[AI/ML] Qwen3-VL-4B 강화 학습(RL) 기반 파인튜닝(Unsloth) 가이드
GRPO를 활용해 Qwen3-VL을 강화학습으로 파인튜닝하는 실전 가이드. Unsloth와 TRL로 수학 문제 해결 능력을 향상시키는 방법과 보상함수 설계법을 제시합니다.
![[AI/ML] Qwen3-VL-4B 강화 학습(RL) 기반 파인튜닝(Unsloth) 가이드](https://images.unsplash.com/photo-1498457349504-289ee698e52c?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDZ8fFJlaW5mb3JjZW1lbnR8ZW58MHx8fHwxNzcwMTE3OTE4fDA&ixlib=rb-4.1.0&q=80&w=1200)
개요
Unsloth를 참고하여 Reinforcement Learning을 정리했습니다.
OpenAI(RLHF), Anthropic(RLAIF), DeepSeek(GRPO), Meta(DPO), Google(RLHF) 등 선도 기업들이 RL 방식을 사용하며 LLM 파인튜닝의 표준으로 자리잡았습니다.
이 글에서는 RL을 통한 파인튜닝 방식을 살펴보고, Unsloth와 TRL의 GRPO를 활용하여 Qwen3-VL 모델을 직접 테스트했습니다.
강화 학습이란?

강화 학습은 시행착오를 통해 에이전트가 자신의 행동의 결과로부터 배우게 됩니다. 정답이 미리 주어진 상태에서 모델을 훈련시키는 것과 달리 시간에 따라 무작위로 공간을 탐색하면서 가장 효율적으로 탐색할 수 있는 모델을 만드는 것입니다.
강화학습은 머신러닝부터 사용되었던 유명한 방식입니다. 팩맨 게임으로 예를 들면
- 상태: 팩맨 위치, 귀신 위치, 남은 구슬
- 행동: 상하좌우 이동
- 보상: 구슬 획득 +10, 귀신에게 잡힘 -500
처음엔 무작위로 움직이다 금방 잡힙니다. 하지만 수천 번 반복하면서 "귀신이 가까우면 피하고, 안전할 때 구슬을 먹는다"는 전략을 스스로 터득합니다.
SFT(Supervised Fine-Tuning)만으로는 모델이 "정답을 맞추는 능력"을 직접 학습하지 못합니다. SFT는 주어진 예시를 모방하는 방식이라, 모델이 왜 그 답이 정답인지 이해하기보다 패턴을 따라가는 경향이 있습니다.
강화학습은 이 문제를 해결합니다. 모델이 생성한 응답에 Reward를 부여하고, 높은 Reward를 받는 방향으로 정책(policy)을 업데이트합니다. 수학 문제처럼 정답 여부가 명확한 태스크에서 특히 효과적입니다.
SFT 파인튜닝은 아래 문서를 참고해주세요.
RLHF, PPO부터 GRPO, RLVR까지 강화학습 발전
강화 학습은 다양한 방법으로 발전하고 있습니다.
RLHF (Reinforcement Learning from Human Feedback)
- OpenAI의 Thumbs Up & Down을 통한 사람의 피드백
- 보상 모델을 사람의 선호도 데이터로 학습
- ChatGPT, Claude 등 대부분의 상용 LLM이 사용
- https://en.wikipedia.org/wiki/Reinforcement_learning_from_human_feedback
PPO (Proximal Policy Optimization)
- Policy: 상태(State) → 행동(Action) 확률을 결정하는 규칙
- 4개의 모델 필요: 생성 정책 (학습 중), 참조 정책 (원본), 보상 모델 (품질 평가), 가치 모델 (baseline)
- 동작 과정
- 보상 모델이 응답 품질을 평가
- Advantage = 보상 - 가치 (평균 대비 얼마나 좋은가)
- Advantage 방향으로 생성 정책 업데이트
- 핵심
- 클리핑으로 정책 변화를 제한
- 참조 정책에서 너무 멀어지는 것을 방지
- https://unsloth.ai/blog/grpo
GRPO (Group Relative Policy Optimization)
- DeepSeek에서 제안, 가치 모델을 제거하고 보상 모델을 여러 번 호출한 통계로 대체
- 보상은 응답 전체에 적용, 정책 업데이트는 토큰 단위 확률 비율로 계산
- 토큰별 비율이 극단적으로 분산될 수 있음
- 업데이트 크기가 들쭉날쭉해서 학습이 안정적으로 수렴하지 못하는 경우 있음
- 데이터셋과 보상 함수에 따라 정확도를 크게 향상 가능
- Rubric 기반 여러 작은 보상 조합으로 구성 (OpenAI 파인튜닝 가이드)
- 올바른 형식 → +0.1
- 추론 과정 포함 → +0.2
- 최종 답 정확 → +0.5
- 보상 함수 설계 방법
- 규칙 기반 (JSON 유효성, 길이 검증)
- 실행 기반 (코드 테스트)
- LLM as Judge
- 하이브리드 (규칙 + LLM 기반 품질 검사)
RLVR (Reinforcement Learning with Verifiable Rewards)
- DeepSeek R1에서 사용, 가치 모델과 보상 모델을 모두 제거 → 검증 함수로 대체
- 코드와 수학 공식같이 정답이 존재하면 보상하는 규칙 기반 검증
- 한계: 정답이 주관적인 대화, 창작에서는 제한적
Unsloth RL 파인튜닝 테스트
Unsloth는 LLM 파인튜닝을 2배 빠르게, VRAM 70% 적게 사용하도록 최적화해주는 오픈소스 프레임워크입니다. Llama, Qwen, DeepSeek 등 다양한 모델의 LoRA/QLoRA 파인튜닝 효율화 기법과 RL/SFT같은 학습 방식을 지원합니다.
