[AI Agent] LLM Evaluation Review (5주차)
생성형 AI 시대, 데모 제작은 빨라졌지만 검증 체계 구축이 더 중요해졌습니다. Golden Dataset, LLM-as-a-Judge, RAGAS를 활용한 체계적 평가 방법으로 RAG 시스템의 검색과 생성을 분리 평가하고, 평균이 아닌 실패 패턴 분석으로 운영 가능한 구조를 설계하세요.
![[AI Agent] LLM Evaluation Review (5주차)](https://images.unsplash.com/photo-1607296393394-6e25d0fc15cc?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDV8fFNhbWV8ZW58MHx8fHwxNzc3MDczMjgwfDA&ixlib=rb-4.1.0&q=80&w=1200)
검증의 시대
생성형 AI 덕분에 많은 것이 쉬워졌습니다.개념 습득, 데모 제작 모두 빨라졌습니다.
반나절이면 뭐라도 돌아가는 것을 만들 수 있는 시대입니다.
문제는 그다음입니다.
PoC를 만들 수 있다는 것과, 그 시스템을 실제로 믿고 운영할 수 있다는 것은 완전히 다른 이야기입니다. 슬라이드는 깔끔하고, 데모도 돌아갑니다. 그런데 "어떻게 검증했는가"를 묻는 순간 말이 막히는 사례를 자주 봅니다. 실패를 어떻게 재현하는지, 환각은 어떤 기준으로 거르는지, 운영 중 무엇을 품질 기준으로 삼는지까지 답할 수 있는 경우는 드뭅니다.
- 최근의 면접관으로 참여하면서 만들었을 뿐 실제로 검증하는 사람은 없습니다.
시장에 쉬운 PoC가 넘치기 시작하는 순간부터, 차별점은 "보여주는 능력"에서 "검증하고 설명하는 능력"으로 넘어갑니다.
도입하는 쪽도 이제는 데모 품질보다 검증 체계 품질을 어떻게 세웠는지 확인해야합니다.
"PoC 비용은 폭락했고, 검증 비용은 폭등."
간단하게 수학 책이라고 예시를 들면, 단순히 수학 문제만 잘 만드는 것이 중요한게 아닙니다.
정답지와 명확한 해설을 줄 수 있어야 비로소 더 양질의 문제만 담을 수 있습니다.
Evaluation이란?
간단하게 정리해보면 "잘 되는 것 같다"는 감각을 버려야 합니다.
무엇이 좋아졌고 무엇이 여전히 취약한지 설명해야 합니다. Advanced RAG가 좋아 보인다는 인상만으로는 부족합니다. 어느 메트릭이 왜 올라갔는지, 어떤 질문 유형에서 흔들리는지, 검색이 문제인지 생성이 문제인지 나눠 봅니다.
이 지점부터 RAG는 데모가 아니라 시스템으로 보이기 시작합니다.
LLM으로 테스트 데이터셋을 만들고 LLM으로 검증하신 분들이 많을거같은데 이를 어떻게 체계화하는지 리뷰하는 내용입니다.
