[AWS] Personalize에서 생성형 AI를 활용한 Content Generator
AWS Personalize를 통한 GenAI 추천기
![[AWS] Personalize에서 생성형 AI를 활용한 Content Generator](https://images.unsplash.com/photo-1662368864997-dd71a2f78433?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDR8fFBlcnNvbmFsaXplfGVufDB8fHx8MTc1Mzc0NzM1MHww&ixlib=rb-4.1.0&q=80&w=1200)
주의사항
- 미국 동부(버지니아 북부)
- 미국 서부(오레곤)
- 아시아 태평양(도쿄)
위 리전에서만 생성형 AI를 통한 Content Generator를 지원하고 있으므로 주의해야합니다.
개요
공식 문서는 아래와 같습니다.
레시피
aws-sims (Similar Items)
- AWS SIMS (Solution for Item-to-Item Similarities): 항목 간 유사성 권장 사항을 생성합니다. 상품 상세 페이지에 유사한 상품을 표시하는 등 특정 상품과 유사한 상품을 추천하고 싶을 때 유용합니다. 이는 이 항목과 상호작용한 사용자가 다른 항목도 좋아할 수 있다는 원칙을 기반으로 합니다.
aws-similar-items
- Similar Items in the Same Category: 이 개념은 일반적으로 aws-sims 접근 방식을 확장하여 기본 항목과 동일한 카테고리 내의 항목에 초점을 맞춥니다. 동일한 카테고리의 항목만 포함하도록 aws-sims 레시피의 출력을 필터링하여 카테고리별 검색 시나리오에서 관련성을 향상시키는 작업이 포함될 수 있습니다.
aws-personalized-ranking
- Personalized Ranking: 항목 목록을 가져와 특정 사용자의 예상 관심도 순으로 순위를 다시 매깁니다. 이는 각 개인의 선호도에 맞게 조정하여 참여 가능성을 높이는 미리 결정된 항목 목록(예: 검색 결과 또는 선별된 목록)이 있는 시나리오에 유용합니다.
aws-user-personalization
- User Personalization: 상호 작용 기록을 기반으로 사용자에게 개인화된 추천을 제공하도록 설계된 강력한 방법입니다. 홈페이지의 개인화된 제품 추천부터 미디어 앱의 개인화된 콘텐츠 추천까지 광범위한 애플리케이션에 적합합니다. 실시간 상호작용에 적응할 수 있어 매우 역동적입니다.
aws-trending-now
- Trending Now: 특정 기간 동안 사용자 기반 전체에서 인기가 높은 항목을 식별하고 순위를 지정하는 데 도움이 됩니다. 관심을 끌고 있는 인기 항목을 강조하는 데 특히 유용하며, 인기 있는 최신 제품을 소개하려는 뉴스 피드, 소셜 네트워크 또는 소매 사이트에서 효과적일 수 있습니다.
aws-popularity-count
- Popularity Count: 개인화 없이 상호 작용 빈도를 기준으로 항목의 순위를 매깁니다. 전체 사용자 기반에서 널리 인기 있는 항목을 강조 표시하는 방법으로, 처음 방문자에게 최고 판매 항목을 표시하는 등 개인화된 추천이 불가능하거나 바람직하지 않은 시나리오에 유용합니다.
정보
- Content Generator의 경우 Similar-items 레시피에서만 사용 가능합니다. (항목 기반 추천 전용)
- 배치 추론시에만 사용 가능합니다. (최대 100개 까지 지원됩니다.)
- Items 데이터 세트가 필요하고 아래와 같은 추가 요구 사항이 있습니다.
- DESCRIPTION 항목의 텍스트 필드가 있어야합니다
- Title 항목의 문자열 필드가 있어야합니다.
- DESCRIPTION 항목의 텍스트 필드가 있어야합니다
- 지원되는 리전은 다음과 같습니다.
- 미국 동부(버지니아 북부)
- 미국 서부(오레곤)
- 아시아 태평양(도쿄)
LLM 모델을 사용하여 Batch 처리 방식으로 Personalize를 위한 테마를 생성합니다. 하나의 테마를 출력할 때마다 1달러가 청구되므로 ItemID 확장시 주의하여야합니다.
프로세스
데이터 준비
Personalize 데이터를 저장할 버킷을 생성하고 다음과 같은 정책을 추가합니다.
{
"Version": "2012-10-17",
"Id": "PersonalizeS3BucketAccessPolicy",
"Statement": [
{
"Sid": "PersonalizeS3BucketAccessPolicy",
"Effect": "Allow",
"Principal": {
"Service": "personalize.amazonaws.com"
},
"Action": [
"s3:GetObject",
"s3:ListBucket",
"s3:PutObject"
],
"Resource": [
"arn:aws:s3:::{your-bucket-name}",
"arn:aws:s3:::{your-bucket-name}/*"
]
}
]
}데이터셋 그룹 설정
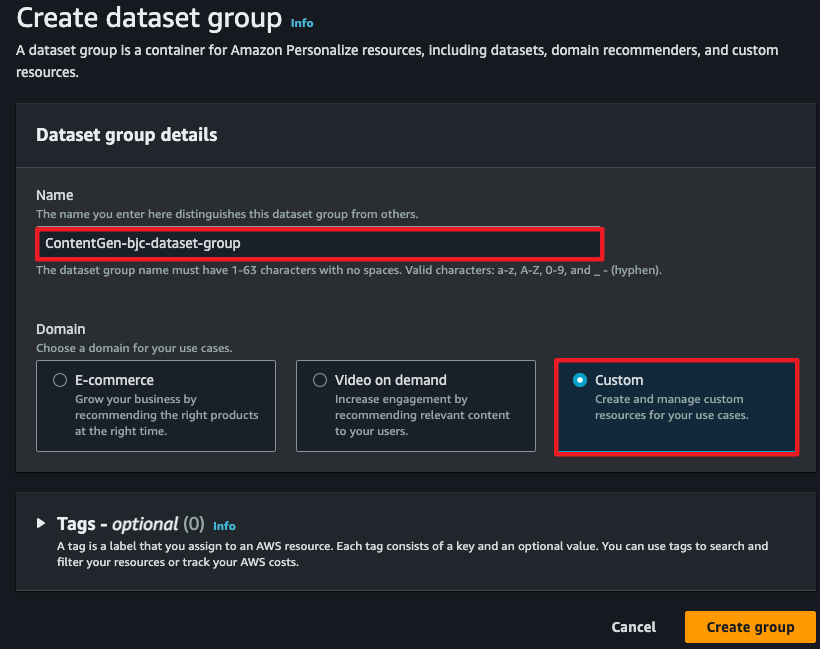
- Create group 후 아래와 같은 step으로 전개됩니다.
