[AI Agent] LLM Evaluation Preview (5주차)
LLM/RAG 시스템의 품질을 숫자로 증명하는 평가 체계를 소개합니다. Golden Dataset, Calibration Dataset, LLM-as-a-Judge, RAGAS 메트릭을 통해 감에 의존하는 평가에서 데이터 기반 의사결정으로 전환하는 방법을 다룹니다.
![[AI Agent] LLM Evaluation Preview (5주차)](https://images.unsplash.com/photo-1644574141709-c739285ae771?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDE5fHxFdmFsdWF0aW9ufGVufDB8fHx8MTc3NjQzMTkyNXww&ixlib=rb-4.1.0&q=80&w=1200)
개요
5주차에서는 "내가 만든 LLM/RAG 시스템이 정말 잘 동작하는가"를 어떻게 확인할 것인가를 다룹니다.
3주차의 Golden Dataset과 4주차의 Advanced RAG 개선 기법들은 모두 "더 좋아졌다"고 말할 수 있을 때 의미가 생깁니다. 그 "더 좋아졌다"를 숫자로 증명하는 방법이 바로 평가(Evaluation)입니다.
이번 Preview는 평가의 전체 지도를 쉬운 수준에서 훑는 것이 목표입니다.
- 평가가 왜 필요한가
- 어떤 데이터셋을 준비해야 하는가 (Golden vs Calibration 중심)
- 어떻게 평가하는가 (LLM-as-a-Judge 기본)
- RAG 시스템은 무엇을 측정해야 하는가 (RAGAS)
- 실무에서 쓰이는 평가 도구들
각 주제는 5주차 Review에서 더 깊이 다룰 예정입니다.
왜 평가가 필요한가
RAG 시스템을 만들다 보면 이런 상황이 반복됩니다.
- 검색 방식을 바꿨는데 어떤 질문은 좋아지고 어떤 질문은 나빠졌다
- 프롬프트를 튜닝했더니 전과 다른 스타일로 답하는데, 이게 더 나은 건지 모르겠다
- 모델을 GPT-4o에서 Claude로 바꿨는데 체감상 비슷한 것 같다
- 고객이 "옛날엔 이런 답을 잘하던데 요즘 이상하다"고 한다
평가 없이는 이 모든 질문에 대한 답이 감에 의존합니다. 몇 가지 예시를 돌려보고 "좋아진 것 같다"고 말하는 방식이죠. 문제는 LLM이 비결정적이라는 점입니다. 같은 질문을 두 번 던져도 답이 다르고, 10개 예시 중 7개가 좋아졌어도 나머지 3개가 심각하게 나빠졌다면 전체적으로는 손해입니다.
평가는 이 감을 숫자와 데이터로 대체합니다.
- 회귀 탐지: 모델·프롬프트·검색기를 바꿨을 때 "어디가 나아졌고 어디가 나빠졌는지" 알려준다
- 개선 증명: "검색기에 BM25를 추가했더니 Context Recall이 0.68 → 0.82로 올랐다"처럼 기여도를 수치로 말할 수 있다
- 배포 의사결정: 이 버전이 프로덕션에 나가도 되는지 자동으로 판단한다
2024–2026년 사이 LLM-as-a-Judge, RAGAS 같은 도구들이 성숙하면서 평가는 "한두 개 예시로 대충 보는 일"이 아니라 개발 파이프라인에 자동으로 통합되는 엔지니어링 문제가 됐습니다.
실무에서 평가 체계를 갖춘 팀과 그렇지 않은 팀의 차이는, "바꾼 뒤에 뭐가 나빠졌는지 말할 수 있느냐" 한 문장으로 갈립니다.
어떤 데이터셋을 준비해야 하는가
평가를 시작할 때 가장 먼저 마주치는 질문은 "뭘 가지고 평가하지?"입니다.
용어가 혼란스러운데, 영문 자료에서도 Golden / Calibration / Evaluation / Benchmark가 섞여 쓰입니다. 각각은 목적과 규모가 다른 별개의 자산이며, 특히 Golden Dataset과 Calibration Dataset의 역할은 정반대에 가깝습니다.
