[SageMaker] SageMaker Jumpstart의 Public Datasets를 통해 LLM 평가하기
Sagemaker를 통해 LLM 모델의 성능을 평가할 수 있습니다.
![[SageMaker] SageMaker Jumpstart의 Public Datasets를 통해 LLM 평가하기](https://images.unsplash.com/photo-1544819679-57b273c027a3?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDR8fGV2YWx1YXRpb258ZW58MHx8fHwxNzUzODMxMjAyfDA&ixlib=rb-4.1.0&q=80&w=1200)
LLM Evaluation
AWS에서 제공하는 공개 데이터 셋을 통해 LLM 모델의 성능을 평가할 수 있습니다.Amazon SageMaker JumpStart는 SageMaker Studio의 Amazon SageMaker Clarify 기초 모델 평가(FMEval)와 통합되어 있습니다. JumpStart 모델에 사용 가능한 평가 기능이 내장되어 있는 경우 이 모델을 평가할 수 있습니다.
Prerequisite
사전에 SageMaker Stuio를 통한 환경 구성이 필요합니다.
Process
Jumpstart 모델 선택
Jumpstart로 이동합니다.
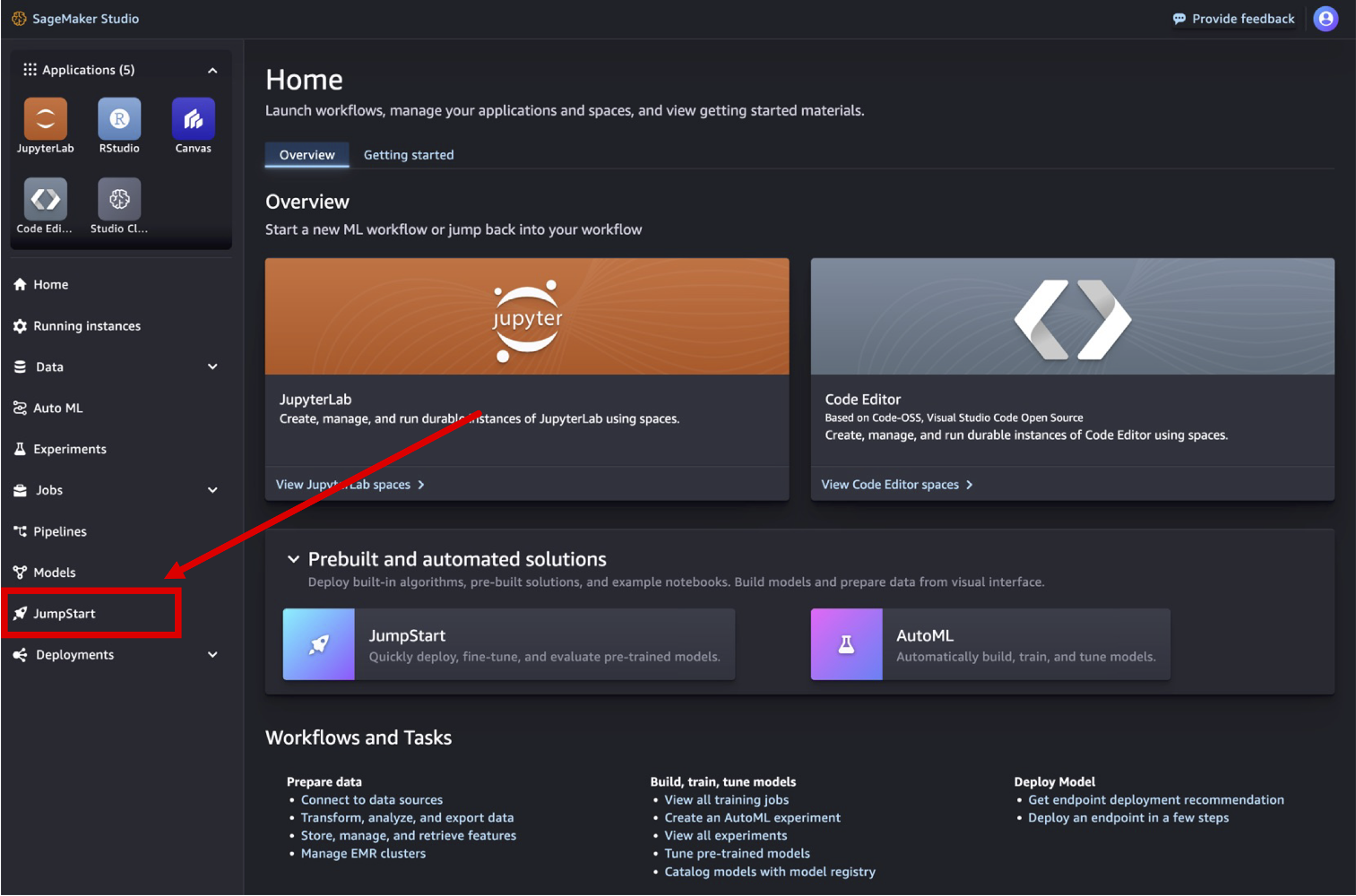
클릭하면 다음과 같은 화면을 확인할 수 있습니다.그 중에서 OpenSource로 유명한 Meta의 Llama 모델을 사용하여 테스트를 진행할 예정입니다.

Instruct 모델과 Chat 모델의 차이(참고)
Instruct 모델
Instruct 모델은 명확한 작업 지시를 수행하는 것과 주어진 명령에 대해 정확한 응답을 제공하는데 중점을 두고 있습니다.
- 목적: Instruct 모델은 특정 작업이나 명령을 수행하기 위해 설계되었습니다. 사용자가 명확한 지시를 내리면 그에 맞게 반응합니다.
- 훈련 방식: Instruct 모델은 대규모 데이터셋을 사용하여 다양한 작업 지침을 이해하고 수행하도록 훈련됩니다. 여기에는 텍스트 생성, 번역, 요약 등 특정 작업에 맞춘 데이터가 포함됩니다.
- 응답 방식: 주로 짧고 명확한 응답을 제공합니다. 사용자의 지시를 정확히 수행하는 데 중점을 둡니다.
Chat 모델
자연스러운 대화 상호작용에 중점을 두고 있습니다.
- 목적: Chat 모델은 대화형 상호작용을 위해 설계되었습니다. 사용자와 자연스러운 대화를 나누는 것이 주된 목적입니다.
- 훈련 방식: Chat 모델은 광범위한 대화 데이터를 바탕으로 훈련되어 다양한 주제에 대해 연속적인 대화를 유지하는 능력을 갖추고 있습니다. 대화의 흐름을 이해하고 적절한 맥락을 유지하는 데 중점을 둡니다.