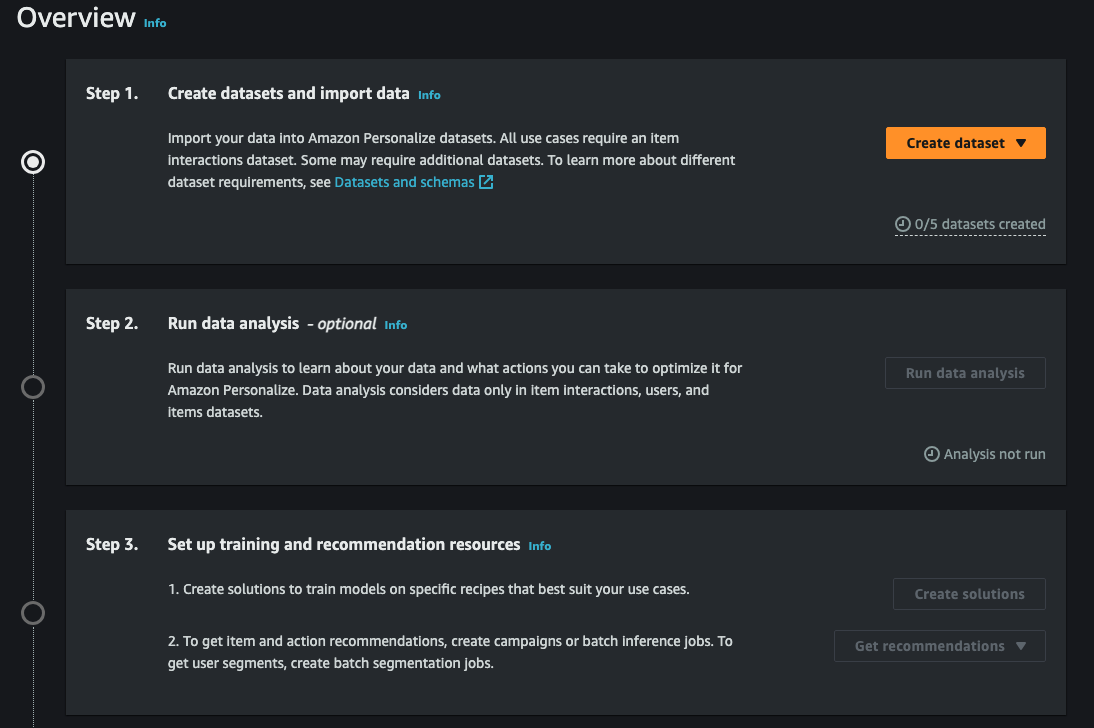
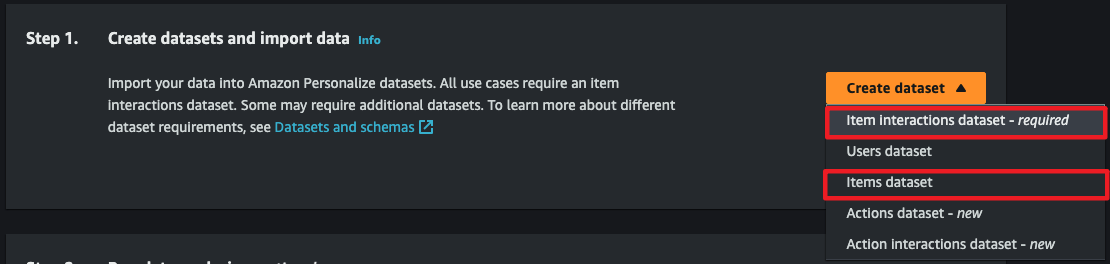
- 여기서 Item interactions dataset은 필수 입니다.
필수 데이터셋 추가
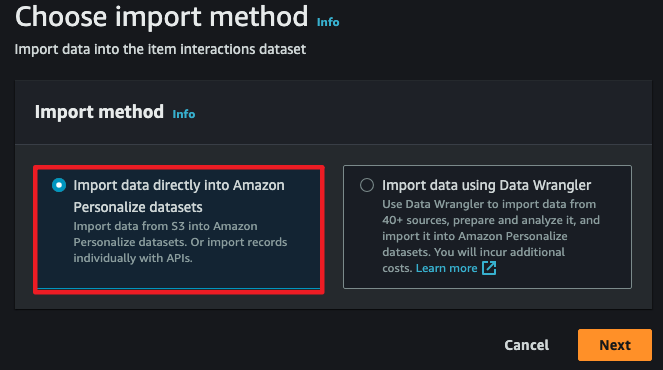
- s3에 직접 데이터를 넣을 수도 있고 Data Wrangler를 통해 어딘가에 저장된 데이터를 포맷하여 사용할 수 있습니다.

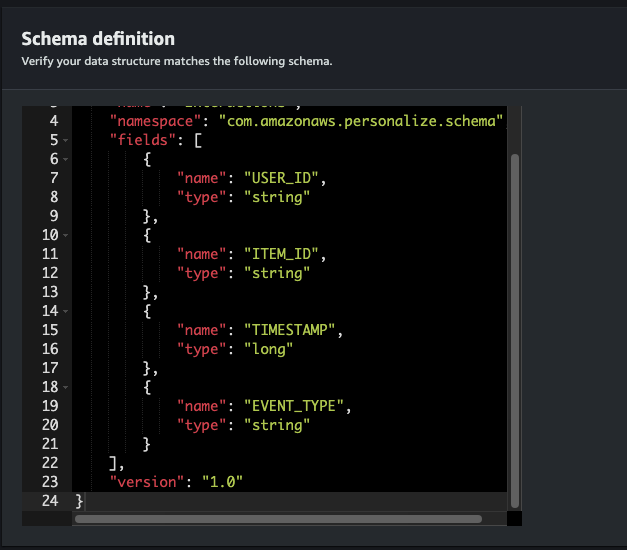
{
"type": "record",
"name": "Interactions",
"namespace": "com.amazonaws.personalize.schema",
"fields": [
{
"name": "USER_ID",
"type": "string"
},
{
"name": "ITEM_ID",
"type": "string"
},
{
"name": "TIMESTAMP",
"type": "long"
},
{
"name": "EVENT_TYPE",
"type": "string"
}
],
"version": "1.0"
}
이후 Next를 누르면, Dataset이 저장되어 계속해서 Import job의 작성 화면으로 이동합니다.
