[RAG] 더 나은 RAG를 위해 Retrieval pipeline 개선하기
벡터 검색 품질을 향상시키기 위한 Sentence-window 청킹 방식을 테스트해보고 정리하였습니다.
![[RAG] 더 나은 RAG를 위해 Retrieval pipeline 개선하기](https://images.unsplash.com/photo-1528819622765-d6bcf132f793?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDF8fHN0cmF0ZWd5fGVufDB8fHx8MTc1NDEzNzQ2Nnww&ixlib=rb-4.1.0&q=80&w=1200)
기존 Retrieval 방식
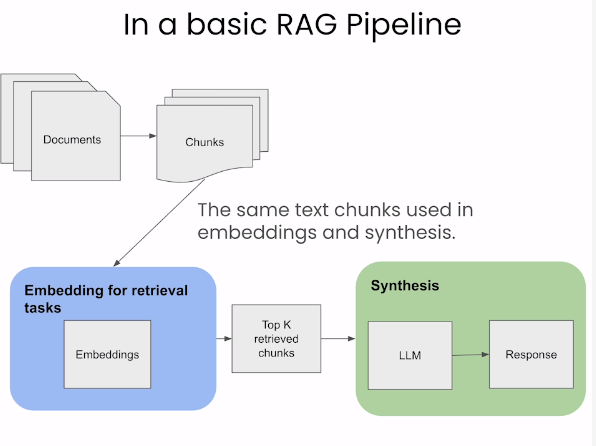
기존 RAG 방식
- Embedding과 생성에 같은 text chunk를 사용합니다.
- 작은 text-chunk에서 잘 작동하지만 LLM이 더 좋은 응답을 생성하기 위해선 더 많은 context와 큰 chunk를 필요로 합니다.
chunk를 작게 설계
- 더 작고 잘 정의된 청크는 생성 모델에 관련성이 높고 집중된 컨텍스트를 제공할 수 있습니다. 이는 검색된 정보의 정밀도가 중요한 구체적이고 좁은 쿼리에 특히 유용합니다.
- 특정 쿼리, 특히 상세하지만 압축된 정보가 필요한 쿼리의 경우 작은 청크가 더 효율적일 수 있습니다. LLM이 고려해야 할 텍스트의 양을 제한하여 계산 오버헤드를 줄입니다.
chunk를 크게 설계
- 더 큰 청크 또는 전체 문서는 더 넓은 맥락을 제공하므로 LLM이 주제의 뉘앙스와 복잡성을 더 잘 이해할 수 있습니다. 이는 정보에 대한 깊은 이해와 종합이 필요한 복잡한 쿼리에 특히 유용합니다.
- 데이터를 더 큰 청크로 유지하면 내러티브 또는 논쟁의 흐름을 유지할 수 있으며 이는 일관되고 논리적으로 구조화된 응답을 생성하는 데 중요할 수 있습니다.
Sentence-window Retrieval(context를 고려한 chunk)
Sentence-window Retrieval(SWR)은 기존 RAG에서 단일 문장으로 검색했던 방식을 문장의 window를 설정한 뒤, window를 고려하여 더 큰 맥락에서 관련 정보를 추출하는데 중점을 두는 방법입니다.근본적인 RAG 방식의 문제점인 정보의 손실은 문서가 긴 경우에 정해진 벡터의 차원으로 표현하기 어려워지는 문제를 해결할 수 있습니다.1. 문서 전처리 및 문장 분할
- 목적: 문서를 개별 문장으로 분할하여 분석의 기본 단위를 생성합니다.
- 과정: 자연어 처리(NLP) 기술을 사용하여 문서를 문장으로 분할합니다.
2. 문장 윈도우 생성
- 목적: 관련 문장들을 그룹화하여 문맥을 유지한 채로 처리합니다.
- 과정: 설정된 윈도우 크기에 따라 연속적인 문장들을 그룹화합니다. 예를 들어, 윈도우 크기가 3이라면, 각 윈도우는 연속된 3개의 문장 혹은 문단으로 구성됩니다.
3. 문장 및 문장 윈도우 벡터화
- 목적: 문장이나 문장 윈도우를 벡터 공간에 매핑하여 수치적으로 표현합니다.