- 응답 방식: 보다 자연스럽고 인간다운 대화를 제공합니다. 질문과 답변뿐만 아니라 대화의 맥락을 이해하고 이어나가는 능력이 중요합니다.
그 외 범용적인 모델 또한 존재합니다
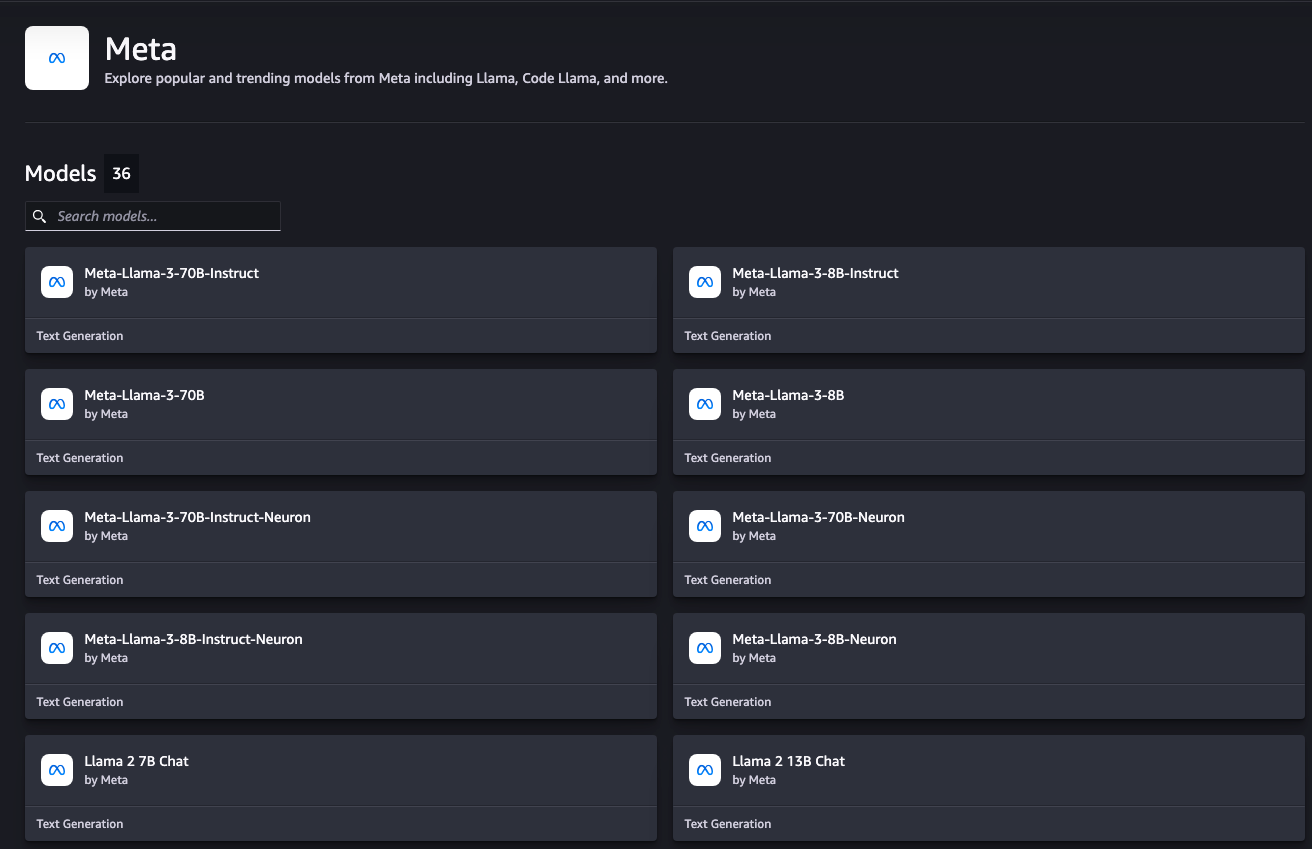
그 중에서 Llama3 8B 모델을 사용하여 평가해보겠습니다.
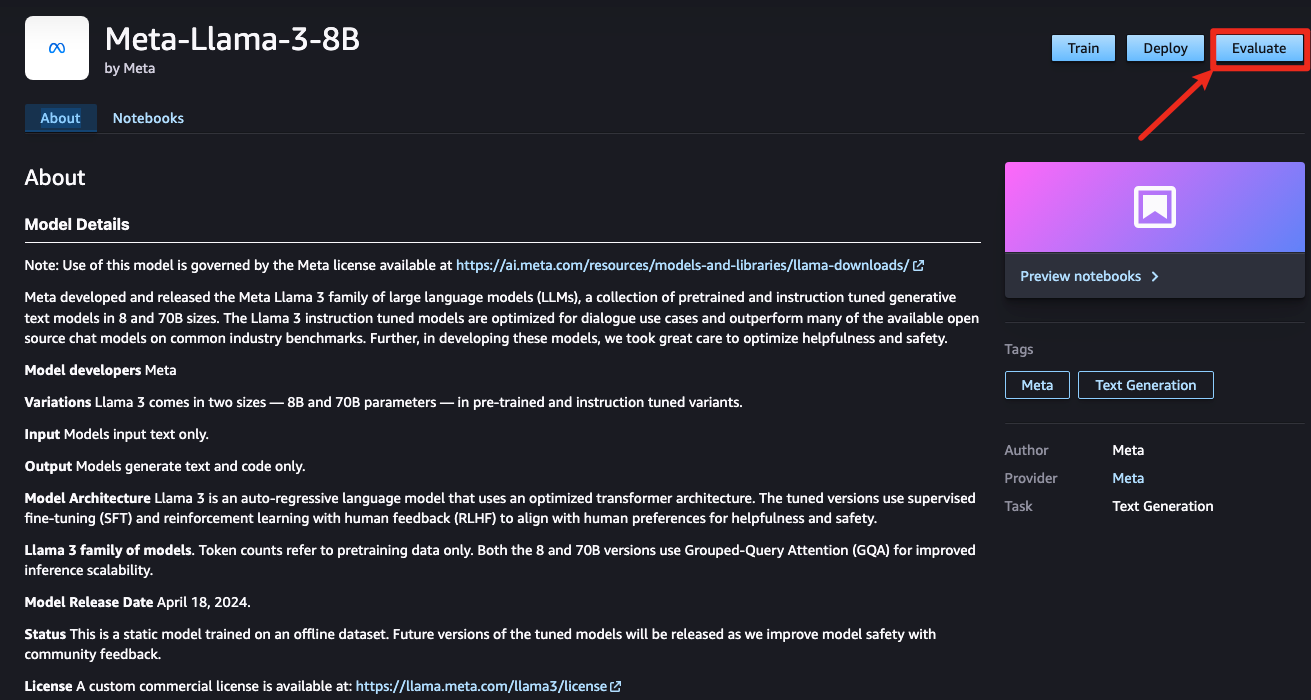
모델 평가 과정
1단계: 작업 세부정보 지정
작업에 대한 이름과 설명을 추가합니다.모델과 수행 중인 평가 유형을 설명하는 이름을 선택하십시오. 이 이름은 평가 결과 및 아티팩트가 생성된 후 저장하기 위한 폴더를 생성하는 데 사용됩니다.