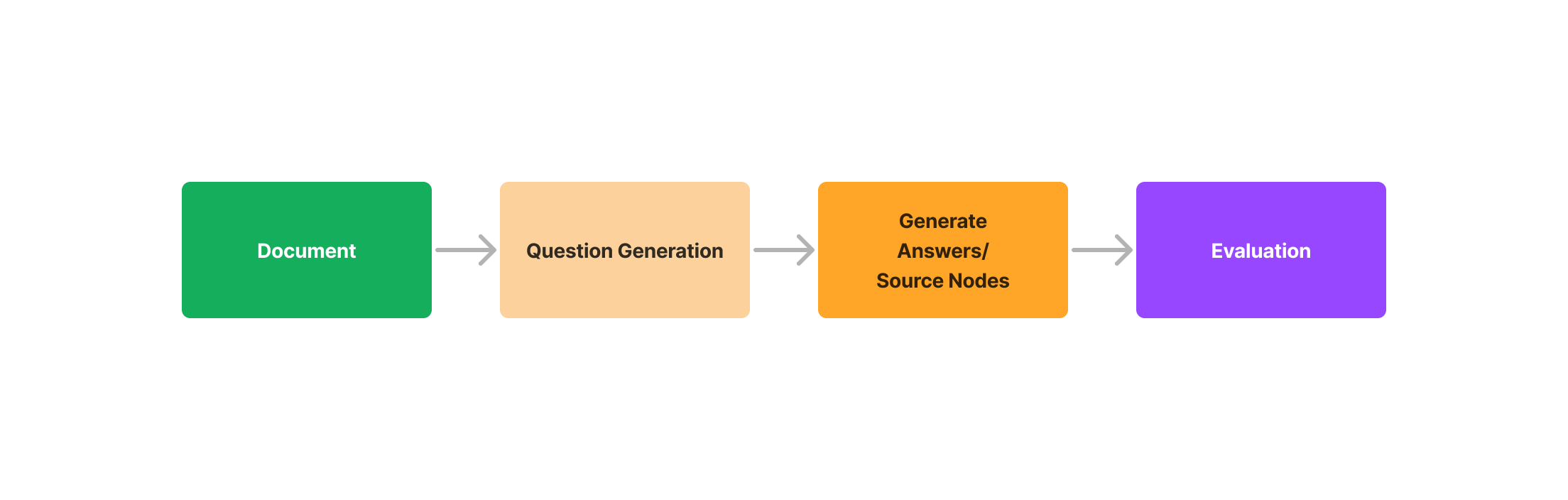
평가는 LLM 애플리케이션이 얼마나 잘 작동하는지를 정량화하는 일입니다. LLM 애플리케이션은 여러 단계로 이루어져 있기 때문에, 효과적인 평가는 시스템을 검색, 생성, 도구 사용, 포맷팅 같은 구성 요소로 나누고 각각을 독립적으로 평가합니다.
LangSmith — Evaluation Concepts

"시스템을 쪼개서 각각 따로 평가한다." 말은 단순한데 손에 잡고 해보면 단순하지 않습니다.
5주차가 어려운 이유는 여기에 있습니다. 이렇게 검색과 생성을 나눠 평가하려면, 먼저 정답과 근거가 포함된 평가용 기준 데이터셋이 필요합니다.
Golden Dataset을 만드는 방법
골든 데이터셋을 간단하게 정리해보겠습니다.
- AI 모델의 성능을 정확하게 측정하고 평가하기 위해 검증된, 정답(Ground Truth)이 포함된 고품질의 참조 데이터셋
데이터셋을 만드는 방법에 대해 조금 더 자세히 확인해보겠습니다.
데이터 구조
4주차 Dataset은 expected_answer 하나였습니다. 이번 주 과제는 여기에 두 필드를 추가합니다. ground_truth와 ground_truth_contexts입니다.
왜 ground_truth와 ground_truth_contexts를 분리해야 하는가를 살펴보면…
ground_truth만 있고ground_truth_contexts가 없으면- 답이 틀렸다는 사실은 보여도
- 검색이 실패했는지, 생성이 실패했는지는 흐려집니다.
ground_truth_contexts까지 있으면- 근거가 검색되지 않은 경우는 retrieval 문제
- 근거는 검색됐는데 답이 틀린 경우는 generation 문제
- retrieval/generation을 분리해서 개선할 수 있습니다.

데이터 채우기
이렇게 어떤 구조를 만들어야하는지 정리했다면 구조대로 데이터를 채우는 방법은 여러 가지입니다.
전문가 수동 라벨링
가장 정석이고, 고위험(법률, 의료 등) 도메인에서 사용하는 방식입니다.