- 과정: 사전 학습된 임베딩 모델을 사용하여 각 문장 또는 문장 윈도우를 고차원 벡터로 변환합니다.
4. 벡터 인덱싱
- 목적: 검색을 위한 준비 과정으로, 변환된 벡터를 인덱스에 저장합니다.
- 과정: 생성된 벡터들을 벡터 저장소에 저장하며, 이 저장소는 후속 검색 쿼리에 응답하기 위해 사용됩니다.
5. 유사성 검색 및 문장 윈도우 검색
- 목적: 특정 쿼리에 대한 가장 관련성 높은 문장 윈도우를 찾습니다.
- 과정: 사용자로부터 입력 받은 쿼리를 벡터화하고, 벡터 저장소 내에서 가장 유사한 벡터들을 검색합니다. 이 때, 코사인 유사도(cosine similarity)와 같은 유사도 측정 기법이 사용될 수 있습니다.
6. 결과 후처리 및 반환
- 목적: 검색 결과의 정확도를 높이고 사용자에게 보다 유용한 정보를 제공합니다.
- 과정: 검색된 결과에 대해 메타데이터 교체, 재정렬, 필터링 등의 후처리 작업을 수행할 수 있습니다. 이후, 최종적으로 선택된 문장 윈도우를 사용자에게 반환합니다.
기존 RAG와 주요 차이점은 청크의 세분성과 그에 따른 검색 프로세스의 초점이 다르다는 점입니다.따라서 정리하면 SWR은 더 큰 문서에서 더 세부적인 텍스트 조각, 특히 문장이나 작은 문장 창을 검색하는 데 중점을 둡니다. SWR의 목표는 쿼리와 직접적으로 관련된 문서 내에서 가장 관련성이 높은 정보를 찾아내는 것입니다. 이를 통해 LLM은 보다 집중된 상황에 집중할 수 있으며 결과의 정확성과 관련성을 잠재적으로 향상시킬 수 있습니다.
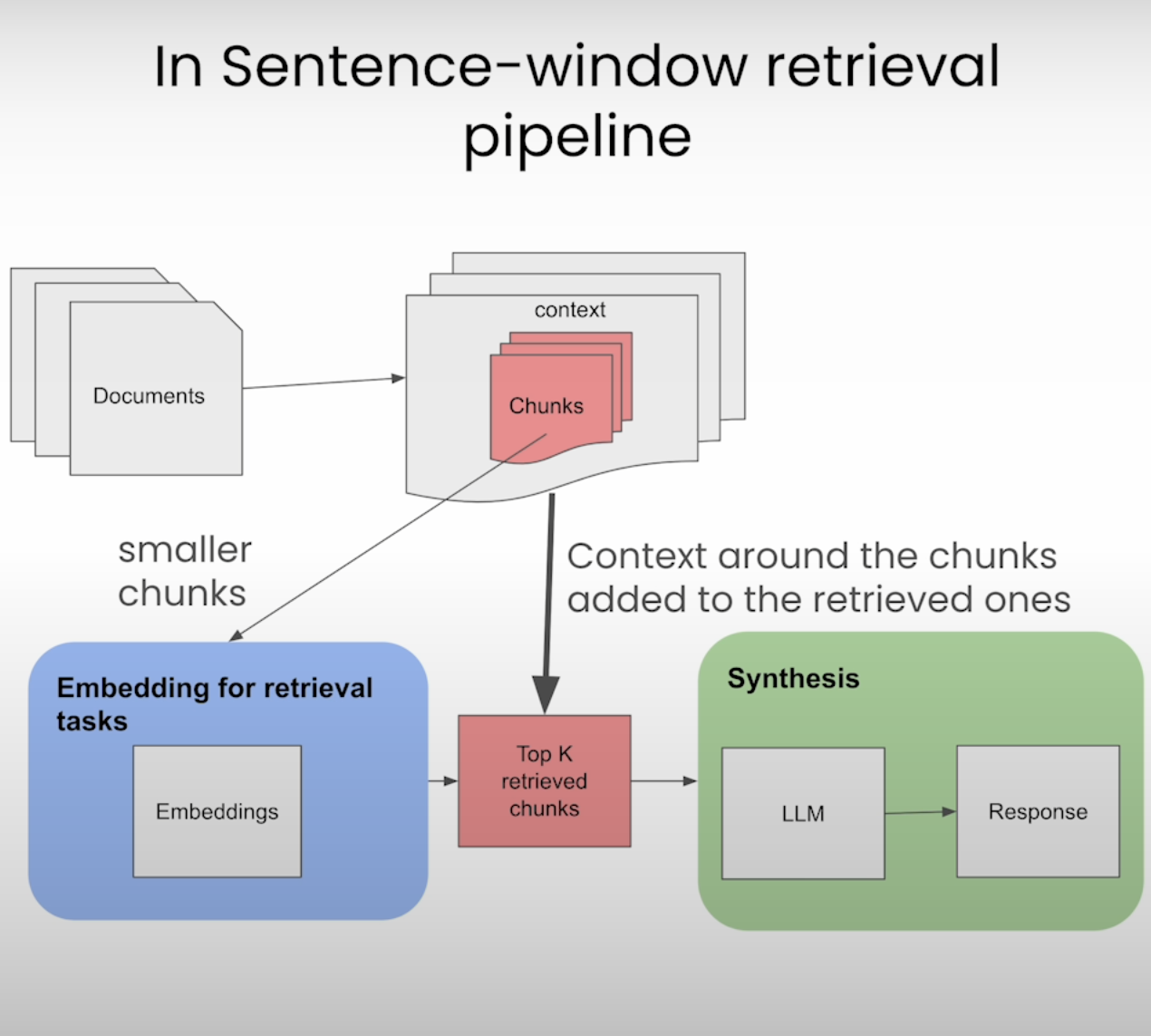
Elasticsearch 및 LlamaIndex를 활용한 Sentence-window Retrieval
- VectorDB를 위한 ElasticSearch 설치
docker run -p 9200:9200 \
-e "discovery.type=single-node" \
-e "xpack.security.enabled=false" \
-e "xpack.security.http.ssl.enabled=false" \
-e "xpack.license.self_generated.type=trial" \
docker.elastic.co/elasticsearch/elasticsearch:8.9.0- llama-index와 LLM을 위한 패키지 설치
!pip3 install llama-index llama-index-llms-bedrock elasticsearch transformers- 데이터 파싱
# pdf file을 읽기 위한 SimpleDirectoryReader
from llama_index.core import SimpleDirectoryReader, VectorStoreIndex, Document- index 생성
from llama_index.vector_stores.elasticsearch import ElasticsearchStore
vector_store = ElasticsearchStore(