Import job 만들기
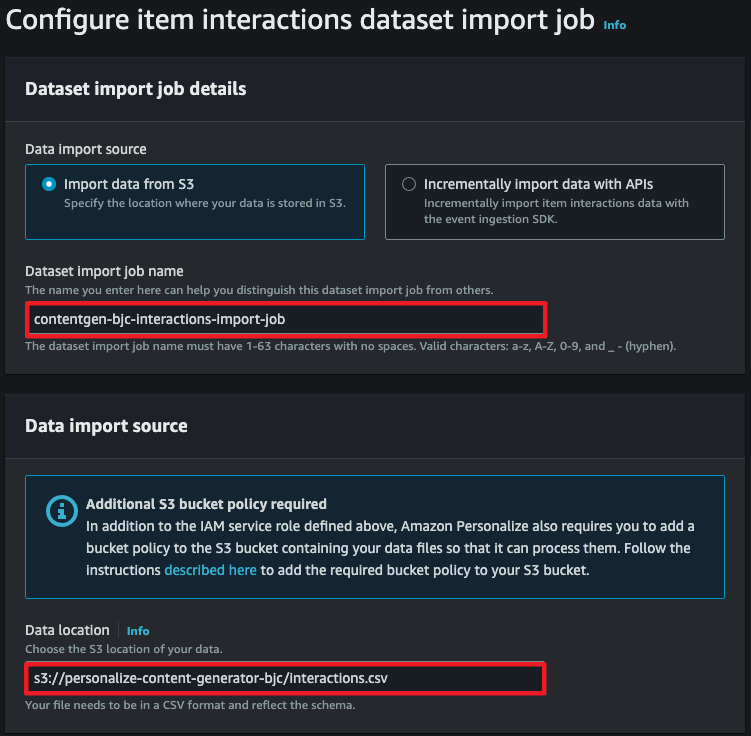
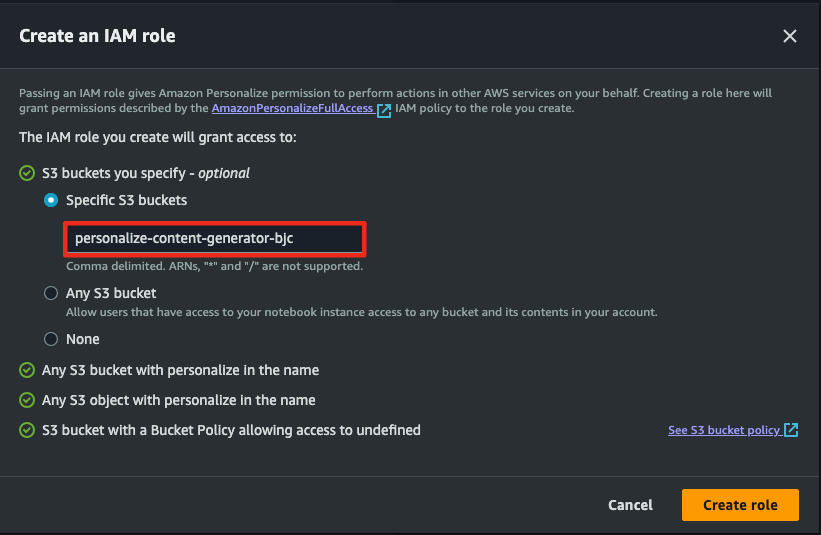
- 준비한 데이터를 연결하기 위해 데이터의 위치와 Personalized에서 접근할 수 있도록 권한을 추가합니다.
- 생성한 버킷명을 입력해야합니다.
아이템 데이터셋 추가
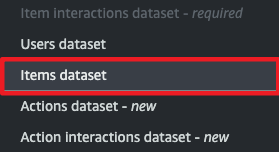
- 유사한 아이템을 추천해주기 위함이므로 Items dataset을 추가합니다.
{
"type": "record",
"name": "Items",
"namespace": "com.amazonaws.personalize.schema",
"fields": [
{
"name": "ITEM_ID",
"type": "string"
},
{
"name": "name",
"type": "string"
},
{
"name": "price",
"type": "int"
},
{
"name": "CATEGORY_L1",
"type": [
"string"
],
"categorical": true
},
{
"name": "CATEGORY_L2",
"type": [
"string"
],
"categorical": true
},
{
"name": "PRODUCT_DESCRIPTION",
"type": [
"string"
],
"textual": true
}
],
"version": "1.0"
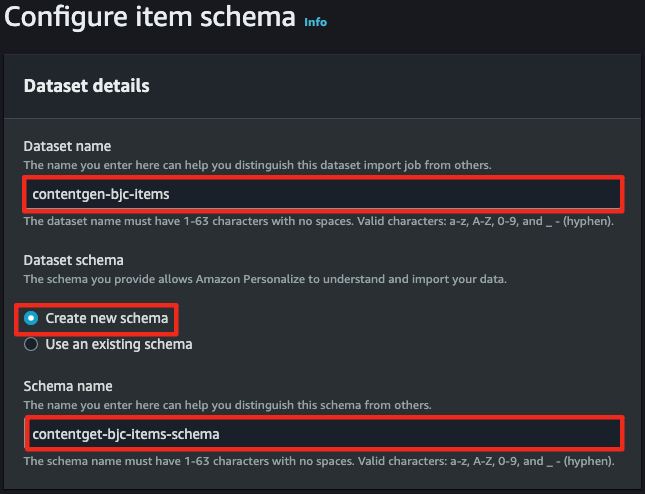
}- item 데이터를 위한 스키마를 새로 생성하여 저장합니다.
PRODUCT_DESCRIPTION의textual항목을 통해 유사한 아이템 추천을 하게 되므로 필수적으로 지정해야하며, 항목 데이터 세트와 스키마 정보는 다음과 같습니다.
