[SageMaker] SageMaker Jumpstart를 사용한 LLM Fine Tuning - Supervised fine tuning (SFT)
Sagemaker를 활용하여 Fine-tuning을 수행하였습니다.
![[SageMaker] SageMaker Jumpstart를 사용한 LLM Fine Tuning - Supervised fine tuning (SFT)](https://images.unsplash.com/photo-1648652678596-d3873bd0c157?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDQ2fHxTdXBlcnZpc2VkfGVufDB8fHx8MTc1MzgzMTg2Mnww&ixlib=rb-4.1.0&q=80&w=1200)
파인튜닝이란?
파인튜닝이란 LLM의 성능을 유지하고 개선하기 위한 수단으로 특정 데이터를 활용하여 LLM을 학습시키는 방법을 의미합니다.파인튜닝의 경우 다음과 같은 장점이 있습니다.
- 파라미터 크기가 작은 모델을 사용했을 때 더 효과가 뛰어납니다.
- 맞춤형 모델 및 데이터 적응력을 향상시킬 수 있습니다.
- 매우 작고 단순한 데이터셋을 활용할 수 있습니다.
하지만 단점으로는 다음과 같습니다.
- 파인튜닝을 한 경우 고객이 계속해서 직접 관리해야하는 단점이 생깁니다.
- 모델에게 훈련 후 데이터를 지울 수 없으므로 데이터를 변경사항이 있는 경우 학습 데이터보다 더 많은 학습시켜야합니다.
- JSON 형식의 포맷과 레이블된 데이터까지 준비해야할 부분이 많습니다.
- 모델에 따라 몇 가지 데이터 형식은 아예 안될 수 있고 어떤 것은 instruct, 매우 적은 부분만 가능합니다.
따라서 파인튜닝이란 대부분의 경우 사용에 적합하진 않으며, 모델에 따라서 복잡한 초기 구성이 필요할 수 있습니다.뿐만 아니라 LLM을 학습시키기 위해 필요한 데이터 혹은 구성 방법 등이 잘 알려져 있지않은 경우가 대부분입니다. 하지만 SageMaker Jumpstart같은 경우 LLM 모델을 학습시키기 위해 필요한 데이터의 정보나 구성 등을 확인할 수 있고 클라우드 상에서 쉽게 LLM 모델을 파인튜닝하여 사용할 수 있게 됩니다.
Supervised fine tuning (SFT)란?
SFT는 레이블이 지정된 데이터를 사용하여 사전 훈련된 LLM을 특정 다운스트림(특정 작업이 가능) 작업이 가능하도록 적용하는데 사용할 수 있는 LLM을 학습시키는 기법 중 하나입니다.SFT에서 사전 훈련된 LLM은 지도 학습 기술을 사용하여 레이블이 지정된 데이터 세트에서 미세 조정됩니다. 모델의 가중치는 LLM의 예측과 실제 레이블 간의 차이를 측정하는 작업별 손실에서 파생된 기울기를 기반으로 조정됩니다.SFT는 일반적으로 3단계 프로세스를 거칩니다.
- 1단계: 사전 훈련 — 기본 또는 기초 모델은 처음에 대규모 데이터 세트에서 훈련되어 주어진 문장에서 다음 단어를 예측하여 언어 패턴, 문법 및 컨텍스트를 이해하는 방법을 학습합니다. 이 단계는 모델이 언어에 대한 광범위한 이해가 가능하도록 설정할 수 있습니다.
- 2단계: 데이터 라벨링 — 미세 조정에 사용되는 데이터 세트를 준비합니다. 각 데이터 포인트에는 올바른 출력이나 답이 표시되어 있습니다. 이 레이블이 지정된 데이터는 미세 조정 프로세스 중에 모델이 매개변수를 조정하도록 안내하므로 지도 학습에서 가장 중요한 단계입니다.
- 3단계: 미세 조정 — 사전 훈련된 모델은 레이블이 지정된 데이터가 있는 작업별 데이터 세트에 대해 추가로 훈련됩니다. 모델은 이 특정 작업의 성능을 향상시키기 위해 매개변수를 조정합니다. 이러한 작업은 텍스트 분류, 감정 분석, 질문 답변 시스템 등 다양한 곳에서 사용할 수 있습니다.
EX) 라벨링된 테스트 데이터는 다음과 같이 구성되어 있습니다.
{"question":"What part of a plant protects the plant cell, maintains its shape, and prevents excessive uptake of water?","correct_answer":"wall"}
{"question":"Bones, cartilage, and ligaments make up what anatomical system?","correct_answer":"skeletal system"}
{"question":"What is the term for the force exerted by circulating blood on the walls of blood vessels?","correct_answer":"blood pressure"}
{"question":"What is the most diverse and abundant group of organisms on earth, numbering in the millions of trillions?","correct_answer":"bacteria"}
{"question":"Energy from sunlight enters many ecosystems through what process?","correct_answer":"photosynthesis"}
{"question":"Modern plants reflect what kind of changes that have occurred over many, many years?","correct_answer":"evolutionary changes"}
이러한 라벨링 데이터를 학습시키기 위해 파인튜닝하기 위한 기법으로는 LoRA가 대표적이며 훈련 가능한 매개변수의 수를 줄이고 미세 조정을 더욱 효율적으로 만들 수 있습니다.
- LoRA(Low-Rank Adaptation) — 낮은 순위 분해를 사용하여 두 개의 더 작은 행렬로 가중치 업데이트를 나타내어 훈련 가능한 매개변수 수를 줄이는 매개변수 효율적인 미세 조정 기술입니다.
- QLoRA(Quantized LoRA) — 대규모 LLM을 미세 조정하는 데 필요한 메모리 요구 사항을 더욱 줄이는 메모리 효율적인 LoRA 변형입니다.
- Basic hyperparameter tuning: 학습률, 배치 크기, 에포크 수와 같은 모델의 하이퍼파라미터를 수동으로 조정하여 원하는 성능을 얻을 때까지 조정하는 과정입니다.
- Transfer learning: 사전 학습된 대규모 언어 모델 LLM을 특정 하위 작업에 맞게 레이블이 있는 데이터를 사용하여 미세 조정하는 기법입니다.
- Multi-task learning: LLM을 여러 작업에 대해 동시에 훈련시켜, 모델이 작업별 패턴과 뉘앙스를 학습하도록 하는 접근법입니다.
- Few-shot learning: 특정 작업에 대해 소수의 레이블이 있는 예제로 LLM을 훈련시키고, 모델의 기존 지식을 활용하여 예측하는 기법입니다.
- Task-specific fine-tuning: 모든 모델 레이어가 훈련 과정에서 조정될 수 있도록 작업 특정 데이터로 전체 모델을 훈련시키는 방법입니다.
