[SageMaker] AWS 내장 알고리즘
Sagemaker 내장 알고리즘을 정리하였습니다.
![[SageMaker] AWS 내장 알고리즘](https://images.unsplash.com/photo-1649734926695-1b1664e98842?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDN8fEFtYXpvbiUyMFdlYnxlbnwwfHx8fDE3NTM3NDU2MDh8MA&ixlib=rb-4.1.0&q=80&w=1200)
AWS에서 정리된 모든 알고리즘입니다.
Linear Learner(선형 회귀)
훈련 데이터에 선을 맞추는게 핵심으로 x 값을 통해 y값을 예측합니다.직선적이기 때문에 모든 데이터가 선형 함수에 적합하진 않기 때문에 데이터의 특징을 잘 파악해야합니다. numeric한 예측과 classification 모두 다룰 수 있습니다.분류를 위해선 선형 임계값 함수를 사용하며 이진 분류와 멀티 클래스 분류를 할 수 있습니다.파일 혹은 파이프 모드 둘다 지원합니다(Batch or Real time)만약 시험에서 훈련 데이터가 오래 걸리는 무제가 있다면 파일 모드 대신 파이프 모드를 통해 필요한 것만 가져올 필요가 있습니다.
선형 회귀를 사용하기 위한 준비
데이터 준비
- 중요한건 훈련 데이터가 정규화 되어있어야 한다는 점(모든 특징들의 가중치가 동일)입니다.
- 선형 학습 알고리즘이 자동으로 작동하기도 합니다.
- 입력 데이터가 잘 섞여있어야합니다.
훈련
- 최적화 알고리즘을 선택할 수 있습니다.
- 여러 모델을 병렬로 훈련할 수 있습니다.
- L1과 L2의 정규화도 가능하며 조정할 수 있습니다.
- 과적합을 막는 방식으로 L1은 Feature를 선택하여 가중치 0으로, L2는 특정 가중치가 너무 크지 않도록 조절하는 방식입니다.
유효성 검사
- 여러 모델 중 최적화된 모델을 선택할 수 있습니다.
중요한 하이퍼 파라미터
- 밸런스
데이터 클래스를 균형있게 만들어줘야 합니다. 각각의 클래스를 똑같이 중요시하거나 정확도가 필요한 부분에 좀 더 밸런스를 주어야합니다.
- 학습 속도와 배치 크기
- L1 or L2 정규화
L2는 하이퍼 파라미터 집합에서 Weight decay(가중치 부패)라는 용어로 사용되기도 합니다.
- Target 정밀도(precision)
- Target 민감도(Sensitive)
정밀도를 유지하면서 민감도를 극대화하거나 민감도를 유지하면서 정밀도를 극대화하는게 중요합니다.
인스턴스 타입
- 단일 혹은 다중 머신의 CPU와 GPU로 선택해야 합니다.
- 하나의 컴퓨터에 GPU가 여러 개 있는건 별로 도움이 되지 않습니다.
XGBoost
최근 정말 핫하게 사용되는 세이지메이커에서 기본 제공되는 알고리즘으로 의사 결정 트리가 모여있는 곳입니다.이전 트리에서 발생한 실수를 수정하기 위해 계속 새로운 나무를 만들고 점점 더 나은 모델을 만들기 위해 서로 쌓아나가는 것입니다.Gradient descent(경사 하강법/그라데이션 하강)을 통해 새 나무가 추가 될 때마다 손실을 최소화하기 위해 사용합니다.
XGBoost는 오픈소스로 만들어진 프로젝트로 CSV 혹은 libsvm을 input으로 받았지만 현재는 RecordIO / protobut 그리고 Parquet 형식으로 확장하였습니다.
XGBoost를 사용하기 위한 준비
- Python Pickle을 사용해서 모델을 serialized/deserialized할 수 있습니다.
- 프레임워크를 노트북안에서 사용할 수 있습니다.
- 기본 제공 SageMaker 알고리즘을 사용하여 ECR XGBoost 이미지를 사용할 수 있습니다.
XGBoost의 중요한 하이퍼파라미터
XGBoost의 하이퍼파라미터는 많고 중요합니다.
- Subsample(하위샘플)
XGBoost에 한번에 많이 넣는 것을 방지하여 과적합을 방지할 수 있습니다.
- Eta
스텝사이즈를 줄여 과적합을 방지할 수 있습니다.
- Gamma
트리의 리프 노드에서 추가 분할을 만드는 데 필요한 최소 손실 감소를 제어하는 데 사용되는 정규화 매개변수입니다. 노드를 분할하는 프로세스는 모델에 복잡성을 추가합니다. 감마는 새로운 분할을 만드는 데 모델을 보수적으로 만들어 이러한 복잡성의 균형을 맞추는 방법을 제공합니다.'감마'를 조정하면 불필요한 작업(이 컨텍스트에서는 분할 혹은 트리의 수)을 줄여 모델의 과적합 경향을 본질적으로 제어할 수 있으며, 이는 보이지 않는 데이터에 대해 모델을 더욱 일반화하고 견고하게 만드는 데 도움이 될 수 있습니다.감마'를 늘리면 새로운 분할을 생성하기 위한 기준이 더욱 엄격해지고(손실의 최소치가 높아짐) 분할 수가 줄어들어 모델이 단순화되고 과적합을 줄여 일반화 기능을 향상시킬 수 있습니다.
- Alpha
L1 정규화와 유사합니다.
- Lambda
L2 정규화와 비슷합니다.
- eval_metric
훈련 및 검증 중에 모델 성능을 평가하는 데 사용되는 평가 지표를 나타냅니다. 다양한 작업에는 다양한 평가 지표가 필요합니다. 정확도, 정밀도, 재현율 → 분류 작업 / RMSE, MAE → 회귀작업 이러한 분류, 회귀 작업에 맞춰 모델의 성능을 측정해주는 함수입니다.공통 평가 지표
- 분류: 정확도, 로그 손실, AUC, 정밀도, 재현율, F1 점수
- 회귀분석: MSE(평균 제곱 오류), RMSE, MAE, R²(R 제곱)
- 다중 클래스 분류: mlogloss(다중 클래스 로그 손실), merror(다중 클래스 분류 오류율)
- scale_pos_weight
positive와 negative weights의 균형을 조절할 수 있습니다.
- max_depth
XGBoost에서 최대 깊이를 지정해줍니다. 너무 과하면 모델에 부담이 심해집니다.
인스턴스 타입
CPU 구현에서는 메모리 제약이 있습니다. GPU를 사용하지않을 것이라면 메모리를 최적화하는 것이 좋습니다.따라서 M5가 좋은 선택이 되지만 XGBoost 1.2에서는 단일 GPU 인스턴스로 실행할 수 있습니다. (P2, P3)트리 메서드 하이퍼파라미터를 gpu_hist를 설정할 필요가 있으며 조금 더 빨라지고 비용효율적으로 될 수 있습니다.XGBoost1.2-2
- P2, P3, G4dn, G5 인스턴스 유형도 추가되었습니다.
XGBoost 1.5+
- 분산된 GPU 훈련도 할 수 있으며, G5 클러스터를 가지고 훈련이 가능합니다.
- use_dask_gpu_training를 true
- 매개 변수를 완전 복제될 수 있도록 설정해야합니다.
- 이렇게 설정하면 훈련 데이터가 자동으로 클러스터에 걸쳐 분배됩니다.
- 분산 GPU는 오로지 CSV나 parquet Input으로만 작동합니다.
Seq2Seq
Input을 토큰의 시퀀스로 취하고 결과도 토큰의 시퀀스를 출력하는 방식입니다.문장을 토큰의 연속이라고 간주하여, 보편적으로 기계번역에서 사용합니다.토큰화된 오디오 웨이브 양식을 텍스트로 출력할 수도 있습니다.
Seq2Seq 정리
Seq2Seq는 어떻게 작동하나요?
Seq2Seq 모델은 일반적으로 두 가지 주요 구성 요소로 구성됩니다.
- 인코더: 모델의 이 부분은 입력 시퀀스(예: 번역을 위한 원어 문장)를 읽고 처리합니다. 인코더는 입력 시퀀스를 입력의 의미론적 의미를 나타내는 고정 크기 컨텍스트 벡터로 변환합니다. 이 컨텍스트 벡터는 입력 시퀀스의 내부 표현으로, 필수 정보를 캡처합니다.
- 디코더: 디코더는 인코더에서 생성된 컨텍스트 벡터에서 시작하여 한 번에 하나의 토큰씩 출력 시퀀스를 생성합니다(예: 번역을 위한 대상 언어로 된 문장). 입력 시퀀스에 의미적으로 대응하는 대상 도메인의 시퀀스를 생성하도록 설계되었습니다.
설명을 명확히 하기
- 변환: Seq2Seq 모델은 인코더를 통해 입력 시퀀스의 의미론적 본질을 이해하고 캡처한 다음 디코더를 사용하여 원래 의미를 유지하지만 다른 형식(예: 다른 언어 또는 요약 요약)으로 표현되는 새로운 시퀀스를 생성합니다.
- 생성: 출력 시퀀스는 입력 시퀀스의 컨텍스트를 기반으로 생성되며, 종종 모델에 알려진 어휘를 사용합니다. 모델은 대상 도메인에서 입력 시퀀스의 의미를 가장 잘 표현하는 방법을 학습합니다. 여기에는 콘텐츠의 표현 변경, 요약 또는 번역이 포함될 수 있습니다.
요약하면 Seq2Seq에 대한 보다 정확한 설명은 다음과 같습니다. "Seq2Seq 모델은 한 언어에서 다른 언어로 문장을 번역하거나 문서를 요약하는 것과 같이 입력 시퀀스를 다른 도메인의 의미상 동일한 출력 시퀀스로 변환하는 데 사용됩니다. 모델은 다음과 같이 구성됩니다. 입력 시퀀스를 의미론적 본질을 캡처하는 컨텍스트 벡터로 처리하는 인코더와 이 컨텍스트를 기반으로 출력 시퀀스를 생성하는 디코더입니다.RNN or CNN(optional)에 의해 구현될 수 있습니다.
Seq2Seq를 사용하기 위한 준비
- 토큰화된 텍스트 파일로 시작: 이는 Seq2Seq 모델과 관련된 작업을 포함하여 NLP 작업을 위한 데이터를 준비하는 일반적인 첫 번째 단계입니다. 토큰화는 원시 텍스트를 토큰 목록(단어, 문자 또는 하위 단어)으로 변환하여 모델 처리를 더 쉽게 만듭니다.
- 샘플 코드를 사용하여 Protobuf로 변환: Protobuf(프로토콜 버퍼)는 구조화된 데이터를 직렬화하는 방법입니다. 토큰화된 텍스트를 Protobuf 형식으로 변환하면 특히 분산 교육 시나리오에서 데이터 저장 및 전송 효율성을 간소화할 수 있습니다.
- 정수로 저장된 단어 어휘 파일: NLP에서 어휘 파일은 고유 토큰을 정수로 매핑합니다. 이 정수 표현은 신경망에 숫자 입력이 필요하기 때문에 사용됩니다.
이는 단어가 모델에 입력되기 전에 단어를 인코딩하는 중요한 단계입니다
추가적인 사항
- 토큰은 정수일 수도 있습니다: 토큰의 정수 표현은 실제로 NLP의 표준 관행입니다. 다른 알고리즘에서 사용되는 부동 소수점 데이터는 토큰 표현 자체보다는 모델에서 처리되는 가중치, 임베딩 및 연속 값에 관한 것입니다.
- 훈련 데이터, 검증 데이터 및 단어 어휘 파일 제공:훈련 데이터는 모델을 훈련하는 데 사용되고, 검증 데이터는 하이퍼파라미터를 조정하고 과적합을 방지하는 데 사용되며, 어휘 파일은 일관된 토큰-정수 매핑을 보장하는 데 사용됩니다.
