[SageMaker] SageMaker Jumpstart를 사용한 LLM Fine Tuning - DAFT(Domain-Agnostic Fine-Tuning)
Sagemaker를 통해 LLM 모델을 파인튜닝하고 테스트합니다.
![[SageMaker] SageMaker Jumpstart를 사용한 LLM Fine Tuning - DAFT(Domain-Agnostic Fine-Tuning)](https://images.unsplash.com/photo-1563207769-3343cb585fcb?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDZ8fHR1bmluZ3xlbnwwfHx8fDE3NTM4MzE2Mjl8MA&ixlib=rb-4.1.0&q=80&w=1200)
파인튜닝이란?
파인튜닝이란 LLM의 성능을 유지하고 개선하기 위한 수단으로 특정 데이터를 활용하여 LLM을 학습시키는 방법을 의미합니다.파인튜닝의 경우 다음과 같은 장점이 있습니다.
- 파라미터 크기가 작은 모델을 사용했을 때 더 효과가 뛰어납니다.
- 맞춤형 모델 및 데이터 적응력을 향상시킬 수 있습니다.
- 매우 작고 단순한 데이터셋을 활용할 수 있습니다.
하지만 단점으로는 다음과 같습니다.
- 파인튜닝을 한 경우 고객이 계속해서 직접 관리해야하는 단점이 생깁니다.
- 모델에게 훈련 후 데이터를 지울 수 없으므로 데이터를 변경사항이 있는 경우 학습 데이터보다 더 많은 학습시켜야합니다.
- JSON 형식의 포맷과 레이블된 데이터까지 준비해야할 부분이 많습니다.
- 모델에 따라 몇 가지 데이터 형식은 아예 안될 수 있고 어떤 것은 instruct, 매우 적은 부분만 가능합니다.
따라서 파인튜닝이란 대부분의 경우 사용에 적합하진 않으며, 모델에 따라서 복잡한 초기 구성이 필요할 수 있습니다.뿐만 아니라 LLM을 학습시키기 위해 필요한 데이터 혹은 구성 방법 등이 잘 알려져 있지않은 경우가 대부분입니다. 하지만 SageMaker Jumpstart같은 경우 LLM 모델을 학습시키기 위해 필요한 데이터의 정보나 구성 등을 확인할 수 있고 클라우드 상에서 쉽게 LLM 모델을 파인튜닝하여 사용할 수 있게 됩니다.
DAFT란(Domain-Adjacent Fine-Tuned Model)?
대규모 언어 모델(LLMs)은 도메인 특화 데이터로 미세 조정될 때 다양한 하위 작업에서 우수한 성능을 보이는 것으로 관찰되었습니다. 그러나 많은 응용 분야에서 이러한 데이터를 쉽게 구할 수 없어, 도메인 인접 모델을 사용한 제로샷 또는 퓨샷 접근법이 필요하게 됩니다. 이러한 방식으로 특정 도메인에 대해 접근하기 위해 domain에서 자주 사용되는 단어를 pre-trained 시키는 방식을 의미합니다.
모든 모델에서 사용할 순 없고 다음과 같은 LLM 모델을 지원하고 있습니다.
[2024년 6월 테스트 자료입니다.]
- Bloom 3B
- Bloom 7B1
- BloomZ 3B FP16
- BloomZ 7B1 FP16
- GPT-2 XL
- GPT-J 6B
- GPT-Neo 1.3B
- GPT-Neo 125M
- GPT-NEO 2.7B
- Llama 2 13B
- Llama 2 13B Chat
- Llama 2 13B Neuron
- Llama 2 70B
- Llama 2 70B Chat
- Llama 2 7B
- Llama 2 7B Chat
- Llama 2 7B Neuron
- https://docs.aws.amazon.com/ko_kr/sagemaker/latest/dg/jumpstart-foundation-models-fine-tuning-domain-adaptation.html
파인튜닝 설정하기
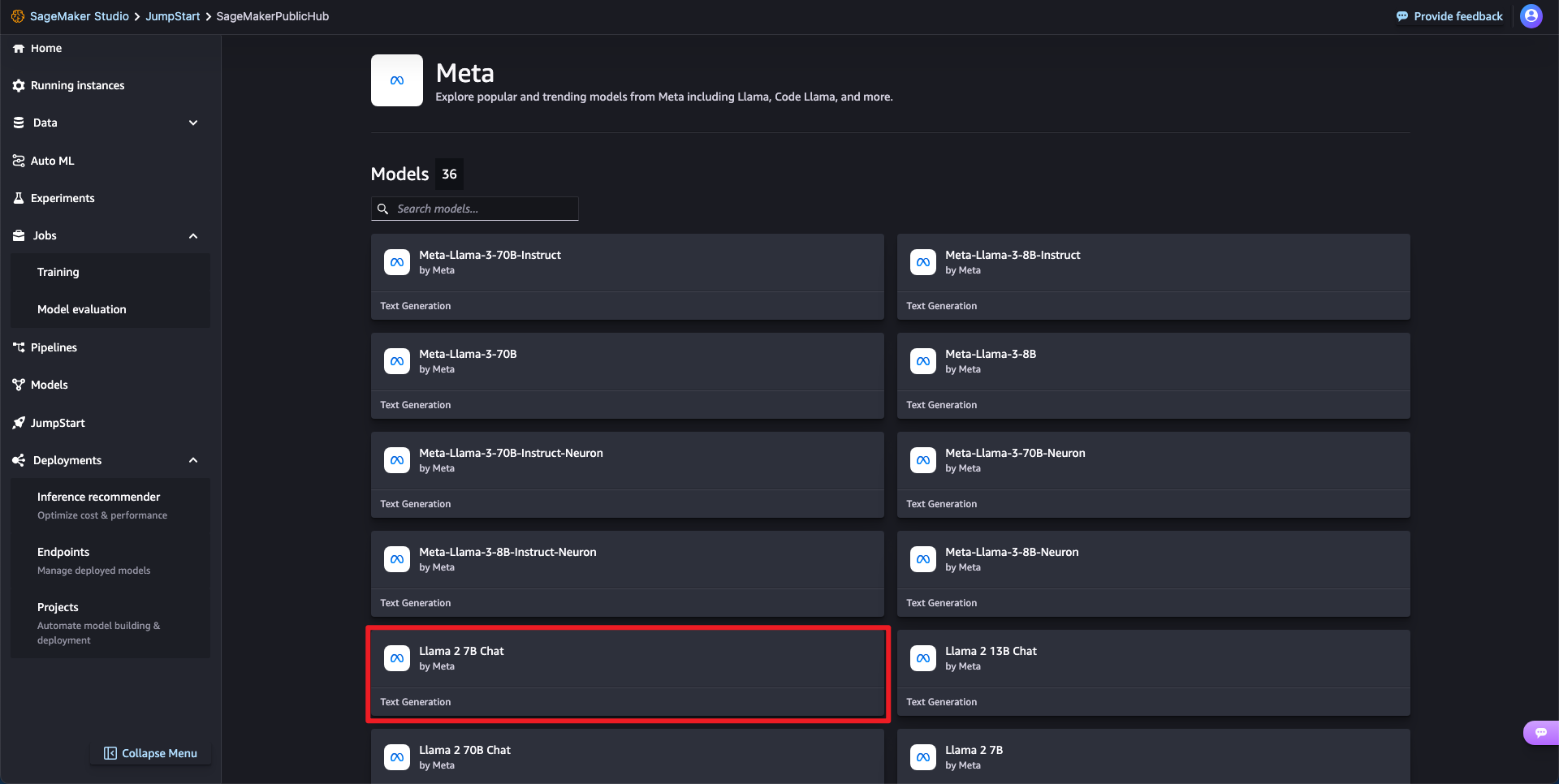
1단계: 파인튜닝 가능한 모델(Llama2 7B Chat)을 선택합니다.