- Reward modeling: 각 입력 데이터 포인트가 올바른 답변 또는 레이블과 연관된 작업 특정 레이블이 있는 데이터셋으로 LLM을 훈련시키는 기법입니다. 모델은 이러한 레이블을 정확하게 예측하도록 파라미터를 조정하는 법을 배웁니다.
- Proximal policy optimization: 인간의 피드백을 통한 강화 학습 RLHF을 사용하여 특정 작업에 대해 LLM을 미세 조정하는 방법입니다.
- Comparative ranking: LLM이 출력의 관련성이나 품질에 따라 다양한 출력을 순위 매기도록 훈련시키는 기법입니다. 이를 통해 모델은 더 관련성 높고 고품질의 출력을 생성하는 법을 학습합니다.
발생할 수 있는 문제
- Overfitting: 모델이 훈련 데이터에 너무 특화되어, 보지 않은 데이터에 대한 일반화 성능이 저하되는 현상을 의미합니다.
- Hyperparameter Tuning: 적절하지 않은 하이퍼파라미터를 선택했을 때 느린 수렴, 불량한 일반화, 또는 불안정한 훈련과 같은 문제가 발생할 수 있습니다.
- Data Quality Issues: 데이터의 품질에 따라 문제가 발생할 수 있습니다.
- Catastrophic Forgetting: 미세 조정 전 데이터를 잊어버릴 수 있습니다.
- Inconsistent Performance: 학습된 구조 변경으로 인해 일관되지 않은 답변을 생성할 수 있습니다.
보편적으로 파인튜닝에서 발생할 수 있는 문제들이 포함되어 있습니다.하지만 SFT 방식은 LLM이 훈련하는 기본적인 방식으로 성능을 향상시키는 가장 유용한 방식으로써 사용될 수 있습니다.
파인튜닝 설정하기
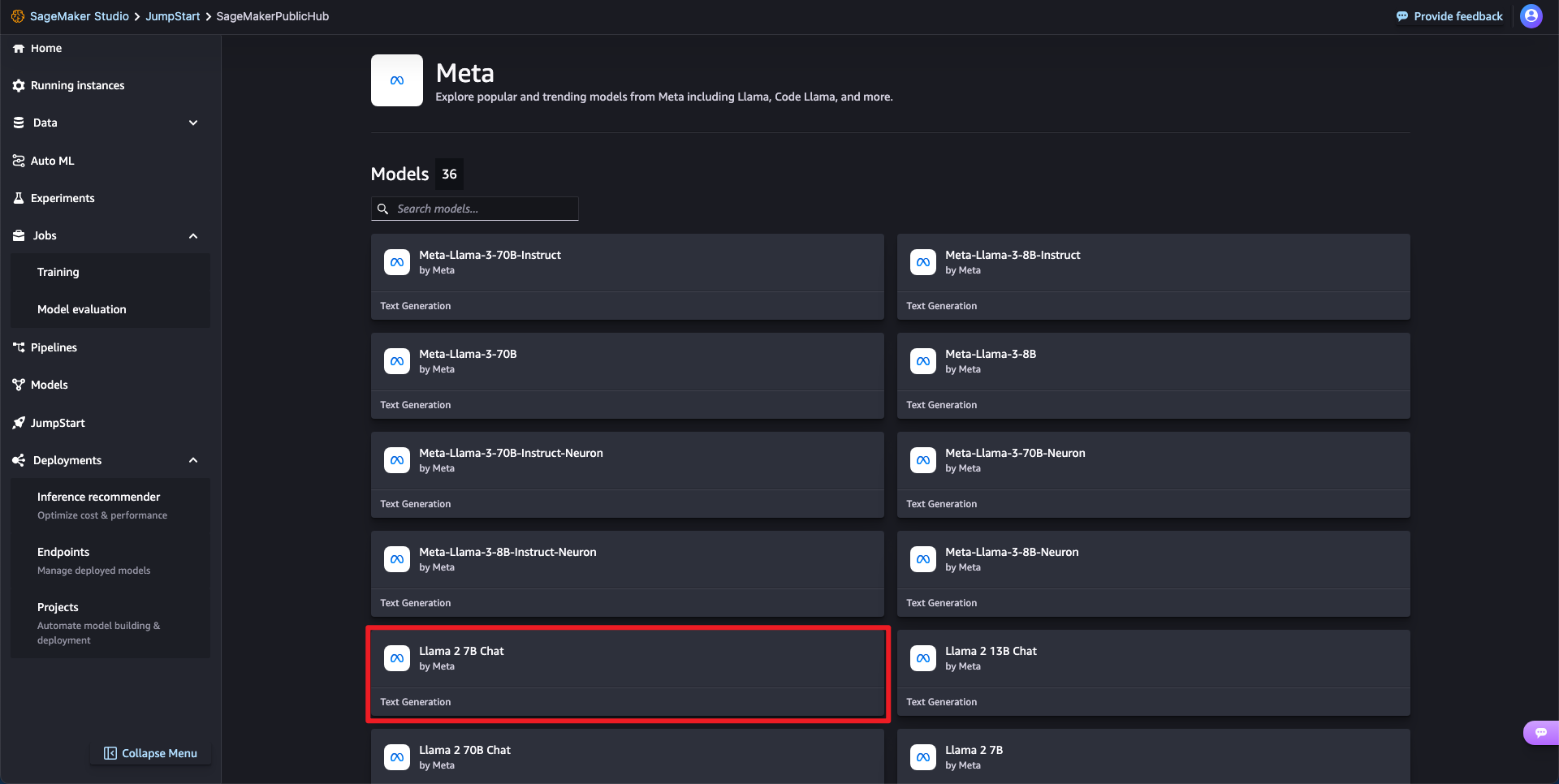
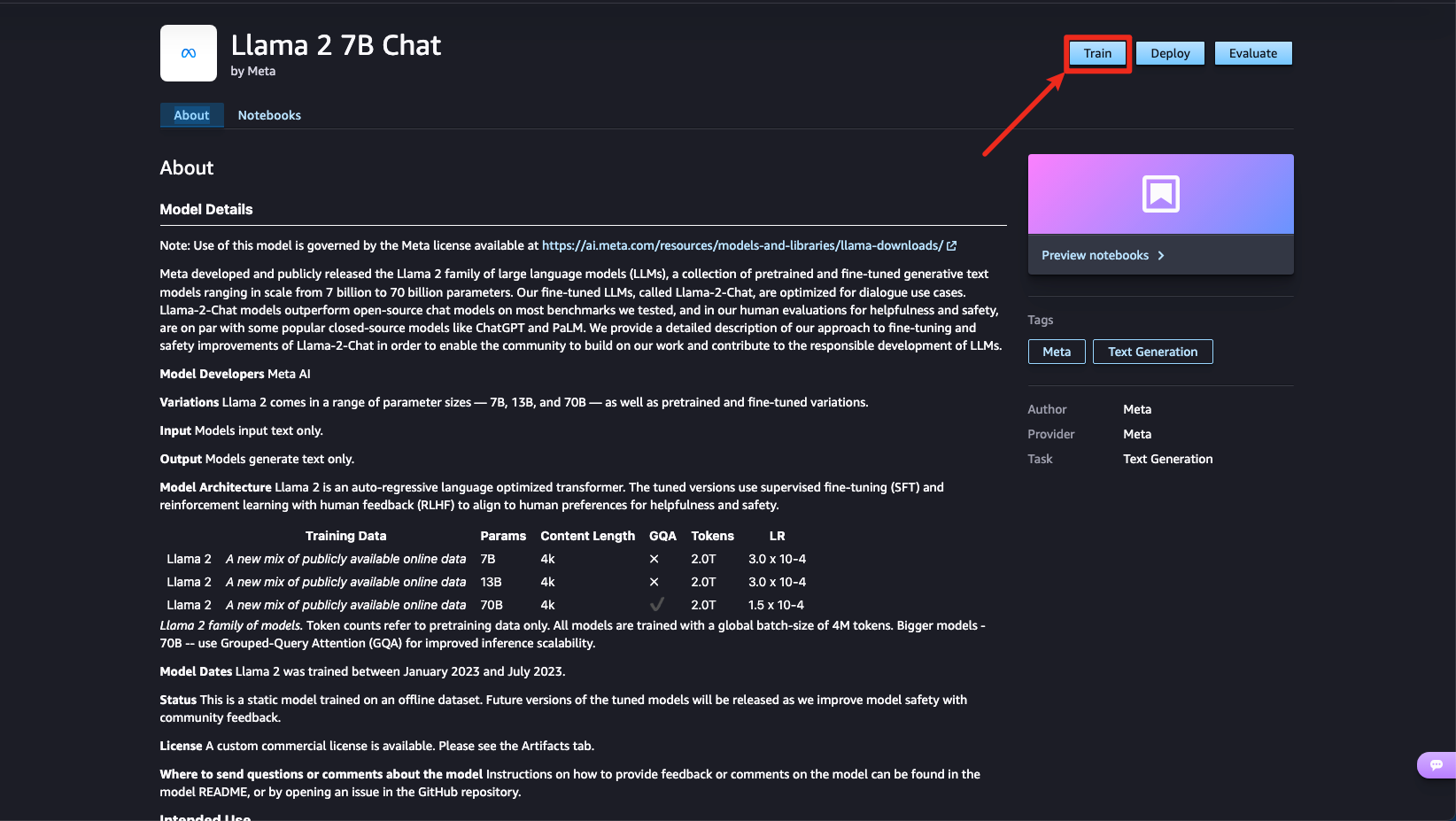
1단계: 파인튜닝 가능한 모델(Llama2 7B Chat)을 선택합니다.
Jumpstart > Meta > Llama 2 7B Chat 모델을 선택하고 Train 버튼을 클릭합니다.

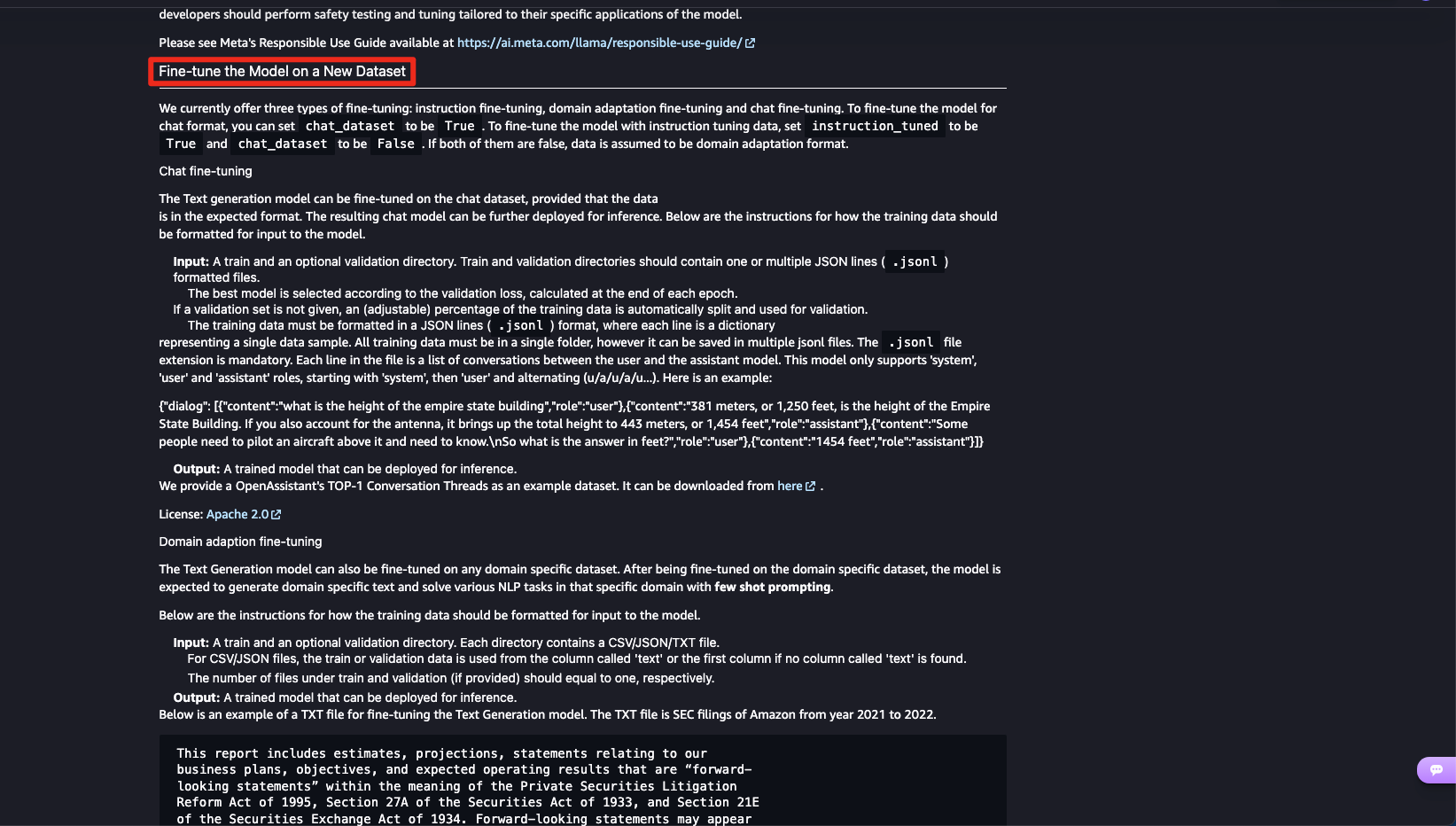
추가적으로 문서를 확인해보면 새로운 데이터셋을 통해 파인튜닝하는 방법을 안내하고 있습니다.