Qwen3-VL 모델을 활용해 GRPO 강화학습을 테스트합니다.
환경 설정
필요한 패키지를 설치합니다.
%%capture
!sudo pip install unsloth vllm
!sudo pip install "transformers>=4.51.0" "trl>=0.15.0" "peft>=0.15.0" "accelerate>=1.0.0"
!sudo pip install datasets bitsandbytes qwen-vl-utils
!sudo pip install --upgrade pillow
!sudo pip install boto3 python-dotenv wandb
GPU 설정 확인
import torch
print(f"PyTorch: {torch.__version__}")
print(f"CUDA: {torch.cuda.is_available()}")
if torch.cuda.is_available():
print(f"GPU: {torch.cuda.get_device_name(0)}")
print(f"VRAM: {torch.cuda.get_device_properties(0).total_memory / 1e9:.1f} GB")
------
PyTorch: 2.9.1+cu128
CUDA: True
GPU: NVIDIA L40S
VRAM: 47.7 GB
모델 로드
from unsloth import FastVisionModel
model, tokenizer = FastVisionModel.from_pretrained(
"unsloth/Qwen3-VL-4B-Instruct-unsloth-bnb-4bit",
max_seq_length=16384,
load_in_4bit=True,
fast_inference=False,
gpu_memory_utilization=0.8,
)
load_in_4bit: 모델 가중치를 4비트로 양자화(quantization)해서 메모리에 로드- VRAM이 부족한 경우 70~80% 절감 가능
LoRA 적용
다른 프레임워크에서 설정한 것 대비 훨씬 쉽게 옵션을 설정할 수 있습니다.
model = FastVisionModel.get_peft_model(
model,
finetune_vision_layers=False, # Vision encoder에 LoRA 적용 (VRAM↑)
finetune_language_layers=True, # Language model에 LoRA 적용
finetune_attention_modules=True, # Attention(q/k/v/o_proj)에 LoRA 적용
finetune_mlp_modules=True, # MLP(gate/up/down_proj)에 LoRA 적용
r=8, # LoRA rank: 학습 용량 (8~128)
lora_alpha=8, # 스케일링=alpha/r, 보통 r의 1~2배
lora_dropout=0, # 드롭아웃: 0=빠른학습, 0.05~0.1=과적합방지
bias="none", # bias 학습: "none", "all", "lora_only"
random_state=3407, # 재현성 시드
use_rslora=False, # RSLoRA: True면 sqrt(r)로 스케일링, 높은 rank에서 유리
loftq_config=None, # LoftQ: 양자화+LoRA 초기화 동시 수행
)
model.print_trainable_parameters()
전체 파라미터 개수 대비 학습할 파라미터 개수를 확인할 수 있습니다.
- 4B 모델이므로 약 4.5B
trainable params: 33,030,144 || all params: 4,470,845,952 || trainable%: 0.7388
Dataset 로드하기
VL 테스트를 위해 공식문서 데이터셋을 그대로 활용했습니다.
- MathVista는 수학 이미지 문제를 모은 벤치마크 데이터셋입니다.
- 차트, 그래프, 기하학 도형 등 다양한 시각적 요소가 포함된 수학 문제로 구성
from datasets import load_dataset
dataset = load_dataset("AI4Math/MathVista", split="testmini")
dataset = dataset.filter(lambda x: x["question_type"] == "free_form")
print(f"Dataset size: {len(dataset)}")
print(f"Columns: {dataset.column_names}")
print(f"\nSample:")
print(f" Question: {dataset[0]['question'][:100]}...")
print(f" Answer: {dataset[0]['answer']}")
데이터 사이즈와 예시 질문,응답 형식을 확인할 수 있습니다.