Jumpstart > Meta > Llama 2 7B Chat 모델을 선택하고 Train 버튼을 클릭합니다.

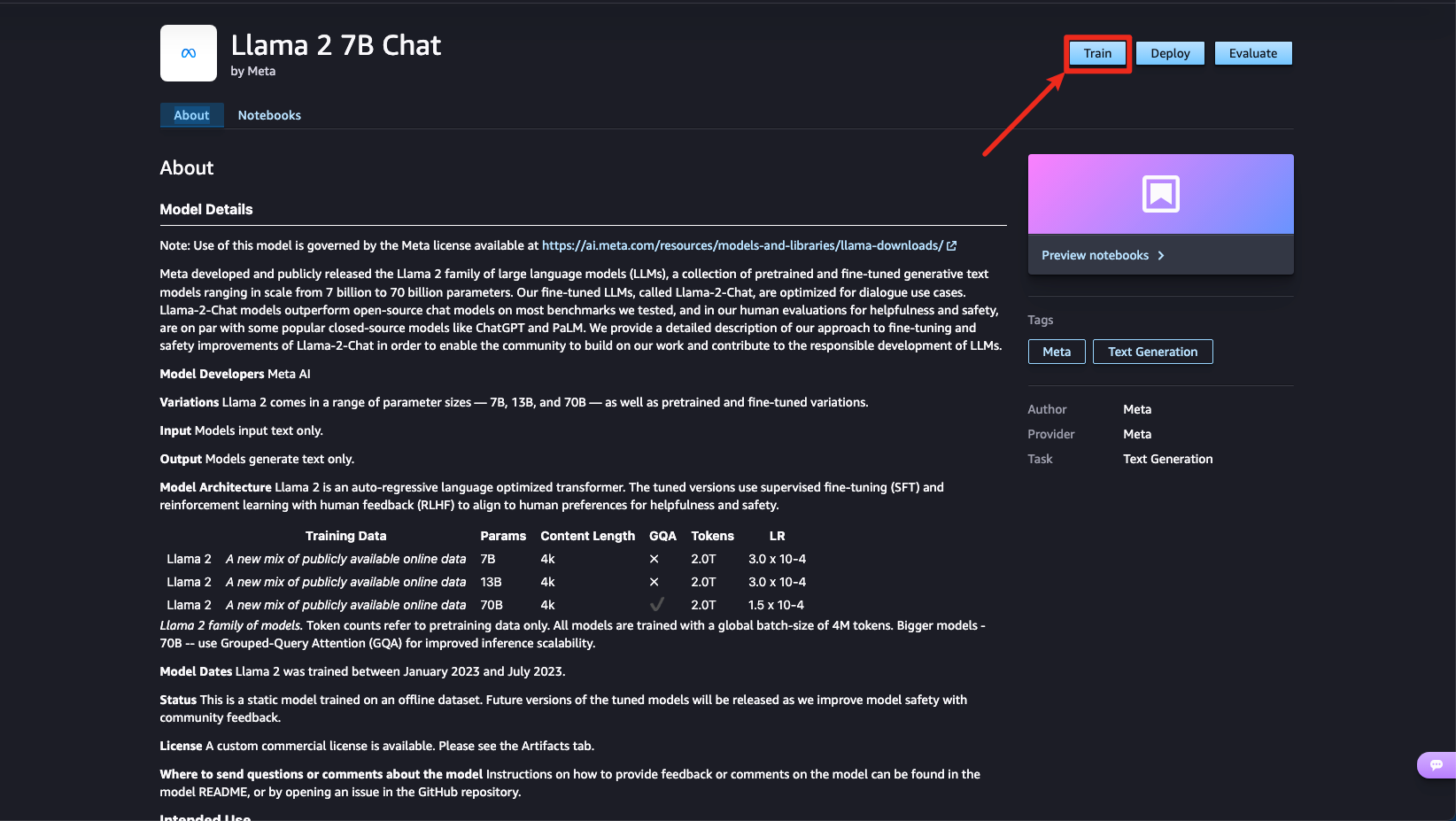
추가적으로 문서를 확인해보면 새로운 데이터셋을 통해 파인튜닝하는 방법을 안내하고 있습니다.
