[AI Agent] 1주차 리뷰
LLM의 작동 원리와 모델 선택 기준을 이해하고, 구조화된 출력과 프롬프트 분리를 통해 안정적인 AI 시스템을 구축하는 방법을 다룹니다.
![[AI Agent] 1주차 리뷰](https://images.unsplash.com/photo-1677442135703-1787eea5ce01?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDh8fEFJJTIwQWdlbnR8ZW58MHx8fHwxNzc0MDUwNDA2fDA&ixlib=rb-4.1.0&q=80&w=1200)
개요
1주차 과제는 LLM API를 직접 호출하는 환경 설정과 프롬프트에 구성에 대한 간략한 이해를 돕는 과제였습니다. 프롬프트를 어떻게 구성하는지, LLM 호출하기 위해 어떠한 구성이 포함되는지 확인하는 차원에서 수행한 과제로 동작을 구체적으로 이해하지 못하셔도 괜찮습니다.
같이 설명드리며 본격적으로 시작하려고 합니다.
LLM이란?
LLM은 Large Language Model의 약자로, 대규모 텍스트 데이터로 학습된 언어 모델입니다. 수십억에서 수조 개의 파라미터를 가진 거대한 신경망이 방대한 텍스트를 학습해서 주어진 입력에 대해 가장 적절한 다음 단어(토큰)를 예측하는 방식으로 동작합니다.
- 사용자 입력 → 시뮬레이션 우주에 대해 설명해줘
- 계산 방식
- 시뮬레이션 우주에 대해 설명해줘 시뮬레이션 (1)
- 시뮬레이션 우주에 대해 설명해줘 시뮬레이션 우주는 → (2)
- 시뮬레이션 우주에 대해 설명해줘 시뮬레이션 우주는 우리가 → (3)
- 시뮬레이션 우주에 대해 설명해줘 시뮬레이션 우주는 우리가 경험하는 → (4)
- …


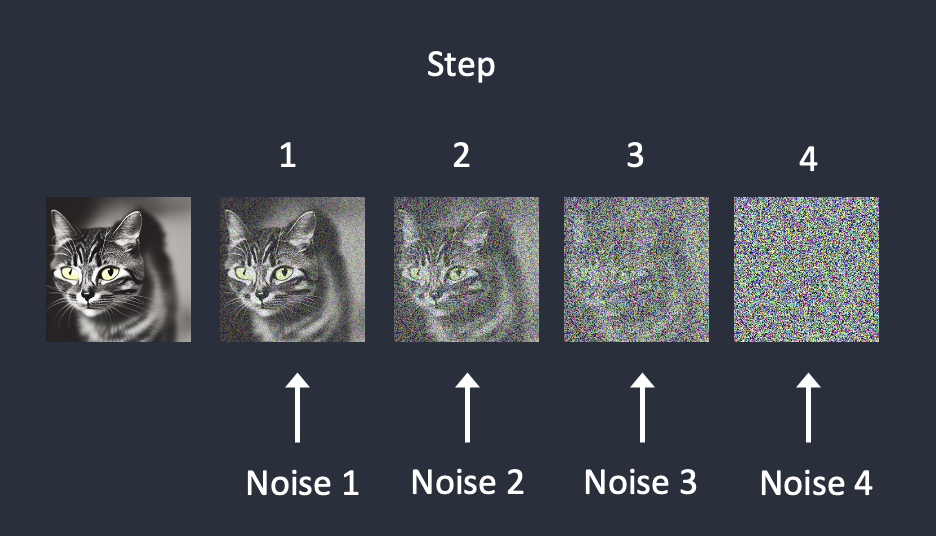
토큰 이란 (참고)
비용 계산, 컨텍스트 윈도우, max_tokens 파라미터 등 실무에서 마주치는 대부분의 개념이 토큰과 연결됩니다.
토큰은 쉽게 LLM이 텍스트를 처리하는 최소 단위입니다. 단어와 1:1로 대응하지 않고, subword(부분 단어) 단위로 텍스트를 쪼갭니다.
"unhappiness" → ["un", "happ", "iness"]
자주 등장하는 단어("the", "Hello")는 그 자체로 하나의 토큰이 되고, 드문 단어나 긴 단어는 여러 토큰으로 분리됩니다. 레고 블록으로 비유하면, 자주 쓰는 표현은 큰 블록 하나로, 드문 표현은 작은 블록 여러 개로 조립하는 것과 같습니다.
...