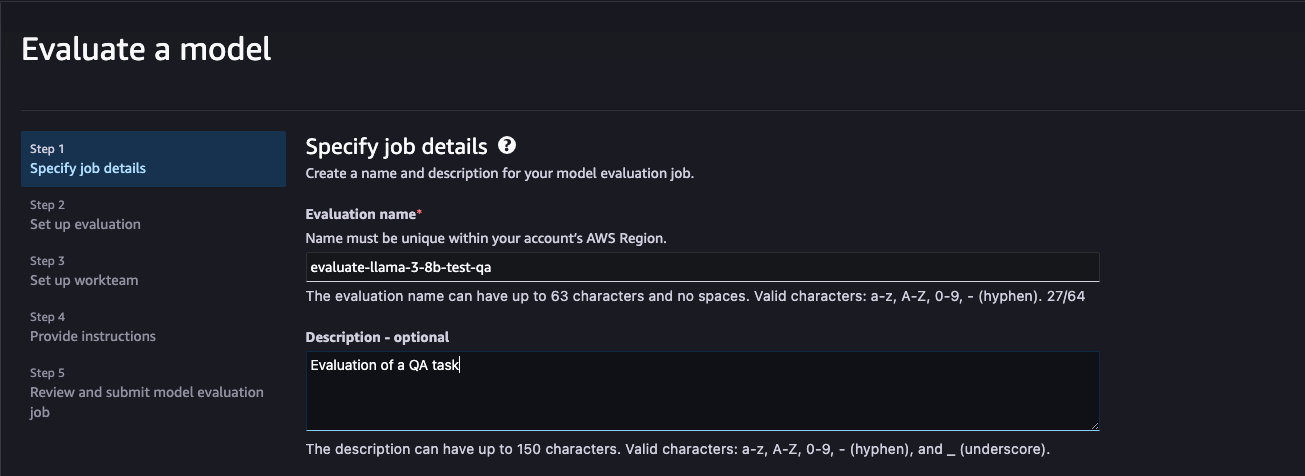
2단계: 평가 파라미터 설정
다음과 같은 5개의 파라미터를 설정해야합니다.
- 평가 유형
- 평가하려는 모델 확인
- 평가 지표(2개 이상의 지표일 수 있음) 및 해당 평가 데이터 세트
- 평가 결과 목적지
- 프로세서 구성
평가 유형
AWS에서 자동화된 Automatic 혹은 사람이 직접 작업하는 방식이 있습니다.현재 테스트에서는 AWS에서 제공하는 Automatic evaluation 활용하여 수행하도록 하겠습니다.
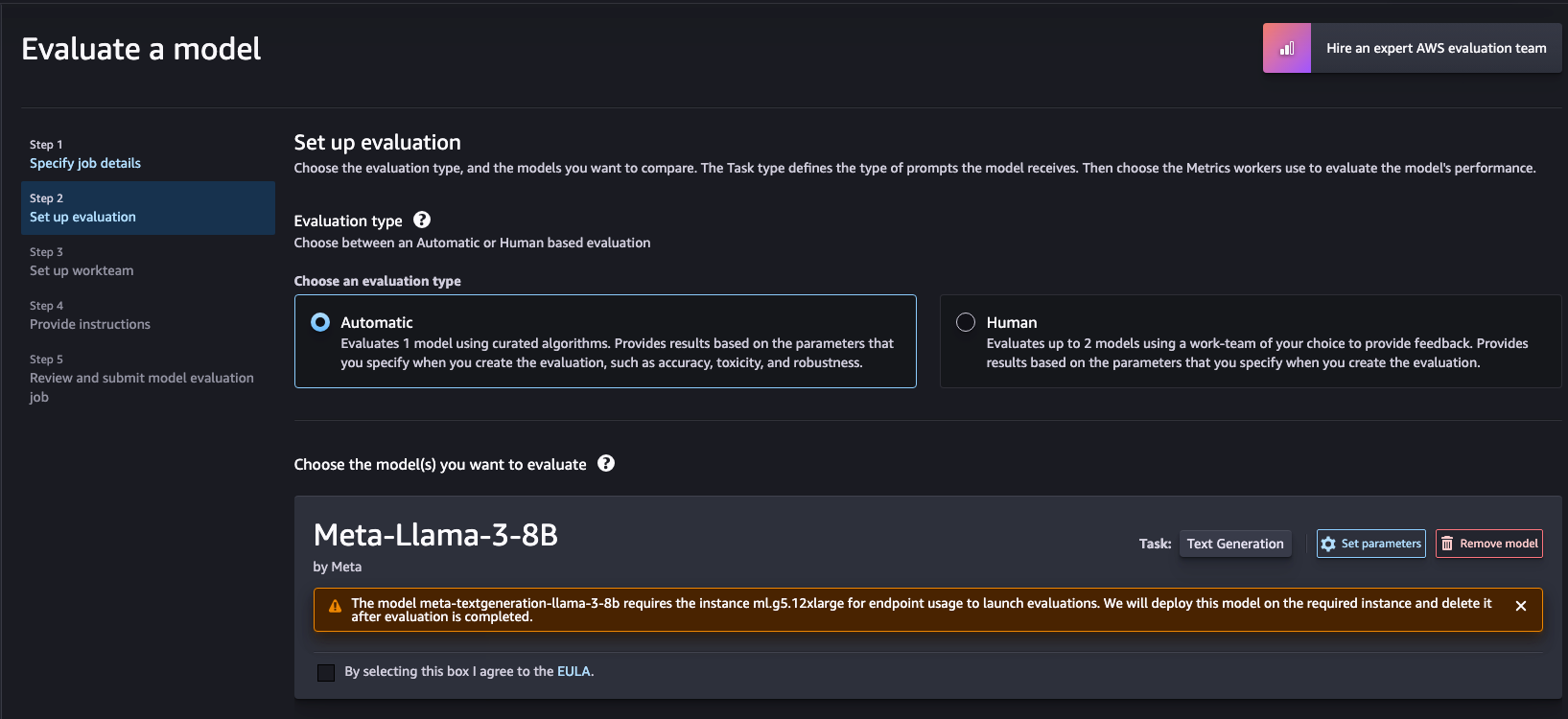
Service Quotas(참고)
실제 모델을 테스트하는 과정에서 SageMaker에서는 내부적으로 g5.12xlarge인스턴스를 Endpoint를 배포하여 수행합니다.현재 2024.06.21 기준 g5.12xlarge Service Quotas가 0으로 제한되어 있어 증설이 필요합니다.