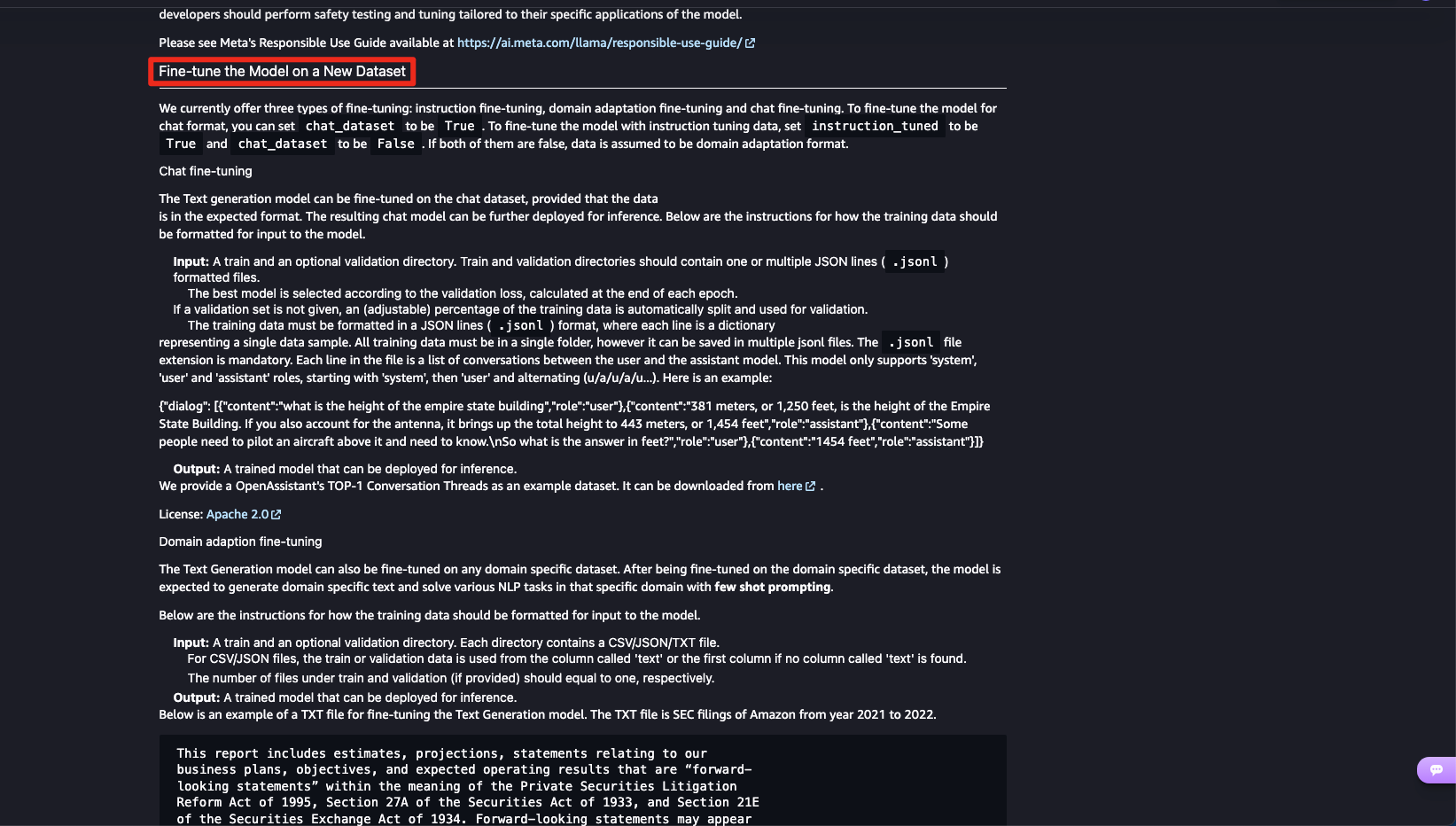
2단계: 파인튜닝 세부 구성
Dataset
SciQ 데이터 세트를 활용합니다.해당 데이터셋에는 생물학, 화학, 물리학, 환경 과학 등 광범위한 과학 주제를 다루고 있으며 파인튜닝을 위한 데이터로 활용하였습니다.S3에 사전 생성된 트레이닝 데이터셋을 추가합니다.
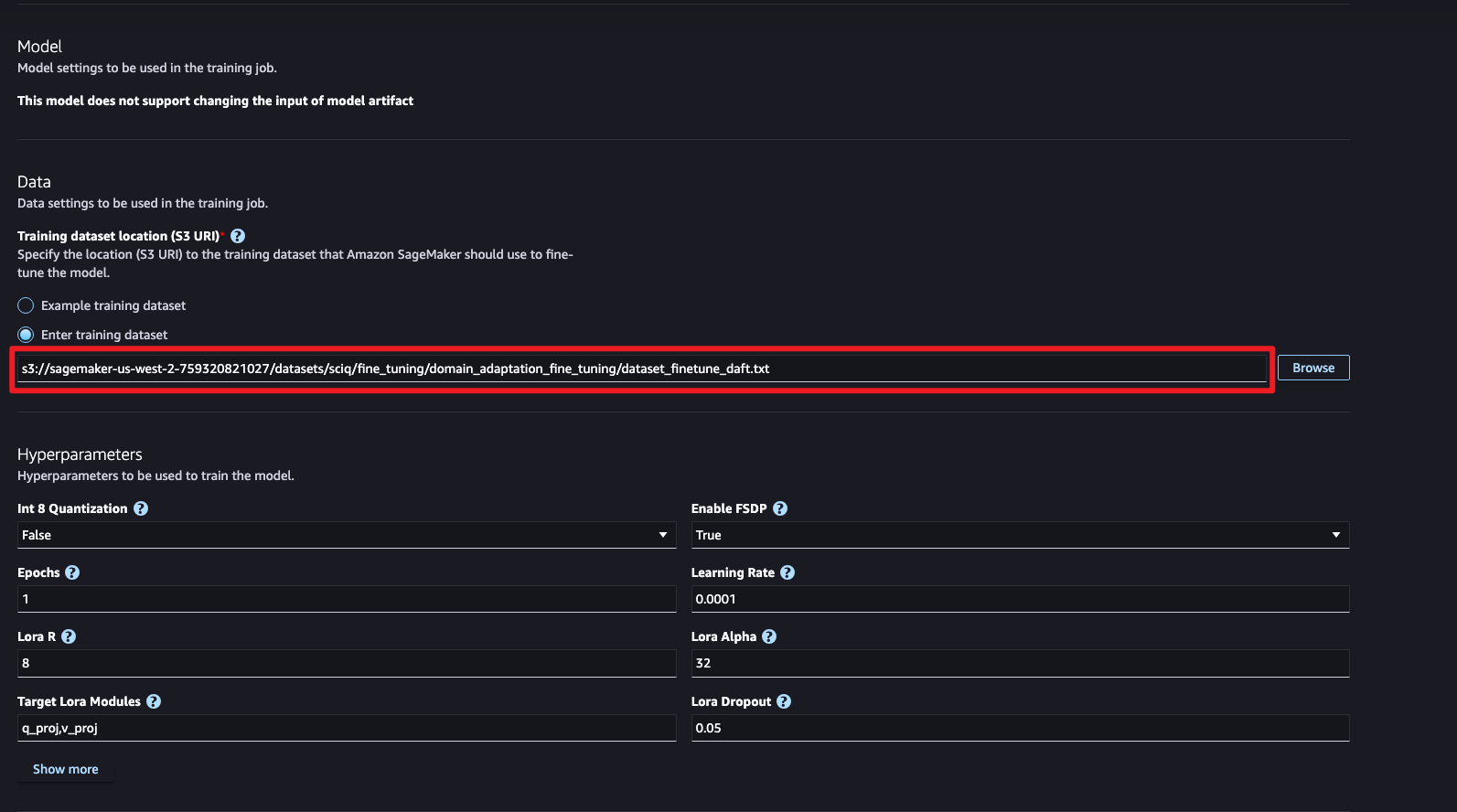
Hyper Parameter
- Int8 양자화
- 모델의 가중치와 활성화 값을 32비트 부동소수점에서 8비트 정수로 변환하는 과정으로 Int8 양자화는 모델의 크기를 줄이고 추론 속도를 높이는 효과적인 방법입니다.