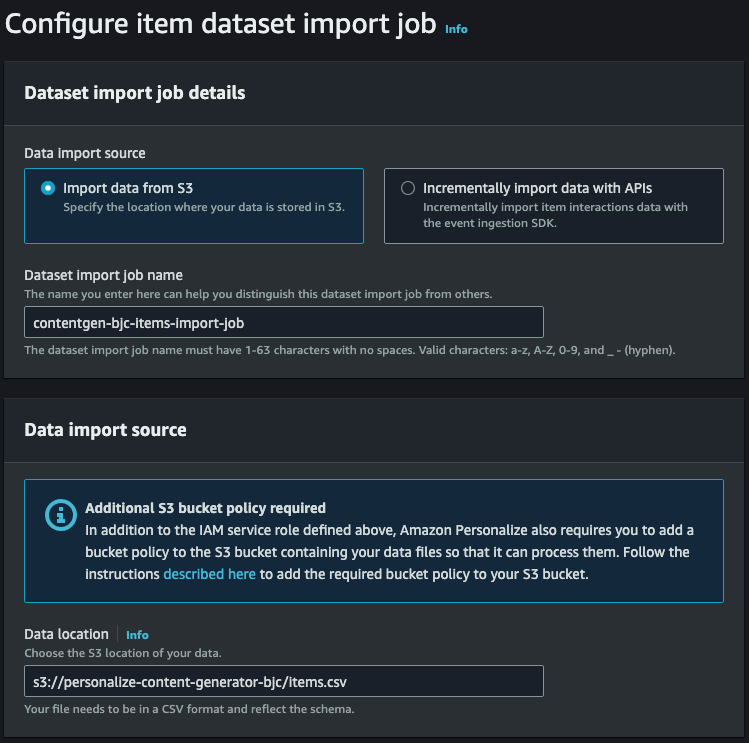
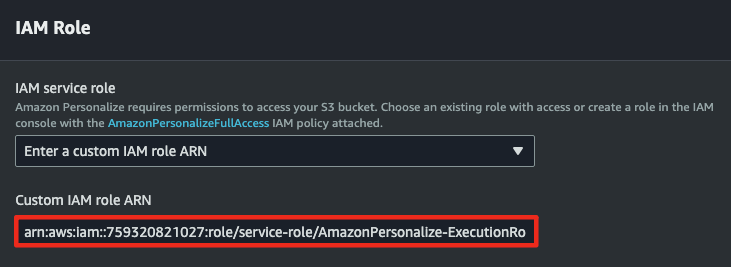
- items 데이터를 연결하고 이전에 설정한 IAM Role을 지정합니다.
Solution 생성
Create solutions를 입력하고 aws-similar-items를 선택합니다.
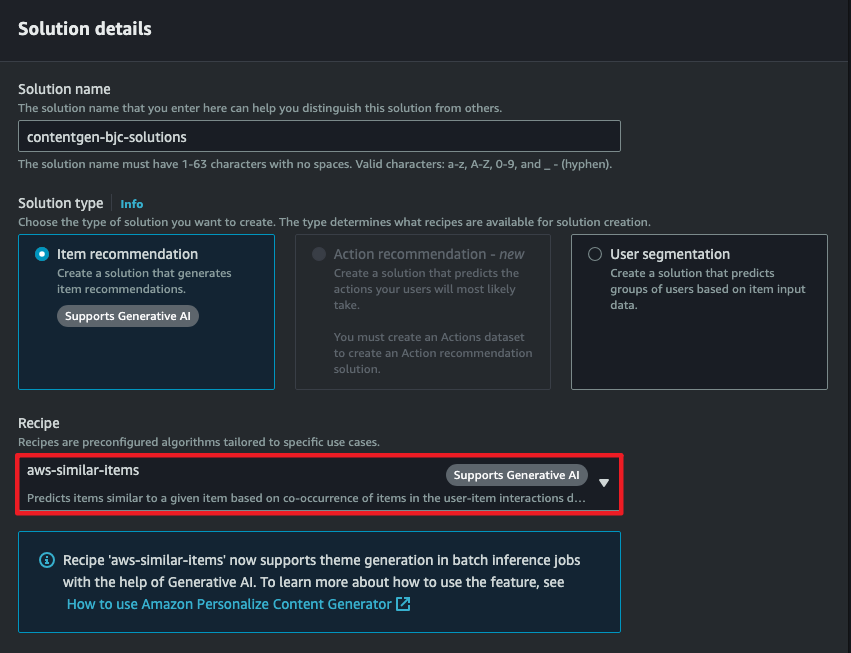
- Next를 선택합니다.

- Advanced 설정은 따로 지정하지않고 넘어갔지만, 데이터셋에 따라 하이퍼파라미터 혹은 실시간 이벤트 유형을 구성할 수 있습니다.