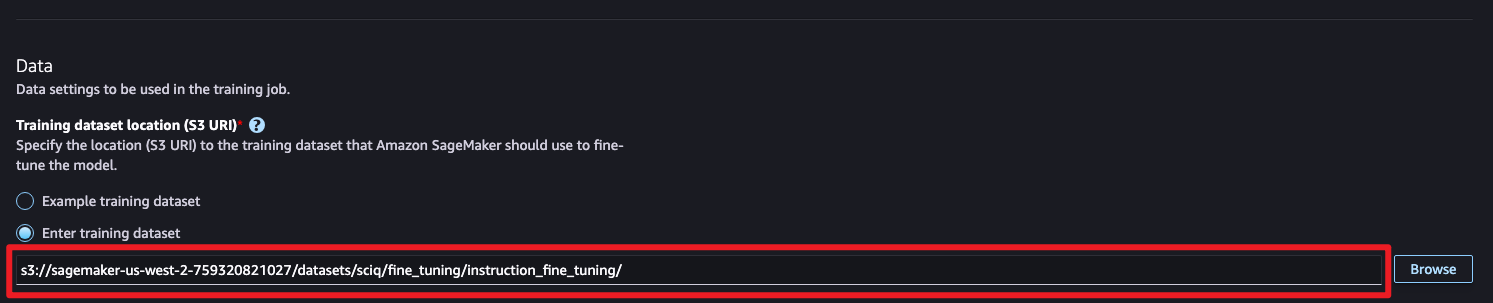
2단계: 파인튜닝 세부 구성
Datasetinstruction, context가 통합되어야 하지만 좀 더 명확한 지침을 내리기 위해 프롬프트 템플릿을 생성하고 Question과 Answer로 구성된 데이터셋을 사용하여 전달합니다.
{"question":"What part of a plant protects the plant cell, maintains its shape, and prevents excessive uptake of water?","correct_answer":"wall"}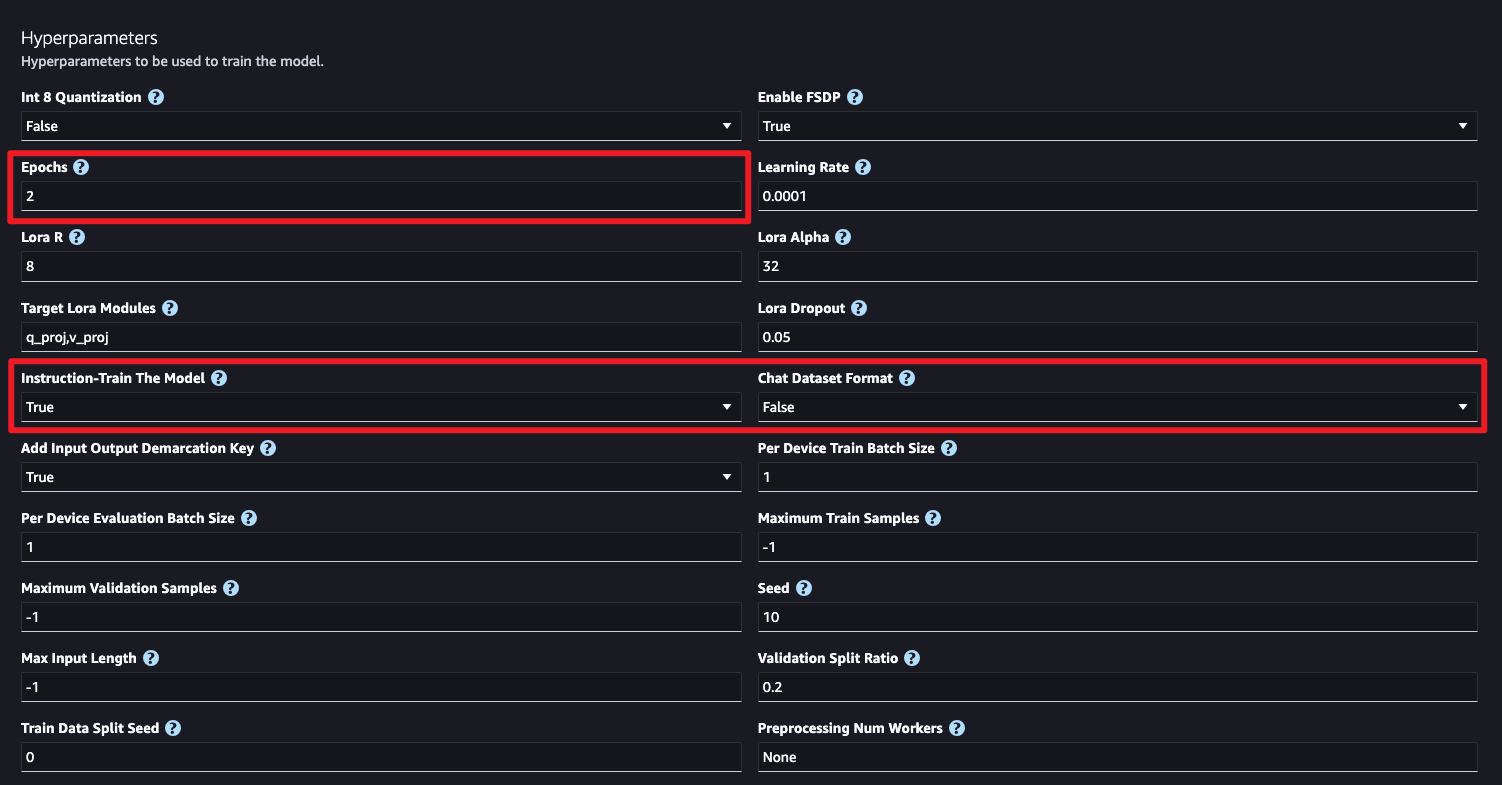
해당 트레이닝에서는 Epochs와 Instruction-Train The Model과 Chat Dataset Format만 설정하고 나머지는 디폴트로 설정하였습니다. 파라미터의 설명은 다음과 같습니다.
- Lora R(LoRA Rank)
- LoRA 저랭크 근사화를 통해 학습 효율성을 높입니다.
- 큰 가중치 행렬을 두 개의 더 작은 행렬의 곱으로 분해하여 학습의 효율성을 높이는 방법입니다.
- Lora Alpha
- LoRA 활성화에 할당되는 가중치를 조절하여 모델의 학습 성능을 최적화합니다.