es_url="http://localhost:9200",
index_name="swr_tutorial" # If this index doesn't exist, a new one is created
)- Document 파싱
# 주어진 문서를 기반으로 문장 윈도우 인덱스를 생성하는 작업을 수행합니다.
# 이 과정에서 문서 내의 문장들을 벡터 형태로 변환합니다.
# 이를 벡터 저장소(vector store)에 인덱싱하는 과정을 포함합니다.
def build_sentence_window_index(
document, llm, vector_store, embed_model=model
):
# SentenceWindowNodeParser 초기화
# 문서를 더 작고 관리 가능한 컨텍스트로 쪼개는 과정입니다.
node_parser = SentenceWindowNodeParser.from_defaults(
window_size=3,
window_metadata_key="window",
original_text_metadata_key="original_text",
)
# 문장을 벡터로 변환합니다.
sentence_context = ServiceContext.from_defaults(
llm=llm,
embed_model=embed_model,
node_parser=node_parser
)
# 벡터 저장소에 저장
storage_context = StorageContext.from_defaults(vector_store=vector_store)
sentence_index = VectorStoreIndex.from_documents(
[document], service_context=sentence_context, storage_context=storage_context
)
return sentence_index- 사용자 검색 진행 후 결과 도출
# 벡터화된 쿼리 통해 검색하여 결과를 추출하는 방식입니다.
def get_sentence_window_query_engine(
sentence_index, # 쿼리
similarity_top_k=6, # 가장 유사한 결과
rerank_top_n=2, # 유사한 결과에서 가장 높은 순위를 가져오기
):
# 각 노드의 텍스트를 window 크기로 변경합니다.
postproc = MetadataReplacementPostProcessor(target_metadata_key="window")
# 결과에 대해 순위를 재정렬합니다.
rerank = SentenceTransformerRerank(
top_n=rerank_top_n, model=model
)
sentence_window_engine = sentence_index.as_query_engine(
similarity_top_k=similarity_top_k, node_postprocessors=[postproc, rerank]
)
return sentence_window_engine- 문서를 임베딩 모델에 넣고 파싱하여 저장합니다.