모델을 사용하기 위해서는 3가지 파일을 모두 제출해야합니다.
해당 작업은 아무리 SageMaker라도 며칠이 걸릴 수 있습니다.이를 해결하기 위해 AWS에서는 미리 훈련된 모델을 제공하고 있습니다.공용 트레이닝 데이터 세트도 있어 따로 어휘 파일을 만들 필요도 없고 다른 언어로 된 단어와 어떻게 대응해야하는지도 따로 설정할 필요가 없습니다.
Seq2Seq의 하이퍼파라미터
주로 신경망 작업에 사용됩니다.
- Batch_size
- Optimizer_type (adam, sgd, rmsprop)
- Learning_rate
- Num_layers_encoder
- Num_layers_decoder
- 최적화
- Accuracy
- BLEU Score → 기계 번역 결과와 사람이 직접 번역한 결과가 얼마나 유사한지 비교하여 번역에 대한 성능을 측정하는 방법입니다
- Perplexity
여기서 중요한건 BELU score와 Perplexity는 기계 번역 문제를 측정하는데 적합하다는 것 입니다.
Seq2Seq 인스턴스 타입
딥러닝 알고리즘으로서 GPU의 장점을 취합니다.GPU 인스턴스 유형을 사용해야하며, 작업이 상당히 오래걸리기 때문에 P3 노트를 사용하여야합니다.훈련은 하나의 머신에서만 할 수 있지만 하나의 머신에 여러 기체로 병렬처리가 불가능합니다.하지만 하나의 컴퓨터에서 여러 GPU를 사용하여 쓸 수 있기 때문에, 대규모 훈련인 경우 P3같은 좋은 단일 성능을 갖춘 인스턴스를 사용하여야합니다.
DeepAR
1차원 타임시리즈 데이터를 예측하는데 사용하며 RNN의 전형적인 사례입니다.EX) 현재 + 과거의 주가를 보고 미래의 주가를 예측시간의 연속성이 상호 의존적인 관계가 많다면 시간 연속성의 관계를 통해 학습하여 각각의 시간연속성을 예측하는 더 나은 모델을 만들 수 있습니다. → 빈도와 계절성을 찾는데 유용합니다.
DeepAR을 사용하기 위한 준비
다양한 형식의 데이터를 사용할 수 있습니다.
- JSON 라인 형식
- Gzip or Parquet
- 기본적으로 포함되는 값들
- Start: 시작 시간표(starting time stamp)
- Target: 타임시리즈 데이터(time series values)
- 다음과 같은 값들이 포함될 수 있습니다.
- Dynamic_feat: 동적인 특징들(dynamic features) 상품에 적용된 프로모션이나 범주화된 특징

- 항상 훈련, 테스트, 예측을 향상시키기 위해선 전체 데이터 세트를 사용해야합니다.
- 전체 데이터셋에 대한 테스트 셋을 활용하고 싶다면 최근 타임포인트를 훈련을 위해 제거해야합니다.
- 400개의 데이터 포인트를 예측하는건 너무 크기 때문에 불가능합니다.
- 여러 타임시리즈를 훈련할 수 있다면 한 가지뿐만 아니라 여러 가지를 연결할 수 있습니다.
DeepAR의 중요한 환경 변수들
하이퍼파라미터로는 딥러닝에서 사용되는 변수들이 가장 많습니다. 여러 히스토리에 걸쳐 훈련하고 제
- Context_length
- 모델이 예측하기 전에 보는 타임 포인트의 갯수입니다.
- 이는 기본적으로 모델이 예측을 수행하는 데 사용하는 과거 관찰 윈도우의 크기입니다.
context_length는 최소한 예측 범위만큼 길어야 하지만 더 길게 설정하면 더 많은 컨텍스트를 제공하는 데 도움이 될 수 있습니다.
- Epochs
- mini_batch_size
- Learning_rate
- Num_cells
DeepAR 인스턴스 타입
- CPU or GPU 인스턴스를 사용할 수 있습니다.
- 단일 컴퓨터나 다중 컴퓨터에서도 실행할 수 있으며, 확장성이 뛰어납니다.
- 반드시 GPU를 사용할 필요는 없고 특히 ML작업의 경우 CPU 인스턴스로 시작하는게 유효할 수 있습니다.
- 보통 튜닝 단계에서 오래 걸리기 때문에 튜닝 단계에서는 큰 인스턴스를 사용했다가 실제 생산 단계에서는 줄이는 것도 유효합니다.
BlazingText
문자(text) 분류
- 주어진 문장에 대해 라벨을 예측할 수 있습니다.
- 웹 검색, 정보 검색에 사용될 수 있지만 전체 문서가 아닌 문장과 관련해서만 사용됩니다.
- 직접적인 감독하에 여러 문장과 그 문장을 연결하는 라벨을 붙여서 훈련하는 방식입니다.
Word2vec
- 단어 내장 레이어, 즉 단어의 벡터 표현을 생성합니다. 의미적으로 유사한 단어들이 벡터가 되어 내장 레이어에서 서로 비슷한 단어를 찾게 됩니다.
- 이를 통해 번역이나 감정 분석같은 작업을 할 수 있도록 사전 처리를 합니다.
- Word2vec의 기본적인 구현에서는 직접적으로 전체 문장이나 문서를 처리하지 않습니다. 대신, 단어들이 문장 내에서 다른 단어들과 어떻게 상호작용하는지를 통해 학습이 이루어집니다.
각 단어는 문장 내의 맥락 속에서 의미를 학습하지만, 이러한 학습은 개별 단어 수준에서 이루어집니다. 따라서, Word2vec은 문장이나 문서 전체의 의미를 직접적으로 모델링하지는 않으며, 단어 간의 관계와 맥락을 통해 단어의 벡터 표현을 학습합니다.
BlazingText를 사용하기 위한 준비
문자 분류를 사용하는 감시 모드를 통해 학습합니다.
- 한 줄당 한 문장만을 입력합니다.
- BlazingText(또는 fastText)에서 지도 학습을 위한 데이터를 준비할 때, 각 텍스트 샘플(예를 들어 문장, 문서 등)의 첫 번째 "단어"는
__label__문자열과 그 뒤에 오는 레이블로 구성됩니다. 이 형식은 모델이 텍스트를 어떤 카테고리에 분류해야 하는지를 학습하는 데 필요한 정보를 제공합니다.
Word2vec에서는 텍스트 파일을 사용합니다. 라인당 훈련 문장 하나로 __label__뒤에 숫자를 붙여 토큰화합니다.이걸 토큰화해서 알고리즘에서 대소문자를 구분할 수 없도록 소문자로 변경하게 됩니다.input 형식은 매우 중요합니다. 증강된 텍스트 형식이 나오지만 여기선 그걸 합치는 구조화된 방식에 더 가깝습니다.레이블 필드엔 소스, 미리 처리된 문장 토큰화와 라벨 번호 등이 있습니다. Word2vec에는 다양한 모드가 있습니다.
- Cbow
끝없는 단어 가방이라는 뜻으로 단어의 순서가 중요한 구조가 아니라 서로 연결이 안 된 단어들이 있고 그 사이의 관계를 학습하는 방식입니다. 따라서 훈련하는 동안 실제 단어 순서가 바뀌게 됩니다.
- Skip-gram, Batch skip-gram
많은 CPU 노드로 분산될 수 있습니다.
BlazingText 하이퍼파라미터
Word2vec
- 모드
- 학습률
- 윈도우 사이즈
- 벡터 차원
- 네거티브 샘플
텍스트 분류
- 반복 횟수
- 학습률
- Work_Ngrams(문장을 몇개 단위로 끊을 것인지)
- 벡터 차원
BlazingText 인스턴스 타입
batch_skipgram같이 모드만 다중 CPU 인스턴스를 사용할 수 있습니다.GPU CPU 상관없이 사용할 수 있고 필요에 따라 확장할 수 있습니다.
Object2Vec
Word2Vec과 유사하지만 전체 문서에서 작동할 수 있습니다.Object2Vec는 고차원 객체를 저차원의 밀집 벡터(embeddings)로 변환하는 기술입니다. 이는 Word2Vec의 개념을 확장하여, 단어 이외의 다양한 유형의 데이터(예: 문서, 이미지, 사용자, 상품 등)를 처리할 수 있도록 설계된 모델입니다. 객체의 모든 속성을 가져다가 저차원 표현으로 만드는 것으로 각각의 객체의 관계를 이해하고 저차원 벡터로 표현한 것입니다.클러스터링을 위해 객체의 가장 가까운 이웃을 계산해서 원한다면 해당 클러스터를 시각화할 수 있습니다.장르 예측이 가능하며 유사한 아이템 추천등에 사용합니다.아이템과 사용자에서 서로의 관계를 찾아 저차원 벡터로 매칭시키는 방식입니다. 이를통해 개인화된 추천, 군집화, 유사성 검색 등을 할 수 있습니다.
Object2Vec을 사용하기 위한 준비
- 데이터를 정수로 토큰화해야합니다.
- Object2Vec는 토큰 쌍 혹은 토큰의 시퀀스로 구성되어 있습니다.
- 문장 - 문장
- 라벨 - 시퀀스(장르와 설명 관계)
- 고객과 고객
- 상품과 상품(축구 제품 - 농구 제품)
- 유저와 아이템(사용자 ID와 구매한 상품)
- 이를통해 Object2Vec은 서로 다른 속성을 바탕으로 관계를 찾는 방식입니다.
입력 경로마다 각각의 인코더를 선택할 수 있으며, 데이터에 가장 좋은 방법을 다양하게 사용할 수 있습니다.
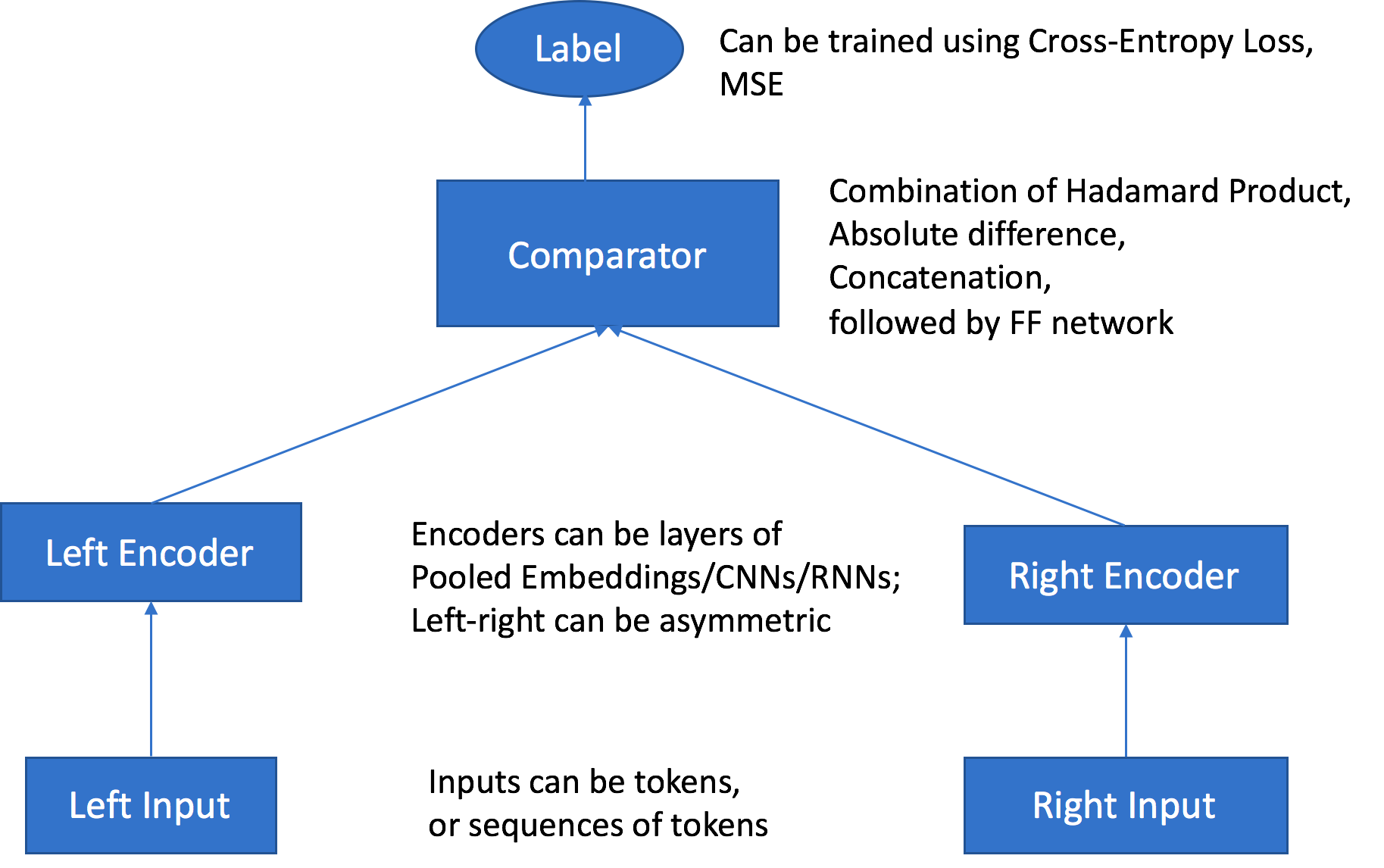
Comparator에 연결된 신경망은 Feed Forward 신경망을 통해 구성되어있습니다.