- 차원을 늘릴 수록 학습량이 많아지게 되며, 더 높은 정확도를 얻을 수 있지만 과적합 될 가능성이 있습니다.
- 관련된 옵션은 아래 자료에서 확인할 수 있습니다.
해당 설정을 넘어가서 솔루션을 생성하면 됩니다.
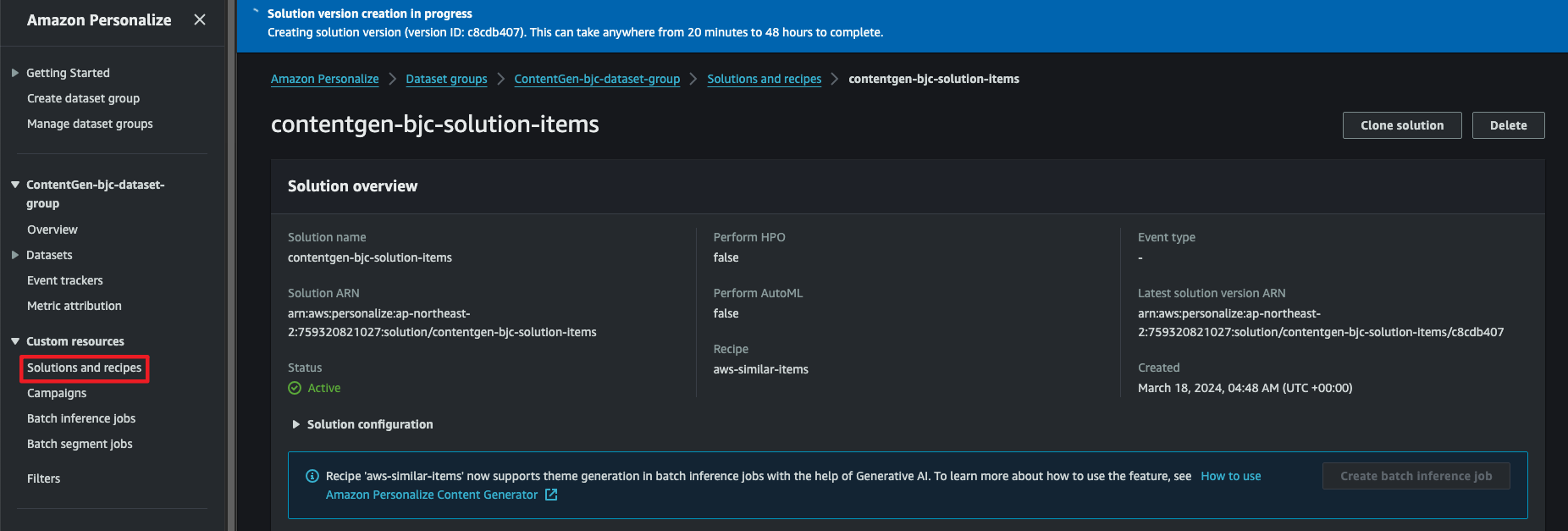
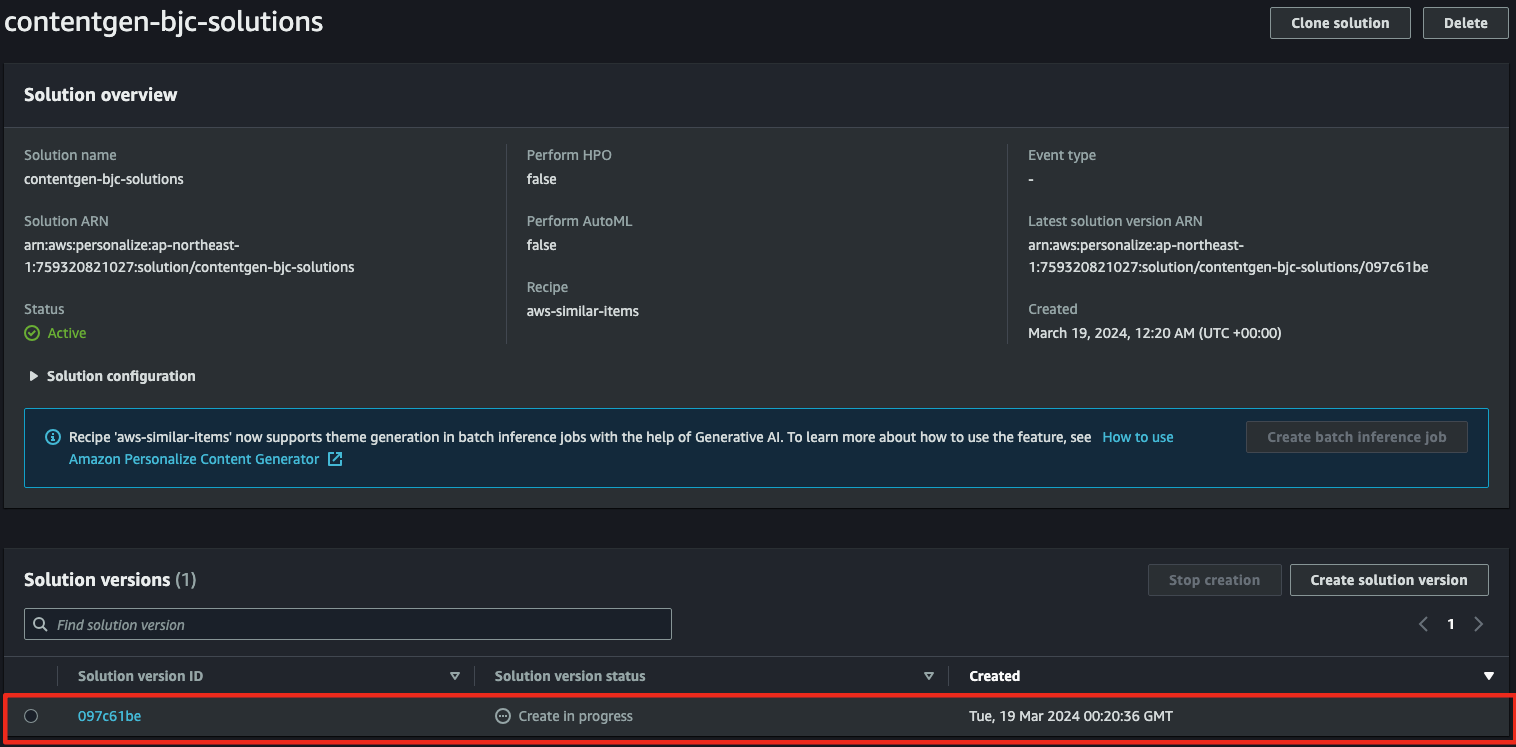
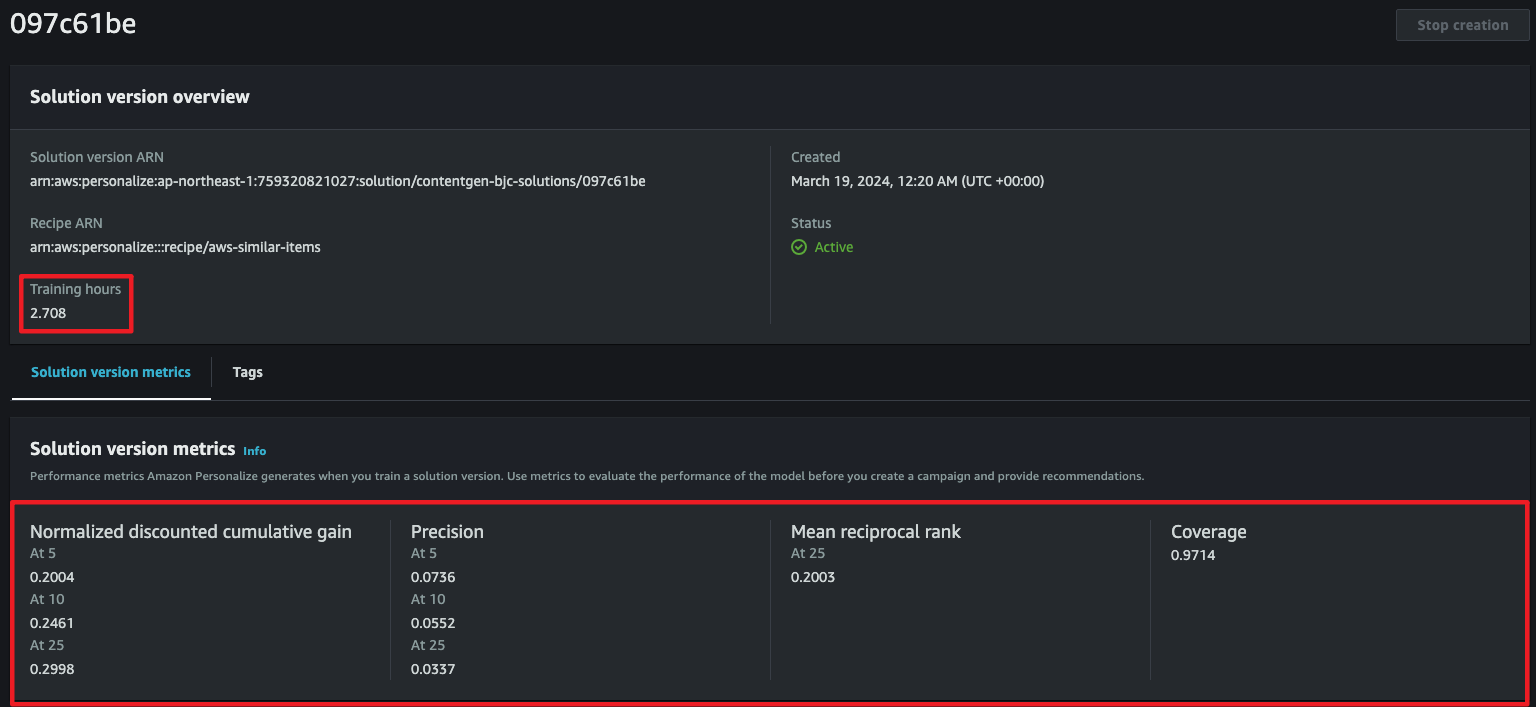
- Custom resources → Solutions and recipes에서 생성 중인 솔루션의 상태를 확인할 수 있습니다.