Dataset size: 460
Columns: ['pid', 'question', 'image', 'decoded_image', 'choices', 'unit', 'precision', 'answer', 'question_type', 'answer_type', 'metadata', 'query']
Sample:
Question: When a spring does work on an object, we cannot find the work by simply multiplying the spring force...
Answer: 1.2
GRPO 학습을 위한 프롬프트 포맷입니다.
image원본을PIL.Image로 변경해야합니다.
시스템 프롬프트에서 <reasoning>과 <answer> 태그를 사용하도록 유도합니다. 이 구조화된 출력 형식은 나중에 Reward 함수에서 활용됩니다.
이미지를 512x512로 리사이즈하는 이유는 메모리 효율성과 학습 안정성 때문입니다. 원본 해상도가 제각각이면 배치 처리가 어려워집니다.
SYSTEM_PROMPT = """You are a helpful math tutor. Analyze the image and solve the problem step by step.
Respond in the following format:
<reasoning>
Your step-by-step reasoning here
</reasoning>
<answer>
Your final answer here
</answer>"""
def resize_image(example):
image = example["decoded_image"]
image = image.resize((512, 512))
if image.mode != "RGB":
image = image.convert("RGB")
example["decoded_image"] = image
return example
def format_prompt(example):
prompt = [
{
"role": "user",
"content": [
{"type": "image"},
{"type": "text", "text": f"{SYSTEM_PROMPT}\n\n{example['question']}"},
],
},
]
return {
"prompt": prompt,
"answer": str(example["answer"]),
}
dataset = dataset.map(resize_image)
dataset = dataset.remove_columns("image")
dataset = dataset.rename_column("decoded_image", "image")
dataset = dataset.map(format_prompt)
dataset = dataset.map(
lambda example: {
"prompt": tokenizer.apply_chat_template(
example["prompt"],
tokenize=False,
add_generation_prompt=True,
)
}
)
dataset = dataset.select_columns(["prompt", "image", "answer"])
print(f"Formatted dataset size: {len(dataset)}")
print(f"Columns: {dataset.column_names}")
print(f"Image type: {type(dataset[0]['image'])}")
print(f"Sample prompt (first 200 chars): {dataset[0]['prompt'][:200]}...")
보상함수(Reward Function) 설정
GRPO에서 Reward 함수는 학습의 방향을 결정하는 핵심 요소입니다.
- 세 가지 Reward 함수를 조합하여 사용합니다.
- Correctness Reward → 정답 보상
- Format Reward → 형식 보상
- Length Penalty → 길이 페널티
import re
def extract_answer(text):
"""<answer> 태그에서 답 추출"""
match = re.search(r"<answer>\s*(.+?)\s*</answer>", text, re.DOTALL)
if match:
return match.group(1).strip()
return text.strip()
def correctness_reward(completions, answer, **kwargs):
"""
정답 보상: 정확히 맞으면 +2.0
"""
rewards = []
for completion in completions:
extracted = extract_answer(completion)
if extracted.lower() == str(answer).lower():
rewards.append(2.0)
elif str(answer).lower() in extracted.lower():
rewards.append(1.0)
else:
rewards.append(0.0)
return rewards
def format_reward(completions, **kwargs):
"""
포맷 보상: <reasoning>과 <answer> 태그 사용 여부
"""
rewards = []
for completion in completions:
reward = 0.0
if "<reasoning>" in completion and "</reasoning>" in completion:
reward += 0.5
if "<answer>" in completion and "</answer>" in completion:
reward += 0.5
rewards.append(reward)
return rewards
def length_penalty(completions, **kwargs):
"""
길이 페널티: 과도하게 짧거나 긴 응답
"""
rewards = []
for completion in completions:
length = len(completion)
if length < 50:
rewards.append(-1.0)
elif length > 2000:
rewards.append(-0.5)
else:
rewards.append(0.0)
return rewards
GRPO 설정