- FSDP 활성화
- FSDP(완전 샤딩된 데이터 병렬 처리)는 모델 매개변수를 여러 GPU에 걸쳐 샤딩하여 대규모 모델을 훈련하는 데 필요한 메모리 공간을 줄이는 기술입니다.
양자화 하는 것과 샤딩 처리하는 것은 서로 상호 보완적으로 동작합니다. 따라서 하나의 옵션만 활성화되어 동작하며 동시에 활성화 할 수 없습니다.
- Epochs
- 모델이 학습 데이터를 반복하는 횟수입니다.
- 학습률(Learning Rate)
- 모델의 가중치를 업데이트할 때 변화할 수 있는 값입니다.
LoRA (Low-Rank Adaptation of Large Language Models)는 대규모 언어 모델(LLM)을 효율적으로 학습하고 적응시키기 위한 기법으로 기본적으로 가중치 행렬의 차원을 줄여 학습하는 방식입니다. 이는 저랭크 행렬 분해(low-rank matrix decomposition) 원리를 이용합니다. 큰 가중치 행렬을 두 개의 더 작은 행렬로 분해하여 계산 복잡도를 줄이고 효율적으로 모델을 학습하는 방식입니다.다음과 같은 장점을 가지고 있습니다.
- 계산 효율성:
- 큰 가중치 행렬을 두 개의 작은 행렬로 분해하여 계산 복잡도를 줄입니다.
- 학습할 파라미터 수가 줄어들어 더 적은 자원으로도 효율적인 학습이 가능합니다.
- 메모리 절약:
- 저랭크 근사를 통해 메모리 사용량이 줄어듭니다.
- 유연성:
- 다양한 모델 구조에 쉽게 적용할 수 있습니다.
- 기존의 가중치 행렬을 직접 변경하지 않고 추가적인 작은 행렬을 학습함으로써 기존 모델을 손쉽게 확장할 수 있습니다.
LoRA는 대규모 언어 모델(LLM)에서 특정 가중치 값이 너무 커서 계산과 변환이 비효율적인 경우에 사용되는 기법입니다. LoRA는 큰 가중치 행렬 W를 두 개의 더 작은 행렬 A와 B로 분해하여 계산합니다. 이 작은 행렬들을 통해 원래의 큰 가중치 W를 근사하는 방식입니다. 이를 통해 메모리 사용량과 계산 복잡도를 줄일 수 있습니다.
- Lora R(LoRA Rank)
- LoRA 저랭크 근사화를 통해 학습 효율성을 높입니다.
- 큰 가중치 행렬을 두 개의 더 작은 행렬의 곱으로 분해하여 학습의 효율성을 높이는 방법입니다.
- Lora Alpha
- LoRA 활성화에 할당되는 가중치를 조절하여 모델의 학습 성능을 최적화합니다.
- Lora Dropout
- LoRA 활성화를 무작위로 삭제하여 모델의 일반화 성능을 향상시킵니다.
- Instruction-Train The Model
- 모델이 Instruction을 학습하도록 조정할 수 있습니다.
- Chat Dataset Format
- 채팅 데이터 세트 형식 옵션이 활성화됩니다. 모델이 채팅 데이터를 학습할 수 있습니다.
- Add Input Output Demarcation Key
- 입력과 출력을 구분하는 키를 추가합니다. 이는 데이터 전처리 과정에서 입력과 출력의 경계를 명확히 하기 위해 사용됩니다.
- Per Device Train Batch Size
- 각 장치에서 학습 시 사용하는 배치 크기입니다. 각 장치에서 한 번에 1개의 샘플을 학습합니다.
- Per Device Evaluation Batch Size
- 각 장치에서 평가 시 사용하는 배치 크기입니다. 각 장치에서 한 번에 1개의 샘플을 평가합니다.
- Maximum Train Samples
- 학습에 사용할 최대 샘플 수입니다. -1로 설정하면 전체 학습 데이터를 사용합니다.
- Maximum Validation Samples
- 검증에 사용할 최대 샘플 수입니다. -1로 설정하면 전체 검증 데이터를 사용합니다.
- Seed
- 무작위성 제어를 위한 시드 값입니다. 동일한 시드 값을 사용하면 반복 실행 시 동일한 결과를 보장할 수 있습니다.
- Max Input Length
- 입력 데이터의 최대 길이입니다. -1로 설정하면 입력 데이터의 길이에 제한을 두지 않습니다.
- Validation Split Ratio
- 학습 데이터를 학습과 검증으로 나누는 비율입니다.