"Û": 151, # 인코딩으로 인한 변환
"Ü": 152,
"Ý": 153,
"Þ": 154,
"ß": 155,
"à": 156,
"á": 157,
"â": 158,
"ã": 159,
"ä": 160,
...
이러한 토큰이 얼마나 들어갔고 얼마나 출력됐는지를 비용으로 측정하게 됩니다.
{
"usage": {
"prompt_tokens": 550, # Input Token
"completion_tokens": 80, # Output Token
"total_tokens": 630
}
}
코드 없이 빠르게 토큰 수를 확인하려면 OpenAI Tokenizer 웹 도구를 사용할 수 있습니다.
한국어 텍스트가 어떻게 구성되는지 확인할 수 있습니다.
- https://platform.openai.com/tokenizer
- https://colab.research.google.com/github/HandsOnLLM/Hands-On-Large-Language-Models/blob/main/chapter02/Chapter 2 - Tokens and Token Embeddings.ipynb#scrollTo=7QlHLof3u8A3
Special Tokens
핵심 특징
LLM의 핵심 특징은 세 가지입니다.
1. 텍스트 입력 → 텍스트 출력 (Next Token Prediction)
LLM은 본질적으로 "다음에 올 토큰을 예측하는 기계"입니다. "오늘 날씨가"라는 입력을 받으면, 학습 데이터에서 이 문맥 뒤에 자주 등장했던 토큰들의 확률 분포를 계산하고 그중 하나를 선택합니다. 이 과정을 반복하여 전체 응답을 생성합니다.
2. 패턴 학습, 규칙 프로그래밍 아님
전통적인 프로그래밍은 규칙을 명시적으로 코딩합니다. "주문 취소"라는 키워드가 있으면 intent=cancel로 분류하라는 식입니다. LLM은 다릅니다. 수십억 개의 텍스트에서 패턴을 학습하여, "주문을 취소하고 싶어요"뿐 아니라 "이거 안 살래요", "결제 전으로 돌려주세요" 같은 다양한 표현도 취소 의도로 파악할 수 있습니다.
3. 하나의 모델, 다양한 작업
번역, 요약, 분류, 코드 생성, 질의응답 등 별도의 모델을 만들 필요 없이 하나의 LLM으로 수행할 수 있습니다. 프롬프트(지시문)를 바꾸는 것만으로 동일한 모델이 다른 작업을 수행합니다. 이 과제에서는 "분류"라는 하나의 작업에 집중하지만, 같은 모델로 고객 응대 문구 생성이나 티켓 요약도 가능합니다.
왜 "Large"인가
"Large"는 두 가지를 의미합니다.
첫 번째는 파라미터 수입니다. GPT-4는 수천억 개 이상의 파라미터를 가진 것으로 알려져 있고 최신 모델들은 수조 개에 달합니다. 파라미터가 많을수록 더 복잡한 패턴을 학습할 수 있습니다.
둘째, 학습 데이터 규모입니다. 웹 페이지, 책, 코드, 논문 등 수조 토큰 규모의 텍스트로 학습합니다. 이 방대한 데이터에서 언어의 패턴과 지식을 추출합니다.
로컬에서 AI 모델을 구축하신 분이라면 확인하셨겠지만 8B(80억), 12B(120억) 이런식의 숫자가 붙어있습니다. 이는 모델이 가진 연산량이라고 이해할 수 있으며 더 복잡한 추론을 가능하게 합니다.
또한 상대적으로 파라미터 수, 학습 데이터 규모가 작은 모델들을 순차적으로 sLM, sLLM
- https://huggingface.co/models
- 토크나이저와 파라미터
Transformer 아키텍처
LLM의 기반이 되는 Transformer 아키텍처는 이 과정에서 깊게 다루지 않습니다. 이 과정의 관점은 내부 구조보다 API를 통한 입출력 제어에 집중합니다. LLM을 자동차 엔진으로 비유하면 엔진의 내부 구조를 모두 이해하지 않아도 운전할 수 있는 것과 같습니다.
참고삼아 Transformer 아키텍처에 관련한 자료를 첨부했습니다.
- 원본 논문: Attention Is All You Need (2017)
- 시각적 설명: The Illustrated Transformer (Jay Alammar)
- 현대의 아키텍쳐: https://sebastianraschka.com/llm-architecture-gallery/
AI 환경구성
다양한 모델
현재 LLM 생태계는 크게 세 개 티어로 나눌 수 있습니다.
