[AI Agent] RAG 리뷰(3주차)
RAG 파이프라인 구축 시 Golden Dataset으로 품질을 객관적으로 측정하고, PDF 로더, 청킹 전략, 임베딩 모델을 단계별로 최적화하여 신뢰성 높은 AI 시스템을 만드는 방법을 소개합니다.
![[AI Agent] RAG 리뷰(3주차)](https://images.unsplash.com/photo-1705484229341-4f7f7519b718?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDV8fERhdGFzZXR8ZW58MHx8fHwxNzc1MjYyNzkxfDA&ixlib=rb-4.1.0&q=80&w=1200)
개요
3주차 RAG(Retrieval-Augmented Generation) 과제 수행 항목을 리뷰합니다. RAG는 AI의 입력되는 데이터를 제어하기 위한 방법 중 하나 입니다. 최상위 레이어로 들어오는 데이터가 잘못되었다면 잘못된 답변을 내뱉을 수 있습니다. RAG는 이를 제어하여 신뢰성있는 AI를 만들기 위한 핵심 구성요소입니다.
- Golden Dataset의 중요성
- RAG 파이프라인의 전체 구조
- PDF 로더 선택과 표 추출
- 청킹 전략
- 임베딩 모델 판단 기준

Golden Dataset의 중요성
정답이 있는 문제에서 정답이 없는 문제로
2주차까지는 의료급여 본인부담률 표라는 명확한 데이터와 질문에 대한 정답도 제공해드렸습니다. 하지만 실무에선 그렇지 않죠
사용자의 질문은 항상 모호하고, 문서는 훨씬 더러우며, 좋은 답변의 기준도 사용자와 상황에 따라 달라집니다. 이런 환경에서 AI 시스템의 품질을 판단하려면 반드시 평가 기준을 만들어야 합니다. 이를 Golden dataset이라고 합니다.
Golden Dataset이 중요한 이유
Golden Dataset은 RAG 파이프라인의 객관적 품질 지표입니다. 이것이 없으면 다음과 같은 상황이 발생합니다.
- 청킹 전략을 바꿨는데, 좋아진 건지 나빠진 건지 알 수 없습니다.
- 임베딩 모델을 교체했는데, 비용만 늘고 개선은 없었는지 확인할 방법이 없습니다.
- 모델 교체, 프롬프트 변경, 컨텍스트 검색 방식 변경 등으로 문제 발생시 확인할 방법이 없습니다.
과제와 실제 프로젝트의 차이
이번 과제에서는 Golden Dataset의 형식과 평가 기준이 미리 정의되어 있습니다.
질문 설계 가이드, 난이도 분포, 필수 필드까지 정해져 있으므로 그 틀 안에서 5문제를 채우면 됩니다.
하지만 실제 프로젝트에서는 이 틀 자체가 존재하지 않고 상황에 따라서 달라질 수 있습니다. 따라서 Golden dataset을 세우기 위해서 가장 먼저 진행해야할 내용은 "이 시스템이 제대로 동작하는지 어떻게 판단할 것인가"입니다.
| 구분 | 실제 프로젝트 |
|---|---|
| 정답 유무 | 정답이 없거나 모호한 경우가 대부분 |
| 평가 기준 | 직접 정의해야 함 |
| 질문 수 | 도메인에 따라 수십~수백 문제 |
| 난이도 설계 | 실제 사용 패턴 분석에서 도출 |
| 유지보수 | 데이터 변경 시마다 갱신 필요 |
또한 주사용자에 따라 달라질 수 있으니
- 수급권자 본인/가족 — 내가 얼마 내야 하는지, 구체적 상황 기반 ("입원하면 얼마?")
- 의료기관 행정 담당자 — 청구·수납 기준, 제도 규정 기반 ("급여 적용 기준은?")
- 사회복지사/상담사 — 대상자에게 제도 안내, 자격·절차 기반 ("신청 방법은?")
- 공무원 (읍면동 담당) — 자격 심사·관리, 기준·예외 기반 ("자격 상실 조건은?")