- Train Data Split Seed
- 학습 데이터를 학습과 검증으로 나눌 때 사용하는 시드 값입니다. 동일한 시드 값을 사용하면 동일한 데이터 분할을 보장할 수 있습니다.
- Preprocessing Num Workers
- 데이터 전처리 시 사용할 작업자(worker) 수입니다. 작업자가 많을수록 전처리 속도가 빨라질 수 있습니다.
하이퍼파라미터는 다음과 같이 설정하였습니다.
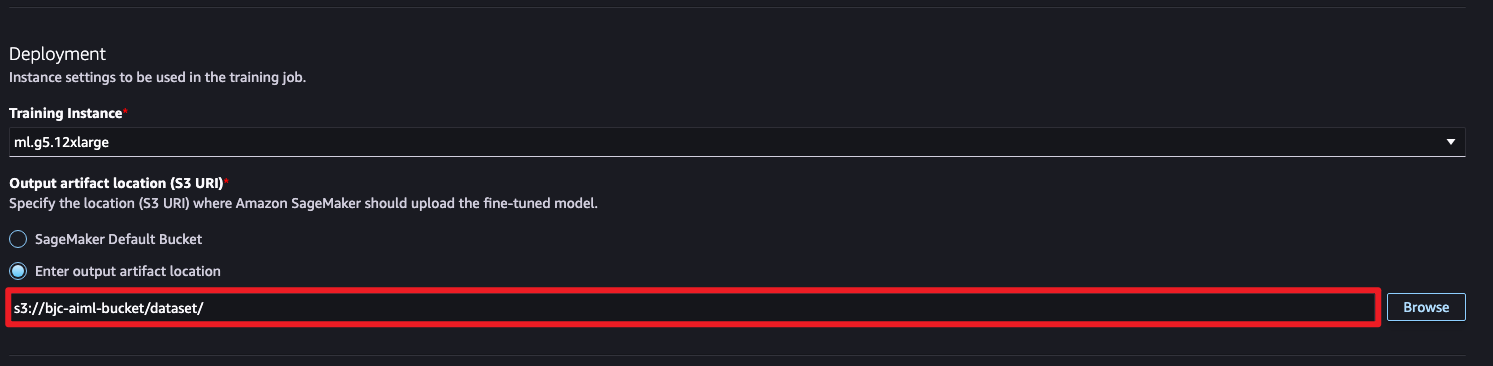
3단계: 모델 저장 및 훈련 등록
파인튜닝된 모델의 결과를 저장하는 버킷을 지정합니다.훈련하는 작업을 등록합니다.

Llama 2 모델에는 Llama 2 커뮤니티 라이센스가 있습니다. 라이센스 계약을 읽고 동의할 수 있습니다.

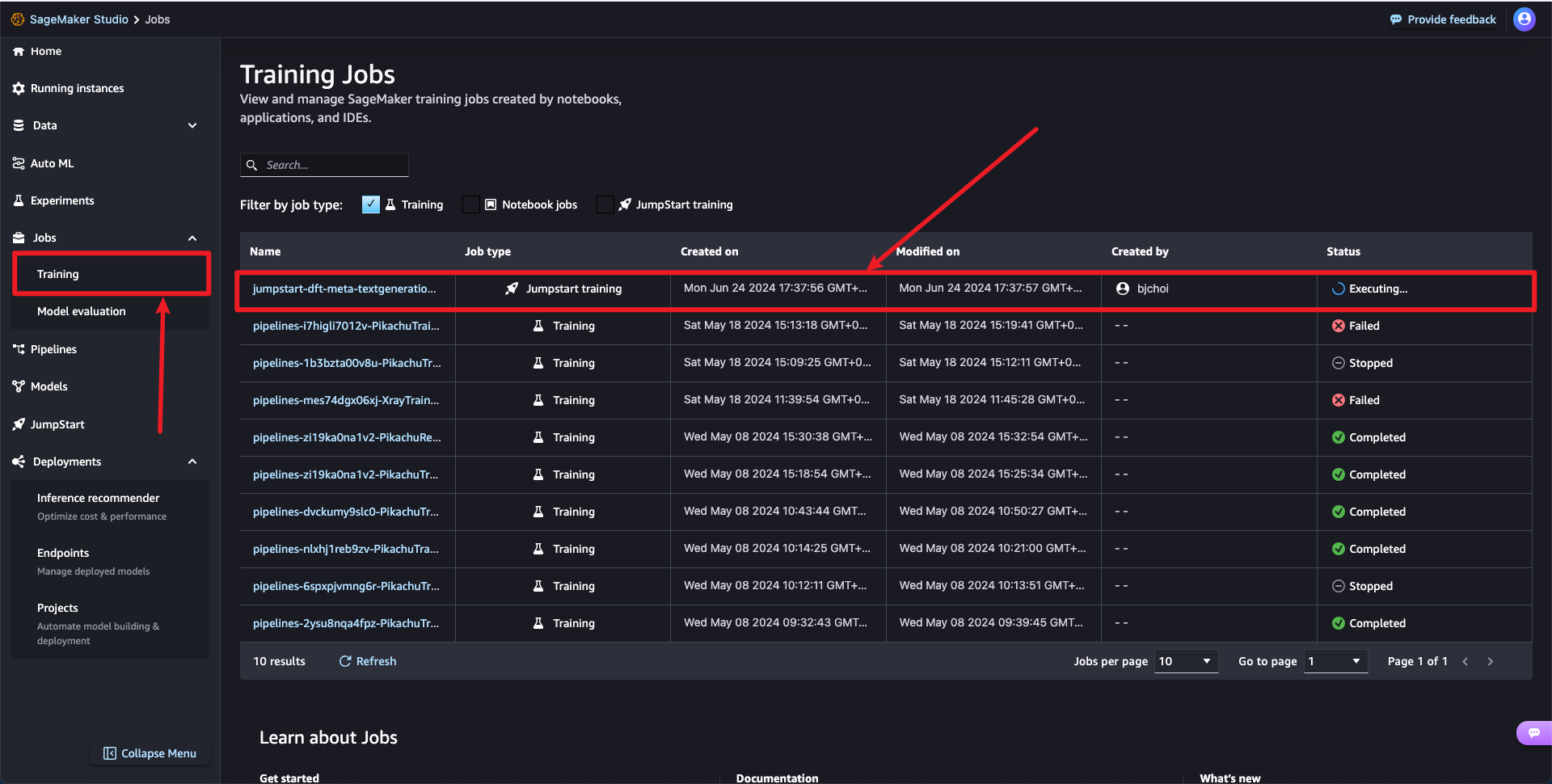
4단계: 작업 시작
Jobs > Training > Training Jobs에서 실행중인 Jumpstart 모델을 확인할 수 있습니다.