Object2Vec의 하이퍼파라미터
- 딥러닝의 중요한 파라미터들이 등장합니다.
- Dropout, Early stopping, epochs, 학습률, 배치사이즈, 레이어, 활성함수, 최적화, Weight decay
- Enc1_network, enc2_network가 있으며 각각의 입력 채널에 맞는 인코더 타입을 선택합니다.
- CNN, LSTM, pooled_임베딩 레이어도 될 수 있습니다.
Object2Vec 인스턴스 타입
- 하나의 머신에서만 훈련할 수 있습니다. CPU나 GPU 인스턴스일 수도 있고 다중 GPU 인스턴스 또한 가능합니다.
INFERRED_MOD 환경 변수를 사용해 인코더 임베딩에 사용하여 최적화할 수 있습니다.
Object Detection(개체 감지)
이미지 속 모든 객체를 식별하는게 핵심입니다.심층 신경망을 이용해 물체를 감지하고 분류합니다. 처음부터 훈련시키거나 MXNet의 경우 ImageNet에 근거해 훈련되어있는 모델을 사용할 수 있습니다.
Object Detection을 사용하기 위한 준비
두 개의 variants가 있습니다. → MXNet과 Tensorflow
- 이미지를 입력과 출력으로 받으며 이미니 내의 모든 개체 인스턴스와 카테고리, 신뢰 점수를 출력합니다.
- MXNet 버전은 콘볼루션 신경망을 사용하며 싱글샷 멀티플렉스 디코더와 SSD 알고리즘을 사용합니다.
- VGG-16 or ResNet-50일 수도 있습니다.
- 학습모드와 점진 훈련모드가 갖춰져있지만 미리 훈련된 모델을 사용하는게 더 유용합니다.
- 내부는 flip, rescale, jitter(이미지 밝기 조절)를 사용하여 과부화를 예방합니다.
- Tensorflow
- ResNet, EfficientNet, MoblieNet 모델을 텐서플로우 모델 가든에서 고를 수 있습니다.
어떻게 사용하고 구성하는지는 선택한 모델에 따라 달라집니다.
- ResNet, EfficientNet, MoblieNet 모델을 텐서플로우 모델 가든에서 고를 수 있습니다.
MXNet의 경우 RecordIO 포맷 혹은 이미지(JPG, PNG)를 사용합니다. 이미지 포맷으로 훈련할 땐 각 이미지에 대해 annotation 데이터를 위해 JSON 파일을 제공합니다. 고유의 데이터로 개체 감지 훈련을 진행합니다.
Object Detection을 사용하기 위한 하이퍼파라미터
MXNet과 Tensorflow에는 중요한 하이퍼파라미터들이 있습니다.
- MXNet → Mini_batch_size
- Tensorflow → Batch_size
서로 같은 파라미터로 훈련중인 배치량을 조정하는 표준 기술입니다.
- Learning_rate(학습률)
학습률은 이 가중치 조정의 크기를 결정하며 데이터에 가장 적합한 최적화 툴 중 하나를 선택할 수 있습니다.
Object Detection을 위한 인스턴스 타입
- 훈련을 위해 GPU 인스턴스를 사용하며 멀티 GPU, 다중 머신 또한 가능합니다.
- 예측할 땐 CPU나 GPU 모두 사용할 수 있습니다.
Image Classification(이미지 분류)
이미지 분류
- 이미지 전체가 어떤 카테고리에 속하는지를 결정합니다.
- 이미지를 대표하는 단일 레이블로 이미지에 여러 객체가 있더라도 이미지는 가장 주요한 객체나 장면의 하나의 카테고리만을 예측합니다.
객체 탐지
- 이미지내의 여러 객체를 식별하고 각 객체를 박스로 표시하여 객체의 카테고릴 분류합니다.
- 이미지 하나에 하나 이상의 라벨을 할당합니다.
Image Classification을 위한 준비
Object Detection처럼 MXNet에 대한 알고리즘과 새로운 Tensorflow 버전이 따로 존재합니다.MXNet 버전
- 완전 훈련 모드가 따로 존재합니다. 네트워크는 무작위 웨이트로 초기화되어 있습니다.
- Transfer Learning Mode →사전에 훈련된 가중치로 초기화되어있습니다.
- 빨강, 초록, 파랑 224 * 224로 이미지넷의 데이터셋과 일치합니다.
Tensorflow 버전
- 턴세플로우 허브에서 고른 특정 모델에 따라 세부사항이 달라집니다.
- (MoblieNet, Inception, ResNet, Efficient Net) 분류할 때 효율적인 알고리즘을 선택할 수 있습니다.
- 상위 레벨 레이어를 추가해 파인튜닝이나 추가적은 훈련을 진행할 수 있습니다.
- 따라서 미리 훈련된 모델을 가지고 확장해서 몰랐던 새로운 물체를 식별할 수 있습니다.
Image Classification을 위한 하이퍼파라미터
- 딥러닝에서 자주 사용되는 변수들
- Batch size, learning rate, optimiizer
- 최적화에 특화된 변수들
- Weight에 특화된 변수들도 존재합니다.
- Weight decay, beta1, beta2, eps, gamma
- Tensorflow의 기본 모델과 MXNet의 차이는 아주 조금 다른점이 있으니 주의해야합니다.
Image Classification 인스턴스 타입
훈련할 때는 GPU를 사용해야합니다.다중 GPU 다중 머신 모두 사용가능하며 추론할 때는 CPU 혹은 GPU도 사용 가능합니다.
Semantic Segmentation

이미지 내의 모든 객체가 픽셀 수준에서 분류되며, 같은 클래스에 속하는 픽셀들은 같은 레이블로 표시됩니다.픽셀 레벨로 내려가 의료 영상이나 진단 로봇 감지 등으로 각각의 픽셀을 레이블이나 분류에 매핑하는 마스크를 만드는데, 이것을 세분화 마스크라고 합니다.
Semantic Segmentation을 사용하는 방법
- 훈련 시 JPG 혹은 PNG 파일에 주석이 붙어있어야합니다.
- 훈련과 유효성 검사 데이터도 필요합니다.
- annotations를 일반 영어로 설명하는 라벨 맵도 존재합니다.
- 성능 향상을 위해 파이프 입력 모드를 사용하고 싶다면 증강된 manifest 이미지 포맷을 사용할 수 있습니다.
- pipe 입력 모드란 디스크 I/O를 사용하지 않고 알고리즘 컨테이너에 직접 입력할 수 있습니다.
- 다중 스레드 백그라운드 프로세스를 통해 s3에서 데이터를 패치합니다.
- pipe 입력 모드란 디스크 I/O를 사용하지 않고 알고리즘 컨테이너에 직접 입력할 수 있습니다.
MXNet Gluon 혹은 Gluon CV 베이스로 구축되어 알고리즘 3가지 중 선택권을 받습니다.
- Fully-Convolutional Network(FCN)
- Pyramid Scene Parsing(PSP)
- DeepLabV3
Backborn이미지 분류, 객체 탐지, 시맨틱 세그멘테이션 등에서 backbone 네트워크는 입력 이미지로부터 중요한 정보와 패턴을 추출하는 역할을 합니다.
- ResNet50
- ResNet101
새로운 개체 세트로 훈련할 수도 있고 ImageNet을 기반으로 시작해 그걸 기반으로 점진적인 훈련도 가능합니다.
Semantic Segmentation의 하이퍼파라미터
- Epochs, 학습률, 배치 사이즈, 최적화, 알고리즘, Backbone(하이퍼파라미터 세그먼트화를 조정할 때 필요합니다)
Semantic Segmentation의 인스턴스 타입
GPU 인스턴스만 훈련용으로 지원하며 예측시엔 CPU 인스턴스를 사용할 수 있습니다.
Random Cut Forest
아마존에서 이상현상 감지를 위해 사용하는 알고리즘으로 관리감독없이도 동작합니다.기본적으로 일련의 데이터를 보고 일련의 데이터에서 이상한 점을 찾아내는 것 입니다.레이블된 훈련데이터가 필요 하지 않지만, 데이터의 정상 범위와 구조를 학습하는 과정이 필요합니다.
Random Cut Forest를 위한 준비
RecordIO - Protobuff 혹은 CSV 포맷을 사용하여 파일이나 파이프모드를 사용할 수 있습니다.정확도 혹은 정밀도, 재현율(민감도)를 계산하고 싶다면 테스트 채널을 사용할 수 있습니다.혹은 레이블된 데이터(이상인지 아닌지)를 F1 스코어를 사용할 수 있습니다.기본적인 알고리즘으로는 Random Forest와 유사하게 훈련 데이터를 분할하여 학습하고 결과를 관찰합니다.새로운 데이터 포인트를 추가하면 많은 가지들이 형성되도록하며 기본적인 결정 트리의 속성을 사용합니다. 만약 결정 트리가 새로운 데이터 포인트를 위해 많은 가지를 만들어낸다면 해당 데이터 포인트에 무언가 문제가 있다는 것을 의미할 수 있습니다. RCF는 키네시스 Analytics에서도 나타나며 데이터 스트림에서 이상 현상을 감지하는데 사용됩니다.스트리밍 데이터에서도 쓸 수 있으며, 데이터 묶음에 국한되지 않습니다.
RCF에서 하이퍼파라미터
가장 중요한 기준은 나무의 수 입니다.
- Num_trees가 많으면 많을 수록 Noise를 줄일 수 있습니다.
- Num_samples_per_tree 나무 한 그루당 표본 개수가 일반 데이터에 비해 이례적인 비율과 비슷합니다.
- 각 결정 트리(decision tree)를 훈련시키기 위해 사용되는 샘플의 수를 지정합니다.
랜덤 포레스트와 같은 앙상블 학습 방법에서는 여러 개의 결정 트리를 생성하고, 각 트리의 예측을 결합하여 최종 예측을 수행합니다.num_samples_per_tree파라미터는 이러한 각각의 트리가 얼마나 다양한 데이터 샘플을 기반으로 학습할지를 결정하는 데 중요한 역할을 합니다. - 데이터에서 이례적인 비율을 알고있다면 나무당 sample를 조정해서 이례적인 걸 더 잘 식별할 수 있습니다.
- 각 결정 트리(decision tree)를 훈련시키기 위해 사용되는 샘플의 수를 지정합니다.
RCF 인스턴스 타입
GPU를 이용하지 않는 간단한 알고리즘으로 C5,M5로 훈련할 수 있습니다.ml.c5.xl은 추론시 유용합니다.