MLOps, LLMOps의 중요한 사이클
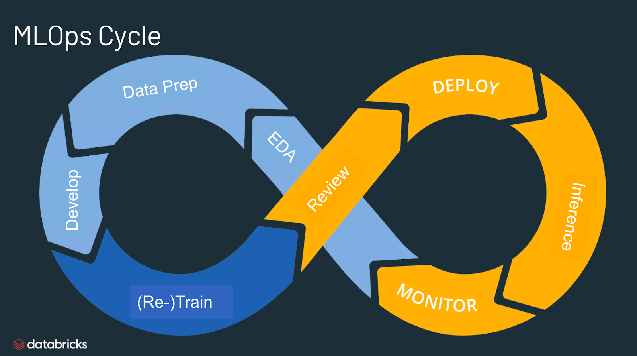
개발에 익숙하신 분들은 단위 테스트, 통합 테스트, 시스템 테스트에 익숙하실겁니다. 코드가 의도한 방향대로 동작하는지를 검증하기 위한 과정입니다. AI에서도 똑같습니다. 데이터가 올바르게 출력하는지 평가(Evaluation)하는 과정을 의미합니다.
코드 기반 평가 단순히 OX로 평가하거나 휴리스틱(경험 기반) 규칙을 만들어 올바른 출력을 만드는지 평가합니다.
이는 다양한 방법이 존재합니다. 코드, 사람, LLM이 LLM을 LLM as a Judge가 존재합니다.
- 평가 방법에 대해서는 이후 5주차에서 자세히 다룰 예정입니다.
Golden Dataset 검증
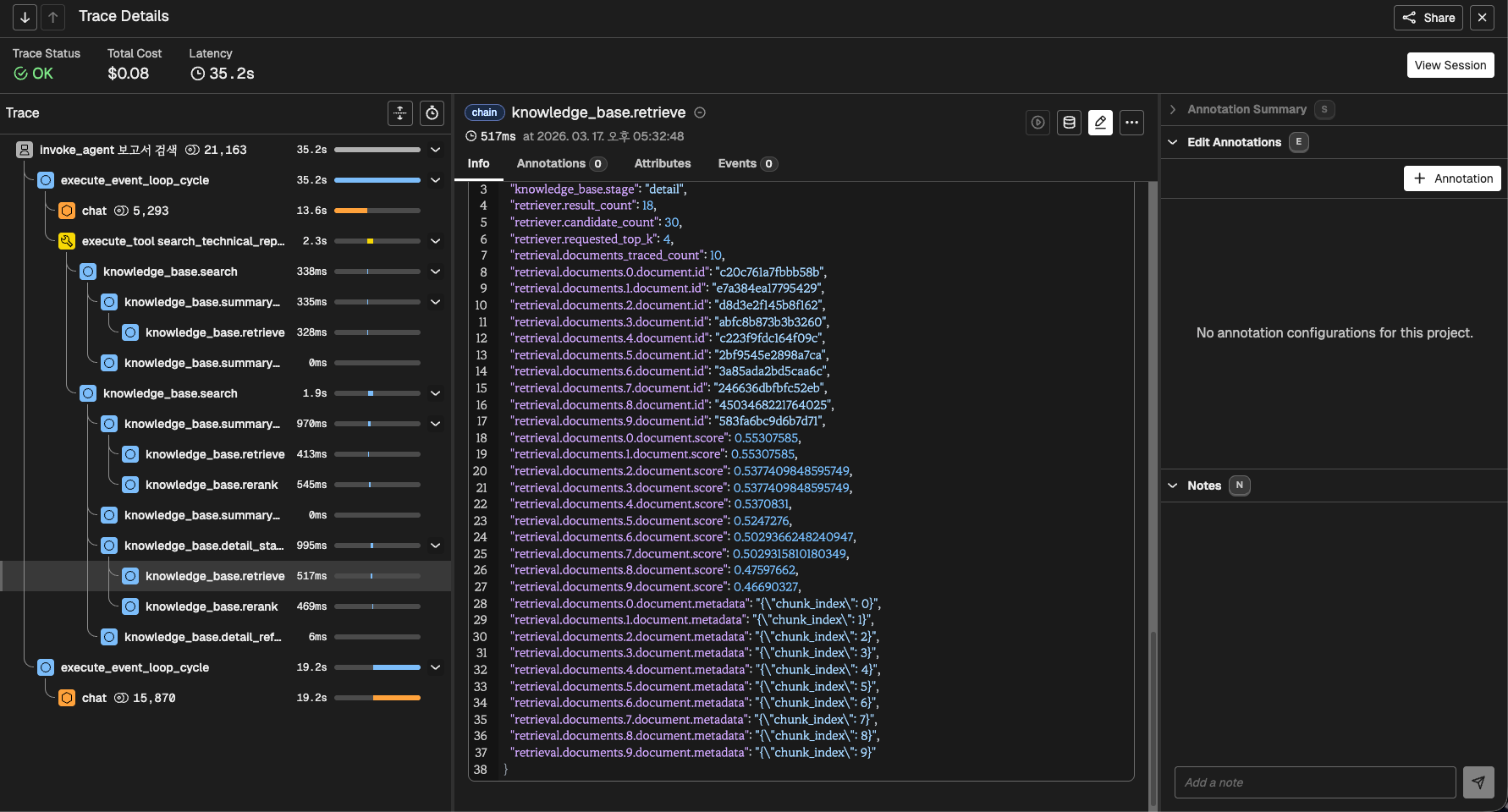
RAG 파이프라인의 구조
데이터 준비 단계 + 사용자 검증 단계로 구성합니다.
| 구분 | 단계 | 특징 |
|---|---|---|
| Indexing (offline) | PDF 로딩 → 청킹 → 임베딩 → 벡터 저장 | 사전 준비. 한 번 해두면 재사용 |
| Retrieval + Generation (online) | 질문 → 임베딩 → 벡터 검색 → LLM 생성 | 사용자 질문 시 실시간 수행 |
PDF 로더 선택과 표 추출
PDF는 렌더링 포맷이지 데이터 포맷이 아닙니다. 내부적으로 텍스트의 "의미 구조"가 아니라 "좌표 위치"로 저장되는 형식으로 모델이 PDF를 입력받을 수 있더라도 해당 PDF에는 불필요한 정보 혹은 너무 대용량의 데이터를 받을 수 있습니다.

이러한 자료를 받더라도 불필요한 정보들이 포함되어 모델들이 정확하게 읽지 못하거나 잘못된 데이터로 해석하여 읽을 수 있습니다.
따라서 로더의 목적은 PDF를 LLM이 처리할 수 있는 데이터 형식으로 보존하여 데이터베이스 혹은 LLM에게 직접적으로 전달하는 목적을 수행합니다.
과제에서의 PDF 로더