- Lora Dropout
- LoRA 활성화를 무작위로 삭제하여 모델의 일반화 성능을 향상시킵니다.
- Instruction-Train The Model
- 모델이 Instruction을 학습하도록 조정할 수 있습니다.
- Chat Dataset Format
- 채팅 데이터 세트 형식 옵션이 활성화됩니다. 모델이 채팅 데이터를 학습할 수 있습니다.
- Add Input Output Demarcation Key
- 입력과 출력을 구분하는 키를 추가합니다. 이는 데이터 전처리 과정에서 입력과 출력의 경계를 명확히 하기 위해 사용됩니다.
- Per Device Train Batch Size
- 각 장치에서 학습 시 사용하는 배치 크기입니다. 각 장치에서 한 번에 1개의 샘플을 학습합니다.
- Per Device Evaluation Batch Size
- 각 장치에서 평가 시 사용하는 배치 크기입니다. 각 장치에서 한 번에 1개의 샘플을 평가합니다.
- Maximum Train Samples
- 학습에 사용할 최대 샘플 수입니다. -1로 설정하면 전체 학습 데이터를 사용합니다.
- Maximum Validation Samples
- 검증에 사용할 최대 샘플 수입니다. -1로 설정하면 전체 검증 데이터를 사용합니다.
- Seed
- 무작위성 제어를 위한 시드 값입니다. 동일한 시드 값을 사용하면 반복 실행 시 동일한 결과를 보장할 수 있습니다.
- Max Input Length
- 입력 데이터의 최대 길이입니다. -1로 설정하면 입력 데이터의 길이에 제한을 두지 않습니다.
- Validation Split Ratio
- 학습 데이터를 학습과 검증으로 나누는 비율입니다.
- Train Data Split Seed
- 학습 데이터를 학습과 검증으로 나눌 때 사용하는 시드 값입니다. 동일한 시드 값을 사용하면 동일한 데이터 분할을 보장할 수 있습니다.
- Preprocessing Num Workers
- 데이터 전처리 시 사용할 작업자(worker) 수입니다. 작업자가 많을수록 전처리 속도가 빨라질 수 있습니다.
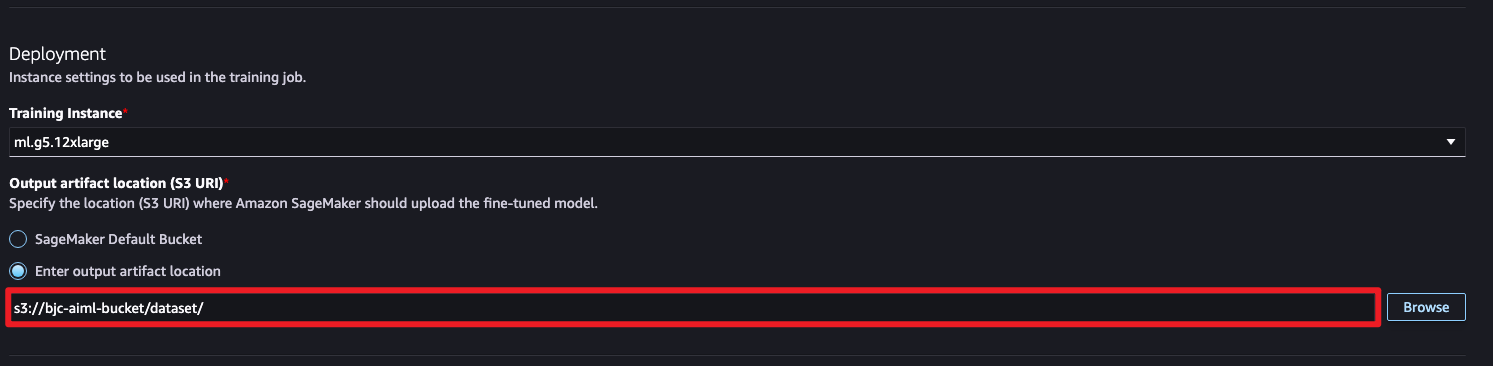
3단계: 모델 저장 및 훈련 등록
훈련된 모델을 저장할 위치를 설정합니다.

4단계 작업 완료
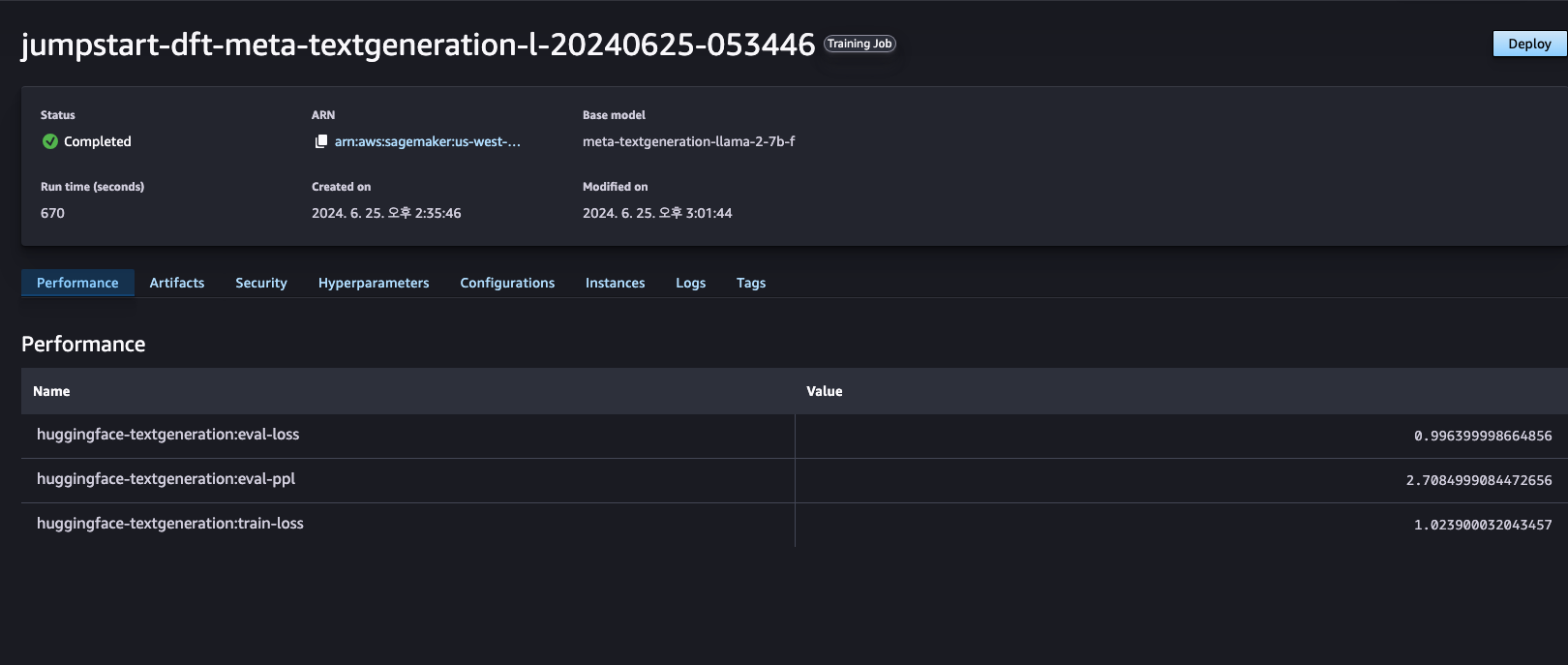
Jobs > Training > Training Jobs에서 실행중인 Jumpstart 모델을 확인할 수 있습니다.해당 Training Job이 완료되면 다음과 같이 퍼포먼스 결과가 출력됩니다.
