
|---|---|---|
| FAISS | 로컬 라이브러리, 무료, GPU 지원 | 연구/프로토타입 |
| Chroma | 경량 오픈소스, 설정 간단 | 빠른 프로토타이핑 |
| Pinecone | 완전 관리형 SaaS | 엔터프라이즈 프로덕션 |
| Weaviate | 하이브리드 검색(벡터+키워드) | 복합 검색 요구 |
Retrieval 단계
사용자 질문을 동일한 임베딩 모델로 벡터화한 뒤, 벡터 저장소에서 코사인 유사도(cosine similarity) 기준으로 가장 가까운 Top-K 문서를 반환한다.
직관적 비유: 도서관 사서에게 질문하면, 관련 책 3~5권을 골라주는 것과 같다. 사서는 모든 책의 내용을 외우지 않아도, 각 책이 어떤 주제인지(벡터 위치)를 알기 때문에 적절한 책을 찾아줄 수 있다.
코사인 유사도: 두 벡터 간의 각도를 측정한다. 값이 1에 가까울수록 의미적으로 유사하다.
Generation 단계
검색된 문서(context)와 원래 질문을 결합하여 LLM 프롬프트를 구성하고, 답변을 생성한다.
[System] 아래 참고 문서를 바탕으로 질문에 답하세요.
참고 문서에 없는 내용은 "정보 없음"이라고 답하세요.
[Context] {검색된 문서 Top-K}
[User] {사용자 질문}
2주차에서 학습한 프롬프트 기법(Few-shot, CoT, Self-Consistency 등)을 이 Generation 단계에 결합할 수 있다. RAG와 프롬프트 엔지니어링은 상호 보완적이다.
RAG 활용 사례와 도구
실제 활용 예시
| 분야 | 활용 방식 |
|---|---|
| 사내 문서 QA | 사내 위키, 매뉴얼을 벡터화하여 직원 질의응답 |
| 고객 지원 챗봇 | 기술 문서 기반으로 정확한 답변 생성 |
| 의료 임상 의사결정 | 임상 가이드라인, 약물 정보 검색 후 의사 지원 |
| 법률 리서치 | 판례, 법령 검색 후 관련 조항 요약 |
주요 프레임워크
LangChain: Indexing과 Retrieval+Generation을 분리한 2단계 구조를 제공한다. Document Loader, Text Splitter, Embedding, Vector Store, Retriever, Chain 등의 추상화로 RAG 파이프라인을 모듈 단위로 조합할 수 있다.
출처: LangChain 공식 문서 (https://docs.langchain.com)
LlamaIndex: Document -> Node -> Vector Store 체계로 데이터 인덱싱에 특화되어 있다. 다양한 데이터 소스(PDF, DB, API 등)에 대한 커넥터를 기본 제공하며, 복잡한 쿼리 엔진(Sub-Question, Router 등)을 지원한다.
출처: LlamaIndex 공식 문서 (https://docs.llamaindex.ai)
2주차 과제를 RAG로 접근한다면
| 구분 | Before (2주차) | After (RAG) |
|---|---|---|
| 데이터 제공 | 의료급여 표 전체를 system prompt에 수동 삽입 | 의료급여 문서를 청킹 + 벡터화하여 저장 |
| 질문 처리 | 항상 전체 표를 context로 사용 | 질문과 관련된 부분만 자동 검색 |
| 확장 시 | 새 문서 추가 시 프롬프트 수동 수정 | 새 문서를 벡터 저장소에 추가하면 끝 |
| 토큰 비용 | 매 요청마다 전체 표의 토큰 비용 발생 | 관련 청크만 포함하여 토큰 절약 |
RAG의 발전과 한계
RAG의 진화 방향
Gao et al. (2024)의 서베이 논문은 RAG의 발전 단계를 세 가지로 분류한다.

출처: Gao et al., "Retrieval-Augmented Generation for Large Language Models: A Survey", 2024 (arXiv:2312.10997)
Naive RAG
단순한 검색 -> 생성 파이프라인이다. 이 발표에서 다룬 기본 구조가 여기에 해당한다.
- 한계: 검색 정밀도/재현율 부족, 불필요한 문서가 포함되거나 필요한 문서가 누락될 수 있음
Advanced RAG
Naive RAG의 한계를 보완하기 위해 검색 전/후에 추가 처리를 도입한다.