네 가지 데이터셋 한눈에 비교
| 구분 | 목적 | 전형적 규모 | 구축 방법 |
|---|---|---|---|
| Golden Dataset | 프로덕션 품질 회귀 테스트 | 50–500개(성숙 제품 1K+) | 전문가가 실제 트레이스·버그 케이스에서 수작업 큐레이션 |
| Calibration Dataset | LLM 평가자가 사람 판단과 일치하는지 검증 | 50–200개(작게 유지) | 다양한 출력을 샘플링해 사람이 라벨링 |
| Evaluation / Test Set | 개발 중 반복 실험용 | 200–2,000개 | 합성 + 실제 트레이스 혼합, 느슨한 라벨 허용 |
| Benchmark Dataset | 공개된 범용 역량 비교(MMLU 등) | 공개 규모 고정 | 연구 커뮤니티 제작, 모델 선정 시 참조용 |
Golden Dataset: 우리 시스템을 테스트하는 것
Golden Dataset은 우리 시스템(파이프라인 + 모델 + 프롬프트)이 정답을 제대로 내는지 반복 확인하는 용도입니다. 각 항목은 보통 이런 구조입니다.
- 입력 질문
- 참고 컨텍스트 또는 정답 문서
- 기대하는 답변 또는 정답 조건(예: "반드시 법조항 이름이 포함되어야 함")
핵심은 "프로덕션에서 실제로 문제였던 케이스"와 "절대 틀리면 안 되는 엣지 케이스"가 섞여 있어야 한다는 점입니다. CS에서 올라온 클레임, 내부 검토에서 걸린 오답, 도메인 전문가가 짚어준 함정 질문들을 꾸준히 추가해 수십 개에서 출발해 수백 개까지 키워갑니다. 이 자산이 쌓이면 모델이나 벤더는 바꿀 수 있어도 Golden Set은 그대로 남는 회사 자산이 됩니다.
Calibration Dataset: 평가자를 테스트하는 것
Calibration Dataset은 이름 그대로 평가자(Judge)를 보정(calibrate)하기 위한 데이터셋입니다. 뒤에서 다룰 LLM-as-a-Judge를 쓰면, 결국 "그 Judge가 사람처럼 판단하는가"라는 메타 질문이 생깁니다.
이 질문에 답하려면 사람이 직접 라벨링한 작은 데이터셋이 필요한데, 그게 바로 Calibration Set입니다.
전형적인 흐름은 이렇습니다.
- 50–200개 샘플을 뽑아 사람 2–3명이 직접 점수를 매긴다(좋음/나쁨 또는 1–5점)
- 같은 샘플을 LLM Judge에게도 채점시킨다
- 사람 점수와 LLM 점수의 일치율을 측정한다(Cohen's κ, Spearman ρ 같은 지표)
- 일치율이 기준(예: κ ≥ 0.4) 이상이면 그 Judge를 "쓸 만하다"고 판정하고, 이후 대량 평가에 투입한다
Golden은 "시스템이 정답을 맞추는가"를, Calibration은 "평가자가 사람과 같은 기준으로 채점하는가"를 검사합니다. 이 둘을 헷갈리면 편향된 평가자가 내린 편향된 점수로 배포 결정을 내리는 사고가 발생합니다.
Evaluation Set과 Benchmark
나머지 둘은 가볍게 짚고 넘어갑니다.
- Evaluation / Test Set: 개발 중에 이것저것 실험할 때 쓰는 중간 규모 데이터셋. RAGAS의
TestsetGenerator같은 합성 생성 도구로 빠르게 만들 수 있습니다. 하드 게이트가 아닌 "어느 방향이 더 좋은가"를 빠르게 보는 용도.
Benchmark Dataset: MMLU, MT-Bench, GPQA, AlpacaEval 2 같은 공개 벤치마크. 우리 제품 평가가 아니라 모델을 선정할 때 참고하는 리더보드용입니다.
실무 팁: 처음 평가 체계를 세운다면 Calibration Set 50개 + Golden Set 30–50개로 시작하는 게 현실적입니다. 규모보다 "품질 좋은 몇십 개"가 우선입니다.
어떻게 평가하는가: LLM-as-a-Judge
데이터셋을 준비했다면 다음 질문은 "누가 채점할 것인가"입니다.
왜 사람이 아니라 LLM이 채점하는가
LLM의 답변은 정답이 여러 개 존재하는 경우가 많습니다. 같은 뜻을 다른 말로 표현할 수 있고, 설명 순서가 달라도 맞을 수 있죠. 이런 답변을 과거 NLP에서 쓰던 자동 지표(BLEU, ROUGE)로 채점하면 "의미는 맞는데 단어가 다르다"는 이유로 점수가 깎입니다.
사람이 채점하면 가장 정확하지만, 문항당 수 분이 걸리고 비용도 비쌉니다. 그래서 강력한 LLM(GPT-4, Claude 등)에게 채점을 맡기는 LLM-as-a-Judge가 2023년부터 표준으로 자리 잡았습니다. Zheng et al.(2023, MT-Bench 논문)은 GPT-4 Judge가 사람과 약 80% 일치한다는 결과를 보고했는데, 이는 사람끼리의 일치율과 거의 동일한 수준입니다.