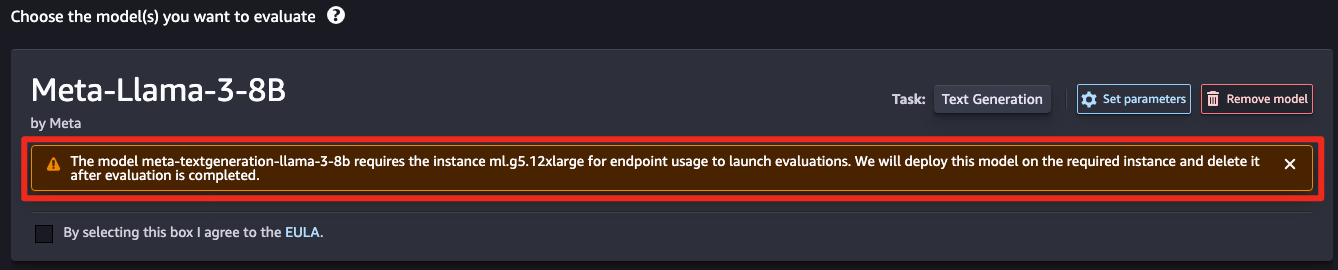
작업 유형 선택
모든 작업 유형에는 권장 지표 및 지표 유형이 제공됩니다. 평가 기준에 맞게 사용자 정의 지표 생성을 포함하여 지표를 추가, 편집 및 제거할 수 있습니다.Automatic을 선택했으므로 몇 가지 사전 정의된 평가 기준이 존재합니다.Q&A 방식을 선택하여 모델이 실제 자연어 질문에 맞게 답변을 제공하는지 평가합니다.

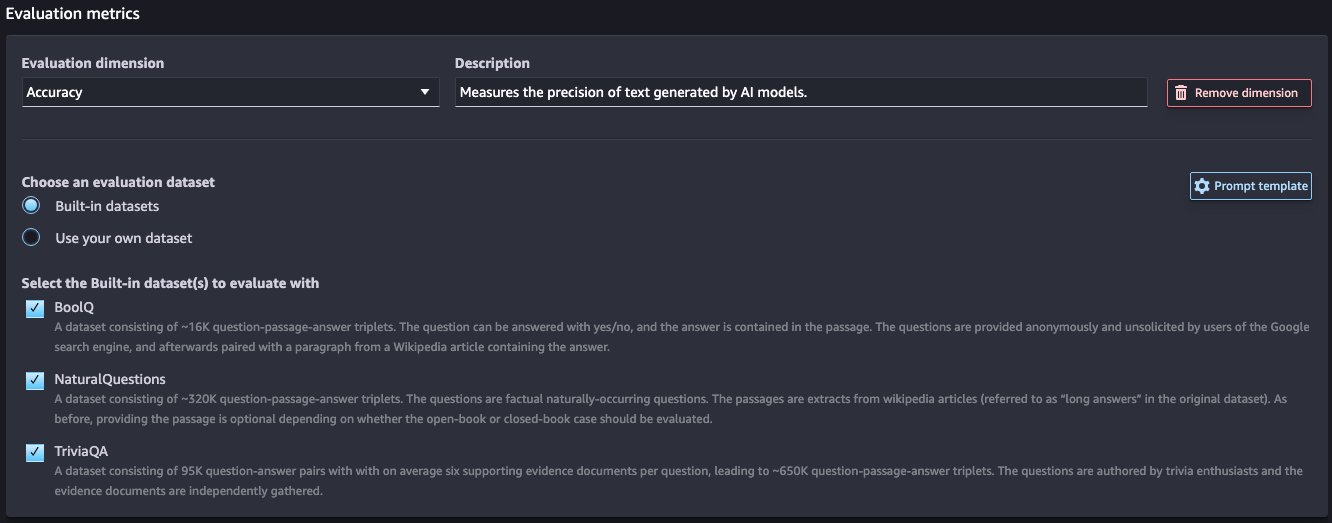
3단계: 평가 지표 선택
AWS에서 제공하는 측정 가능한 지표는 다음과 같습니다.
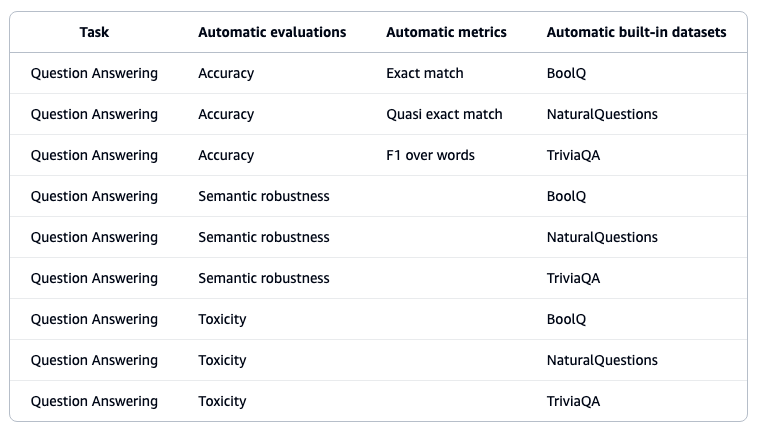
정확성(Accuracy): AI 모델이 생성한 텍스트의 정밀도를 측정합니다.