5단계: 테스트
해당 모델을 배포하여 성능 테스트를 진행해보도록 하겠습니다.
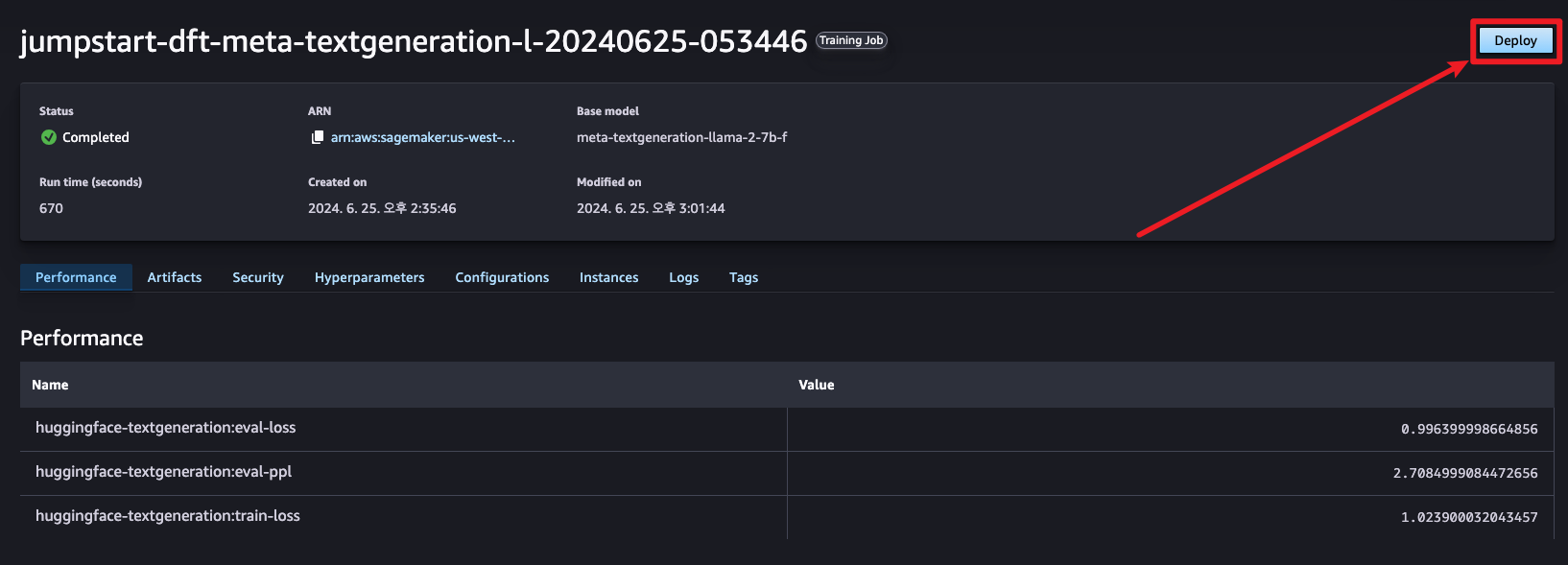
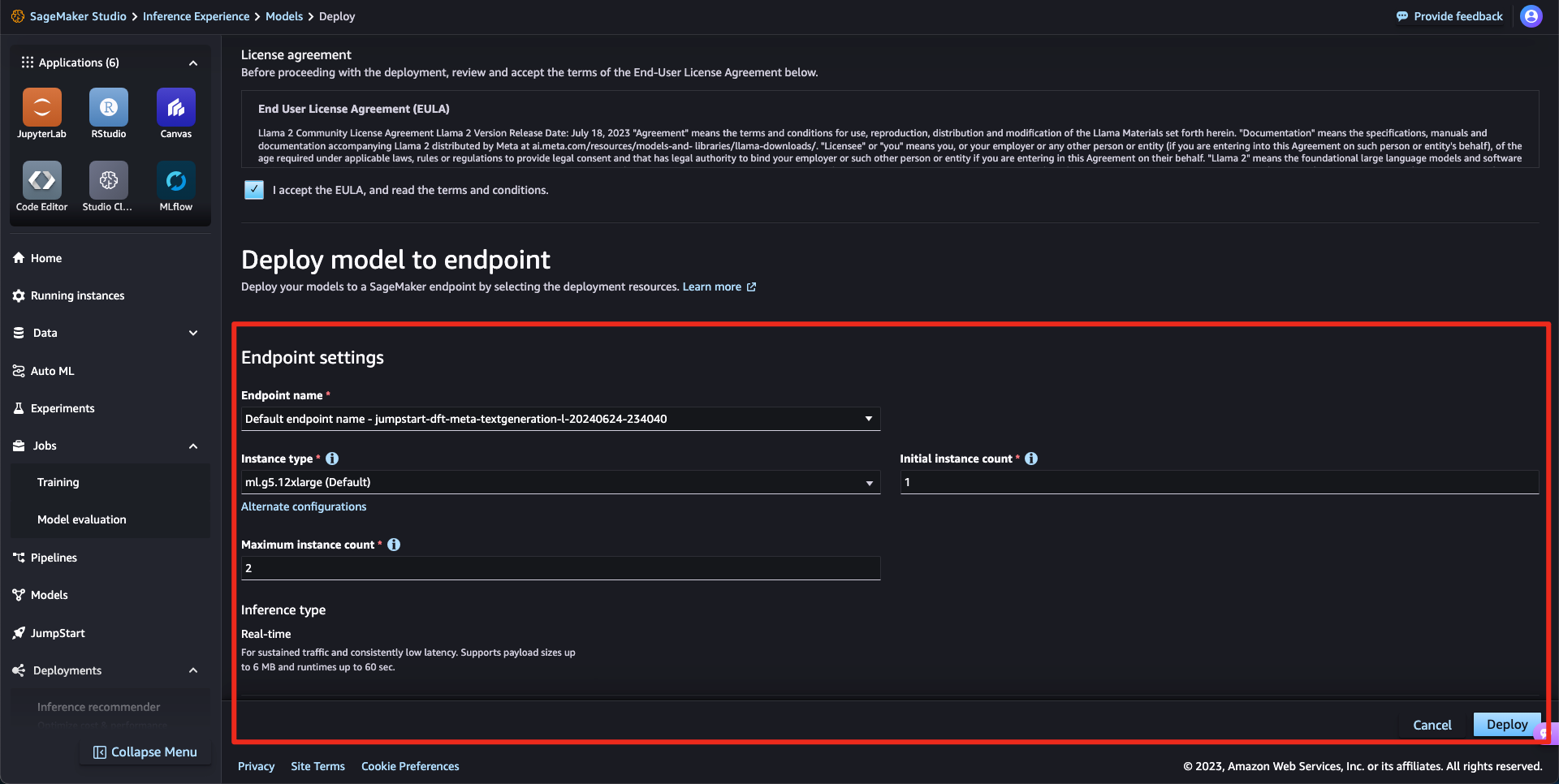
이후 Deployments > Endpoints로 모델이 자동적으로 배포되며 GPU 상황에 따라 배포되며 배포가 실패할 경우 GPU 상태를 확인해보시는 것을 권장드립니다.배포가 완료되었다면 생성된 Endpoint ID를 endpoint_name으로 설정하여 테스트를 진행할 수 있습니다.