Neural Topic Model(NTM)
- 문서가 무엇인지를 파악하여, 문서를 주제로 정리하기 위한 모델입니다. 비지도 학습 방식으로 자동으로 주제를 학습하고 식별합니다.
- 분류에 사용하 수도 있고, 나타낸다고 생각되는 주제에 근거해 문서를 요약할 수 있습니다.
- 단순한 TF/IDF 형식이 아니라 용어가 나타내는 바를 더 높은 수준으로 묶어내는 것입니다.
- 관리감독이 필요없습니다.
- Neural Variational Inference → 신경 변이 추론이라고 일컫습니다.
Neural Topic Model을 사용하기 위한 준비
- 4개의 데이터 형식이 있습니다.
- train 필수 / validation, test, auxiliary 옵션값입니다.
- recordIO - protobuf or CSV 데이터를 넘겨 문서 세트를 분석할 수 있습니다.
- 단어는 토큰으로 정수화해야합니다.
- 원본 텍스트만 보내는게 아니라 먼저 문서를 쪼개 각 단어의 토큰으로 변환해야합니다. 이후 어휘 파일로 넘겨서 문서에 나타나는 숫자와 단어들을 매핑시킵니다.
- 모든 문서마다 모든 단어의 수를 세어 개별적인 CSV 파일로 만들어냅니다.
- 어휘 데이터는 보조 채널에 사용되어 파일이나 파이프 모드로 사용할 수 있습니다.
Topic option
- 얼마나 많은 토픽을 원하는지 정의해야합니다.
- 이렇게 만들어진 토픽은 사람이 읽을 수 없고, 알고리즘 상에서 유지되며 관리감독없이 학습하는 방식입니다.
따라서 만들어진 문서 중 상위 순위 단어들을 기반으로 잠재적 표현으로 만들어집니다.
Topic Modeling을 통해 얻어진 각 주제는 문서 내에서 가장 빈번하게 나타나는 관련 단어들에 의해 정의되고, 이 단어들을 통해 주제의 내용을 추론할 수 있음을 나타냅니다. - 주제는 문서 내에서 자주 등장하는 단어들을 기반으로 결정되며, 이 단어들의 집합을 유지하여 새로운 문서의 주제를 추론하는 것이 주제 모델링의 핵심입니다.
잠재적 표현
"잠재적 표현"이란 주제나 개념을 직접적으로 관측할 수 없을 때, 그것을 간접적으로 나타내는 데이터의 형태를 말합니다. 예를 들어, 문서에 나타난 단어들을 분석하여 주제를 유추하는 것과 같이, 원래의 데이터에서 추출된 추상적인 특성이나 패턴을 나타냅니다.
Neural Topic Model의 중요한 하이퍼 파라미터
- Lowering mini_batch_size, 학습률을 통한 손실함수를 줄일 수 있습니다.
- Num_topics
Neural Topic Model의 인스턴스 타입
딥러닝이기 때문에 GPU를 사용하는게 좋습니다.추론시에는 CPU가 좋으며 CPU가 더 저렴합니다.
LDA (Latent Dirichlet allocation)
- 딥러닝이 아닌 다른 방식의 주제 모델링 알고리즘입니다.
- 관리감독이 필요없습니다.
- 토픽 그 자체론 라벨이 없고, 문서들이 공유하는 공통된 단어가 뭔지에 따라 구성된 문서 그룹입니다.
- 주제 모델링이 아닌 다른 용도로 사용될 수 있습니다.
- 구매 내역에 따라 고객들을 클러스터할 수 있고 알고리즘을 이용해 음악 분석도 가능합니다.
- 관리감독없는 클러스터링과 개체의 공통점들에 근거해서 그룹을 만들 수 있습니다.
LDA를 사용하기 위한 준비
- 훈련용 채널이 필요하며, 선택적으로 옵셔널한 채널을 사용할 수 있습니다.
- 토큰화(Tokenization): 문서 내의 텍스트를 개별 단어나 토큰으로 분리하는 과정입니다. 이는 LDA 모델이 단어의 분포를 분석하여 주제를 추출하는 데 필수적입니다.
- 어휘 목록(Vocabulary) 생성: 토큰화된 데이터를 바탕으로 어휘 목록을 생성합니다. 이 목록은 문서 집합에서 발견된 모든 고유 단어를 포함하며, 각 단어에는 고유한 인덱스가 할당됩니다.
- 데이터 포맷팅: LDA 모델 학습을 위해, 데이터를 모델이 처리할 수 있는 형식으로 변환해야 합니다. AWS에서 LDA를 사용할 경우, RecordIO-protobuf 또는 CSV 포맷을 지원합니다.
- recordIO 형식만 파이프 모드를 지원합니다.
- 관리감독이 필요없으며, 정확도를 측정하기 위해 테스트 채널을 사용할 수 있습니다.
- Per-word log
- NTM과 유사하지만, LDA는 CPU 기반입니다.
LDA 하이퍼 파라미터
- Num_topics
- 단순한 서류 묶음으로 얼마나 세밀하게 조정할지를 결정합니다.
- 너무 적은 수의 주제를 설정하면 다양한 정보가 충분히 반영되지 않을 수 있으며, 너무 많은 주제를 설정하면 과적합(overfitting)이 발생하거나 주제 간의 구분이 모호해질 수 있습니다.
- 생성된 주제들은 기본적으로 단어 분포로 표현됩니다. 즉, 각 주제는 문서 집합 내에서 함께 자주 나타나는 단어들의 집합으로 구성되며, 이러한 단어들의 확률 분포를 통해 주제를 정의합니다.
이 과정에서 LDA는 주제를 숫자나 코드로 직접 레이블링하지 않습니다. 따라서 LDA가 생성하는 주제들은 "사람이 읽을 수 없는(human-unreadable)" 형태, 즉 직관적인 레이블이나 이름 없이 숫자와 단어 분포로만 표현됩니다.
- Alpha0
- 작은 값은 서로 주제를 적게 만들지만 큰 값은 다양한 주제를 생성합니다.
따라서 LDA같은 주제 모델링에서 가장 중요한 파라미터는 주제 개수입니다.
LDA 인스턴스 타입
단일 CPU 노드면 충분합니다.
KNN(K-Nearest Neighbor)
분류(classification)와 회귀(regression) 문제에 사용되는 간단하면서도 효과적인 머신러닝 알고리즘 중 하나입니다.
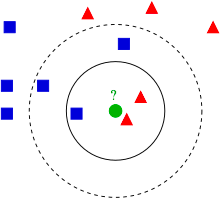
주어진 데이터 포인트(샘플)에 대해, K-NN은 특성 공간(feature space) 내에서 가장 가까운 K개의 이웃 데이터 포인트를 찾아, 이들의 레이블을 기반으로 샘플의 레이블을 예측합니다. 가장 유사한 K를 살펴보면 됩니다.회귀의 경우 가장 가까운 K개의 이웃에서 에측하고자하는 특성의 평균 값을 반환시킵니다.
KNN을 사용하기 위한 준비
- 사용자의 데이터를 테스트 채널에 포함할 수 있습니다.
- 테스트 채널은 정확도 또는 MSE의 정확도를 측정하는데 사용할 수 있습니다
- RecordIO - protobuf 혹은 CSV를 사용할 수 있습니다.
- CSV의 경우 첫 번째 열은 레이블 데이터
- 파일과 파이프모드 모두 사용할 수 있습니다.
- 데이터 샘플을 채취합니다.
- Sagemaker에서는 고차원 데이터의 차원의 저주를 피하기 위한 차원 축소 기법을 사용합니다.
- 하지만 노이즈와 정확성이 trade-off 될 수 있습니다.
- Sign과 fjit 메소드를 통해 차원을 감소시킵니다.
- 이웃을 빨리 검색할 수 있는 인덱스를 생성합니다.
- 모델을 직렬화합니다.
- 주어진 K를 모델에 쿼리합니다.
KNN의 중요한 하이퍼파라미터
- 가장 중요한 파라미터는 k입니다. 많은 이웃을 살펴보면 살펴볼수록 원하는 값을 얻을 수 있습니다.
- Sample_size 많으면 많을수록 정확합니다
KNN 인스턴스 타입
- CPU나 GPU 인스턴스에서 훈련할 수 있습니다.
- CPU는 latency를 낮추지만 GPU는 큰 배치에 대한 처리량을 높여줍니다.
K-Means
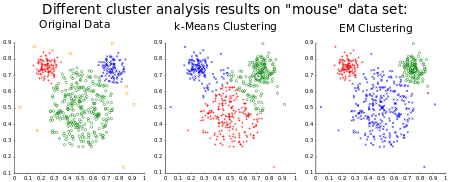
- 비지도 학습: K-Means는 비지도 학습 알고리즘입니다. 즉, 레이블이 지정된 입력 데이터에 의존하지 않습니다. 데이터 자체 내의 패턴과 구조를 식별합니다.
- 데이터 분할: 알고리즘은 각 클러스터 내의 분산을 최소화하고 서로 다른 클러스터 간의 분산을 최대화하여 데이터 세트를
K클러스터로 나눕니다. 'K' 값은 사용자가 지정하는 하이퍼파라미터로, 형성할 클러스터의 개수를 나타냅니다. - 특성 공간: K-평균은 데이터 세트의 특성 공간에서 작동하며, 여기서 각 차원은 데이터의 특성을 나타냅니다. 알고리즘은 유사성을 확인하기 위해 이 공간에 있는 데이터 포인트 사이의 거리를 계산합니다.
- 중심: 각 클러스터는 클러스터에 있는 포인트의 평균인 중심으로 표시됩니다. 알고리즘은 수렴할 때까지 각 클러스터에 할당된 모든 점의 평균을 계산하여 중심을 반복적으로 업데이트합니다.
SageMaker는 Web-scale K-Means 클러스터링을 통한 대규모로 동작할 수 있게 구성하였습니다.
K-Means를 사용하기 위한 준비
- 훈련용 채널이 필요하며 비지도학습이기 때문에 테스트 채널은 선택사항입니다.
- 테스트 데이터와 결과를 비교할 때만 사용됩니다.
- 테스트할 때 s3와 어떻게 상호작용할지 지정할 수 있습니다.
- 훈련의 경우 트레이닝 노트에 모든 걸 복사하는게 아닌 s3 키로 스케일을 나눠 복사하면 좋습니다.
- 여러 개의 디바이스를 훈련에 사용한다면 더 효과적입니다.
- recordIO - protobuf 혹은 CSV
- 파일 및 파이프모드를 지원합니다.
- K-Means 알고리즘은 실제로 관측치를 N차원 공간에 배치합니다. 여기서 N은 특징의 수입니다.
그런 다음 각 클러스터 내의 분산을 최소화하여 데이터 포인트를 클러스터링하고 이 기능 공간의 유클리드 거리를 기반으로 유사한 관찰을 효과적으로 그룹화합니다.- K-Means의 주요 목표는 각 클러스터 중심으로부터의 점 거리의 합이 최소화되도록 K 중심(클러스터 중심)의 최적 위치를 찾는 것입니다.
- 표준 K-means의 경우 클러스터간 너무 가까워질 수 있습니다. 이러한 문제를 해결하기 위해 k-means++를 사용하게 됩니다.
- K-Means++는 K-Means 클러스터링 알고리즘의 초기 값(또는 "시드")을 선택하기 위한 알고리즘입니다. K-평균++의 목표는 표준 K-Means 최적화 반복을 진행하기 전에 초기 클러스터 중심을 분산시키는 것입니다.
이 접근 방식은 서로 멀리 떨어져 있는 중심을 초기화하여 더 나은 클러스터링을 찾는 경향이 있으며, 이는 수렴을 개선하고 잘못된 초기 중심 선택 문제를 완화할 수 있습니다.
K-Means의 중요한 하이퍼 파라미터들
- K!