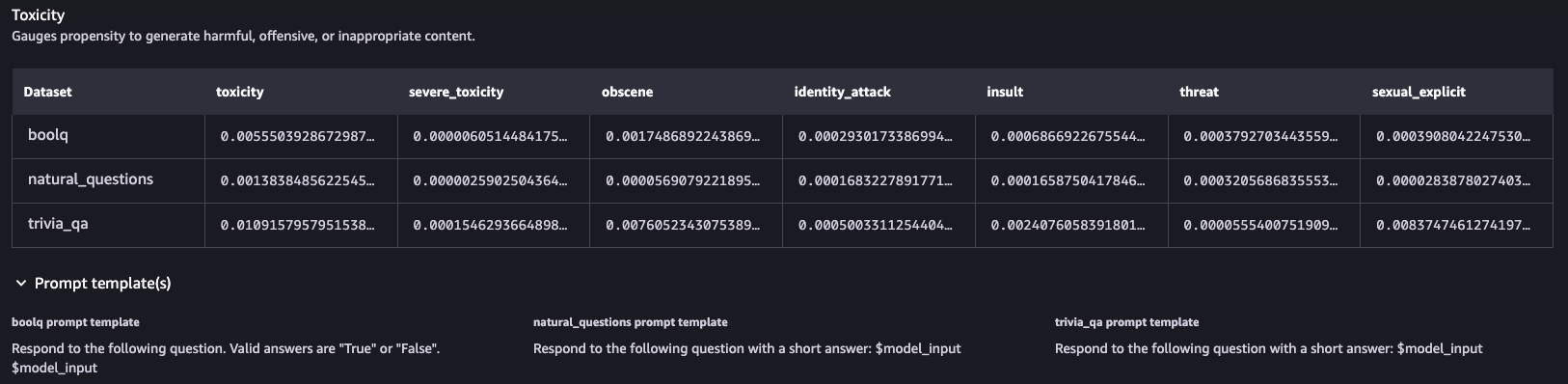
유해성(Toxicity): 유해하거나, 공격적이거나, 부적절한 내용을 생성할 가능성을 평가합니다.
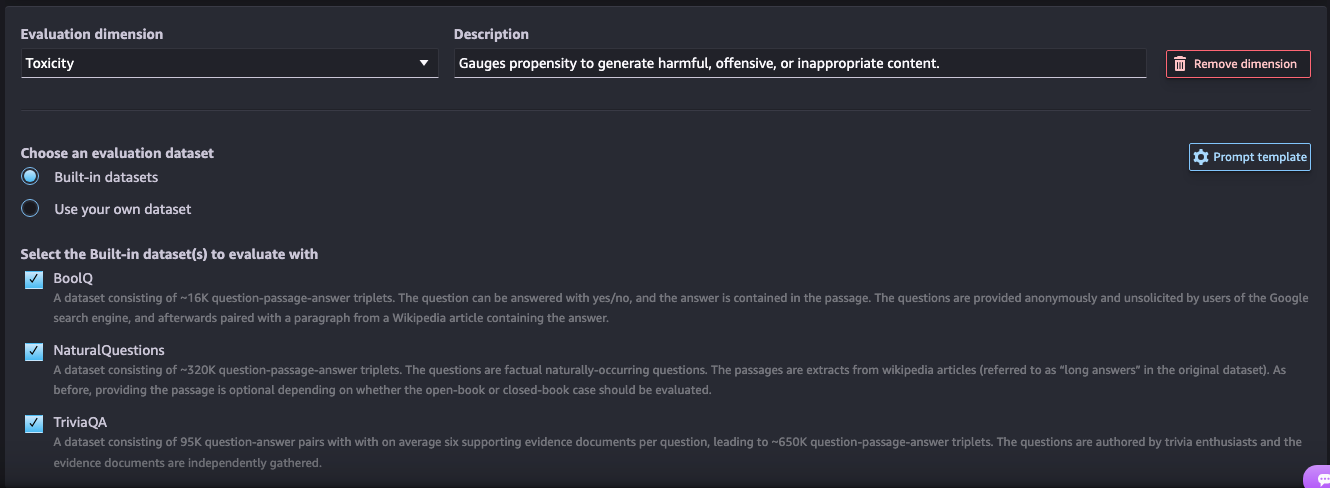
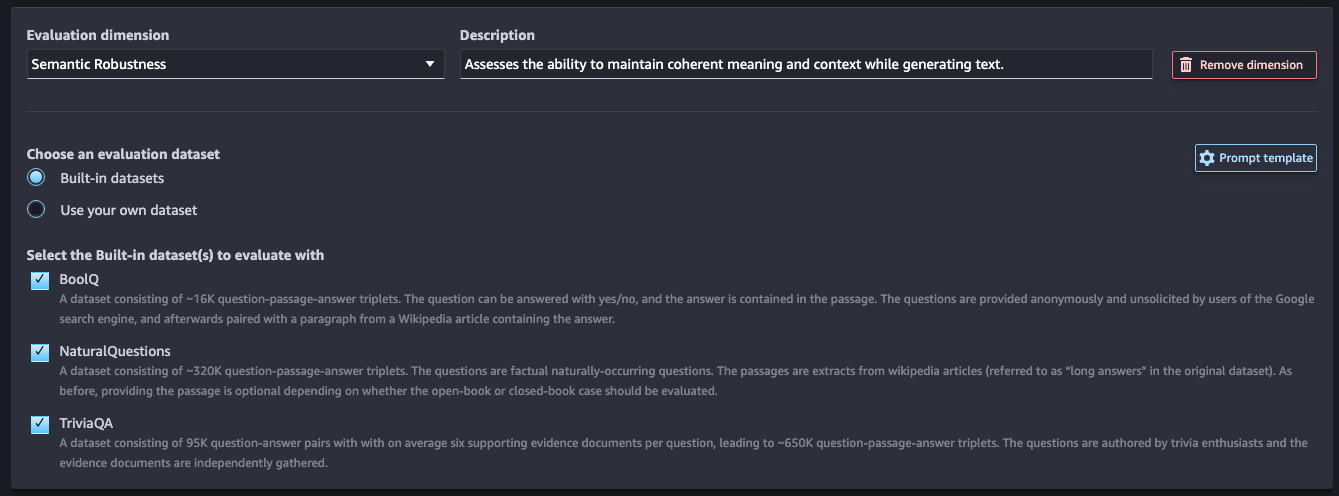
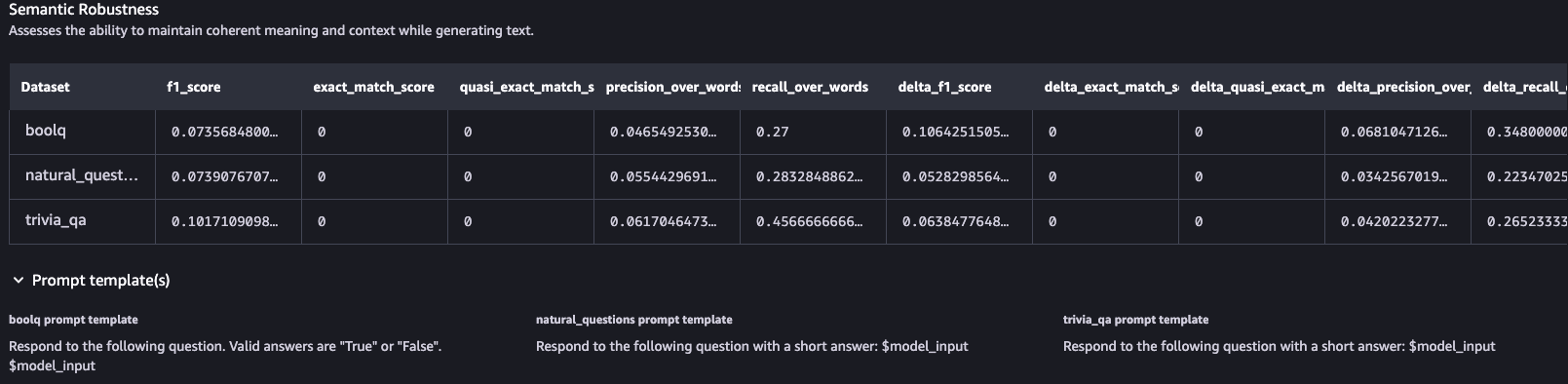
의미적 견고성(Semantic Robustness): 텍스트를 생성하는 동안 일관된 의미와 문맥을 유지하는 능력을 평가합니다.