- 검색 전 (Pre-Retrieval): 쿼리 확장(query expansion), 쿼리 재작성(query rewriting), HyDE(Hypothetical Document Embeddings)
- 검색 후 (Post-Retrieval): 재순위화(re-ranking), 압축(compression), 필터링
Modular RAG
독립적 기능 모듈(검색, 메모리, 융합, 라우팅, 스케줄링 등)을 자유롭게 조합하는 유연한 구조다. 파이프라인이 고정되지 않고, 태스크에 맞게 모듈을 교체하거나 추가할 수 있다.
RAG의 한계
| 한계 | 설명 |
|---|---|
| 검색 품질 의존 | 잘못된 문서가 검색되면 답변도 틀림 (garbage in, garbage out) |
| 청킹 전략 민감도 | 청크 크기, overlap, 분할 방식이 결과에 큰 영향 |
| 멀티모달 한계 | 이미지, 표, 차트 등 비텍스트 데이터 처리가 어려움 |
| 추론 한계 | 여러 문서에 걸친 복합 추론(multi-hop reasoning)이 어려움 |
- RAG 파이프라인 직접 구현 실습
- Advanced RAG 기법 (re-ranking, query rewriting) 적용
- Agent와 RAG의 결합: Agentic RAG (LLM이 검색 전략을 스스로 결정)
참고문헌
논문
- Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V., Goyal, N., ... & Kiela, D. (2020). "Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks". NeurIPS 2020. https://arxiv.org/abs/2005.11401
- Gao, Y., Xiong, Y., Gao, X., Jia, K., Pan, J., Bi, Y., Dai, Y., Sun, J., & Wang, H. (2024). "Retrieval-Augmented Generation for Large Language Models: A Survey". https://arxiv.org/abs/2312.10997
- Reimers, N. & Gurevych, I. (2019). "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks". EMNLP 2019. https://arxiv.org/abs/1908.10084
- Johnson, J., Douze, M., & Jegou, H. (2017). "Billion-scale similarity search with GPUs". IEEE Transactions on Big Data. https://arxiv.org/abs/1702.08734
- Gunther, M., Mohr, I., Williams, D., Wang, B., & Xiao, H. (2024). "Late Chunking: Contextual Chunk Embeddings Using Long-Context Embedding Models". https://arxiv.org/abs/2409.04701
- Singh, R. et al. (2024). "ChunkRAG: Novel LLM-Chunk Filtering Method for RAG Systems". https://arxiv.org/abs/2410.19572
공식 문서
- LangChain Documentation. https://docs.langchain.com
- LlamaIndex Documentation. https://docs.llamaindex.ai
- OpenAI Embeddings Guide. https://platform.openai.com/docs/guides/embeddings
- Anthropic Contextual Retrieval https://www.anthropic.com/engineering/contextual-retrieval
- Anthropic Cookbook https://platform.claude.com/cookbook/capabilities-contextual-embeddings-guide
![[AI Agent] Prompt Engineering 리뷰(2주차)](https://images.unsplash.com/photo-1704965021000-dab5ec30ac7e?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDN8fFByb21wdHxlbnwwfHx8fDE3NzQ2MTc0ODJ8MA&ixlib=rb-4.1.0&q=80&w=960)
![[AI Agent 과정 1기] LLM 기초 정리](https://images.unsplash.com/photo-1677442135703-1787eea5ce01?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDh8fEFJJTIwQWdlbnR8ZW58MHx8fHwxNzc0MDUwNDA2fDA&ixlib=rb-4.1.0&q=80&w=960)
![[LLM] VLM으로 표를 정확히 추출하기](https://images.unsplash.com/photo-1623667322051-18662ce6334c?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDl8fHBkZnxlbnwwfHx8fDE3NzIzNzMzODN8MA&ixlib=rb-4.1.0&q=80&w=960)
![[RAG] 한국어 Reranker 모델을 사용하여 RAG 성능 올리기](https://images.unsplash.com/flagged/photo-1578928534298-9747fc52ec97?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDF8fFJhbmtpbmd8ZW58MHx8fHwxNzU0MTM3OTQ4fDA&ixlib=rb-4.1.0&q=80&w=960)