- k값을 초기에 올바르게 사용하는건 매우 어렵습니다.
- elbow 메소드를 통해 기본적으로 클러스터간 너무 좁게 구성되어있는 걸 최적화할 수 있습니다.
- 클러스터의 탄력을 최적화해야하며 제곱의 집합으로 측정하는게 그 이유 입니다.
- Mini_batch_size
- Extra_center_factor
- Init_method (SageMaker의 K-means++ 모델을 조정)
K-means의 인스턴스 타입
- CPU 권장, GPU도 가능합니다.
- GPU의 경우 인스턴스당 GPU 하나만 사용됩니다.
PCA (Principal Component Analysis) - 차원 압축
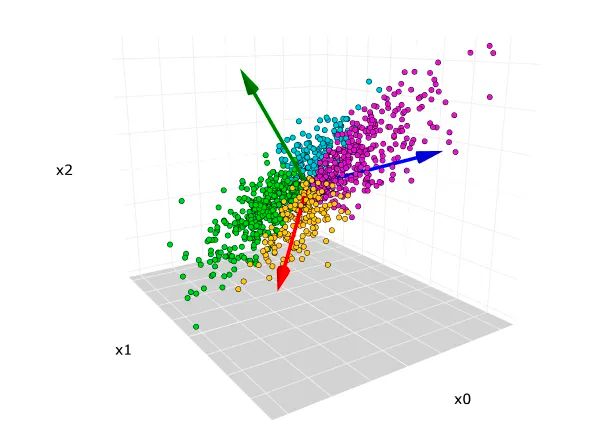
차원 감축 기술로 고차원의 데이터를 가져오는 방법입니다.다양한 특징이나 속성을 함유한 데이터를 저차원 공간에 넣으며 작업이 훨씬 쉬워집니다. 이것을 차원의 저주라고 하며 이것을 피하기 위한 방식으로 사용됩니다.사용자 데이터의 feature를 적은 수로 축소하는 방법이며, 고차원 데이터를 저차원 공간으로 투사하면서 정보의 손실을 최소화하는 방식입니다. 이를 통해 많은 기능과 속성을 가진 데이터를 더 적은 속성으로 압축하여 효율적으로 변동성을 나타낼 수 있습니다.
PCA는 기계 학습을 위한 데이터 전처리의 차원 축소에 널리 사용됩니다. 기능 수를 줄이면 모델을 단순화하고 속도를 높이며 과적합 위험을 줄이는 데 도움이 됩니다.비지도학습으로 만들어지며, 과정을 거쳐 기본 구성 요소로 정제 됩니다.
PCA를 사용하기 위한 방법
- RecordIO - protobuf 혹은 CSV를 사용합니다.
- 파일과 파이프 모두 지원합니다.
- Covariance matrix(데이터 세트의 여러 변수 간의 선형 관계에 대한 시각화를 제공하는 지표)를 만들어 SVD라는 알고리즘으로 규모를 줄입니다.
- SageMaker에는 두 가지 모드가 있습니다.
- Regular: 데이터가 적은 경우 또는 관찰과 feature가 적절한 경우 사용됩니다.
- Randomized : 많은 양의 관찰과 Feature가 필요한 경우 사용됩니다. 추정 알고리즘을 사용합니다.
PCA의 중요한 하이퍼 파라미터들
- Algorithm_mode
- Subtract_mean
- 편향을 제거하는데 유용합니다.
PCA의 인스턴스 타입
- GPU or CPU 모두 가능하며 입력 데이터의 세부 사항에 따라 달라집니다.
Factorization Machines(추천시스템)
Feature 간의 모든 상호 작용을 고려할 수 있는 범용 예측 모델입니다.
- 부족한 데이터셋에서의 예측에 유용하며, 추천 시스템, 등급 예측, 회귀, 분류 등 다양한 태스크에 적용될 수 있습니다.
- 추천 시스템으로 사용자가 좋아할만한 페이지나 제품을 예측하고자하지만 문제는 엄청난 수의 페이지나 엄청난 수의 제품속에서 제품을 추천하기는 쉽지 않습니다.
- 훈련 목적으로 데이터를 많이 확보할 수 없으며 실제로는 전체 제품 카탈로그 중에서 아주 적은 수의 제품에 대한 정보만 갖고 있을 수 있습니다.(데이터가 흩어져있다는 것을 의미합니다.)
- 개개인에 대한 몇 가지밖에 모르며, 상호작용하지 않은 것에 대해 어떻게 생각하는지를 만들어야합니다.
- 수백만 개의 상품 중 어떤 걸 클릭할지를 예측하는 것과 같습니다.
- 지도학습으로 분류와 회귀 모델을 함께 사용할 수 있습니다.
- 해당 제품을 좋아하는지 여부, 특정 점수 값으로 구성..
- 최소 2차원 데이터가 필요합니다. (사용자와 아이템..)
Factorization Machines을 사용하기 위한 준비
- Float32의 데이터 포맷에서 RecordIO - protobuf
- 부족한 데이터에서 CSV는 실용적이지 않습니다.
- 매우 제한된 상호 작용 데이터를 기반으로 다양한 항목에 대한 사용자 선호도를 예측하거나 분류하는 것입니다.
- 기능 간의 복잡한 상호 작용을 캡처하는 기능은 제한된 상호 작용 데이터로 정확한 예측을 목표로 하는 추천 시스템과 같은 애플리케이션에 적합합니다.
- 기능 간의 복잡한 상호 작용을 캡처하는 기능은 제한된 상호 작용 데이터로 정확한 예측을 목표로 하는 추천 시스템과 같은 애플리케이션에 적합합니다.
Factorization Machines의 중요한 하이퍼 파라미터
- 편향과 선형에 대한 초기 설정을 할 수 있습니다.
- Uniform, normal, constant
- Factorization Machines에 대한 여러 값들과 다이얼이 있습니다.
Factorization Machines의 인스턴스 타입
- CPU or GPU
- CPU가 추천되며 GPU는 데이터가 많을 때 유용합니다.
Factorization Machine은 데이터가 적은 곳에서 처리하고 분류하여 예측하는 것에만 집중합니다.
IP Insights
주어진 IP 주소에서 수상한 행동을 자동으로 찾아내는 기술입니다.이례적인 IP 주소에서 로그인 시도를 식별할 수 있으며, 비정상적인 IP 주소에서 리소스를 생성하는 계정을 식별할 수 있는 기본적인 보안 도구로 사용됩니다.웹로그를 분석할 때 사용되는 것으로 신호를 보내거나 세션을 종료할 수 있는 의심스러운 행동을 찾아내는 방식입니다.
IP Insights를 사용하기 위한 준비
- 사용자 이름과 계정 ID를 직접 받아들이기 때문에 데이터를 미리 처리할 필요가 없습니다.
- 훈련용 채널은 있으며, 유효성 검사는 선택사항입니다.
- CSV 형식만 사용 가능합니다.
- Entity, IP주소 뿐입니다.
- 신경망을 이용해 IP 주소와 잠재벡터를 학습하고 있습니다.
- 엔티티는 해시되고 내장되어 계층을 유지하며 해당 작업을 위해서는 충분한 크기의 해시가 필요합니다.
- 훈련하는 동안 엔티티와 IP를 임의로 엮어서 자동으로 부정적인 샘플을 생성합니다.
IP Insights에 중요한 하이퍼 파라미터들
- Num_entitiy_vectors
- 해시 사이즈
- 엔티티 식별자의 수를 두 배로 설정하라고 권장되어있습니다.
- Vector_dim
- 임베딩 벡터의 사이즈
- 너무 크면 과적합될 수 있습니다(데이터 캡쳐 용량이 늘어나 훈련 데이터의 노이즈와 특이성을 포착할 수 있습니다.
- Epochs, Learning rate, batch size...
IP Insights의 인스턴스 타입
- CPU or GPU
- GPU가 추천되며 한 가지 머신에서 여러 GPU를 사용할 수 있습니다.
- CPU의 사이즈는 vector_dim과 num_entitiy_vectors 크기에 따라 결정됩니다.
Reinforcement Learning(강화 학습)

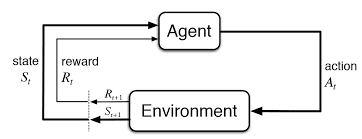
에이전트가 환경에서 행동을 취함으로써 목표를 달성하려고 할 때 어떻게 결정을 내려야 하는지를 배우는 머신러닝 패러다임의 한 유형입니다. 지도 학습이 정답이 미리 주어진 상태에서 모델을 훈련시키는 것과는 달리, 강화 학습은 시행착오를 통해 에이전트가 자신의 행동의 결과로부터 배우게 됩니다.시간에 따라 무작위로 공간을 탐색하면서 가장 효율적으로 탐색할 수 있는 모델을 만드는 것입니다.한 번 학습하면 배포되고 실행되는건 매우 빠릅니다.공급망 관리, 공조 설비 시스템, 자율 주행 차량까지 거대한 세상 속에 있는 하나의 에이전트입니다.
- 에이전트(Agent): 학습자 또는 결정자로, 환경과 상호작용합니다.
- 환경(Environment): 에이전트가 움직이는 세계로, 에이전트의 행동에 따라 특정한 상태와 보상을 제공합니다.
- 상태(State): 환경에 의해 반환된 현재 상황의 표현입니다.
- 행동(Action): 에이전트가 취할 수 있는 모든 가능한 움직임입니다.
- 보상(Reward): 환경으로부터의 피드백 신호입니다. 에이전트의 행동을 장려하거나 억제하기 위해 즉각적으로 주어지는 반환값입니다.
- 정책(Policy): 에이전트가 현재 상태에 따라 다음 행동을 결정하기 위해 사용하는 전략입니다.
- 가치 함수(Value Function): 특정 정책에 따라 특정 상태에서 시작한 에이전트에 대한 기대되는 반환(보상)을 예측합니다.
- Q-값 또는 행동-가치 함수(Q-Value or Action-Value Function): 주어진 상태에서 특정 행동을 취하고 이후 특정 정책을 따랐을 때의 기대되는 반환을 예측합니다.
Q-Learning
강화학습을 구체적을 구현한 것을 Q러닝이라고 합니다.
주어진 행동에 따라 Q가 값을 가질 수도 있습니다. Q는 0으로 시작해서 액션을 취하고 보상과 변화를 통해 최종적으로 가장 높은 Q값을 가지는 것이 목적입니다. 경험을 통해 Q값을 증폭시킬 수 있고 이어진 행동을 향상시키는 하나의 방식입니다.
강화학습의 문제점
- 탐사, 훈련 단계에서 효율적으로 만들 수 있는 방법
- 항상 가장 높은 Q값을 위해 행동하도록 설정할 수 있습니다.
- 만약 동률이 발생한다면 랜덤 값을 선택하여 움직입니다.
- 가장 단순한 방법이지만 매우 비효율적으로 사용됩니다.
- 탐사를 하면서 무작위로 변화를 주는 것입니다.
- 앱실론 용어라고 불리며 주사위를 굴려 임의로 정한 값보다 낮다면 가장 높은 Q값을 따르지않고 움직입니다.
- 훨씬 더 광범위한 가능성을 탐구할 수 있습니다.
- 항상 가장 높은 Q값을 위해 행동하도록 설정할 수 있습니다.
용어
- Markov Decision Process(MDP)
- 모델링 의사 결정을 위한 수학적 프레임워크입니다.
- 컨셉 자체는 앞선 강화학습과 동일하며 쉽게 의사 결정 과정을 정형화하고, 확률적인 결과와 다양한 상황에서의 최적의 결정을 찾는 데 있어 강력한 프레임워크를 제공한다고 이해할 수 있습니다.
다양한 움직임을 주는 방식으로 각 상황에 따라서 행동에 따라 보상이나 패널티를 추적합니다.
Reinforcement Learning in SageMaker
- 딥러닝 프레임워크 Tensorflow와 MXNet에서 지원합니다.
- 다양한 도구 키트도 지원합니다.