5단계: 작업 완료
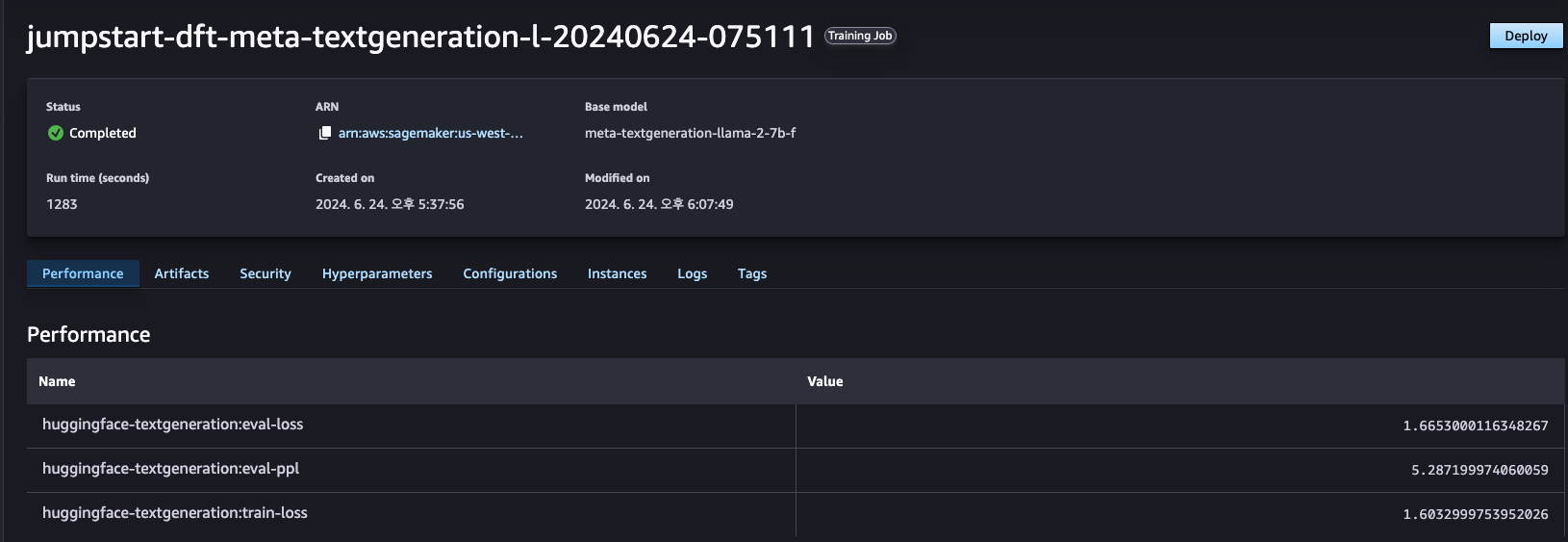
HuggingFace 데이터셋을 사용해 평가되었으며 모델의 지표를 확인할 수 있습니다.
- 평가 손실(eval-loss):
- 모델이 평가(검증) 데이터세트에서 얼마나 잘 수행되었는지를 나타냅니다. 일반적으로 값이 낮을수록 성능이 향상됩니다.
- 평가 복잡성(eval-ppl):
- Perplexity는 확률 모델이 표본을 얼마나 잘 예측하는지를 나타내는 척도입니다.
- 훈련 손실(train-loss):
- 훈련 손실은 모델이 훈련 데이터세트에서 얼마나 잘 수행되었는지를 보여줍니다.
6단계: 테스트
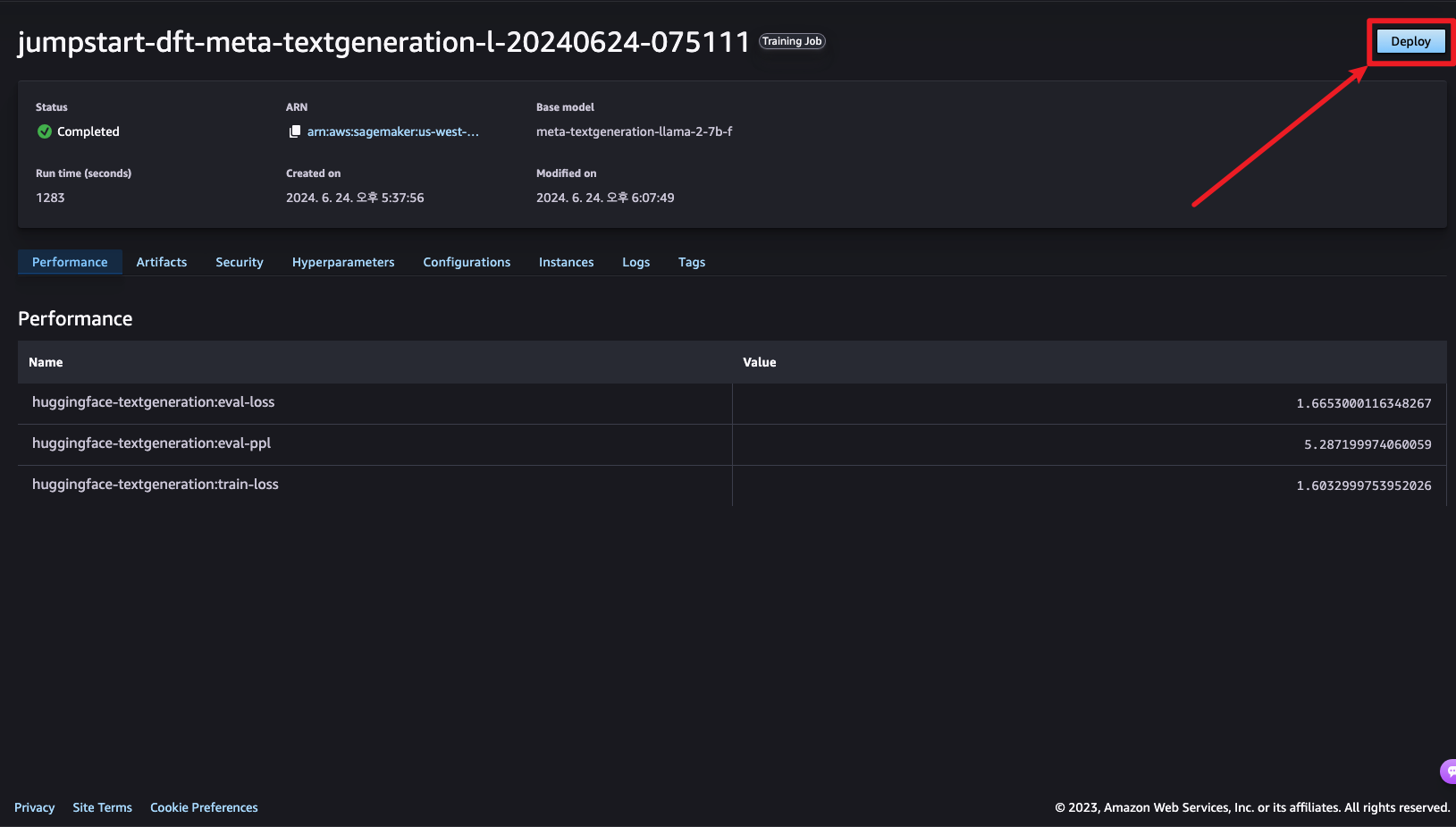
우측 상단의 Deploy를 통해 파인튜닝된 모델을 사용할 수 있습니다.