sentence_index = build_sentence_window_index(
document,
llm,
embed_model=model,
vector_store=vector_store
)
query_engine = get_sentence_window_query_engine(sentence_index=sentence_index)- 쿼리 실행
resp = query_engine.query(
"Explain article 69, para 1"
)
print(resp)- 실행 결과
- Article 69, paragraph 1 allows Member States to call upon experts from the scientific panel to support their enforcement activities related to this Regulation on Artificial Intelligence. This provision enables Member States to seek assistance and expertise from the scientific panel's experts when carrying out tasks related to enforcing the rules and requirements set forth in the Regulation within their respective jurisdictions.
- 참고
from elasticsearch import Elasticsearch
# Elasticsearch 인스턴스 초기화
es = Elasticsearch("http://localhost:9200")
# 검색 쿼리 실행
response = es.search(index="swr_tutorial", body={
"query": {
"match_all": {} # 모든 문서를 검색합니다. 실제 사용 시 여기를 적절한 쿼리로 교체하세요.
}
})
# 검색 결과 출력
for hit in response['hits']['hits']:
print(hit["_source"]["content"]) # 문서의 내용을 출력합니다.window_size가 3이며 89, 90, 91번 문단이 하나의 데이터 청크로 묶여 처리된 것을 확인할 수 있습니다.
(89) Third parties making accessible to the public tools, services, processes, or AI components other than general-purpose AI models, shall not be mandated to comply with requirements targeting the responsibilities along the AI value chain, in particular towards the provider that has used or integrated them, when those tools, services, processes, or AI components are made accessible under a free and open licence. Developers of free and open-source tools, services, processes, or AI components other than general-purpose AI models should be encouraged to implement widely adopted documentation practices, such as model cards and data sheets, as a way to accelerate information sharing along the AI value chain, allowing the promotion of trustworthy AI systems in the Union.