어떻게 채점을 시키는가
LLM Judge에게 채점을 시키는 가장 흔한 방식은 루브릭을 주고 점수를 매기게 하는 것입니다. 예를 들면 이런 프롬프트입니다.
아래 질문과 답변을 보고, 답변이 질문에 얼마나 정확하게 대답했는지
1부터 5점 사이로 평가해주세요.
- 5점: 완벽하게 정확하고 필요한 정보를 모두 포함
- 3점: 핵심은 맞지만 일부 정보 누락
- 1점: 질문과 무관하거나 틀린 답변
질문: {question}
답변: {answer}
점수:
이 외에도 두 답변을 비교해 어느 쪽이 더 좋은지 고르게 하거나(쌍대 비교), 정답이 있는 경우 정답과 비교하게 하는 방식이 있습니다.
LLM Judge의 함정
편리한 만큼 함정도 있습니다.
LLM Judge는 같은 모델이 쓴 답변을 후하게 평가하거나, 먼저 제시된 답변을 선호하거나, 긴 답변을 더 좋다고 평가하는 편향을 가집니다. 실무에서는 이를 완화하기 위해 생성과 평가에 다른 모델 패밀리를 쓰거나(GPT가 생성하면 Claude가 평가), 답변 위치를 스왑해서 평균을 내거나, 복잡한 기준을 단순한 단일 기준 여러 개로 쪼개는 방식을 씁니다.
편향 각각에 대한 자세한 이야기는 5주차 본편에서 다룰 예정입니다.
한 줄 요약: 편리한 LLM Judge를 쓰되, Calibration Set으로 Judge 자체의 품질을 주기적으로 점검한다.
RAG 시스템은 무엇을 측정해야 하는가: RAGAS
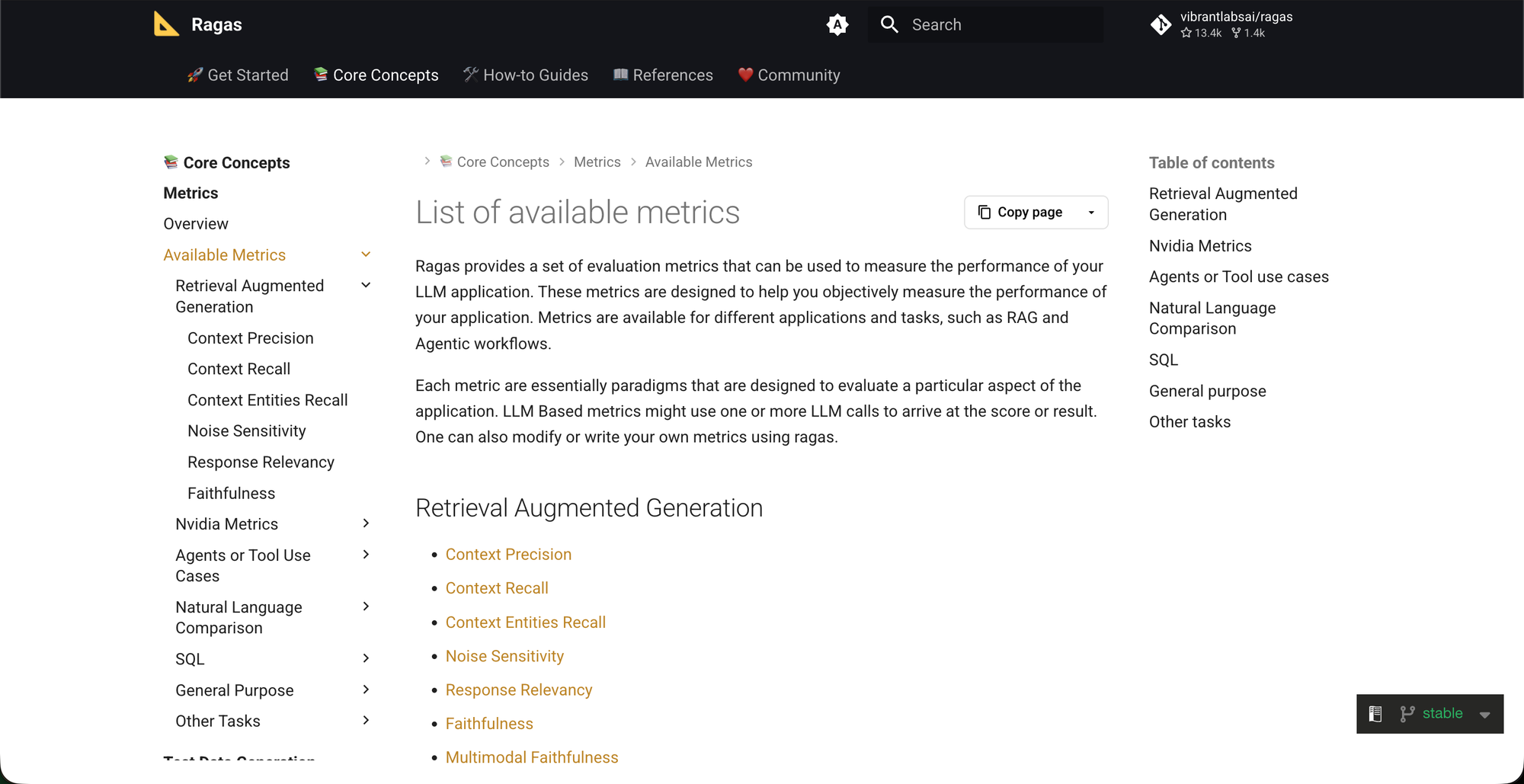
일반 LLM 평가에서 한 걸음 더 들어가면, RAG 시스템은 구조상 "검색이 잘 되었는가"와 "검색 결과를 바탕으로 잘 답했는가"가 분리됩니다. 답변 품질만 보면 문제가 어디서 터졌는지 알 수 없습니다. 이 분해를 가장 잘 정리한 프레임워크가 2023년 등장한 RAGAS(Es et al., arXiv:2309.15217)입니다.
RAGAS 핵심 메트릭
| 메트릭 | 측정 단계 | 직관적 의미 | 정답 필요? |
|---|---|---|---|
| Faithfulness | Generation | 답변의 주장이 검색된 컨텍스트로 뒷받침되는가 (환각 여부) | 불필요 |
| Answer Relevancy | Generation | 답변이 실제로 질문에 답하고 있는가 | 불필요 |