의료급여 PDF는 표(table) 중심 문서입니다. 로더 선택에 따라 추출 결과의 품질이 근본적으로 달라집니다. 이번 과제에서는 참고하실 수 있게 LangChain의 PyPDFLoader 를 전달드렸지만 표를 직접적으로 추출하긴 어려우셨을거라 생각합니다.
- https://docs.langchain.com/oss/javascript/integrations/document_loaders/file_loaders/pdf
- https://www.llamaindex.ai/blog/pdf-parsing-llamaparse
실무에서 사용되는 도구
과제에서는 PyPDFLoader와 pdfplumber만 언급드렸지만 실무에서는 더 정교한 문서 파싱 도구들이 활발하게 사용되고 있습니다. 특히 표, 수식, 복잡한 레이아웃이 포함된 문서를 다룰 때 차이가 큽니다.
| 도구 | 표 처리 | OCR | 특징 |
|---|---|---|---|
PyPDFLoader |
약함 | 미지원 | LangChain 기본 로더. 텍스트만 추출 |
pdfplumber |
강함 | 미지원 | 표 구조 보존. 프로그래밍 방식으로 행/열 접근 가능 |
Docling |
강함 | 지원 | IBM 오픈소스. 페이지 레이아웃, 표 구조, 수식, 코드까지 인식. PDF/DOCX/PPTX/이미지 등 다양한 형식 지원 |
MinerU |
매우 강함 | 지원 (109개 언어) | 표를 HTML로 변환, 다중 페이지 표 병합, 표 내 수식/이미지 파싱. 복잡한 레이아웃 처리에 강점 |
Unstructured |
강함 | 지원 | LangChain 통합 용이. 다양한 파일 형식 지원. 파티셔닝 전략 선택 가능 |
의료급여 PDF처럼 표가 핵심인 문서에서는 pdfplumber만으로도 충분한 결과를 얻을 수 있습니다. 하지만 스캔 문서가 섞여 있거나, 수식/이미지가 포함된 복잡한 문서를 다루게 된다면 Docling이나 MinerU 같은 도구를 검토할 필요가 있습니다.