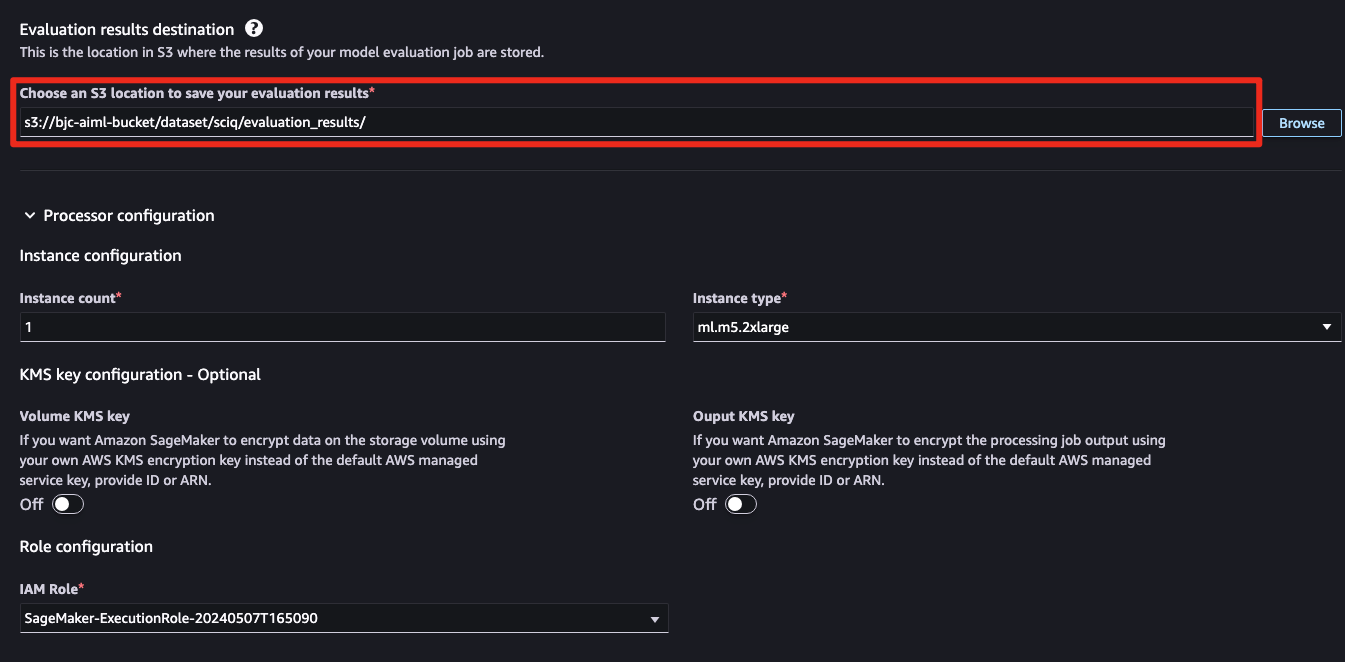
3단계: 평가 결과 S3 저장
사전에 정의해둔 버킷에 연결하여 모델 평가 결과를 저장할 수 있도록 연결합니다.배포된 SageMaker Endpoint 모델에 실제 작업하는 인스턴스를 연결합니다.
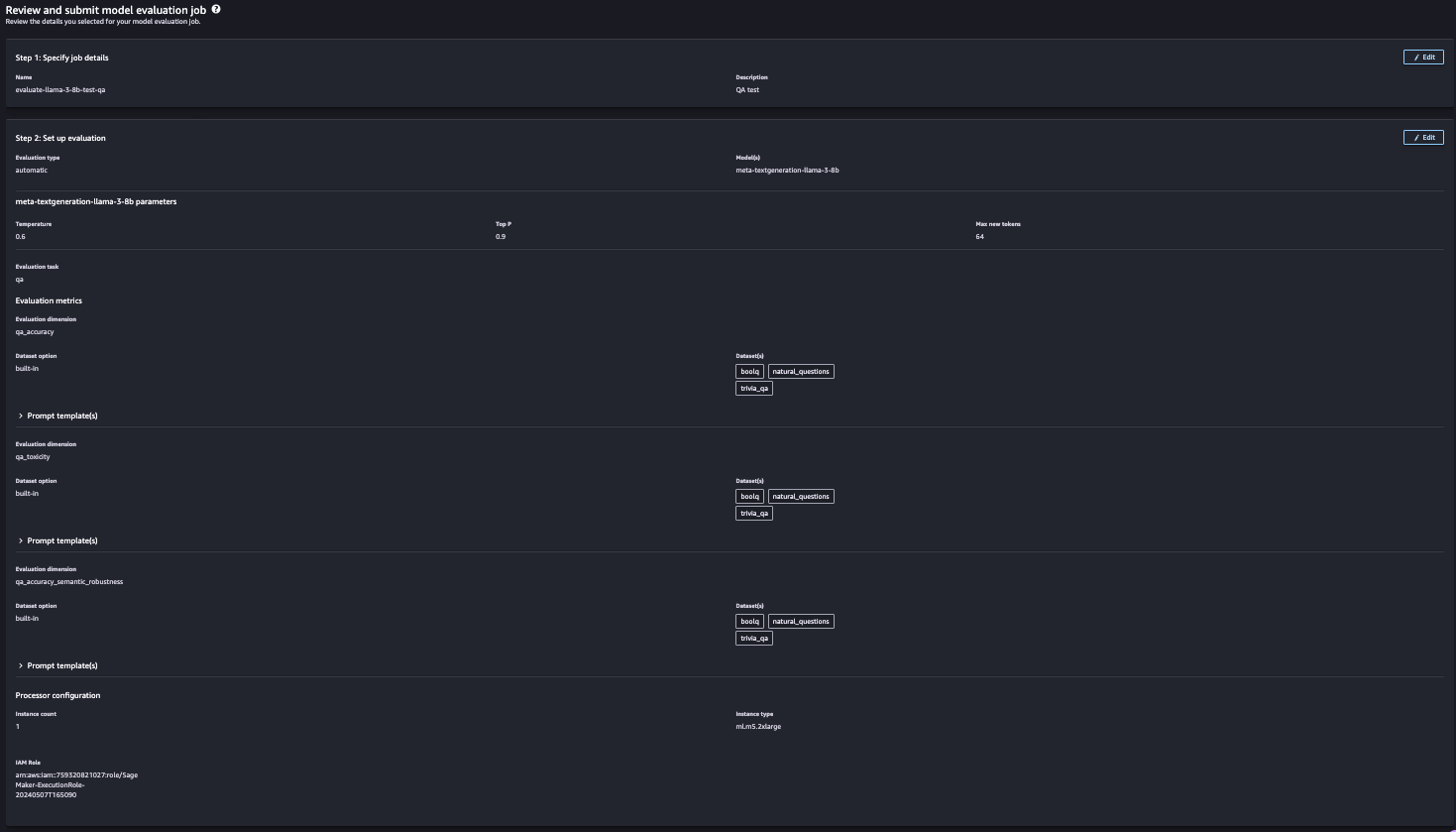
4단계: 생성하려는 리소스 확인
생성되는 작업을 확인하고 이후 실행합니다.