sft_endpoint_name = "jumpstart-dft-meta-textgeneration-l-20240625-064708"아래 테스트 코드와 평가를 위한 데이터셋입니다.
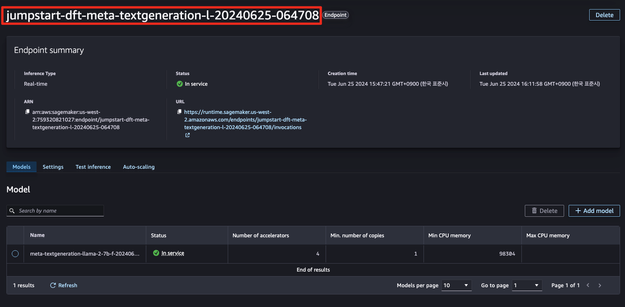
위 테스트 데이터셋을 통해 출력한 결과입니다.
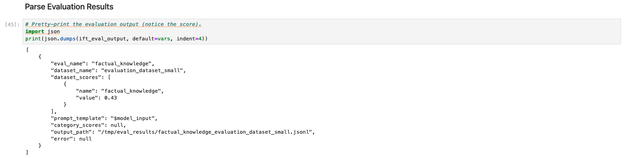
6단계: SageMaker Test Inference
현재 배포된 SageMaker Endpoint에서 Test inference를 진행할 수 있습니다.
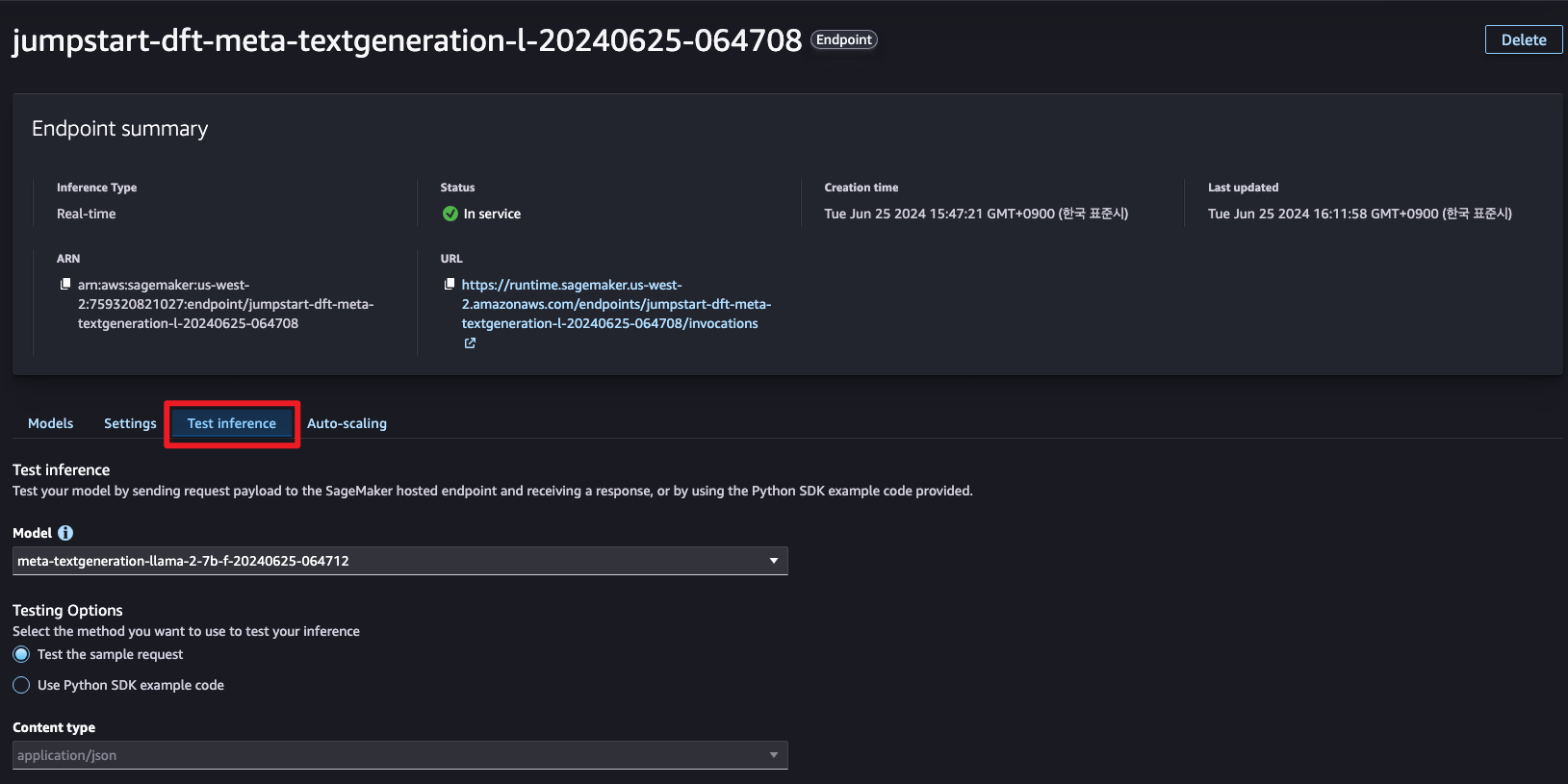
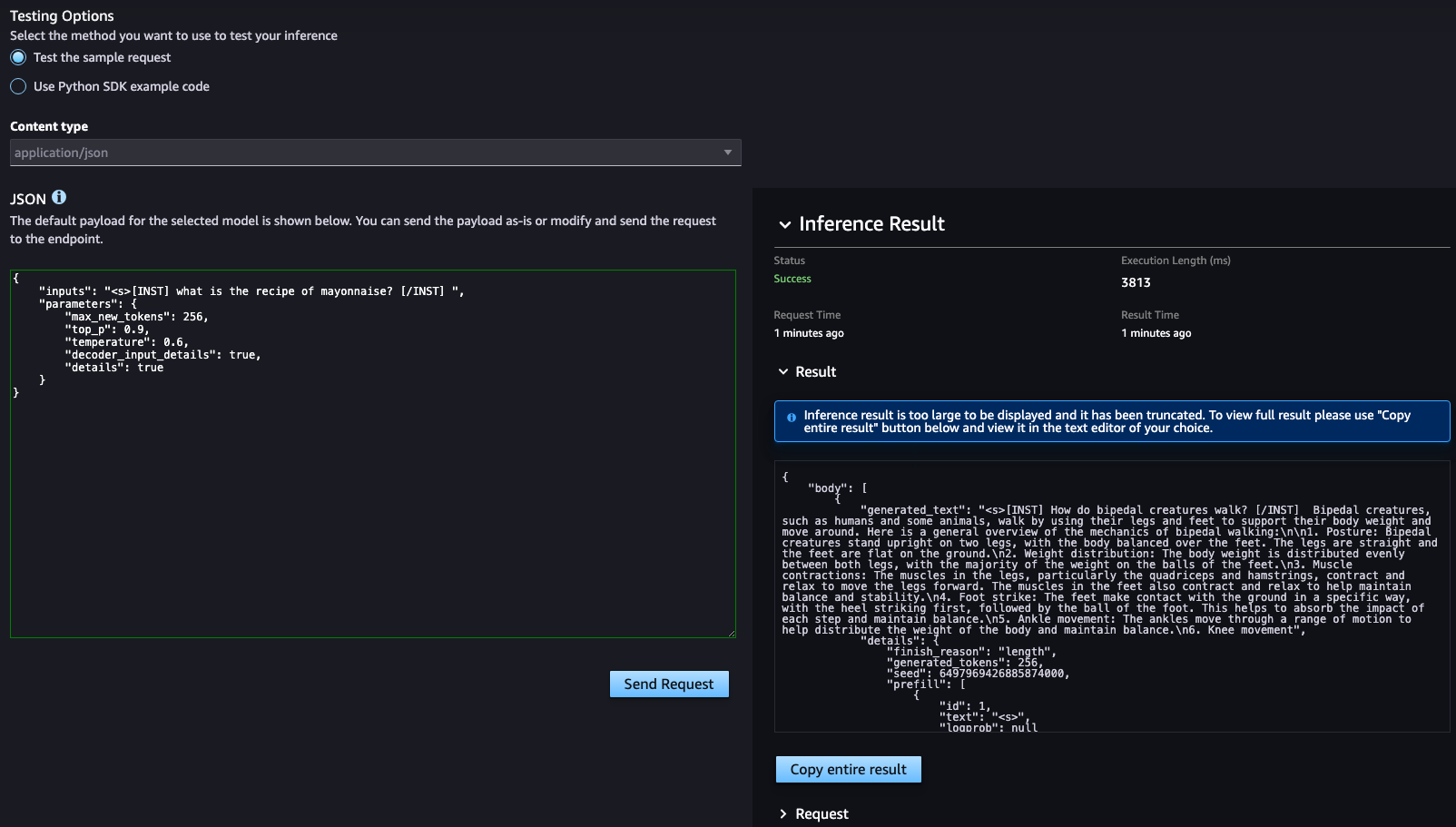
Training dataset에서 일부 데이터를 가져와 질문한 결과 다음과 같이 출력되었습니다.
{
"inputs": "<s>[INST] How do bipedal creatures walk? [/INST] ",
"parameters": {
"max_new_tokens": 256,
"top_p": 0.9,
"temperature": 0.6,
"decoder_input_details": true,
"details": true
}
}{"question":"How do bipedal creatures walk?","correct_answer":"on two legs"}{
"body": [
{
"generated_text": "<s>[INST] How do bipedal creatures walk? [/INST] Bipedal creatures, such as humans and some animals, walk by using their legs and feet to support their body weight and move around. Here is a general overview of the mechanics of bipedal walking:\n\n1. Posture: Bipedal creatures stand upright on two legs, with the body balanced over the feet. The legs are straight and the feet are flat on the ground.\n2. Weight distribution: The body weight is distributed evenly between both legs, with the majority of the weight on the balls of the feet.