전문가가 기준을 만들고, 1차 라벨러가 작업하고, 전문가가 리뷰/판정하는 구조
- 평가 범위와 라벨 기준 정의
- 샘플 수집 / 큐잉
- 파일럿 라벨링
- 1차 라벨링
- 리뷰 / adjudication
- 버전 고정
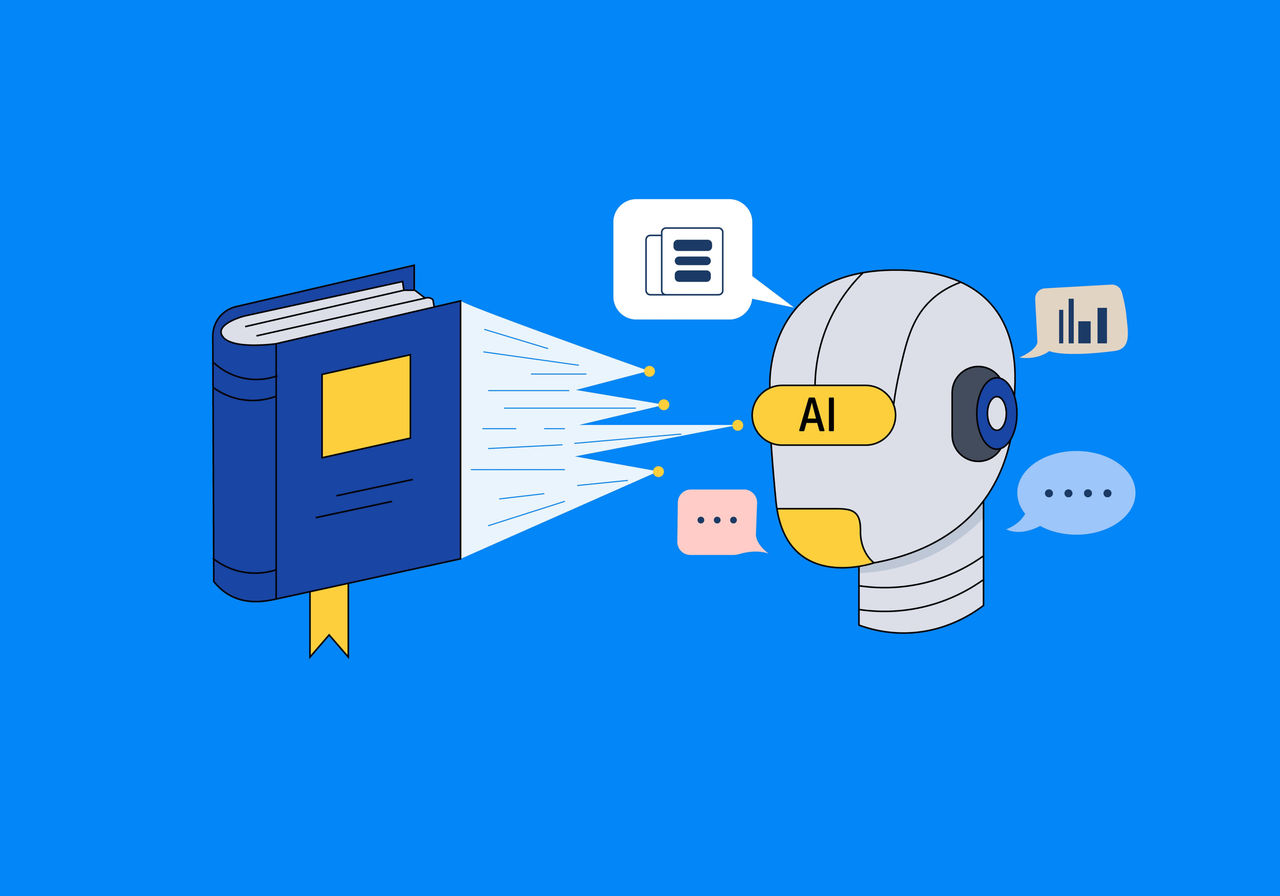
문서 참조 합성 데이터 생성
수작업만으로는 규모 확장이 어렵기 때문에 가장 널리 쓰이는 보조 수단입니다.
AI가 데이터를 참고하여 Q&A Pair를 생성하는 생성 방식입니다.
LlamaIndex 역시 문서에서 question / answer pair를 생성하는 dataset generation 기능을 제공합니다.
from llama_index.evaluation import DatasetGenerator
from llama_index import SimpleDirectoryReader
# Load documents
reader = SimpleDirectoryReader("./data")
documents = reader.load_data()
# Generate Question
data_generator = DatasetGenerator.from_documents(documents)
question = data_generator.generate_questions_from_nodes()
장점
- 빠르게 대량 샘플을 만들 수 있습니다.