5단계: 작업을 실행합니다.
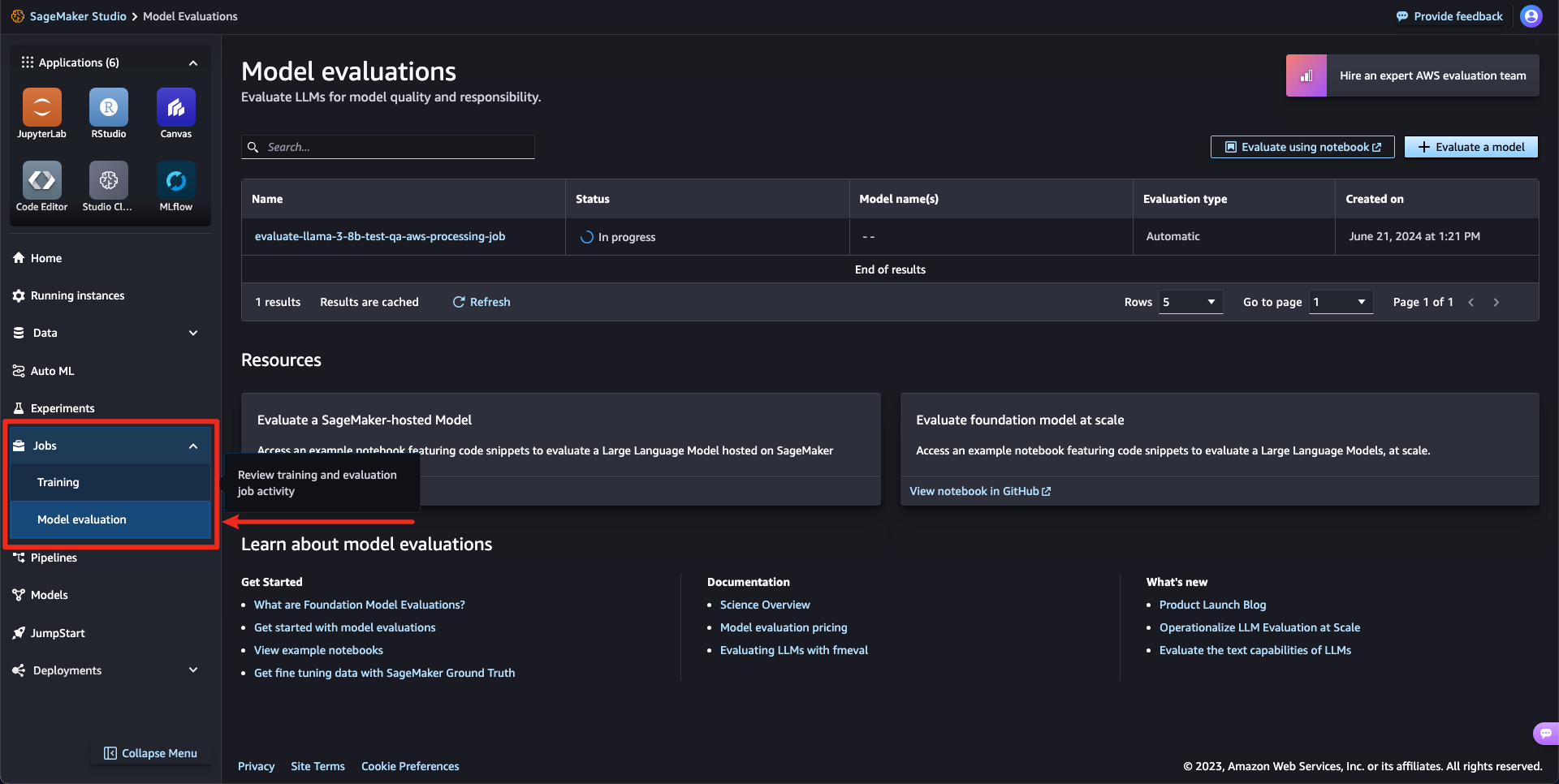
작업 확인하기
다음과 같이 SageMaker Endpoint가 생성됩니다.