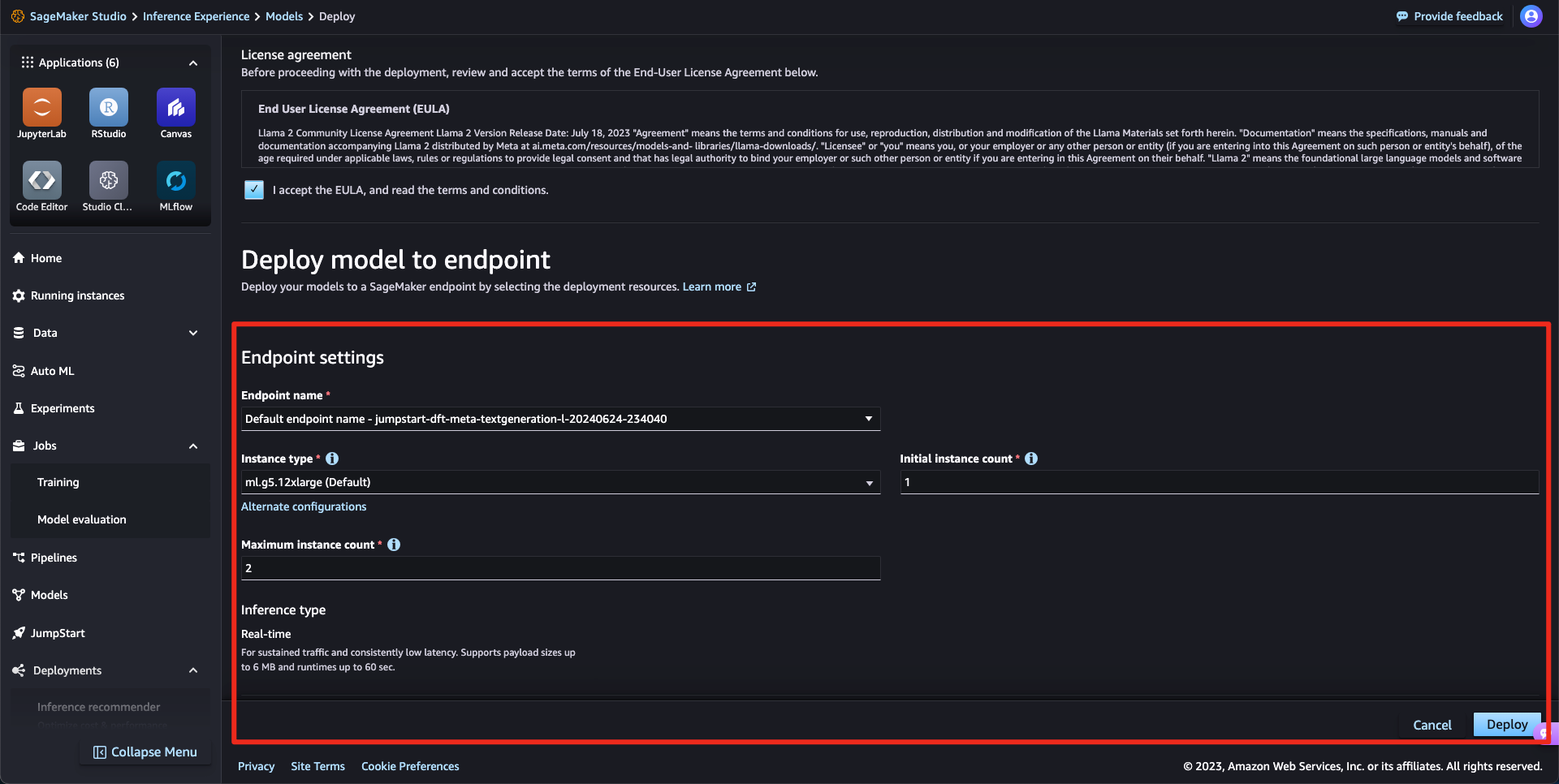
Endpoints 세팅을 진행합니다. AWS에서 제공하는 기본 권장사항으로 생성하였습니다.