- 한 가지 정보만 참조(single-hop), 여러가지 정보를 참조(multi-hop), 해석이나 추상적인 질문(abstract question)을 섞어 난이도 분포를 넓히기 쉽습니다.
- 수작업 시드가 적어도 초안 풀(pool)을 빠르게 확보할 수 있습니다.
한계
- 쉬운 질문, 교과서적 질문으로 편향되기 쉽습니다.
- 정답은 맞아 보여도 근거 문단 지정이 부정확할 수 있습니다.
- 문서의 문장을 거의 베껴 질문으로 만드는 leakage성 샘플이 생깁니다.
- 사람 검증이 없으면 golden dataset이라고 부르기 어렵습니다.
- AI 모델의 성능을 정확하게 측정하고 평가하기 위해 검증된, 정답(Ground Truth)이 포함된 고품질의 참조 데이터셋 목적
- 참고


방법 3. LLM 초안 + 사람 검수
실무에서 가장 현실적인 절충안입니다. 모델이 초안을 만들고, 사람은 승인·수정에 집중합니다.
작업 방식
- LLM이 질문, 정답 초안, 근거 후보 문단을 생성합니다.
- 사람이 질문의 유효성 / 정답의 정확성 / 근거 문단의 최소성,충분성을 확인합니다.
장점
- 순수 수동 라벨링보다 훨씬 빠릅니다.
- 합성 데이터보다 품질 통제가 쉽습니다.
- "빈 화면에서 작성"보다 "초안 수정"이 빠릅니다.
한계
- 초안을 너무 신뢰하면 검수 강도가 약해집니다.
- 모델이 만든 오류를 사람이 그대로 통과시키는 automation bias가 생길 수 있습니다.
- 맞는 내용인데 사람이 틀리다고 분류 / 틀린 내용인데 사람이 맞다고 분류
이런 작업을 위한 오픈소스도 존재합니다.

실무 권장 전략
완전 수동이나 완전 합성 한쪽으로 치우치기보다 아래 조합이 현실적입니다.
- 핵심 intent 30~50개는 전문가가 직접 라벨링합니다.
- 수작업 시드를 기준으로 합성 질문을 생성해 3~5배 확장합니다.
- 운영 로그에서 실패 질문을 지속적으로 추가합니다.
- LLM이 정답과 근거 초안을 만들고 사람이 승인·수정합니다.
- 액티브 러닝으로 다음 검수 대상을 우선순위화합니다.
- 현재 모델이 가장 불확실한 질문
- retriever와 generator 결과가 엇갈리는 질문
- 모델 버전 간 점수 차가 큰 질문
- 도메인상 중요하지만 실패 비용이 큰 질문
LLM-as-a-Judge
- 평가 방식 3가지
- 코드, 사람, LLM 평가
- 코드는 수학 문제의 정답만 비교할 수 있지만 풀이 과정은 비교하기 어려움
- 사람은 과정과 정답을 명확하게 판단할 수 있지만 너무 비쌈
- LLM 기반으로 사람의 기준을 대용량으로 평가 가능
- 코드, 사람, LLM 평가
골든 데이터셋은 평가의 기준선이고 실제 점수와 판정으로 연결하는 방법 중 하나가 LLM-as-a-Judge입니다.
RAGAS를 통해 LLM as a Judge를 수행했습니다.
from ragas.dataset_schema import SingleTurnSample
sample = SingleTurnSample(
# Golden dataset -> 예상 답변과 청크, 입력
user_input=golden_row["question"],
reference=golden_row["ground_truth"],
reference_contexts=golden_row["ground_truth_contexts"],
# 실제 모델이 수행한 결과
response=run_result["answer"],
retrieved_contexts=run_result["contexts"],
)





표를 보기 전에 지표 이름부터 간단히 풀어보겠습니다.
Context Recall- 질문에 답하는 데 필요한 근거를 검색 결과가 얼마나 빠짐없이 가져왔는지를 보는 지표입니다.
- 쉽게 말하면 "필요한 자료를 놓치지 않았는가"에 가깝습니다.