| Context Precision | Retrieval | 검색된 청크 중 관련 있는 것의 비율과 순서 | 필요 |
| Context Recall | Retrieval | 정답에 필요한 내용이 컨텍스트에 모두 들어왔는가 | 필요 |
| Answer Correctness | End-to-End | 정답과 비교했을 때의 정확도 | 필요 |
이 메트릭들의 강점은 어느 단계가 문제인지 진단이 된다는 점입니다.
- Context Recall이 낮으면 → 검색기가 정답 청크를 못 가져오고 있음. 청킹 전략이나 Hybrid Search를 검토 (4주차 Retrieval 단계).
- Context Precision이 낮으면 → 정답 청크는 들어왔지만 순서가 밀려 있음. Reranker 도입을 검토.
- Faithfulness가 낮으면 → 검색은 됐는데 LLM이 컨텍스트를 무시하고 환각 중. 프롬프트나 모델을 검토.
- Answer Relevancy가 낮으면 → 질문 자체를 잘못 이해했을 가능성. Query 변환(HyDE, Step-back) 검토.
즉, RAGAS 메트릭이 4주차에서 다룬 Query–Retrieval–Generation 개선 기법을 어떤 순서로 적용해야 하는지 알려주는 나침반이 됩니다.
- 프롬프트의 문제인지, 데이터셋의 문제인지, 모델의 한계인지 파악 가능
어떤 수치를 목표로 해야 하나
정답은 도메인마다 다르지만, 흔히 쓰이는 출발점 기준은 다음과 같습니다.
- Faithfulness ≥ 0.8
- Answer Relevancy ≥ 0.75
- Context Precision ≥ 0.7
- Context Recall ≥ 0.75
이 선을 넘지 못하는 버전은 프로덕션에 올리지 않는다는 "최소 임계값"으로 운영하고, 실제 프로덕션 트래픽에서 드러나는 문제를 보면서 도메인별로 조정해 나갑니다.
RAGAS 외에도 DeepEval, TruLens(RAG Triad로 같은 개념을 재포장) 같은 대안이 있습니다. 프레임워크는 취향이지만, 메트릭을 Retrieval 단계와 Generation 단계로 분리해서 측정한다는 원칙은 모두 같습니다.
최소 임계값은 도메인별로 설정합니다.