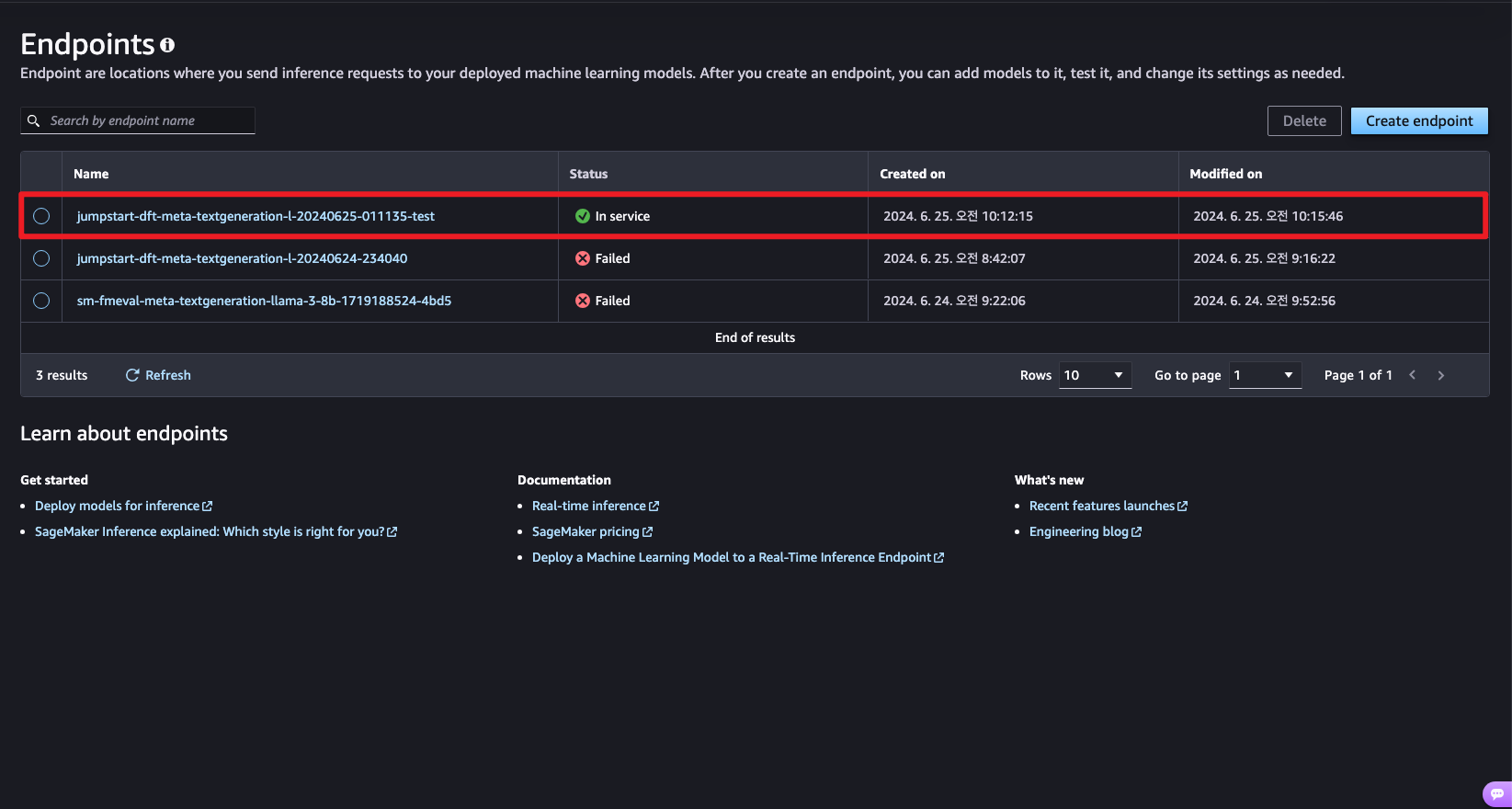
이후 배포가 성공하고 아래 코드를 통해 파인튜닝된 모델의 성능을 테스트를 진행하였습니다.
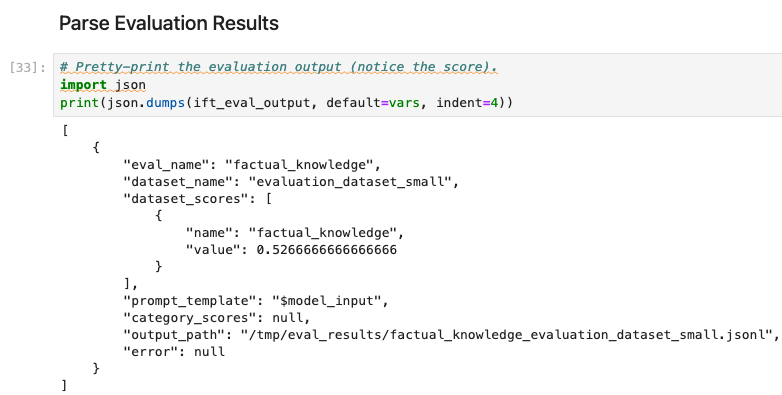
훈련 및 테스트 데이터 셋
![[LLM] VLM으로 표를 정확히 추출하기](https://images.unsplash.com/photo-1623667322051-18662ce6334c?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDl8fHBkZnxlbnwwfHx8fDE3NzIzNzMzODN8MA&ixlib=rb-4.1.0&q=80&w=960)
![[AI/ML] Qwen3-VL-4B 강화 학습(RL) 기반 파인튜닝(Unsloth) 가이드](https://images.unsplash.com/photo-1498457349504-289ee698e52c?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDZ8fFJlaW5mb3JjZW1lbnR8ZW58MHx8fHwxNzcwMTE3OTE4fDA&ixlib=rb-4.1.0&q=80&w=960)
![[AI/ML] Qwen3 VL 8B SFT LoRA Fine Tuning 가이드](https://images.unsplash.com/photo-1764477122486-5006de4bd62f?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDIwfHxtb2RlbCUyMHR1bmluZ3xlbnwwfHx8fDE3Njk4NDY4NDZ8MA&ixlib=rb-4.1.0&q=80&w=960)
![[SageMaker] SageMaker Jumpstart를 사용한 LLM Fine Tuning - Supervised fine tuning (SFT)](https://images.unsplash.com/photo-1648652678596-d3873bd0c157?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDQ2fHxTdXBlcnZpc2VkfGVufDB8fHx8MTc1MzgzMTg2Mnww&ixlib=rb-4.1.0&q=80&w=960)