- 정답 근거 청크가 10개 있어야 하는데 6개만 찾았다 -> Recall = 6/10 = 0.6
Context Precision- 검색해 온 청크들 중 실제로 답변에 도움이 되는 청크의 비율이 얼마나 높은지를 보는 지표입니다.
- 쉽게 말하면 "쓸모 있는 자료 위주로 가져왔는가"에 가깝습니다.
- 찾은 청크가 8개인데 그중 6개만 실제로 관련 있다 -> Precision = 6/8 = 0.75
Faithfulness- 생성된 답변이 검색된 근거를 벗어나지 않고, 근거 안에서 말하고 있는지를 보는 지표입니다.
- 쉽게 말하면 "없는 말을 지어내지 않았는가"입니다.
Correctness- 최종 답변이 기준 정답(
ground_truth/reference)과 실제로 맞는지를 보는 지표입니다. - 쉽게 말하면 "최종 답이 맞았는가"입니다.
- 최종 답변이 기준 정답(
평가 지표를 하나만 두고 개별적으로 확인하는 건 위험합니다
| 패턴 | 해석 | 다음 수 |
|---|---|---|
| Context Recall 높음 + Correctness 낮음 | 필요한 근거는 검색됐는데 생성이 실패 | 프롬프트·모델·포맷부터 의심합니다 |
| Context Recall 낮음 + Faithfulness 높음 | 근거를 충분히 못 찾았지만 없는 말은 안 지어냄 | 검색 단계 개선이 먼저입니다 |
| Faithfulness 높음 + Correctness 낮음 | 근거 안에서 말했는데 정답과 다름 | ground_truth 품질 또는 질문 조건 부족을 의심합니다 |
| Context Precision 높음 + Context Recall 낮음 | 상위 청크는 관련 있지만 결정적 정보가 빠짐 | Top-K 확대, 메타데이터 필터를 재검토합니다 |
| 전 메트릭이 평탄하게 중간값 | Dataset이 쉬운 경우가 대부분 | 어려운 질문을 더 투입합니다 |
Metric(수치) 하나만 보는 것보다 전체 관계로 보는 것이 중요합니다.
LLM as a Judge의 한계 (편향 / bias)
지금까지 문제지의 답지를 만드는 방법과 답지로 문제를 채점자와 채점할 때 봐야하는 수치들에 대해서 설명드렸습니다.
- 과정은 맞췄는데 답변은 틀렸다던지, 과정과 답변 자체가 틀렸는지, 옳은 지문과 공식을 참고했는지 등
하지만 당연하게도 LLM 평가(채점)에도 한계가 존재합니다. 바로 편향입니다.

또한 당연하게도 해당 메트릭으로 모든 것을 판단할 수 없죠.
년도 혼동은 기본 메트릭으로는 직접 잡히지 않습니다. "2025년 본인부담금"을 묻고 답이 2026년 값이어도, Faithfulness는 2026년 청크를 근거로 높게 나옵니다. Answer Correctness만 낮아집니다. 문제의 원인이 "년도 판별"에 있다는 정보는 메트릭 이름 어디에도 없습니다.
그래서 도메인 특화 커스텀 메트릭이 필요해집니다. 5주차 심화 과제의 YearAccuracy가 여기에 해당합니다.
https://docs.ragas.io/en/stable/howtos/customizations/metrics/write_your_own_metric/
장황함, 톤 일관성 같은 주관적 품질도 기본 메트릭은 잡지 못합니다. 도메인 임계값을 정하거나 커스텀 메트릭을 붙여야 합니다. "Ragas를 켰으니 평가가 끝났다"가 가장 위험한 착각입니다.
실무에서는?
이 글의 본편입니다. 블로그가 가볍게 지나간 영역이자, 실무 사고가 가장 자주 나는 지점입니다. 평가를 시작하면 사람은 숫자를 믿고 싶어집니다. 숫자가 생기면 시스템이 통제 가능한 상태처럼 느껴지기 때문입니다. 그러나 점수는 언제나 일부만 보여줍니다.
- Faithfulness 0.9여도 답은 불완전할 수 있습니다. 근거 안에서만 말했지만 사용자가 필요로 했던 조건을 빠뜨렸을 수 있습니다.
- 또한 의료, 법률, 금융 도메인에서는 0.9조차도 위험할 수 있습니다.