- 커스텀, 오픈소스, 기타 여러 환경을 지원합니다.
- Amazon Sumerian, AWS RoboMaker
- 탐구와 훈련 단계를 여러 머신에 분배할 수 있고, 환경 롤아웃도 배포할 수 있습니다.
- 멀티코어, 멀티 인스턴스 모두 가능합니다.
Reinforcement Learning의 하이퍼 파라미터
강화 학습을 위한 하이퍼파라미터 설정은 없지만 원하면 직접 만들 수 있습니다.
Reinforcement Learning의 인스턴스 타입
어떤 인스턴스를 사용해야하는지 지침은 없습니다.Tensorflow 혹은 MXNet같은 프레임워크에 기초하고 있습니다. 일반적으로 다중 인스턴스와 다중 코어를 지원되기 때문에 GPU가 일반적으로 도움이 됩니다.
Automatic Model Tuning
자동으로 하이퍼파라미터를 튜닝하는 것으로 몇 가지에 대한 지침이 있지만, 일부는 지역 최소량을 찾는데 적합하지 않습니다.복잡한 시스템이라 여러 가지 방법을 시도해보고 가장 효과적인 방법을 찾는게 중요한데, 안에서 무슨 일이 벌어지는지 정확히 알 수 없다는 점이 많이 어려운 부분입니다.네트워크를 추가하면 추가할수록 문제는 기하급수적으로 커지며 모든 값들을 시도하고 훈련하고 평가하는데 비용이 정말 많이 소모됩니다.이 부분을 세이지메이커에서 도움을 줄 수 있으며 중요한 하이퍼파리미터와 하이퍼 파라미터에서 시도하고 싶은 값의 범위, 최적화하려는 메트릭만 정의하면 됩니다. 하이퍼파라미터 튜닝 작업을 해서 가능한 많은 조합을 훈련할 수 있고 비용을 통제하고, 얼마나 많은 훈련을 거쳐야하는지 상위에서 바인딩할 수 있습니다.이를 통해 가능한 훈련인스턴스를 병렬적으로 훈련할 수 있고 다양한 조합의 매개변수를 훑어볼 수 있습니다.
동시에 시간이 지나룻록 튜닝시키는 모델도 학습하여 더 긍정적인 방향으로 더 똑똑하게 테스트할 수 있습니다.모든 매개변수를 테스트하지 않고 어떤게 가장 합리적인지 알아보기 위한 학습이며 튜닝에 필요한 많은 리소스를 절약할 수 있습니다.
Automatic Model Tuning: Best Practices
- 한 번에 너무 많은 하이퍼파라미터를 최적화하지 않는게 중요합니다.
- 모델의 정확도에 영향을 줄 부분들만 집중하는게 중요합니다.
- 범위를 가능한 작게 유지하는게 중요합니다.
- 필요시 로그의 비율을 사용하여 스케일을 조정하는게 중요합니다.
- 너무 많은 훈련을 동시에 진행하지 않는게 중요합니다.
- 동시에 배우면 훈련이 잘 진행되지 않습니다. 따라서 한 번에 한 두가지 트레이닝을 하는 것이 효율적입니다.
- 매개 변수 튜닝과 동시에 너무 많은 트레이닝은 학습하는데 한계를 볼 수 있기 때문에 하이퍼파라미터 튜닝 효율성이 중요합니다.
- 훈련 작업이 여러 인스턴스에 걸쳐 실행된다면 최종 결과로부터 정확하고 객관적인지 신경을 써야합니다.
- 트레이닝 작업 코드를 작성하는게 조금 까다로울 수 있습니다.
- 튜닝 후 모든 인스턴스가 합쳐졌을 때 하이퍼파리미터 튜닝에서 최적화 보고를 잘 확인해야합니다.
중요한건 과도하지 않게 설정해야하고 학습은 순차적으로 진행된다는 것을 잘 인지하고 있어야 합니다.
SageMaker and Spark
Apache Spark는 전처리 데이터 프레임워크로 유명하며, 머신 러닝도 대규모로 수행할 수 있습니다. MLlib도 많이 구축되어 있어, 여러 면에서 SageMaker와 비슷하지만 사전 처리에서는 그 이상의 작업도 할 수 있습니다.기본적으로 데이터를 데이터 프레임에 로드하고 프레임의 프로세싱을 여러 곳으로 분산시킬 수 있습니다.AWS가 제공하는 SageMaker-Spark Library를 통해 스파크 드라이버 스크립트 내에서 SageMaker를 사용할 수 있게 해줍니다.Spark 작업이 완료되면 Spark의 데이터 프레임 객체를 얻게 됩니다.사전에 처리된 모든 데이터를 담고있으며, 이후 Spark의 MLlib 대신 SageMakerEstimator를 사용할 수 있습니다.SageMaker 내부의 인기있는 알고리즘을 사용할 수 있습니다(K-Means, PCA, XGBoost)SageMaker 안에서 ML 인스턴스를 만들어 최종 단계를 수행할 수 있습니다.
SageMaker와 Spark간 통합
- 훈련된 데이터 프레임은 두 배의 벡터와 두 배의 정밀도를 가진 features column으로 이루어져야합니다.
- 만들어진 데이터 프레임을 SageMakerEstimator를 만들어 맞추면 SageMaker 모델을 얻을 수 있습니다.
- SageMaker 모델에서 Transform을 호출해 훈련된 모델을 추론할 수 있습니다.
- 스파크 파이프라인과도 작동합니다.
왜 SageMaker와 Spark를 통합하는지?
- 사전 처리 능력과 빅데이터셋을 처리하는 스파크를 사용해 SageMaker의 훈련과 예측을 끌어올릴 수 있습니다.
- Spark도 대규모의 머신 러닝이 가능하지만 AWS 리소스가 있다면 SageMaker의 여러 Autotomatic Tuning 등의 기능을 활용하는 것이 좋습니다.
New SageMaker Features(2020년 이후)
SageMaker는 IDE, SageMaker Studio로 구축하며 많은 기능을 추가해왔습니다.
SageMaker Studio
VIsual IDE나 머신러닝을 위한 통합 개발 환경을 제공합니다. 노트를 그룹간 공유할 수 있으며 하드웨어 구성으로 전환할 수도 있습니다. → 관리할 인프라가 없기 때문입니다.모델간 비교하고 최선의 모델을 알아낼 수 있으며 SageMaker 작업을 통해 결과를 시각화하고 해석할 수 있습니다.
SageMaker Debugger
주기적인 간격으로 내부 모델 상태를 저장해 훈련 중 무슨 일이 벌어지는지 볼 수 있습니다.모델이 훈련 받으면서 긴 시간동안 개별적인 Gradients와 tensors를 저장해서 훈련이 진행됨에 따라 결과를 확인할 수 있습니다.훈련 중 원치않는 상황을 감지하는 규칙이 있으며, 규칙에 걸리면 자동으로 경보가 발령됩니다. 이후 규칙에 대한 디버그 작업이 개별적으로 실행되어 알람을 받을 수 있게됩니다.SageMaker Studio Debugger Dashboard가 있어 모든 걸 시각적 환경에서 확인할 수 있습니다.자동으로 훈련 리포트틑 생성할 수 있으며, 체크박스를 통해 훈련 중 발생한 일들을 확인할 수 있습니다.SageMaker에는 훈련 과정동안 일어난 일에 대해 알 수 있도록 몇 가지 규칙이 내장되어 있습니다.
- 병목현상 모니터링 시스템이 있습니다.
- Tensorflow같은 모델 프레임워크 연산을 프로파일링이 가능합니다.
- 모델 파라미터를 디버그 할 수 있습니다.
지원하는 프레임워크와 알고리즘
- Tensorflow
- PyTorch
- MXNet
- XGBoost
- SageMaker generic estimator(커스텀한 훈련된 컨테이너를 사용합니다.)
Github에서 디버거를 위한 API도 존재합니다.
- CreateTraining Job과 DescribeTrainingJob API에서 자신만의 후크와 규칙을 만들 수 있습니다.
- SMDebug를 통해 클라이언트에서 훈련된 데이터를 SageMaker Debugger로 전달하여 분석과 처리를 할 수 있게 됩니다. → SMDebug = 사용자의 트레이닝 코드와 SageMaker Debugger를 통합하는 클라이언트 라이브러리의 이름
SageMaker Debugger 특징
- SageMaker Debugger Insight Dashboard를 통해 모든 걸 그래픽으로 확인하여 훈련 과정 중 무슨 일이 벌어지는지 알 수 있습니다.
- Debugger를 위한 구체적인 프로파일러 규칙이 있습니다.
- ProfilerReport → 대시보드에 있는 프로파일링 리포트를 시작하는 역할
- Hardware system metrics(CPU 병목, GPU 메모리 증가량...)
- Framework Metrics(최대 초기화 시간, 전체 프레임워크 메트릭스, StepOutlier)
- 하이퍼 파라미터로 간주됩니다.
- Built-in actions → 디버거 이벤트에 반응
- StopTraining(훈련 종료하는 트라거), Email 혹은 SMS 알림
- 설정해놓은 Debugger Rule에 대한 반응 → 자동 훈련 중단 혹은 알림
SageMaker Autopilot
데이터에 근거해 예측을 하기 위한 적절한 모델과 알고리즘을 자동으로 찾아내는 역할을 합니다.동시에 알고리즘 선택과 데이터 사전 처리 모델 조율과 관련된 모든 인프라가 함께 작동해서 정말 쉽게 모델을 구축할 수 있습니다. 하이퍼 파라미터 튜닝부터 다양한 모델 유형으로 실험하면서 자동으로 최적의 결과가 나옵니다.
Autopilot workflow
- 트레이닝을 위해 데이터를 s3로 로드합니다.
- 컬럼을 선택하면 자동으로 모델 생성이 시작됩니다.
- 모델 노트북을 통해 시각화와 컨트롤이 가능해집니다.
- 모델을 동작하고 leaderboard를 통해 추천 모델 리스트 중 하나를 선택할 수 있습니다.
- 모델을 배포하고 모니터링할 수 있으며, 노트북을 통해 모델을 최적화할 수 있습니다.
Autopilot의 추가적인 특징
- 프로세스에 인간의 지도를 추가할 수 있습니다.
- 모든걸 자동으로 맡길지 사람이 조절할지를 선택할 수 있습니다.
- 코드없이 동작할 수 있고 필요시 SDK를 통해 코드를 추가할 수 있습니다.
- 3가지의 주요 유형이 있습니다.
- 이진 분류
- 다중클래스 분류
- 회귀
- 알고리즘 타입
- Linear Learner
- XGBoost
- Deep Learning(MLP’s, Multi-Layer Perceptron)
- Ensemble mode
- 모든 알고리즘을 자동으로 혼합하여 최상의 결과를 도출하는 알아내도록 합니다.
- 데이터는 tabular CSV 혹은 Parquet 형식이 가능합니다
Autopilot Explainability
훈련 데이터에 관한 최적의 모델을 만든다고 한들 훈련 데이터에 어떤 편향이 존재하는지 알 수 없습니다.따라서 해당 모델이 뭘 하는지 이해하는게 중요하고 감사 문제가 있을 수도 있습니다.
- SageMaker Cloudify와 통합되어 다양한 특징이 어떻게 예측에 기여했는지 표시됩니다.
- 어떠한 특징에 기반한 편견이 존재하는지도 표시됩니다.
이러한 점은 AutoML의 문제점으로 제한이나 생각없이 모델을 마구 만들어내면 이러한 편견이 발생할 수 있습니다.이러한 문제를 해결하기 위해 다음과 같은 Feature attribution을 사용합니다.
- SHAP 베이스라인 → 각 특징의 예측값에 대해 중요한 값을 할당합니다.
- 최종 예측에 어떤 기능이 가장 큰 역할을 했는지 알아내는 방법입니다.
- 인간적인 지식을 통해 편향을 확인하고 다시 돌아가서 정리하거나 해결해야합니다.