예를 들어 환각이 절대 발생하면 안되는 의료, 금융 챗봇이라면 검색이 실패하더라도 Faithfulness를 100% 가까이 만들 필요가 있습니다. 하지만 그 외 CS센터, 사내 챗봇은 AI의 환각을 발생시키더라도 검색 결과를 출력할 필요가 있습니다.
실무에서 쓰이는 평가 도구들
지금까지 다룬 데이터셋 준비, LLM-as-a-Judge 채점, RAG 메트릭 계산을 직접 구현하지 않아도 되도록 도와주는 도구들이 성숙해 있습니다.
2025–2026년 기준으로 자주 쓰이는 것들입니다.
| 도구 | 성격 | 주요 용도 |
|---|---|---|
| RAGAS | OSS 파이썬 라이브러리 | RAG 5대 메트릭 계산, 합성 테스트셋 생성 |
| DeepEval | OSS, pytest 네이티브 | 60+ 메트릭, 테스트 코드처럼 평가 작성 |
| Promptfoo | OSS CLI + YAML | 프롬프트 회귀 테스트, GitHub Action 연동 |
| LangFuse | OSS + SaaS | 프로덕션 트레이스 관측 + 실험 추적 |
| LangSmith | SaaS | LangChain/LangGraph 생태계 평가 |
선택 기준은 단순합니다.
- RAG RAGAS — 10분 안에 Faithfulness/Context Recall을 돌릴 수 있다
- pytest 스타일로 테스트 코드처럼 쓰고 싶다면 DeepEval
- 프롬프트 회귀를 CI에 붙이고 싶다면 Promptfoo
- 프로덕션 트래픽 관측이 같이 필요하다면 LangFuse나 LangSmith
결국 이 도구들은 모두 "Golden Dataset 위에서 메트릭을 자동 계산하고, 임계값을 넘으면 통과"라는 동일한 패턴을 따릅니다. 5주차 본편에서 이 패턴을 실제 코드로 붙여보는 실습을 다룰 예정입니다.
도구에 너무 오래 붙잡히지 마세요. 평가 품질의 80%는 "얼마나 잘 만든 Golden/Calibration 데이터셋이 있는가"에서 결정됩니다.
특히 AI에서는 100%란 불가능합니다. Trade off가 존재하며 실제 Production에서 예상치 못한 품질 이슈를 경험할 수 있습니다.
5주차에서 기대하는 것
이번 Preview에서는 평가의 전체 지도를 다음 순서로 훑었습니다.
- 평가가 왜 필요한가 (감이 아니라 숫자로)
- 어떤 데이터셋을 준비하는가 (Golden vs Calibration 중심)
- 어떻게 채점하는가 (LLM-as-a-Judge 기본)
- RAG는 무엇을 측정하는가 (RAGAS 5대 메트릭)
- 실무 도구 선택 가이드
5주차 본편에서는 이 지도를 기반으로 다음을 한 단계 더 깊이 다룰 예정입니다.
- RAGAS와 DeepEval을 실제로 돌려 메트릭 숫자를 뽑아보는 실습
- LLM-as-a-Judge 프롬프트 설계와 편향 완화 기법
- Golden/Calibration Dataset을 어떻게 구축하는가
- 간단한 CI 파이프라인에 평가 연결하기
3주차 Golden Dataset과 4주차 Advanced RAG 기법들이 평가라는 공통 언어 위에서 만나, 프로덕션 레벨 LLM 시스템을 지속적으로 개선하는 엔진이 됩니다.
![[AI Agent] AI Engineering Review (12주차)](https://images.unsplash.com/photo-1531262951893-05a0ffb31b27?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDN8fGZpbmFsfGVufDB8fHx8MTc4MTkxNDI0MXww&ixlib=rb-4.1.0&q=80&w=960)
![[AI Agent] LLM Evaluation Review (5주차)](https://images.unsplash.com/photo-1607296393394-6e25d0fc15cc?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDV8fFNhbWV8ZW58MHx8fHwxNzc3MDczMjgwfDA&ixlib=rb-4.1.0&q=80&w=960)
![[AI Agent] Advanced RAG 리뷰(4주차)](https://images.unsplash.com/photo-1605701250441-2bfa95839417?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDI5fHxSZWluZm9yY2V8ZW58MHx8fHwxNzc2NDMxODE2fDA&ixlib=rb-4.1.0&q=80&w=960)
![[AI Agent] Advanced RAG Preview(4주차)](https://images.unsplash.com/photo-1608741869829-8eb30661c7be?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDd8fEFkdmFuY2V8ZW58MHx8fHwxNzc1MjYyODcxfDA&ixlib=rb-4.1.0&q=80&w=960)