[AI Agent] Advanced RAG 개요(4주차)
Advanced RAG는 Hybrid Search로 의미와 키워드를 동시에 검색하고, Re-ranking과 메타데이터 필터링으로 정확성을 높입니다. 벡터 검색과 BM25를 결합하여 RAG의 검색 정밀도와 재현율 문제를 해결합니다.
![[AI Agent] Advanced RAG 개요(4주차)](https://images.unsplash.com/photo-1608741869829-8eb30661c7be?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDd8fEFkdmFuY2V8ZW58MHx8fHwxNzc1MjYyODcxfDA&ixlib=rb-4.1.0&q=80&w=1200)
개요
RAG의 성능을 끌어올리기 위한 Advanced RAG에 대해 정리합니다.
RAG의 진화
RAG로 AI에게 외부 세계의 지식, 신뢰할 수 있는 데이터를 넣어줌으로써 최신 정보를 반영시키고 환각을 줄여보았습니다.
하지만 당연하게도 RAG의 시스템적인 한계도 존재하는데 이를 해결하기 위해 다양한 처리 방식이 발전했습니다.

그 중에서 Advanced RAG가 대표적인데 Advanced RAG를 알아보기 전에 먼저 기존 RAG의 한계를 말씀드리곘습니다.
Naive RAG의 한계
기존 RAG는 텍스트 데이터의 의미적 유사성을 기반으로 검색을 수행하는 과정을 수행합니다.
검색 단계의 한계
- 키워드 매칭 실패: 정확한 키워드가 중요한 경우에는 오히려 약합니다. 예를 들어 "1종 수급권자"라는 정확한 용어를 포함한 문서를 찾아야 할 때, 벡터 검색은 의미가 비슷한 다른 표현의 문서를 가져오고 정작 필요한 문서를 놓칠 수 있습니다.
- 검색 정밀도 부족: Top-K로 가져온 청크 중 실제로 질문에 관련된 것은 일부에 불과할 수 있다. 무관한 청크가 컨텍스트에 포함되면 LLM의 답변 품질이 떨어진다.
- 검색 재현율 부족: 정답 근거가 포함된 청크가 Top-K 안에 들어오지 못하면, LLM이 아무리 뛰어나도 정답을 생성할 수 없다.
생성 단계의 한계
- garbage in, garbage out: 검색된 컨텍스트의 품질이 낮으면 LLM 답변도 부정확해진다. 검색이 성공해도 관련 없는 청크가 섞여 있으면 LLM이 혼란을 겪는다.
- 할루시네이션: 컨텍스트에 정답 근거가 부족하면, LLM이 자체 지식으로 답변을 생성하거나 없는 내용을 지어낼 수 있다.
- lost in the middlehttps://arxiv.org/abs/2307.03172
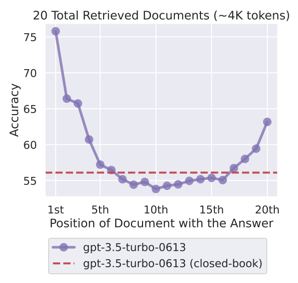
Advanced RAG란?
Advanced RAG는 Naive RAG + 검색 전(Pre-Retrieval)과 검색 후(Post-Retrieval) 처리로 해결하는 방식
| 문제 | 해결 기법 | 적용 단계 |
|---|---|---|
| 키워드 매칭 실패 | Hybrid Search (벡터 + BM25 결합) | Pre-Retrieval |
| 검색 정밀도 부족 | Re-ranking (Cross-encoder 재순위화) | Post-Retrieval |
| 무관한 컨텍스트 혼입 | 컨텍스트 압축 / 메타데이터 필터링 | Post-Retrieval |
Hybrid Search: 두 방식의 결합
Hybrid Search는 벡터 검색과 BM25를 함께 사용하여 각각의 약점을 보완합니다.