중요한 것은 어떤 도구를 선택하든, 추출 결과를 직접 눈으로 확인하는 습관입니다.
로더가 표, 데이터 구조를 깨뜨렸다면, 이후 청킹이나 임베딩을 아무리 조정해도 복구할 수 없습니다.
표나 수식같은 복잡한 데이터를 처리한다면?
Chunking Strategy
문서 전체를 하나의 벡터로 임베딩하면, 문서 안의 세부 정보가 평균화되어 검색 정밀도가 떨어집니다. 청킹은 문서를 적절한 크기로 분할하여, 질문과 관련된 부분만 정확하게 검색할 수 있도록 하는 것이 목적입니다.
- 청킹 = 색인 카드가 챕터/섹션별로 있음 → "3장 2절에 답이 있습니다"
- 전체 임베딩 = 색인 카드가 책 한 권당 하나 → "이 책 어딘가에 있을 수도 있습니다"
따라서 청킹의 목적을 정리하면 검색이 잘 되어 LLM이 신뢰성 답변을 할 수 있게하는 것
청킹 전략
- Fixed-size chunking: 고정 길이로 분할. 가장 단순하지만 문맥이 중간에서 잘릴 수 있습니다
- Recursive chunking: 구분자(nn, n, 문장 등)를 기준으로 재귀적으로 분할. LangChain의
RecursiveCharacterTextSplitter가 이 방식입니다 - Semantic chunking: 임베딩 유사도를 기준으로 의미가 달라지는 지점에서 분할. 의미 단위를 보존하지만 계산 비용이 높습니다
- Document structure chunking: 문서의 구조(제목, 표, 단락)를 기준으로 분할. 표 중심 문서에서 특히 효과적입니다
- No Chunking: 청킹을 안하고 원문을 보존합니다.
특히 표나 수식같은 것들의 청킹 전략을 고려하지 않고 넣는다면 표가 잘려 해석의 문제가 발생할 수 있습니다.
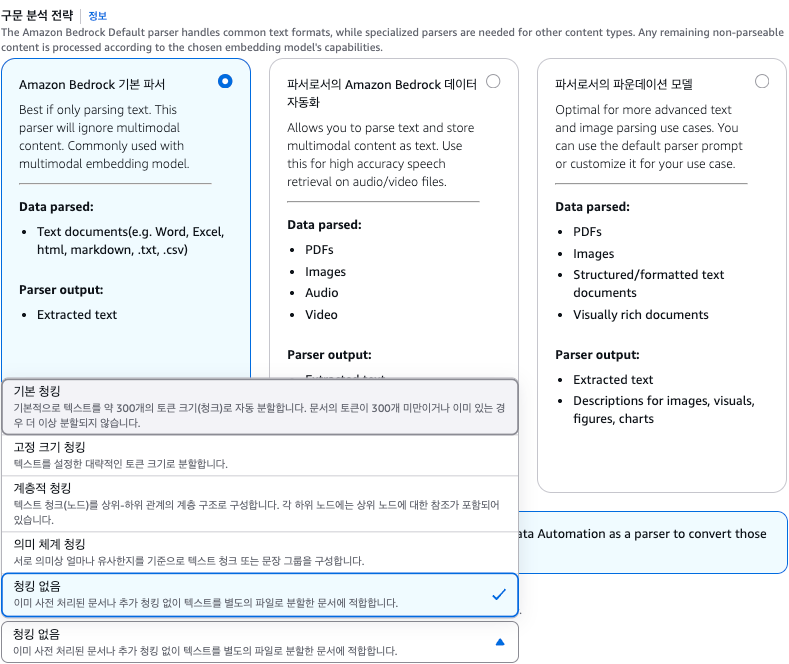
특히 청킹에 "정답"은 없습니다. 설정을 변경할 때마다 Golden Dataset으로 검색 품질을 재측정하여, 감이 아닌 데이터로 판단하는 것이 중요합니다.