- Training hours에 따라 비용이 청구되며, 실시간 작업과는 별개의 요금 단위가 청구됩니다.
Content Generator Batch inference
학습시킨 솔루션에 itemId를 전달하면 Theme 기반으로 유사한 상품의 추천이 가능합니다.
{"itemId": "3dbfc503-b595-4fed-bb7f-b60202b0b835"}
{"itemId": "c4a3ded4-0004-49dd-9f98-542bb6d71f2c"}
{"itemId": "f3407b88-742a-44b0-88da-3cc775bdb55b"}
{"itemId": "546784ce-5a1e-4880-85ce-fcc8b84ce7b6"}
{"itemId": "c4daa771-3583-4cb4-8d38-f5b3bf0aa3b2"}s3://{your-bucket-name}/batch-inference/input.jsonl 형식으로 저장합니다.
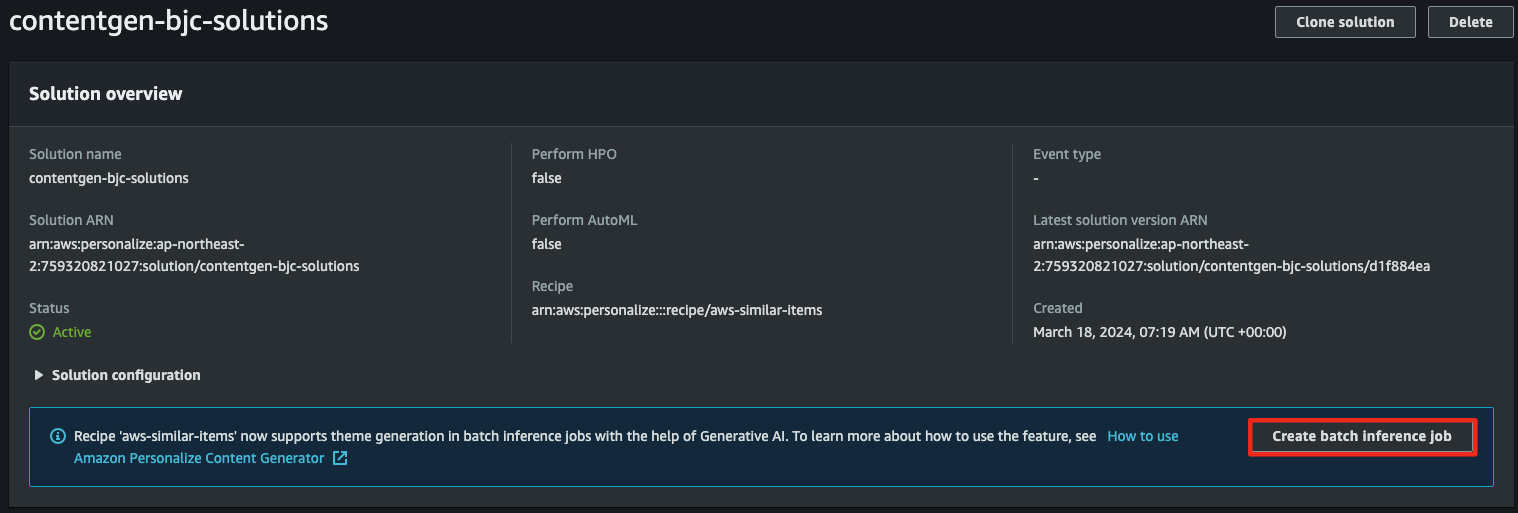
- 작업이 완료되었다면
Create batch inference job을 선택할 수 있습니다.
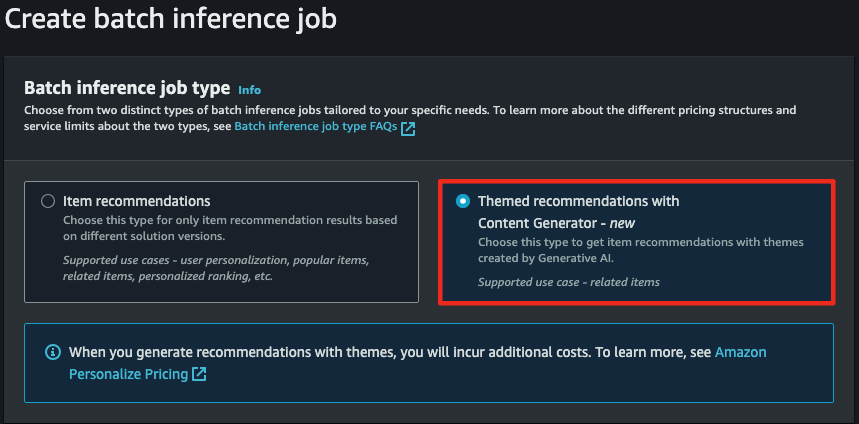
- Gen AI를 사용한 추론을 진행할 수 있습니다.