(90) The Commission could develop and recommend voluntary model contractual terms between providers of high-risk AI systems and third parties that supply tools, services, components or processes that are used or integrated in high-risk AI systems, to facilitate the cooperation along the value chain. When developing voluntary model contractual terms, the Commission should also take into account possible contractual requirements applicable in specific sectors or business cases.
(91) Given the nature of AI systems and the risks to safety and fundamental rights possibly associated with their use, including as regards the need to ensure proper monitoring of the performance of an AI system in a real-life setting, it is appropriate to set specific responsibilities for deployers....It remains necessary to ensure information of workers and their representatives on the planned deployment of high-risk AI systems at the workplace where the conditions for those information or information and consultation obligations in other legal instruments are not fulfilled.
추가(Auto-merging retrieval)
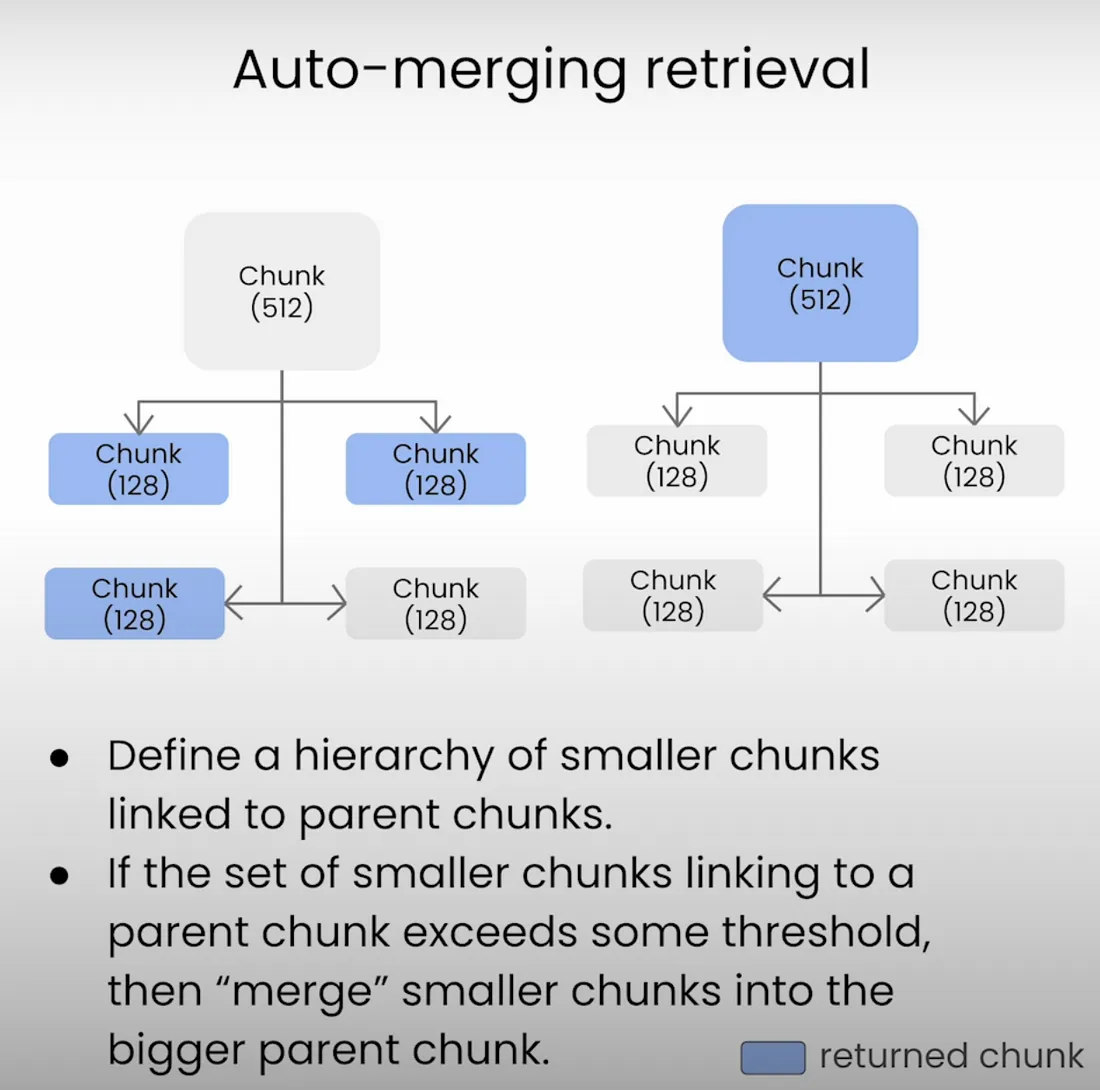
이 외에도 Parent-Child 구조를 가지는 방식도 설정 가능하며 해당 구성은 추후에 다시 테스트하고자 합니다.
- 작은 청크를 더 큰 상위 청크에 연결하여 계층 구조를 만드는 방식입니다.
- 쿼리를 날려 데이터를 검색하는 과정에서 특정 백분율 임계값이 초과되면 자동으로 상위 인덱스로 병합되며, 더 매끄러운 정보 흐름을 보장하게 됩니다.
![[LLM] VLM으로 표를 정확히 추출하기](https://images.unsplash.com/photo-1623667322051-18662ce6334c?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDl8fHBkZnxlbnwwfHx8fDE3NzIzNzMzODN8MA&ixlib=rb-4.1.0&q=80&w=960)
![[RAG] 한국어 Reranker 모델을 사용하여 RAG 성능 올리기](https://images.unsplash.com/flagged/photo-1578928534298-9747fc52ec97?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDF8fFJhbmtpbmd8ZW58MHx8fHwxNzU0MTM3OTQ4fDA&ixlib=rb-4.1.0&q=80&w=960)
![[Parser] UpstageLayoutAnalysisLoader 를 활용한 문서 파싱](https://images.unsplash.com/photo-1607434472257-d9f8e57a643d?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDJ8fFBhcnNpbmd8ZW58MHx8fHwxNzU0MDA1ODUxfDA&ixlib=rb-4.1.0&q=80&w=960)
![[GraphDB] GraphRAG(Neo4j)](https://images.unsplash.com/photo-1434626881859-194d67b2b86f?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDExfHxncmFwaHxlbnwwfHx8fDE3NTM4MzI1MjF8MA&ixlib=rb-4.1.0&q=80&w=960)