\n3. Muscle contractions: The muscles in the legs, particularly the quadriceps and hamstrings, contract and relax to move the legs forward. The muscles in the feet also contract and relax to help maintain balance and stability.\n4. Foot strike: The feet make contact with the ground in a specific way, with the heel striking first, followed by the ball of the foot. This helps to absorb the impact of each step and maintain balance.\n5. Ankle movement: The ankles move through a range of motion to help distribute the weight of the body and maintain balance.\n6. Knee movement",
...
}테스트한 결과 질문에 대한 응답은 하였지만 조금 광범위하게 학습 데이터를 출력했음을 확인하였습니다. 따라서 만약 더 구체적인 결과나 혹은 특정한 형식의 출력을 원한다면 프롬프트를 제어하거나, 더 구체적인 데이터를 출력해야합니다.
![[LLM] VLM으로 표를 정확히 추출하기](https://images.unsplash.com/photo-1623667322051-18662ce6334c?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDl8fHBkZnxlbnwwfHx8fDE3NzIzNzMzODN8MA&ixlib=rb-4.1.0&q=80&w=960)
![[SageMaker] SageMaker Jumpstart를 사용한 LLM Fine Tuning - DAFT(Domain-Agnostic Fine-Tuning)](https://images.unsplash.com/photo-1563207769-3343cb585fcb?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDZ8fHR1bmluZ3xlbnwwfHx8fDE3NTM4MzE2Mjl8MA&ixlib=rb-4.1.0&q=80&w=960)
![[SageMaker] SageMaker Jumpstart Evaluation(Ground Truth)을 구성하여 사람이 LLM 평가하기](https://images.unsplash.com/photo-1632144130358-6cfeed023e27?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDN8fEh1bWFuJTIwRmVlZGJhY2t8ZW58MHx8fHwxNzUzODMxNDUwfDA&ixlib=rb-4.1.0&q=80&w=960)