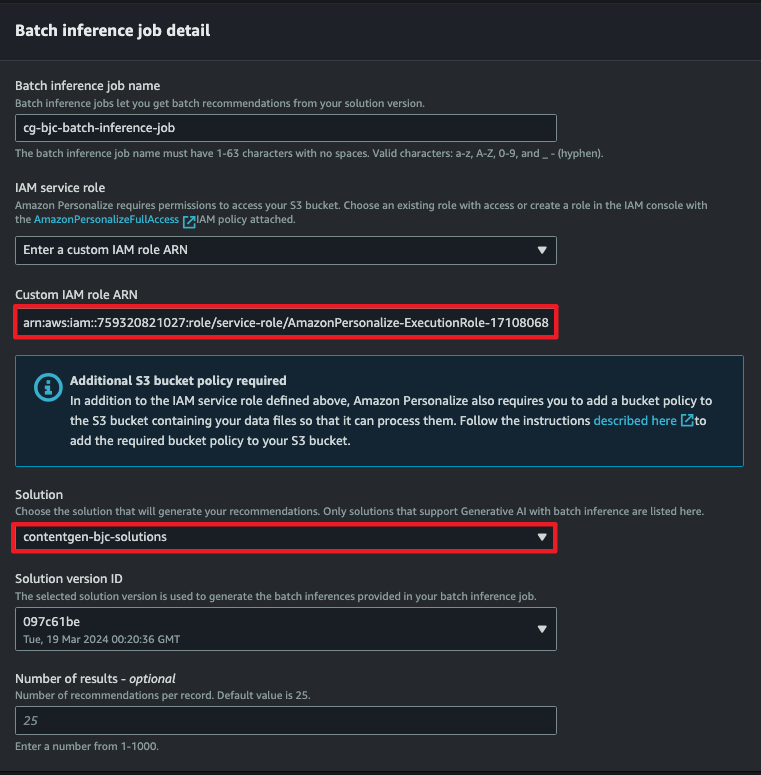
- IAM Role은 Dataset에서 사용했던 것과 동일한 것을 사용합니다.
- 데이터 훈련 작업이 끝난 솔루션을 등록합니다.
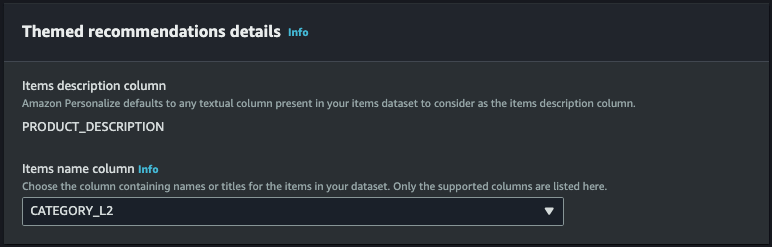
- PRODUCT_DESCRIPTION은 기본적으로 간주됩니다.
- 훈련시킨 items.csv 파일에는 아이템에 대한 이름이 없어 CATEGORY_L2로 지정합니다.
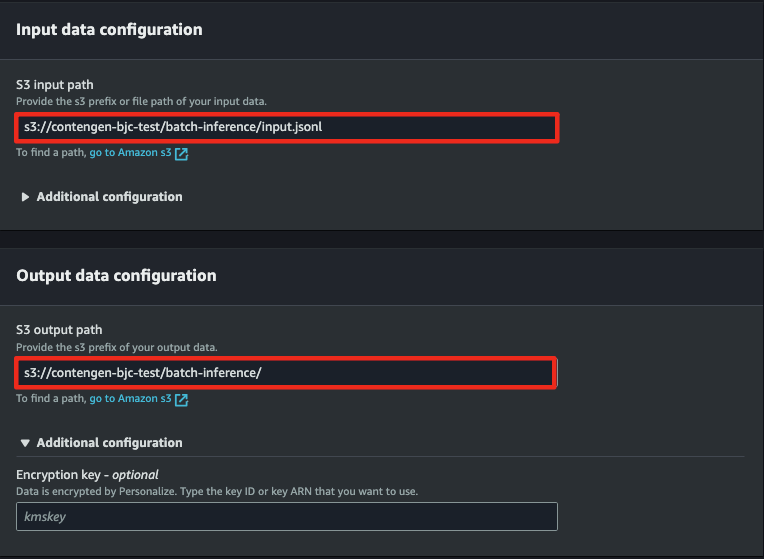
- 앞서
s3://{your-bucket-name}/batch-inference/input.jsonlinference input을 지정합니다. - 결과물을 저장할 디렉토리도 지정합니다.
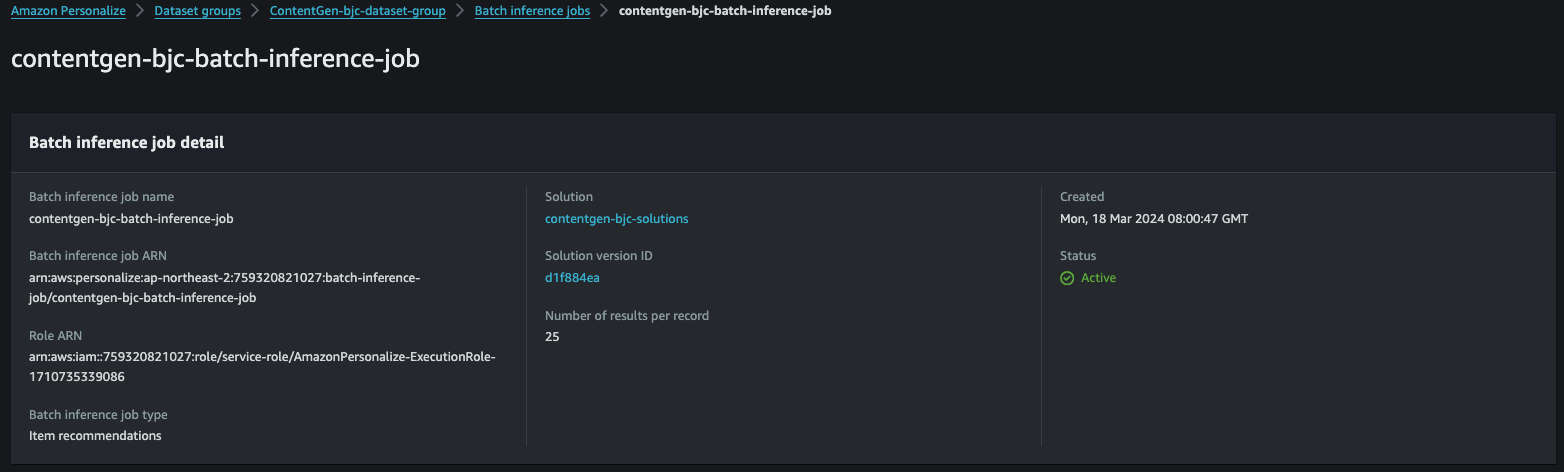
- 해당 작업이 완료되면 사전에 지정한 s3 output으로 데이터가 저장됩니다.