Frontier 모델은 GPT-5, Claude Sonnet 4.5 등입니다. 복잡한 추론, 긴 문맥 처리, 모호한 입력에서 차이를 보입니다. 가장 높은 정확도를 제공하지만 비용도 가장 높습니다.
Mid 모델은 GPT-4o-mini, Claude Haiku 4.5 등입니다. 비용 대비 성능이 최적화되어 있고, 분류처럼 출력이 구조화된 작업에서는 프론티어 모델과 정확도 차이가 미미합니다. 응답 속도도 빠릅니다.
Open Source 모델은 DeepSeek-V3.2, Qwen 3 235B, Llama 4 Maverick 등입니다. 직접 운영하려면 GPU 인프라가 필요하지만, Hugging Face Inference API를 통해 무료로 호출할 수도 있습니다.
| 티어 | 모델 예시 | 입력 비용 (1M tokens) | 분류 적합도 | 비고 |
|---|---|---|---|---|
| Frontier | GPT-5, Claude Sonnet 4.5 | $1.25-$3.00 | 최고 정확도 | 12건 기준 비용 무시 가능 |
| Mid | GPT-4o-mini, Claude Haiku 4.5 | $0.15-$1.00 | 빠른 작업 | 비용 대비 성능 최적 |
| Open Source | DeepSeek-V3.2, Qwen 3 235B, Llama 4 Maverick | - | 양호 | GPU 인프라 관리 |
AI 모델 선택 이유
프론티어 모델이 항상 최선은 아닙니다.
GPT-5 혹은 Claude Sonnet 4.6 등은 복잡한 추론이나 계산, 긴 문맥 처리를 수행하지만 4개 필드를 채우는 구조화 분류는 중간 티어 모델 혹은 작은 모델로도 충분한 정확도를 낼 수 있습니다.
12건 규모에서는 비용 차이가 무시 가능하지만, 수천 건 이상으로 확장할 때 모델 선택이 비용에 직접 영향을 줍니다.토큰 당 비용을 계산해보면 10~20배 정도 차이가 발생하며 이것은 AI를 장기적으로 운영하기 위해 중요합니다.
또한 단순히 비용적인 측면 뿐만 아니라 TPS(토큰이 생성되는 시간) 혹은 TTFT(첫 토큰이 도착하는 시간)에 영향을 주게 되며 이는 Agent의 동작 시간, 사용자 경험의 중요한 영향을 줄 수 있기에 중요합니다.
과제를 해결하기 위해 구성해야했던 점
구조화된 출력
LLM 출력은 기본적으로 비정형 텍스트라서 다음 문제가 발생
- 파싱 실패: JSON 기대했는데 마크다운이나 설명 텍스트가 섞여 나옴
- 스키마 불일치: 필드 누락, 타입 오류, 추가 필드 등
- 파이프라인 중단: 후속 시스템이 정해진 포맷을 기대하므로 하나라도 틀리면 전체 실패
- 재시도 비용: 출력 실패 시 재호출 → 비용/지연 증가
에이전트 파이프라인에서 모델의 출력을 제어하고
from vllm import LLM, SamplingParams
from pydantic import BaseModel
class ExtractedData(BaseModel):
name: str
age: int
skills: list[str]
llm = LLM(model="Qwen/Qwen3-8B")
params = SamplingParams(
temperature=0.1,