num_generations=2: 프롬프트당 2개 응답 생성, 상대적 Reward 차이로 학습loss_type="dr_grpo": length bias 문제 해결, 응답 길이에 독립적인 학습 (TRL v0.15.0+)importance_sampling_level="sequence": 시퀀스 단위 importance weight로 학습 안정성 향상optim="adamw_8bit": 8bit 옵티마이저로 메모리 절약max_grad_norm=0.1: 낮은 gradient clipping으로 VLM 학습 안정성 확보
from trl import GRPOConfig, GRPOTrainer
training_args = GRPOConfig(
output_dir="outputs",
num_generations=4, # 프롬프트당 생성 수 (그룹 크기). 권장: 4~8
max_prompt_length=1024, # 프롬프트 최대 토큰 (이미지+텍스트)
max_completion_length=1024, # 응답 최대 토큰. reasoning 포함시 1024+
per_device_train_batch_size=2, # GPU당 배치. VRAM 여유시 4까지 가능
gradient_accumulation_steps=2, # 그래디언트 누적. effective_batch = 2*4*2=16
learning_rate=5e-6, # GRPO 권장: 1e-6~5e-6 (SFT보다 낮게)
warmup_ratio=0.1, # 웜업 비율: 전체 스텝의 10%
lr_scheduler_type="cosine", # 코사인 감쇠: 부드러운 학습률 감소
weight_decay=0.1, # L2 정규화: 과적합 방지
max_grad_norm=0.1, # 그래디언트 클리핑 (DeepSeekMath 권장)
loss_type="dr_grpo", # Dr. GRPO: 분산 감소, 기본 GRPO보다 안정적
importance_sampling_level="sequence", # 시퀀스 레벨 중요도 샘플링
num_train_epochs=2, # 에폭 수. GRPO는 1~3이 일반적
logging_steps=5, # N 스텝마다 로그 출력
save_steps=100, # N 스텝마다 체크포인트 저장
bf16=True, # BF16 혼합 정밀도 (Ampere GPU 이상)
optim="adamw_8bit", # 8비트 AdamW: 옵티마이저 메모리 75%↓
seed=3407, # 재현성 시드
report_to="none", # 로깅: "wandb", "tensorboard", "none"
)
GRPO로 Training을 수행합니다.
trainer = GRPOTrainer(
model=model,
args=training_args,
train_dataset=dataset,
reward_funcs=[
correctness_reward,
format_reward,
length_penalty,
],
tokenizer=tokenizer,
)
trainer.train()

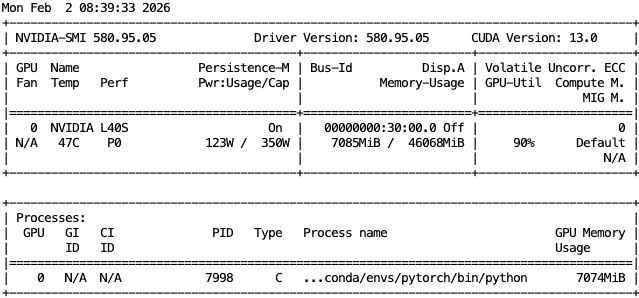
8 VRAM 내에서 안정적으로 수행되는 것을 확인했습니다.
추론 테스트
두 가지 모델 저장 방식이 있습니다.
- LoRA adapter: 용량이 작고(수십 MB), 나중에 다른 base 모델에도 적용 가능
- Merged model: base 모델 + LoRA가 병합된 전체 모델. 배포 시 추가 로딩 없이 바로 사용 가능
model.save_pretrained("outputs/lora_adapter")
tokenizer.save_pretrained("outputs/lora_adapter")
print("LoRA adapter saved!")
model.save_pretrained_merged(
"outputs/merged_model",
tokenizer,
save_method="merged_16bit",
)
from datasets import load_dataset
from qwen_vl_utils import process_vision_info
FastVisionModel.for_inference(model)
test_dataset = load_dataset("AI4Math/MathVista", split="testmini")
test_sample = test_dataset[0]
print(f"Question: {test_sample['question'][:200]}...")
print(f"Ground Truth: {test_sample['answer']}")
test_image = test_sample["decoded_image"]
if test_image.mode != "RGB":
test_image = test_image.convert("RGB")
messages = [
{
"role": "user",
"content": [
{"type": "image", "image": test_image},
{"type": "text", "text": f"{SYSTEM_PROMPT}\n\n{test_sample['question']}"},
],
},
]
text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
image_inputs, video_inputs = process_vision_info(messages)
inputs = tokenizer(
text=[text],
images=image_inputs,
videos=video_inputs,
padding=True,
return_tensors="pt",
).to(model.device)
with torch.no_grad():
outputs = model.generate(
**inputs,
max_new_tokens=512,
temperature=0.7,
do_sample=True,
)
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(f"\nModel Output:\n{response}")
Question: When a spring does work on an object, we cannot find the work by simply multiplying the spring force by the object's displacement. The reason is that there is no one value for the force-it changes. Ho…
Ground Truth: 1.2
Model Output:
user
You are a helpful math tutor. Analyze the image and solve the problem step by step.