[
{
"itemId": "546784ce-5a1e-4880-85ce-fcc8b84ce7b6",
"theme": "Groceries",
"recommendedItems": [
"4527bda1-0338-439f-9a56-749943dff6cb",
"e1c8e574-93fa-4bb4-8f17-374fdcf85da6",
"58c4056b-bad4-4098-9996-2c6d3be93218",
"089baa54-b066-4359-83ff-8a41011d3110",
"14c5314c-6325-41e9-8e5b-4f72f5b05f27",
"62f6d1c3-33ea-415c-95dd-b3cf8a8051c9",
"9abdf04d-a9b7-4627-9ce8-b11668db3c98",
"82aa8f53-3556-4fb9-aeed-547a4ea726ff",
...
],
"itemsThemeRelevanceScores": [
0.449,
0.432,
0.432,
0.432,
0.418,
0.418,
0.418,
0.383,
...
]
},
]- itemId 별, theme, recommendedItems, itemsThemeRelevanceScores(Theme과의 관련도)를 확인할 수 있습니다.
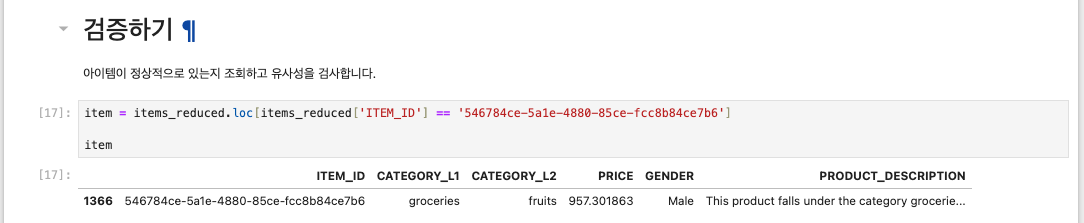
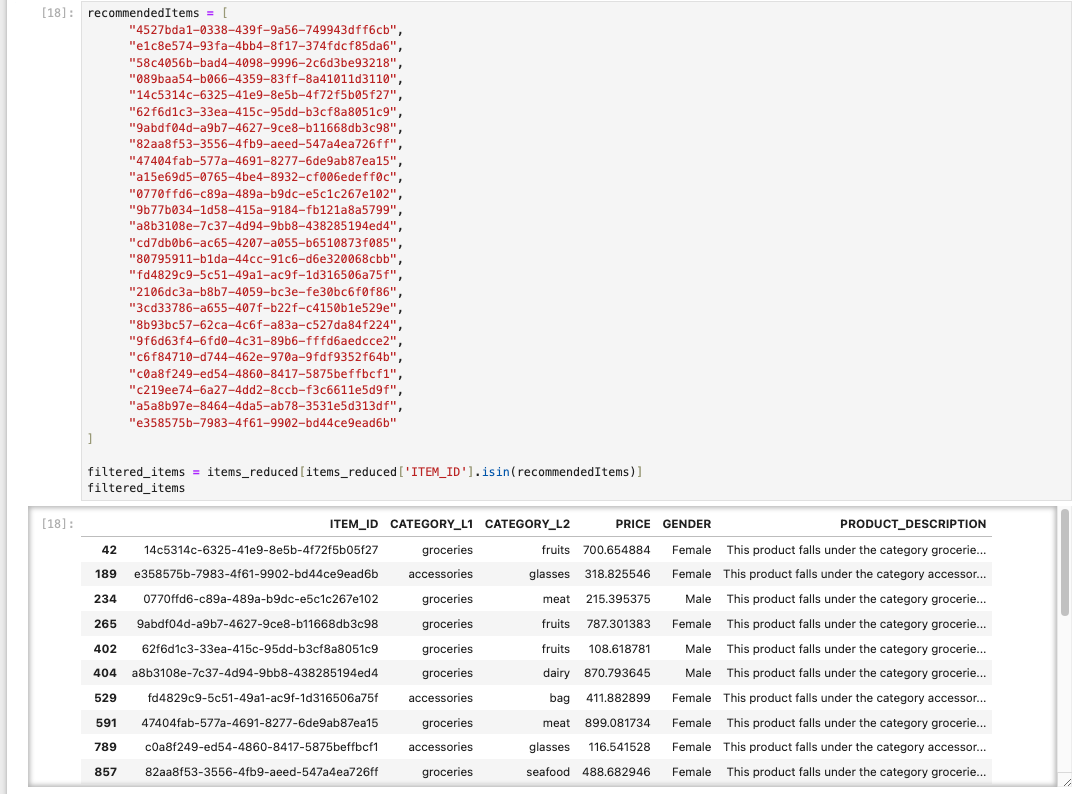
PRODUCT_DESCRIPTION을 통해 데이터의 유사도를 판별하게 됩니다.- 샘플 데이터 속 특정 열의 데이터를 CATEGORY_L1과 CATEGORY_L2를 합쳐 테스트 형식으로 만든 PRODUCT_DESCRIPTION는 실제 검증을 해봤을 땐 데이터가 다소 정확하지 않게 출력되었습니다.
- groceries fruits를 넣었는데 추천에는 accessories의 glasses가 나왔습니다.
- 데이터의 정확도를 위해선 더 좋은 데이터 샘플 혹은 프로덕션 데이터가 필요하므로 결과에 대해선 진행 방식만 참고해주세요.
- 샘플 데이터 속 특정 열의 데이터를 CATEGORY_L1과 CATEGORY_L2를 합쳐 테스트 형식으로 만든 PRODUCT_DESCRIPTION는 실제 검증을 해봤을 땐 데이터가 다소 정확하지 않게 출력되었습니다.
데이터 interactions이 필수인만큼 중요한 부분을 차지하는데, 아이템 값을 채우기 위해 랜덤으로 돌려둔만큼 정확한 데이터가 추론되지 않는 것으로 보입니다.
![[AWS] DynamoDB 스키마 설계 가이드](https://images.unsplash.com/photo-1554098415-788601c80aef?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDV8fFNRTHxlbnwwfHx8fDE3NjcyMzc1NDJ8MA&ixlib=rb-4.1.0&q=80&w=960)
![[AWS] AWS 기반 데이터 파이프라인 서비스 정리](https://images.unsplash.com/photo-1507823690283-48b0929e727b?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDR8fHBpcGVsaW5lfGVufDB8fHx8MTc1NDIyNjIwOXww&ixlib=rb-4.1.0&q=80&w=960)
![[EKS] 액세스 정책 권한 검토](https://images.unsplash.com/photo-1584433144859-1fc3ab64a957?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDZ8fHBvbGljeXxlbnwwfHx8fDE3NDcwNTU5NDR8MA&ixlib=rb-4.1.0&q=80&w=960)