max_tokens=512,
guided_decoding={
"json_object": ExtractedData.model_json_schema() # JSON Schema 전달
}
)
outputs = llm.generate(["텍스트에서 정보 추출..."], params)
[프롬프트만] ← 보장 없음
└─ 순수 프롬프트 엔지니어링
[프롬프트 + 학습] ← 높은 확률, 100%는 아님
└─ Claude tool_use (시스템 프롬프트 주입 + tool_use 포맷 학습)
[디코딩 레벨 강제] ← 100% 보장
└─ OpenAI Structured Outputs (constrained decoding)
└─ vLLM guided_decoding (Outlines/FSM)
구조화된 출력이 중요한 이유
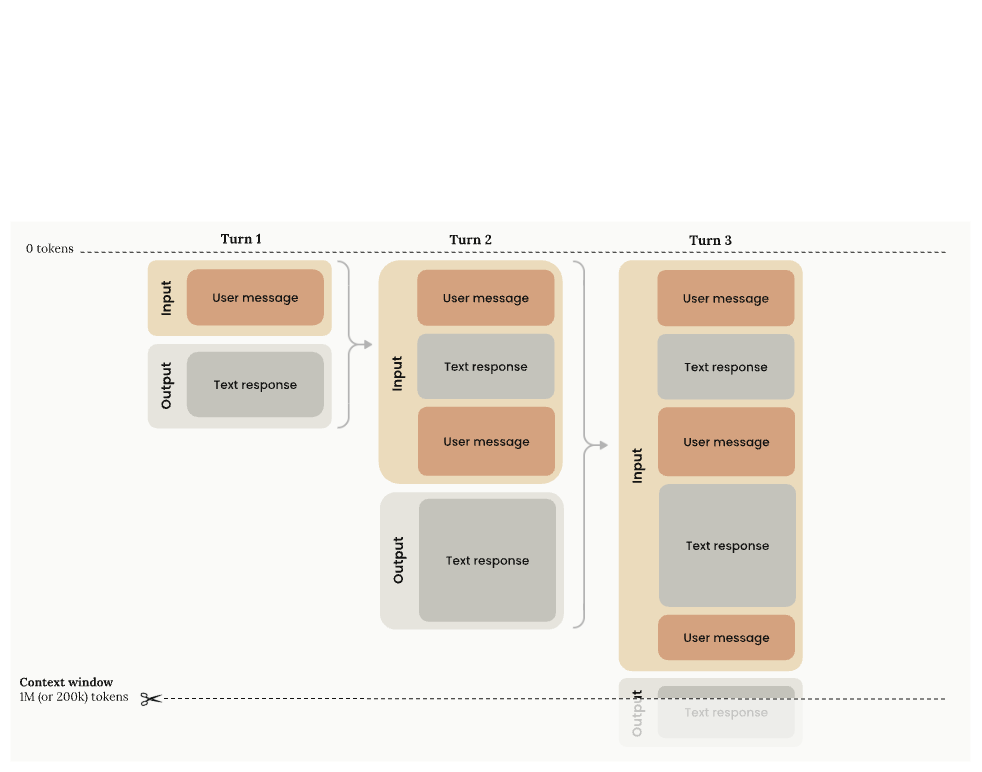
프롬프트 구성 - system과 user 메시지 분리
LLM API에서 메시지는 역할(role)로 구분됩니다.
system: 모델의 행동 규칙, 분류 기준, 출력 형식 등 지속적 지시를 담습니다.user: 실제 처리할 입력 데이터를 담습니다. 이 과제에서는 고객 문의 텍스트가 여기에 들어갑니다.
messages = [
{"role": "system", "content": "고객 문의를 분류하여 JSON으로 반환하세요..."},
{"role": "user", "content": "주문한 신발 사이즈를 변경하고 싶어요"},
]
단순히 하나의 프롬프트에 모두 넣어도 동작은 합니다. 하지만 분리하면 두 가지 이점이 있습니다.
[System Prompt 최적화]
연구에 따르면 system과 user를 분리할 경우, 모델이 system prompt에 더 높은 가중치를 할당합니다.
하나로 합칠 때보다 지시사항을 잘 준수합니다.
[Instruction hierarchy]
OpenAI는 system prompt를 user prompt보다 높은 우선순위로 처리하도록 모델을 학습시킵니다. 이는 user 입력에 포함될 수 있는 의도치 않은 지시(예: "이전 지시를 무시하고...")로부터 시스템을 보호하는 역할을 합니다.
고객 문의 텍스트에 어떤 내용이 들어가도 system prompt의 분류 규칙을 우선합니다.
- 참고: The Instruction Hierarchy (2024, OpenAI)
무작위성과 다양성 - 파라미터 제어
LLM의 출력은 블랙박스입니다. 확률을 계산하는 것으로 동일한 입력을 넣어도 매번 다른 결과가 나올 수 있습니다.
Temperature
temperature는 다음 토큰의 확률을 결정할 수 있습니다.
temperature 낮음 (→ 0): 확률 차이가 벌어짐
"반갑습니다" 60% ← 거의 항상 이것만 선택
"안녕하세요" 25%
"..." 15%
temperature 높음 (→ 1): 확률이 고르게 펴짐
"반갑습니다" 35% ← 어느 것이든 선택될 수 있음
"안녕하세요" 33%
"..." 32%
- 0에 가까울수록 가장 확률이 높은 토큰을 결정적으로 선택합니다. 같은 입력을 넣으면 같은 출력이 나올 가능성이 높습니다.