| 검색 방식 | 매칭 방법 | 강점 | 약점 |
|---|---|---|---|
| 벡터 검색 | 임베딩 벡터 유사도 | 의미적으로 유사한 문서 반환 | 정확한 키워드 매칭 실패 |
| BM25 | 정확한 단어 일치 (TF-IDF) | 정확한 용어가 포함된 문서를 직접 검색 | 의미적 유사성 포착 불가 |
| Hybrid | 벡터 + BM25 병합 | 의미적 유사도 + 키워드 매칭을 동시에 커버 | 가중치 튜닝 필요 |
- https://docs.trychroma.com/cloud/search-api/hybrid-search
- https://reference.langchain.com/python/langchain-classic/retrievers/ensemble/EnsembleRetriever
Post-Retrieval: Re-ranking
Hybrid Search로 후보 문서를 넓게 가져왔다면 관련 있는 것만 고르는 단계가 필요한데 이것이 Re-ranking입니다.
검색 결과 Top-20을 가져왔다고 합시다. 질문과 정말 관련 있는 청크도 있고, 키워드만 겹칠 뿐 실제로는 관련 없는 청크도 섞여 있습니다. 검색 결과를 그대로 넘기기엔 LLM이 잘못된 정보를 받아 답변 품질이 떨어질 수 있습니다.
Re-ranking은 이 20개 후보를 평가해서 관련 있는 청크만 선별하고 순서를 정렬하여 전달합니다.
- lost in the middlehttps://arxiv.org/abs/2307.03172
Post-Retrieval: 메타 데이터 필터링
청크의 부가 정보(메타데이터)를 기준으로 검색 대상을 사전에 걸러내는 기법입니다.
예시로 "2025년 외래 본인부담금"을 검색할 때 source_year = 2025 필터를 걸면, 2026년 청크는 검색 대상에서 아예 제외됩니다. 벡터 유사도가 아무리 높아도 필터에 걸리면 결과에 포함되지 않습니다.
| 메타데이터 | 용도 | 예시 |
|---|---|---|
| 출처 년도 | 다년도 문서에서 년도 혼동 방지 | source_year: 2025 |
| 문서 섹션 | 특정 주제의 청크만 검색 | section: 본인부담률 |
| 페이지 번호 | 원본 위치 추적 | page: 42 |
| 카테고리 | 문서 유형별 필터링 | category: 입원, category: 외래 |
메타데이터 필터링은 Hybrid Search나 Re-ranking과 다른 차원의 기법입니다. Hybrid Search가 "어떻게 검색할지"를 개선한다면, 메타데이터 필터링은 "어디서 검색할지"를 제한합니다. 두 기법을 함께 사용하면 더 효과적입니다.