SageMaker Model Monitor
배포된 모델의 품질 편차에 대해 자동적으로 경고를 받을 수 있습니다.한 번 배포하고 시간이 흐르며 데이터의 속성의 품질이 떨어질 수 있습니다.
- CloudWatch로 동작하기 때문에 상황이 바뀌면 자동으로 알림을 받을 수 있습니다.
- 데이터 드리프트라는 시각화 도구를 통해 시간에 따라 모델 변화를 모니터링 할 수 있습니다.
- 데이터에서 새로운 이상 현상이나 예외가 발생하면 Model Monitor를 설정해 새로운 걸 자동으로 보고하게 됩니다.
- 이전에 보지 못했던 새로운 기능을 확인할 수 있습니다.
- 코드는 필요없이, SageMaker Studio 혹은 웹 기반 대시보드로 설정할 수 있습니다.
Model Monitor + Clarify
Model Monitor는 배포된 모델의 지속적인 성능 및 데이터 품질 모니터링을 위해 설계되었으며 Clarify는 모델 배포 전후의 편향 탐지 및 모델 설명 가능성에 중점을 둡니다.
- Model Monitor 는 새로운 데이터가 발견될 때 모델이 시간이 지나도 계속해서 잘 작동하는지 확인해야 할 때 사용(모니터링)됩니다. Clarify는 데이터와 모델의 편향을 이해하고, 문서화하고, 완화해야 할 뿐만 아니라 투명성을 위해 모델의 예측을 설명해야 할 때 사용(분석)됩니다.
Model Monitor 특징
- S3에 데이터를 안전하게 보관합니다.
- 지속적으로 확인하기 위해선 모니터링 스케줄을 설정해야하며 추가적인 배포가 필요합니다.
- CloudWatch 알람과 연동해 모델을 감사하거나 시정 조치를 할 수 있습니다.
- Tensorboard, Quicksight, Tableau 혹은 SageMaker Studio에서 통합할 수 있습니다.
- 모니터링 타입
- 데이터 품질
- 표준 편차, 최소화, 최대화 등 Feature에 대한 통계적 속성입니다.
- 모델 모니터 작업시 만든 기준선과 관련되어 있습니다.
- 모델 품질
- 정확도, RMSC, 정밀도, 민감도 등이 있습니다. 해당 품질과 너무 벗어나면 경고를 생성할 수 있습니다.
- Ground Truth 라벨과 통합해 사람들이 데이터를 어떻게 분류하는지 확인할 수 있습니다.
- Bias(편향) 드리프트
- Feature 데이터에서 새로운 편향이 있었는지 발견할 수 있습니다.
- Feature attribution drift
- NDCG 점수에 근거하여 훈련과 실제 데이터의 Feature 순위를 비교해보고 어떤 Feature가 중요한지를 확인할 수 있습니다.
- 데이터 품질
Feature data & attribution
data
시간이 지남에 따라 모델이 수신하는 입력 데이터(특성) 분포의 변화를 나타냅니다. 이는 특히 모델의 입력 기능에 초점을 맞춘 데이터 드리프트 유형입니다. 이는 사용자 행동의 변화, 계절적 변화, 모델이 예측하는 데이터에 영향을 미치는 외부 환경의 변화 등 다양한 요인으로 인해 발생할 수 있습니다.attribute시간이 지남에 따라 다양한 특성이 모델 예측에 기여하는 방식의 변화와 관련이 있습니다. 전체 데이터 분포는 동일하게 유지(또는 변경)될 수 있지만 예측을 수행하는 데 있어 개별 기능의 중요성이나 가중치는 바뀔 수 있습니다. 이 개념은 모델 해석 가능성 및 기계 학습 모델의 설명 가능성 측면과 밀접한 관련이 있습니다.
Deployment Safeguards
배포 가드레일로 비동기성이나 실시간 예측 엔드포인트에 배포할 수 있습니다.비동기성이기 때문에 응답이 돌아오는 걸 기다리지않고 다른 작업을 계속 진행합니다.동시에 트래픽을 새 모델로 제어할 수 있습니다. 단순히 배치하는게 아니라 블루/그린 방식의 배포 모델을 적용할 수 있습니다
- All at once
- Canary
- Linear
자동 롤백을 지원하여 이전 모델로 자동으로 롤백할 수 있습니다.Shadow Test를 통해 성능을 비교할 수 있습니다.
- shadow variant를 통해 프로덕션 환경의 퍼포먼스를 비교할 수 있습니다.
- SageMaker 콘솔을 통해 모니터링 하고 언제 수정할지 결정할 수 있습니다.
SageMaker Canvas
- 단순한 엔지니어링 용 도구가 아닌 머신러닝 작업이 가능한 BI 전용 도구 입니다.
- 모델을 훈련하고 싶은 데이터(CSV 포맷)를 업로드하기만 하면 알아서 분석과 예측을 실행합니다.
- 예측하고자하는 라벨이 포함된 행을 알려주고 버튼 한번으로 모델을 만들면 모든게 자동으로 처리됩니다.
- 자동으로 누락된 값과 아웃라이어를 처리하고 중복된 값을 처리합니다.
- 현재는 분류와 회귀만 다루고 있습니다. → 실제 메커니즘과 모델은 자동으로 선택됩니다.
SageMaker 세부사항
- s3 버킷을 설치하여 적절한 CORS와 보호가 있어야 데이터를 s3에 보관할 수 있습니다.
- Okta SSO와 통합하여 사용자를 수동으로 설정하지않고도 로그인할 수 있습니다.
- Canvas 업데이트시 계속해서 수동으로 업데이터할 수 있습니다
- Redshift와 잘 통합되기도 합니다.
- 타임시리즈도 가능하지만 IAM 역할에 부착해서 VPC 안에서 실행할 수 있도록 설정할 수 있습니다.
- 트레이닝에 쓴 트레이닝 비, Cell이 많으면 많을수록 가격이 저렴해집니다.
- 머신러닝 엔지니어가 아니라, 머신러닝에 대해 잘 모르는 사람을 대상으로 합니다.
SageMaker Bias Metrics in Clarify
- 편향 훈련 데이터를 통해 편향 시스템을 만들 가능성을 아주 잘 인식하고 있습니다.
따라서 편견이 무엇인지 정의하는데 사용하는 다양한 측정 지표가 있습니다.
- Class Imbalance(CI)
- 클래스 불균형은 데이터셋 내에서 각 클래스의 데이터 양이 크게 다른 경우를 말합니다. 예를 들어, 희귀 질병을 예측하는 모델을 학습시킬 때, 질병이 없는 사람들의 데이터가 희귀 질병을 가진 사람들의 데이터보다 훨씬 많은 경우가 이에 해당합니다. 이로 인해, 모델은 다수의 클래스(질병이 없는 경우)를 예측하는 데 편향될 수 있으며, 소수의 클래스(희귀 질병)를 제대로 예측하지 못할 위험이 있습니다.
- Difference in Proportions of Labels(DPL)
- DPL은 데이터 라벨링에 있어서의 편향을 나타내는 지표입니다. 특정 그룹 간에 긍정적인 라벨(예: 대출 승인)의 비율이 다를 때 높은 DPL 값을 볼 수 있습니다. 예를 들어, 중년층과 다른 연령대의 사람들을 대상으로 대출 승인을 분류할 때, 중년층이 다른 연령대에 비해 대출 승인 비율이 높다면, 이는 DPL이 높다는 것을 의미합니다. 이런 경우 학습된 모델은 훈련 데이터에 있는 불균형을 미래의 예측에도 반영할 가능성이 있습니다.
- Kullback-Leibler Divergence(KL), Jensen-Shannon Divergence(JS)
- 양면의 분포가 얼마나 다른지가 관건입니다.
여러 집단의 실제 결과를 살펴보고, 각 집단에 대한 편견이 얼마나 심한지 확인할 수 있습니다.
- 양면의 분포가 얼마나 다른지가 관건입니다.
- Lp-norm (LP)
- 특성간의 거리를 측정하여 정규화를 통해 모델의 복잡도를 조절합니다.
- Total Variation Distance(TVD)
- L1-norm(정규화)을 통해 편향을 확인합니다.
- Kolmogorov-Smirnov(KS)
- 여러 측면에서 분포되는 결과의 최대 분포를 측정하는 것입니다.
이전에는 결과의 분포를 측정했지만 현재는 분배 결과를 측정하는 방식입니다.
- 여러 측면에서 분포되는 결과의 최대 분포를 측정하는 것입니다.
- Conditional Demographic Disparity(CDD)
- 상대적인 결과의 비율로 계산하고 CDD로 측정하여 편향을 측정합니다.
- 상대적인 결과의 비율로 계산하고 CDD로 측정하여 편향을 측정합니다.
내용 정리
- 클래스 불균형(CI): 데이터셋 내 클래스 간 데이터 양의 큰 차이로, 모델이 다수 클래스에 편향될 수 있습니다.
- 라벨의 비율 차이(DPL): 데이터 라벨링 과정에서 발생할 수 있는 편향으로, 특정 그룹 간 긍정적인 라벨의 비율 차이를 나타내는 것을 의미합니다.
CI와 DPL은 모두 모델 예측의 공정성과 정확성에 영향을 미칠 수 있는 편향 유형을 다루지만 데이터의 다양한 측면에 중점을 둡니다. CI는 클래스당 데이터의 양에 관한 것으로 잠재적으로 다수 클래스에 대한 선호로 이어질 수 있습니다. DPL은 데이터 내 여러 그룹에 긍정적 또는 부정적 결과가 어떻게 분포되어 있는지 조사하며, 이로 인해 특정 그룹에 대한 편향 또는 우호적인 예측 편향이 발생할 수 있습니다.
SageMaker Training compiler
훈련 단계에서 트레이닝 컴파일러가 모델들을 위해 동작합니다.AWS 딥러닝 컨테이너 DLC에 통합된 것으로 DLC가 아니면 사용할 수 없습니다.Training Job을 컴파일하고 최적화합니다. 특히 GPU 인스턴스에서 50%까지 빨라질 수 있지만 한도를 제대로 설정하지 않으면 오히려 해가 될 수 있습니다.단순한 자동적인 솔루션이 아닙니다.특정 라이브러리를 사용할 경우 트레이닝 컴파일러가 잘 동작할 수 있습니다.자신의 모델을 가져와서 사용할 경우 결과를 장담할 수 없습니다. → 호환되지 않을 수 있습니다.
- GPU 인스턴스를 사용할 것(ml.p3, ml.p4)
- PyTorch 모델을 사용할 경우 PyTorch / XLA 모델의 저장 기능을 사용할 수 있습니다.
- 훈련 컴파일러에 필요한 정보를 저장하기 위해 저장기능이 필요합니다.
- 훈련 중에 디버그 해야한다면 디버그 플래그를 활용해야합니다.
SageMaker Feature Store
기능은 행에 대한 레이블을 예측하기 위해 정보들을 사용하는 열이나 필드입니다.사람의 주소, 소득, 나이 등 단순히 머신러닝 모델을 훈련시키기 위한 속성입니다.머신 러닝 모델은 훈련을 위해 아주 많은 양의 데이터를 빠르게 흡수해야합니다.데이터를 정돈하고 다른 모델에 걸쳐 이러한 feature를 공유하는 것도 어려운 일이며, 빠르게 읽고 쓰기 위해선 여러 번 저장하는 상황을 피해야합니다.feature는 일종의 EMR 파이프라인이나 Glue, SageMaker 프로세싱에서 나올 수 있습니다.