- 1에 가까울수록 확률 분포가 평탄해져서 다양한 토큰이 선택될 수 있습니다. 같은 입력이라도 매번 다른 출력이 나올 수 있습니다.
max_tokens
모델 출력의 최대 토큰 수를 제한하는 파라미터입니다. 이 과제의 JSON 출력은 약 50-80 tokens입니다. 예상 출력의 2~3배인 256으로 설정하면 충분합니다.
너무 작으면 JSON이 중간에 잘려서 파싱이 실패합니다:
{"intent": "order_ch
너무 크면 JSON 뒤에 불필요한 설명 텍스트가 붙을 가능성이 생깁니다.
정리
주요 내용을 정리하면 다음과 같습니다
- 적절한 모델 선택
- 메시지 구조 분리(System, User)
- Temperature과 max_tokens 설정
from openai import OpenAI
client = OpenAI()
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": ticket_text},
],
temperature=0.0,
max_tokens=256,
)
AI Framework
참고할만한 논문
LLM 출력 구조 -- Autoregressive 생성의 이해
LLM은 텍스트를 한 번에 생성하지 않습니다. 한 토큰씩 순차적으로 생성합니다.
이것을 autoregressive 방식이라 합니다.
고객 문의를 분류하세요"라는 입력에 대해 {"intent": "order_change", ...}를 출력할 때, 모델은 { -> " -> intent -> " -> : -> ... 순서로 한 토큰씩 생성합니다. 그리고 이미 생성한 토큰이 다음 토큰 선택에 영향을 줍니다.
1. Snowball Effect -- 초기 오류가 연쇄적으로 확산됩니다
모델이 첫 필드에서 잘못된 분류를 하면, 이후 필드도 그에 맞춰 일관되게 잘못될 수 있습니다. 예를 들어 intent를 shipping_issue로 잘못 분류하면, route_to도 shipping_ops로 따라가는 식입니다. 모델은 자기가 이미 출력한 토큰에 구속되기 때문입니다. 연구에 따르면 GPT-4조차 자기 오류의 87%를 사후에 식별할 수 있지만, 생성 중에는 이미 출력한 토큰을 되돌릴 수 없습니다.
- 참고: How LM Hallucinations Can Snowball (ICML 2024)
2. Beginning Lock-in Effect -- 처음 몇 토큰이 전체 경로를 결정합니다
prefix 토큰(처음 생성한 토큰들)이 이후 추론 경로를 강하게 구속합니다. 중간에 교정을 시도해도 최대 9.2%만 회복 가능하다는 연구 결과가 있습니다. 이것이 system prompt의 초기 지시가 왜 중요한지를 설명합니다. 모델이 첫 토큰부터 올바른 방향으로 생성을 시작하도록 유도해야 합니다.
- 참고: Beginning Lock-in Effect (BLE) (2025)
과제 리뷰
작성하신 프롬프트의 공통 특징을 정리했습니다
- temperature & max-tokens
urgency필드에서 파싱실패가 많이 발생(지침이 없음)- few-shot 프롬프팅과 휴리스틱
- 페르소나와 메타인지. MoE
- 영어 토큰
- Pydantic
![[LLM] VLM으로 표를 정확히 추출하기](https://images.unsplash.com/photo-1623667322051-18662ce6334c?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDl8fHBkZnxlbnwwfHx8fDE3NzIzNzMzODN8MA&ixlib=rb-4.1.0&q=80&w=960)
![[SageMaker] SageMaker Jumpstart를 사용한 LLM Fine Tuning - Supervised fine tuning (SFT)](https://images.unsplash.com/photo-1648652678596-d3873bd0c157?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDQ2fHxTdXBlcnZpc2VkfGVufDB8fHx8MTc1MzgzMTg2Mnww&ixlib=rb-4.1.0&q=80&w=960)
![[SageMaker] SageMaker Jumpstart를 사용한 LLM Fine Tuning - DAFT(Domain-Agnostic Fine-Tuning)](https://images.unsplash.com/photo-1563207769-3343cb585fcb?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDZ8fHR1bmluZ3xlbnwwfHx8fDE3NTM4MzE2Mjl8MA&ixlib=rb-4.1.0&q=80&w=960)
![[SageMaker] SageMaker Jumpstart Evaluation(Ground Truth)을 구성하여 사람이 LLM 평가하기](https://images.unsplash.com/photo-1632144130358-6cfeed023e27?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDN8fEh1bWFuJTIwRmVlZGJhY2t8ZW58MHx8fHwxNzUzODMxNDUwfDA&ixlib=rb-4.1.0&q=80&w=960)