정리: Advanced RAG 전체 그림
지금까지 살펴본 내용을 하나의 파이프라인으로 정리하면 다음과 같습니다.
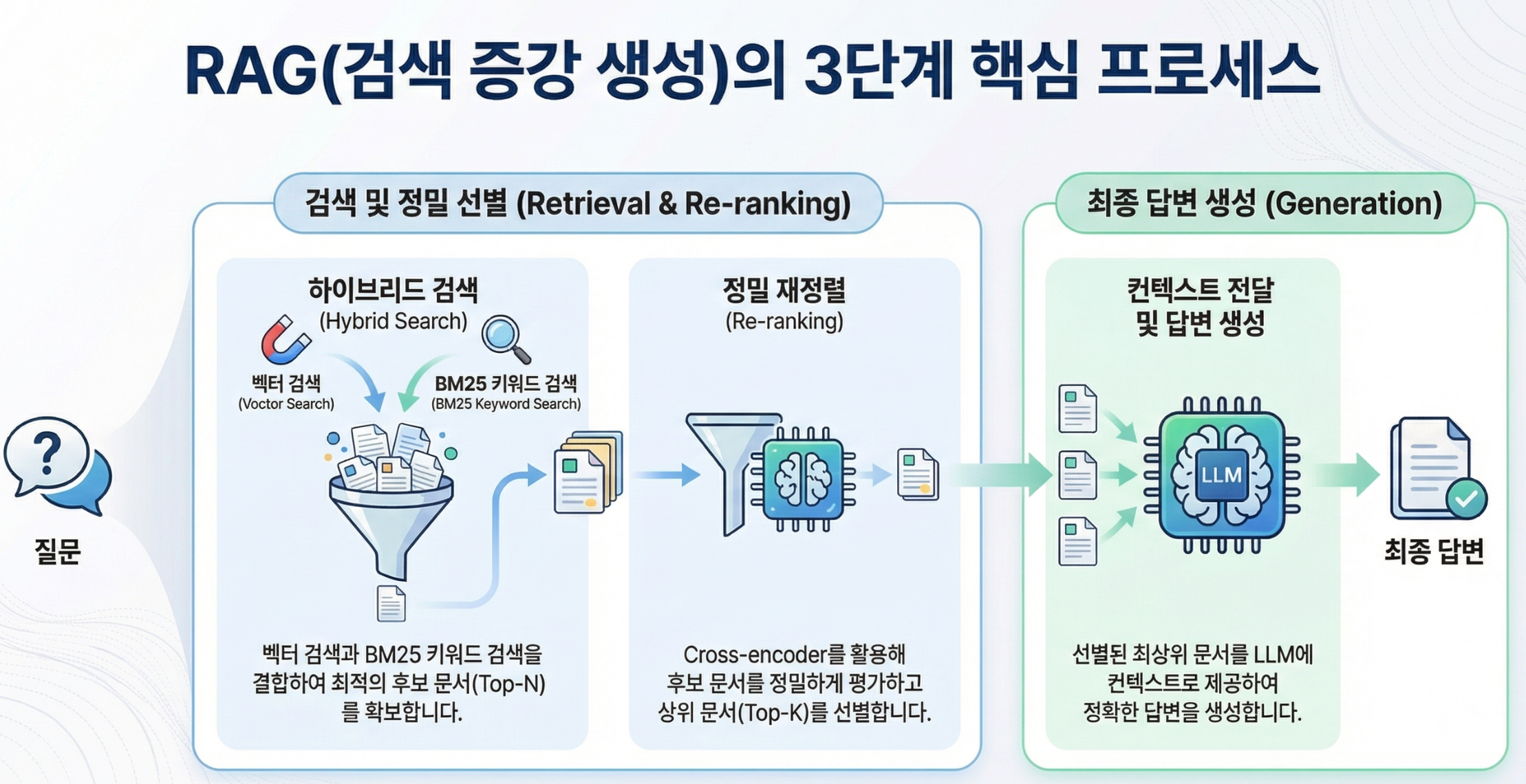
| 단계 | 기법 | 하는 일 |
|---|---|---|
| Pre-Retrieval | Hybrid Search | 벡터 + 키워드 검색을 결합하여 후보를 넓게 확보 |
| Post-Retrieval | Re-ranking | 후보 문서를 정밀 평가하여 관련성 높은 것만 선별 |
| Post-Retrieval | 메타데이터 필터링 | 출처, 날짜 등 메타데이터로 검색 범위를 제한 |
| Post-Retrieval | 컨텍스트 압축 | 청크에서 질문과 관련 있는 부분만 추출하여 전달 |
![[AI Agent] RAG 리뷰(3주차)](https://images.unsplash.com/photo-1705484229341-4f7f7519b718?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDV8fERhdGFzZXR8ZW58MHx8fHwxNzc1MjYyNzkxfDA&ixlib=rb-4.1.0&q=80&w=960)
![[AI Agent] RAG overview(3주차)](https://images.unsplash.com/photo-1766162357668-d41a4af974df?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDE5fHxDb250ZXh0fGVufDB8fHx8MTc3NDYxNzU3OXww&ixlib=rb-4.1.0&q=80&w=960)
![[LLM] VLM으로 표를 정확히 추출하기](https://images.unsplash.com/photo-1623667322051-18662ce6334c?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDl8fHBkZnxlbnwwfHx8fDE3NzIzNzMzODN8MA&ixlib=rb-4.1.0&q=80&w=960)
![[RAG] 한국어 Reranker 모델을 사용하여 RAG 성능 올리기](https://images.unsplash.com/flagged/photo-1578928534298-9747fc52ec97?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDF8fFJhbmtpbmd8ZW58MHx8fHwxNzU0MTM3OTQ4fDA&ixlib=rb-4.1.0&q=80&w=960)