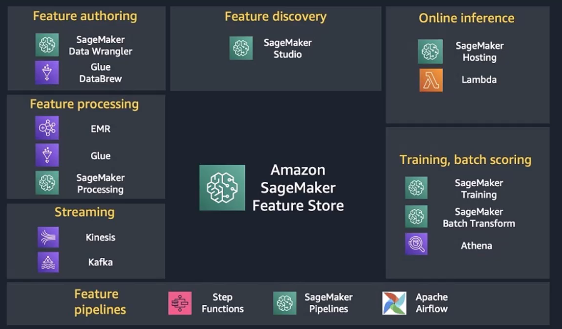
Feature Store은 어떻게 데이터를 구성하는지
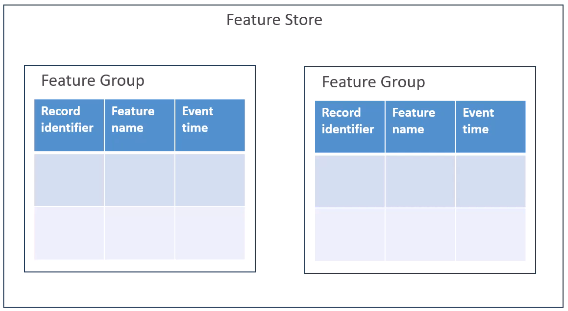
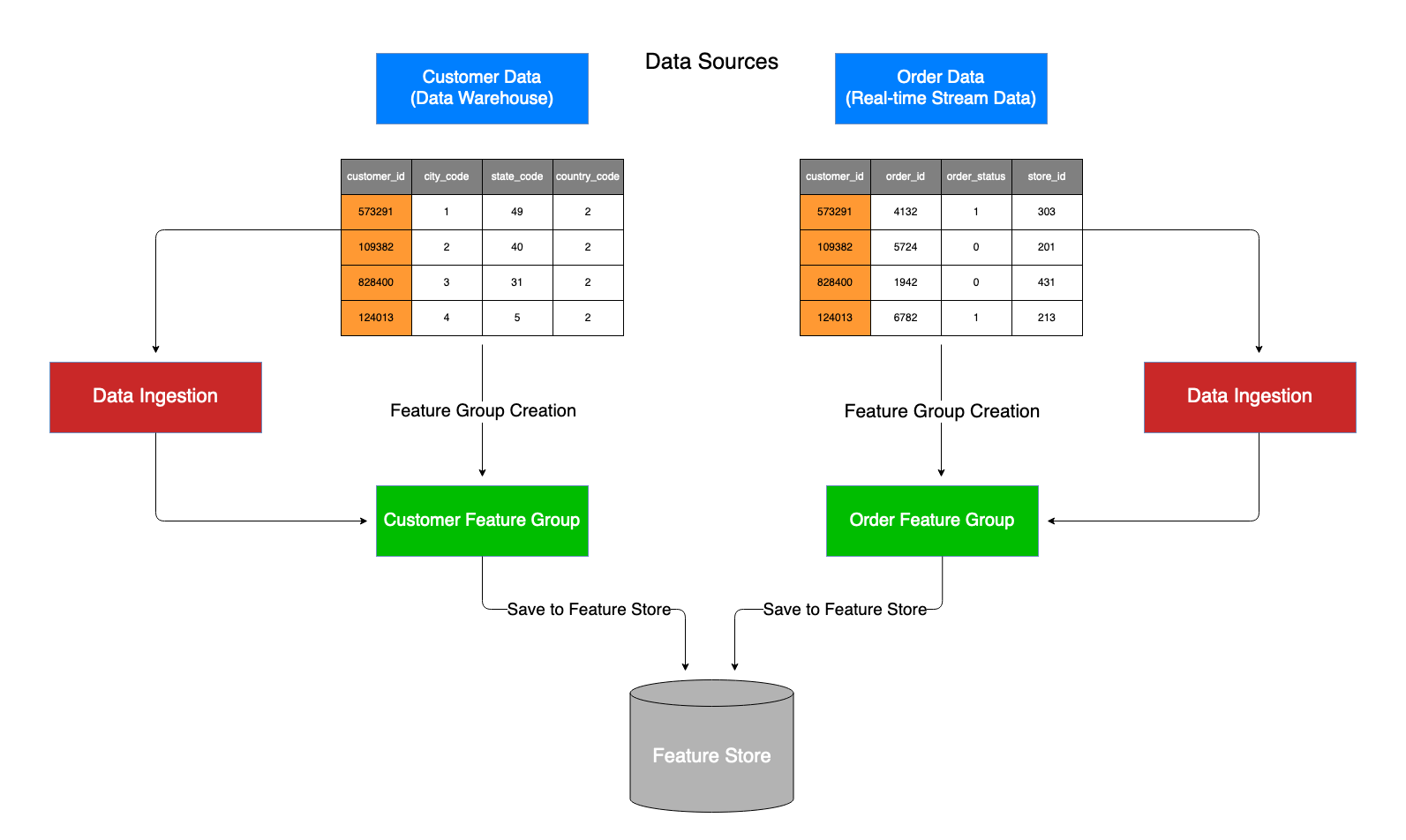
Feature 스토어가 있고, 그 안에 Feature 그룹이라는 것들이 있는데 Feature들을 함께 구성합니다.각 Feature 그룹은 기록 식별자(Record identifier)와 해당 기능과 관련된 이름, Event Time 등의 정보를 구성하고 있습니다.
동작 방식
기본적으로 스트리밍 방식과 배치 방식이 있습니다.배치 엑세스를 원한다면 오프라인 스토어를 사용하면 되며, 데이터로 원하는 많은 것들을 할 수 있습니다.
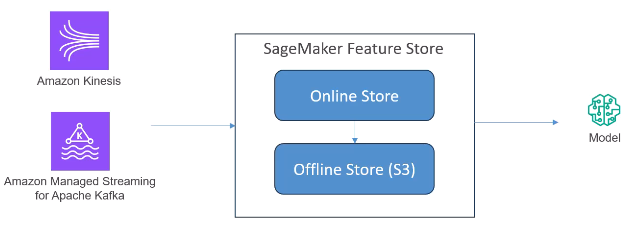
Feature Store Security
- 모든 것은 암호화되어 이동합니다.
- 접근 제어는 IAM을 통해 가능합니다.
- PrivateLink를 이용해서 아무도 접근하지 못하게 할 수 있습니다.
SageMaker ML Lineage Tracking
- 머신 러닝 워크플로를 자동으로 생성하고 저장합니다.
- MLOps로 불리며 모든 파이프라인과 프로세스를 광범위하게 추적하는 분야입니다.
- 자동적으로 모델의 실행 기록을 저장해 감사와 규정 준수 목적으로 사용합니다.
- 자동, 혹은 메뉴얼을 만들어 개체를 트레킹할 수 있습니다.
- Resource Access Manager를 사용해 계정 간 계보 추적을 할 수 있습니다.
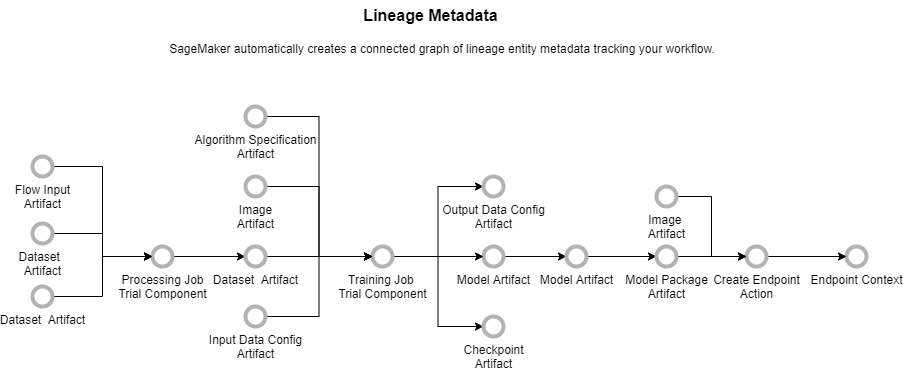
Lineage Tracking Entities(추적할 수 있는 개체)
- Trial component(전처리작업, 훈련작업, 변환작업)
- 모델 구성 요소를 조합하여 시험할 수도 있습니다.
- 특정 유스케이스에 대한 집단 실험도 할 수 있습니다.
- 컨텍스트(논리적으로 그룹핑된 개체)
- Action(workflow step, model deployment)
- Artifact(객체나 데이터, s3 버킷에 저장된 모델 혹은 ECR 이미지)
- Association(개체간의 연결)
Querying Lineage Entities
- Python에서 할 수 있는 LineageQuery API가 있습니다.
- Python용 SageMaker SDK의 일부입니다.
- 모든 모델, 엔드포인트, Artifact를 찾을 수 있습니다.
- 시각화도 가능하며 외부 시각화 도구가 필요합니다.
SageMaker Data Wrangler
데이터엔지니어링에 적용가능한 기술입니다.
- 기본적으로 SageMaker Studio에 포함된 ETL 파이프라인입니다.
- Glue Data Studio와 공통점이 많습니다. 머신 러닝의 데이터 준비를 위해 구성되었습니다.
- 어디서든 데이터를 가져올 수 있습니다.
- 시각화하고 데이터 분포가 괜찮은지 푸시하기 전에 발생할 수 있는 아웃라이어를 알게 할 수 있습니다.
- 데이터를 변환할 수 있습니다.
- 300개 이상의 변환 방식이 있으며 원한다면 Pandas, PySpark 등으로 직접 변형할 수 있습니다.
- Quick Model을 통해 데이터를 준비하려는 모델을 훈련시키고 결과를 신속히 측정합니다.
- 입력하는 모델에 맞춰 데이터를 준비해서 바로 넣고 결과를 측정 가능합니다.
Data Wrangler sources
다양한 데이터 소스로부터 데이터를 흡수해서 Data Wrangler 파이프라인을 통해 변환하고 SageMaker와 통신합니다.
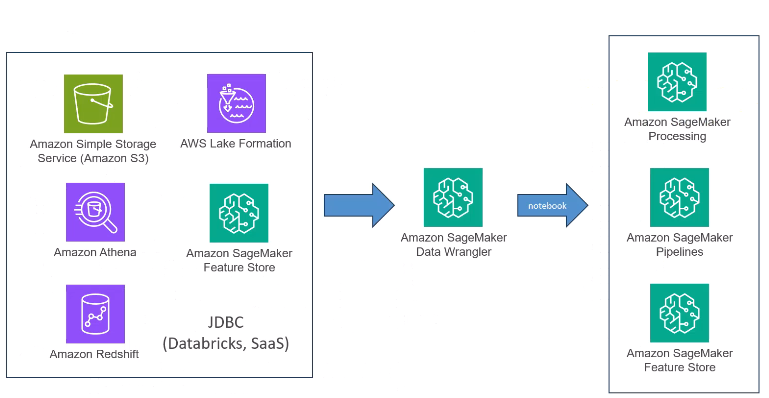
Data Wrangler는 파이프라인에서 변환을 하는게 아니라 변환을 하기 위해 코드만 생성합니다.단순한 코드 생성 도구로 생각할 수 있으며, 코드는 데이터를 보내는 곳에 자신의 Endpoint를 생성하고 SageMaker에서 가져와 모델을 훈련하는 방식입니다.https://aws.amazon.com/ko/blogs/korea/introducing-amazon-sagemaker-data-wrangler-a-visual-interface-to-prepare-data-for-machine-learning/
데이터를 어떻게 변환하고 모델에 어떻게 제시하느냐에 대한 선택은 모델의 품질에 큰 차이를 가져올 수 있으며, 데이터를 정규화하는 것도 아주 중요합니다.QuickModel을 통해 데이터를 변형하고 테스트할 수 있습니다. 중요한건 Data Wrangler는 파이프라인 그 자체에 있지않고, 파이프라인으로 가는 코드를 생성합니다.
Data Wrangler Troubleshooting
- SageMaker Studio 사용자가 Data Wrangler를 위한 적절한 IAM을 설정해야 합니다.
- Data Wrangler가 엑세스할 수 있도록 데이터 소스를 확인해야 합니다.
- ec2 인스턴스 제한이 있다면 할당량 증가가 필요할 수도 있습니다.
- quota 증가