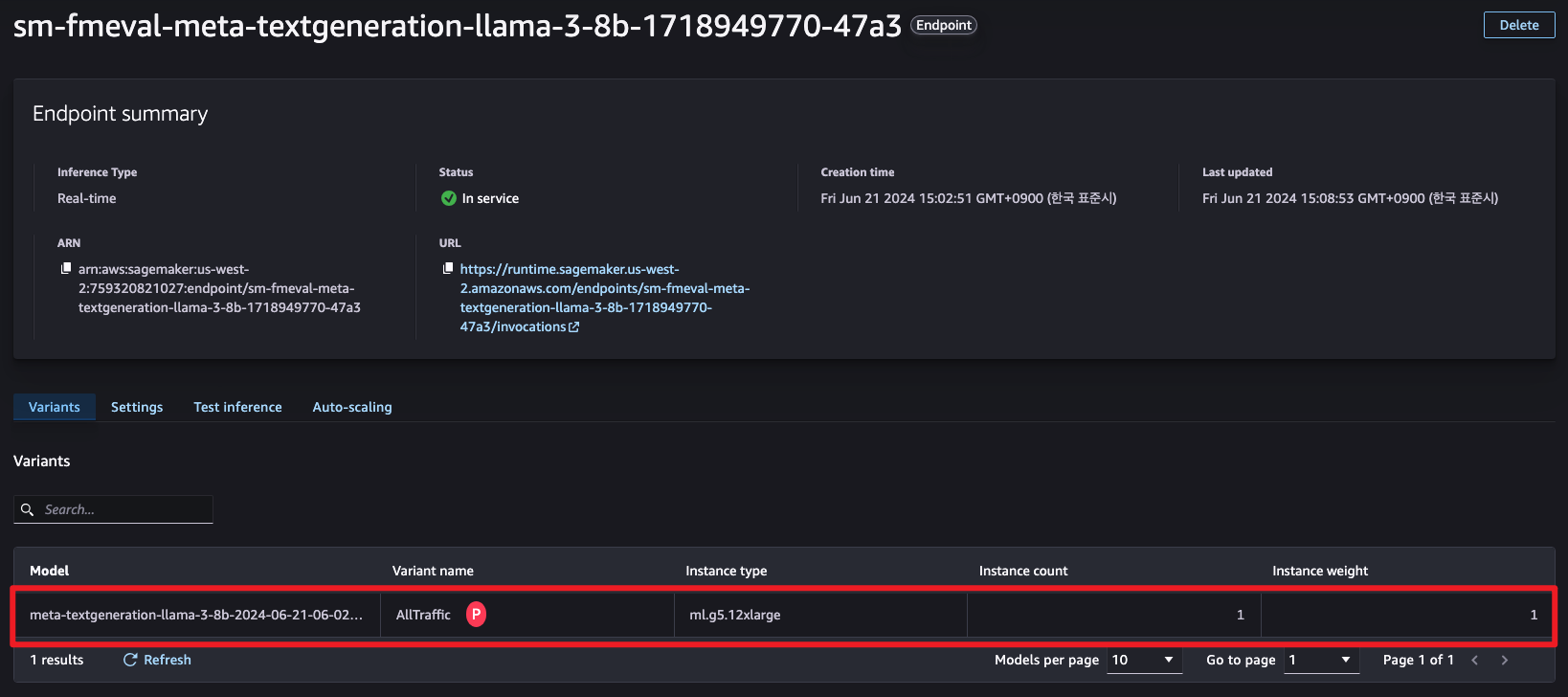
작업이 완료되었습니다.

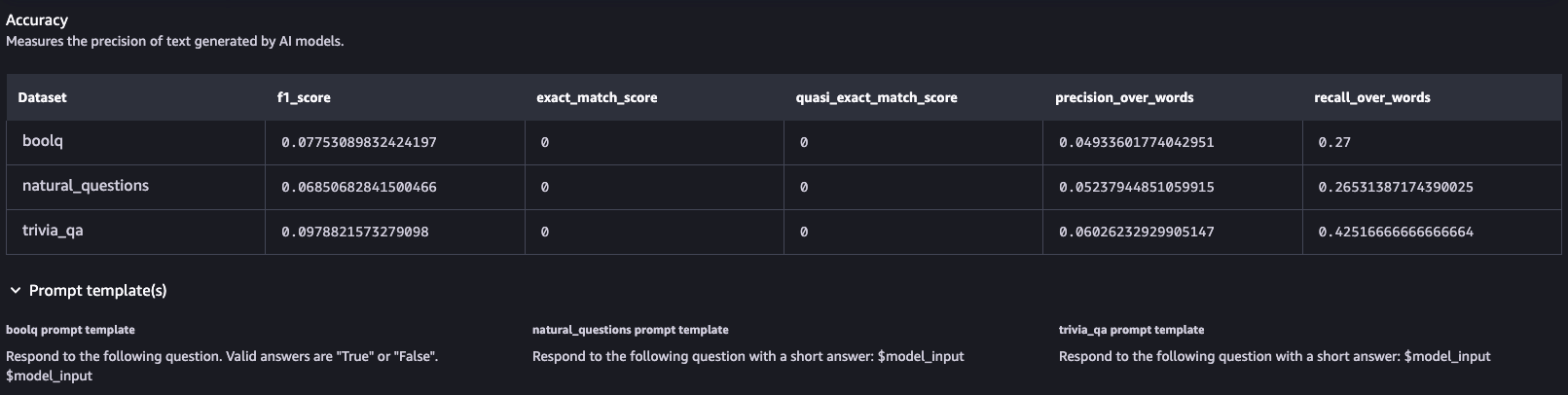
정확성
유해성
의미적 견고성
생성된 성능테스트 리포트
결론
Llama 3-8B 모델은 다양한 데이터셋에서 Q&A 작업 수행 시 다양한 성과를 보입니다. F1 점수는 전반적으로 낮으며, 정확히 일치하는 경우가 없습니다. 모델은 의미론적 견고성을 어느 정도 보여주지만, 퍼터베이션 후 F1 점수의 변화가 있습니다. 독성 평가에서는 일반적으로 낮은 수준의 독성 콘텐츠를 보이지만, TriviaQA 데이터셋에서는 다소 높은 점수를 보였습니다.어떤 데이터를 통해 테스트 되었는지를 확인할 수 있으며 추후 참고 가능한 다양한 지표로 구성되어 출력되는 것을 확인하였습니다.
![[LLM] VLM으로 표를 정확히 추출하기](https://images.unsplash.com/photo-1623667322051-18662ce6334c?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDl8fHBkZnxlbnwwfHx8fDE3NzIzNzMzODN8MA&ixlib=rb-4.1.0&q=80&w=960)
![[SageMaker] SageMaker Jumpstart를 사용한 LLM Fine Tuning - Supervised fine tuning (SFT)](https://images.unsplash.com/photo-1648652678596-d3873bd0c157?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDQ2fHxTdXBlcnZpc2VkfGVufDB8fHx8MTc1MzgzMTg2Mnww&ixlib=rb-4.1.0&q=80&w=960)
![[SageMaker] SageMaker Jumpstart를 사용한 LLM Fine Tuning - DAFT(Domain-Agnostic Fine-Tuning)](https://images.unsplash.com/photo-1563207769-3343cb585fcb?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDZ8fHR1bmluZ3xlbnwwfHx8fDE3NTM4MzE2Mjl8MA&ixlib=rb-4.1.0&q=80&w=960)
![[SageMaker] SageMaker Jumpstart Evaluation(Ground Truth)을 구성하여 사람이 LLM 평가하기](https://images.unsplash.com/photo-1632144130358-6cfeed023e27?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDN8fEh1bWFuJTIwRmVlZGJhY2t8ZW58MHx8fHwxNzUzODMxNDUwfDA&ixlib=rb-4.1.0&q=80&w=960)