Respond in the following format:
<reasoning>
Your step-by-step reasoning here
</reasoning>
<answer>
Your final answer here
</answer>
When a spring does work on an object, we cannot find the work by simply multiplying the spring force by the object's displacement. The reason is that there is no one value for the force-it changes. However, we can split the displacement up into an infinite number of tiny parts and then approximate the force in each as being constant. Integration sums the work done in all those parts. Here we use the generic result of the integration.
In Figure, a cumin canister of mass $m=0.40 \mathrm{~kg}$ slides across a horizontal frictionless counter with speed $v=0.50 \mathrm{~m} / \mathrm{s}$. It then runs into and compresses a spring of spring constant $k=750 \mathrm{~N} / \mathrm{m}$. When the canister is momentarily stopped by the spring, by what distance $d$ is the spring compressed?
assistant
<reasoning>
We are given a scenario where a mass m slides on a frictionless surface and compresses a spring. The spring force does negative work, reducing the kinetic energy of the mass until it stops. We are to find the compression distance d.
Since there is no friction, mechanical energy is conserved. The initial kinetic energy of the mass is converted entirely into the elastic potential energy stored in the spring at maximum compression.
The initial kinetic energy is:
KE = (1/2)mv²
The elastic potential energy stored in the spring when compressed by distance d is:
PE = (1/2)kd²
Setting the initial kinetic energy equal to the final spring potential energy (since the mass stops, its kinetic energy is zero):
(1/2)mv² = (1/2)kd²
We can cancel the 1/2 from both sides:
mv² = kd²
Solving for d:
d = √(mv² / k)
Now plug in the given values:
m = 0.40 kg
v = 0.50 m/s
k = 750 N/m
First calculate the numerator:
mv² = 0.40 × (0.50)² = 0.40 × 0.25 = 0.10
Then:
d = √(0.10 / 750) = √(0.0001333...) = √(1.333... × 10⁻⁴)
d ≈ √(1.333 × 10⁻⁴) = √(1.333) × 10⁻² ≈ 1.1547 × 10⁻² m
So, d ≈ 0.0115 m or 1.15 cm.
</reasoning>
<answer>
0.0115 m
</answer>
다음과 같은 방식으로 보상 함수가 설정되었을 때 훈련대로 출력되는 것을 확인했습니다.
<reasoning>태그 사용 → 성공 (+0.5)<answer>태그 사용 → 성공 (+0.5)- 단계별 추론 과정 → 에너지 보존 법칙 적용
- 물리 공식 정확성 → KE = PE 올바르게 적용
- 최종 답 정확도 → 정답 포함 (+2.0)
다음 단계
학습이 완료되면 평가와 튜닝을 반복하여 품질을 개선합니다. 이후 최종 모델을 배포합니다.
- 평가: MathVista 전체 테스트셋에서 정확도 측정
- 하이퍼파라미터 튜닝:
num_generations,learning_rate, Reward 가중치 조정 - 데이터셋 확장: 더 많은 수학 데이터셋 추가 (GSM8K, MATH 등)
- 1~4 반복…
- 배포: vLLM 또는 SageMaker Endpoint로 서빙
배포를 위해 S3에 모델을 저장합니다.
import os
S3_BUCKET = os.getenv("S3_BUCKET")
S3_PREFIX = os.getenv("S3_DATA_PREFIX", "rl-fine-tuning/models")
if S3_BUCKET:
!aws s3 sync outputs/lora_adapter s3://{S3_BUCKET}/{S3_PREFIX}/lora_adapter/
!aws s3 sync outputs/merged_model s3://{S3_BUCKET}/{S3_PREFIX}/merged_model/
print(f"Uploaded to s3://{S3_BUCKET}/{S3_PREFIX}/")
else:
print("S3_BUCKET not set, skipping upload")
![[AI/ML] Qwen3 VL 8B SFT LoRA Fine Tuning 가이드](https://images.unsplash.com/photo-1764477122486-5006de4bd62f?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDIwfHxtb2RlbCUyMHR1bmluZ3xlbnwwfHx8fDE3Njk4NDY4NDZ8MA&ixlib=rb-4.1.0&q=80&w=960)
![[SageMaker] SageMaker Jumpstart를 사용한 LLM Fine Tuning - DAFT(Domain-Agnostic Fine-Tuning)](https://images.unsplash.com/photo-1563207769-3343cb585fcb?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDZ8fHR1bmluZ3xlbnwwfHx8fDE3NTM4MzE2Mjl8MA&ixlib=rb-4.1.0&q=80&w=960)