- Answer Relevancy가 높아도 사실이 틀릴 수 있습니다. 질문의 방향에는 맞았지만 년도·금액·대상 조건이 틀렸을 수 있습니다.
- 앞서 편향으로 계산 한계, 서로 간 편향이 발생할 수 있습니다.
- Context Precision이 높아도 Recall이 낮으면 결정적 근거 하나를 통째로 놓쳐 미탐이 발생할 수 있습니다
- 더 좋아질 수 있는데 한계가 발생할 수 있습니다.
더 위험한 것은 평균입니다. → "평균은 언제나 상황을 예쁘게 만듭니다."
서비스는 평균으로 망가지지 않습니다. 특정 실패 유형에서 망가집니다. no-answer 상황에서 무리하게 답을 만들거나, cross-year 질문에서 최신 정보를 놓치거나, 특정 문서 구조에서만 흔들리는 경우가 운영에서는 훨씬 치명적입니다.
그래서 평가는 평균보다 슬라이스가 먼저입니다. 저희는 계속해서 이 기준으로 데이터를 나누고 확인해봤는데요
| 슬라이스 축 | 보는 이유 |
|---|---|
| 난이도 (easy / medium / hard) | 쉬운 질문 평균에 속지 않기 위해서입니다 |
| 년도 (단일 / cross-year) | 최신성·혼동 문제를 분리합니다 |
| 정답 존재 여부 (정답 있음 / no-answer) | 과잉 생성·환각 유발 구간을 점검합니다 |
| 문서 구조 (표 / 서술) | 청킹 전략 약점을 노출시킵니다 |
데이터셋 자체에도 함정이 있습니다.
공개 벤치마크는 사전학습 데이터와 겹쳐 오염될 수 있고, 널리 쓰이는 벤치마크는 모델이 여기에 맞춰 최적화되면서 포화 상태에 이릅니다. Hugging Face 평가 가이드북이 이 문제를 정면으로 다룹니다.
공개 벤치마크는 모델 사전학습 데이터에 섞이면서 오염될 수 있고, 널리 알려진 벤치마크는 모델이 그것에 맞춰 최적화될수록 포화 상태에 이릅니다. 이런 두 조건 때문에 벤치마크 점수는 실제 성능을 잘못 보여줄 수 있습니다.
Hugging Face — Evaluation Guidebook

정리
평가는 AI 운영을 위한 필수적인 언어입니다.
5주차는 Ragas를 한 번 돌려보는 주차가 아닙니다.
정답률 하나로는 설명되지 않는 시스템을 어떻게 봐야 하는지 배우는 주차입니다. "좋아 보인다"는 감각을 버리고 "왜 그런 결과가 나왔는지"를 설명하기 시작하는 주차입니다. Golden Dataset이 그래서 중요했고, LLM-as-a-Judge가 그래서 유용했고, Ragas가 그래서 가치가 있었습니다.
더 중요한 것은 그다음입니다.
- 점수를 만드는 것보다 기준을 세우는 일이 더 어렵습니다.
- 메트릭을 읽는 것보다 실패를 해석하는 일이 더 어렵습니다.
- PoC를 만드는 것보다 운영 가능한 구조를 설계하는 일이 더 어렵습니다.
- 좋은 모델을 고르는 것보다 좋은 평가셋을 유지하는 일이 더 오래 갑니다.
참고 자료
Ragas 공식 문서
- Available Metrics
- Context Recall
- Context Precision
- Faithfulness
- Answer Relevancy
- Answer Correctness
- Test Data Generation
- Write Your Own Metric
- 한국어 프롬프트 적응
논문·가이드
- Zheng et al., 2023 — Judging LLM-as-a-Judge with MT-Bench
- Liu et al., 2023 — G-Eval
- LangSmith — Evaluation Concepts
- Hugging Face — Evaluation Guidebook
![[AI Agent] LLM Evaluation Preview (5주차)](https://images.unsplash.com/photo-1644574141709-c739285ae771?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDE5fHxFdmFsdWF0aW9ufGVufDB8fHx8MTc3NjQzMTkyNXww&ixlib=rb-4.1.0&q=80&w=960)