최근에는 AI가 더 높은 품질의 답변을 받을 수 있도록 저렴한 AI로 정제하기도 합니다.
- 표 → 마크다운/텍스트로 변환
- 이미지 → 캡션/설명 생성 (Vision 모델)
- 수식 → LaTeX나 자연어 설명으로 변환
- 긴 문단 → 요약 청크 생성 (Contextual Retrieval 등)
- 기타 검색 요소를 활용하기 위한 메타데이터 구성
Embedding Model & Vector Storage
임베딩의 목적 텍스트의 의미를 숫자 목록(리스트)으로 표현하는 것입니다. 이렇게 텍스트를 여러 숫자의 조합으로 표현하게 되면 계산을 수행하여 비슷한 문장끼리의 검색이 가능해집니다. (코사인 유사도)
예시) Transformer에서도 사용됩니다.
- "I love you" / "I like you" → 의미가 비슷해서 가까움
- "I love you" ↔ "I hate you" → 의미가 반대라서 멂
Embedding model
텍스트를 숫자(벡터)로 변환하는 역할을 수행하는 것이 임베딩 모델입니다.
다양한 임베딩 모델이 존재하지만, 각 모델은 서로 다른 학습 데이터와 아키텍처를 사용하여 서로 다른 벡터 공간을 형성하기 때문에, 서로 다른 임베딩 모델에서 변환된 벡터를 직접 비교하는 것은 불가능합니다.
- Gemini Embedding 2 (멀티모달) ↔ OpenAI text-embedding-3-large
- 차원과 데이터를 수치로 어떻게 배치하는 것인지 모델에 따라 차이가 존재하기에 계산 불가능
- 차원이 높은 것이 더 세밀한 의미 차이를 표현 가능하지만 반드시 성능을 의미하는 것은 아님
- 학습 데이터의 품질과 양
- 사용 목적과의 적합성 (범용 vs 특정 도메인)
- https://huggingface.co/spaces/mteb/leaderboard
참고문헌
- Lewis, P., Perez, E., Piktus, A., et al. (2020). "Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks." NeurIPS 2020. https://arxiv.org/abs/2005.11401
- Gao, Y., Xiong, Y., Gao, X., et al. (2024). "Retrieval-Augmented Generation for Large Language Models: A Survey." https://arxiv.org/abs/2312.10997
- MTEB Leaderboard - Massive Text Embedding Benchmark. https://huggingface.co/spaces/mteb/leaderboard
- OpenAI Embeddings Guide. https://platform.openai.com/docs/guides/embeddings
- LangChain RAG Tutorial. https://python.langchain.com/docs/tutorials/rag/
- LlamaIndex Starter Tutorial. https://docs.llamaindex.ai/en/stable/getting_started/starter_example/
- FAISS - Facebook AI Similarity Search. https://github.com/facebookresearch/faiss
- Chroma Documentation. https://docs.trychroma.com/getting-started
![[AI Agent] Advanced RAG 개요(4주차)](https://images.unsplash.com/photo-1608741869829-8eb30661c7be?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDd8fEFkdmFuY2V8ZW58MHx8fHwxNzc1MjYyODcxfDA&ixlib=rb-4.1.0&q=80&w=960)
![[AI Agent] RAG overview(3주차)](https://images.unsplash.com/photo-1766162357668-d41a4af974df?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDE5fHxDb250ZXh0fGVufDB8fHx8MTc3NDYxNzU3OXww&ixlib=rb-4.1.0&q=80&w=960)
![[LLM] VLM으로 표를 정확히 추출하기](https://images.unsplash.com/photo-1623667322051-18662ce6334c?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDl8fHBkZnxlbnwwfHx8fDE3NzIzNzMzODN8MA&ixlib=rb-4.1.0&q=80&w=960)
![[RAG] 한국어 Reranker 모델을 사용하여 RAG 성능 올리기](https://images.unsplash.com/flagged/photo-1578928534298-9747fc52ec97?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDF8fFJhbmtpbmd8ZW58MHx8fHwxNzU0MTM3OTQ4fDA&ixlib=rb-4.1.0&q=80&w=960)