[AI Agent] Prompt Engineering 리뷰(2주차)
Zero-shot, Few-shot, Chain-of-Thought, Self-Consistency 등 프롬프트 엔지니어링 기법을 순차적으로 적용하여 LLM 정답률을 개선하는 방법과, Reasoning 모델의 등장으로 달라진 프롬프트 설계 패러다임을 다룹니다.
![[AI Agent] Prompt Engineering 리뷰(2주차)](https://images.unsplash.com/photo-1704965021000-dab5ec30ac7e?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDN8fFByb21wdHxlbnwwfHx8fDE3NzQ2MTc0ODJ8MA&ixlib=rb-4.1.0&q=80&w=1200)
개요
2주차 과제는 프롬프트 엔지니어링 기법을 순차적으로 적용하면서 LLM의 정답률이 어떻게 개선되는지 직접 확인하는 과제였습니다. → 다만 생각보다 LLM의 성능이 좋아서 많은 분들이 Zero shot으로도 좋은 결과를 받으신 걸로 확인했습니다.
다만 의도는 의료급여 본인부담률이라는 복잡한 조건부 표 데이터를 이미지, 텍스트, HTML 등 형식으로 LLM에 제공하고, 다중 조건 추론(수급권자 종별, 나이, 질환 유무, 의료기관 종별)을 정확히 수행하도록 프롬프트를 개선해 나가는 것이 핵심입니다.
프롬프트 엔지니어링 핵심 기법 (Step 1)
1. Zero-shot Prompting
개념: 예시 없이 과제 지시만으로 모델이 응답을 생성하는 기법. Instruction Tuning + RLHF로 학습된 모델이 자연어 지시를 범용적으로 이해할 수 있기 때문에 작동합니다.
system_prompt = """아래는 의료급여 본인부담률 참조 데이터입니다.
질문에 대해 정확한 본인부담률을 답하세요. 답만 간결하게 작성하세요.
{copayment_reference}
"""
# user message에는 질문만 전달
| 장점 | 단점 |
|---|---|
| 구현이 가장 간단하고 빠름 | 다중 조건 추론에서 정확도 낮음 |
| 항상 첫 번째로 시도해야 할 baseline | 출력 형식이 불안정할 수 있음 |
| Reasoning 모델에서는 이것만으로 충분할 수 있음 | 첫 토큰 방향이 틀리면 Snowball Effect 발생 |
2. Few-shot Prompting
개념: 2-5개의 입출력 예시를 프롬프트에 포함하여 패턴을 추론하도록 하는 인컨텍스트 학습(ICL). 가중치 업데이트 없이 예시의 구조적 패턴만으로 작동합니다. 핵심 발견으로, 레이블의 정확성보다 형식과 분포가 더 중요합니다(Min et al., 2022).
system_prompt = f"""아래는 의료급여 본인부담률 참조 데이터입니다.
{copayment_reference}
[예시 1]
Q: 1종 수급권자가 제1차의료급여기관에서 외래 진료를 받으면?
A: {{"answer": "1,000원", "reason": "1종 + 1차 외래 = 1,000원"}}
[예시 2]
Q: 2종 수급권자가 약국에서 처방전으로 조제받으면?
A: {{"answer": "500원", "reason": "2종 + 약국 처방전 조제 = 500원"}}
"""
| 장점 | 단점 |
|---|---|
| 출력 형식을 안정적으로 유도 | 예시가 토큰을 소비 (비용 증가) |
| 예시가 첫 토큰 방향의 앵커 역할 | 예시 순서에 따라 성능 변동 (랜덤~SOTA) |
| 도메인 특화 패턴 전달 가능 | 너무 많으면 과적합, 너무 적으면 과소적합 |
팁: 가장 좋은 예시를 마지막에 배치. 프로덕션에서는 시맨틱 유사도 기반 동적 예시 검색이 최선입니다.
3. Chain-of-Thought (CoT)
개념: 모델이 중간 추론 단계를 생성한 후 최종 답을 도출하도록 유도하는 기법. Autoregressive 관점에서, 중간 추론 토큰이 다음 토큰 생성의 컨텍스트가 되어 최종 답의 정확도를 높입니다.
from pydantic import BaseModel
class CopaymentAnswer(BaseModel):
reason: str # 추론 과정 (이 토큰이 먼저 생성됨)
answer: str # 최종 답변 (reason을 참고하여 생성)
system_prompt = """반드시 다음 단계를 순서대로 수행하세요:
1. 수급권자 종별 확인 (1종/2종)
2. 환자 나이/조건 확인 (1세 미만, 만성질환 등)
3. 의료기관 종별 확인 (1차/2차/3차/약국)
4. 진료 유형 확인 (입원/외래)
5. 해당 조건의 교차점에서 본인부담률 결정
"""
| 장점 | 단점 |
|---|---|
| 다중 조건 교차 추론에 효과적 | 응답 시간 35-600% 증가 |
| 수학/기호 추론에서 강한 이점 | 쉬운 문제에서 오히려 오류 유발 |
| Structured Outputs와 결합하여 추론/답변 분리 | Reasoning 모델에서는 효과 미미 (2.9-3.1%) |
4. Self-Consistency
개념: 동일 질문에 temperature를 올려 N개의 다양한 추론 경로를 생성하고, 다수결 투표로 최종 답을 선택하는 디코딩 전략. CoT + 다수결의 조합입니다.
import collections
def self_consistency(question: str, n: int = 5, temperature: float = 0.7) -> str:
answers = []
for _ in range(n):
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{"role": "system", "content": cot_system_prompt},
{"role": "user", "content": question},
],
temperature=temperature, # 다양성을 위해 0이 아닌 값
)
answers.append(parse_answer(response))
counter = collections.Counter(answers)
return counter.most_common(1)[0][0]
| 장점 | 단점 |
|---|---|
| Snowball Effect를 다수결로 상쇄 | N번 호출 → 비용 N배 |
| GSM8K +17.9%, SVAMP +11.0% 향상 | temperature 튜닝 필요 (0.5-0.7 권장) |
| 경계선 문항의 안정성 크게 향상 | 대부분의 개선은 0→5 샘플에서 발생 (이후 체감) |
컨텍스트 엔지니어링으로의 전환
2025년을 기점으로 프롬프트 엔지니어링의 패러다임이 전환되고 있습니다.
"프롬프트의 적절한 단어를 찾는 것이 아니라, 모델의 원하는 행동을 생성할 가능성이 가장 높은 컨텍스트 구성이 무엇인가라는 더 넓은 질문에 답하는 것."
— Anthropic, "Effective Context Engineering for AI Agents" (2025.6)
2023-2024년의 핵심 질문이 "모델에게 어떻게 물어야 하는가"였다면, 2025-2026년의 질문은 "모델에게 무엇을 제공해야 하는가"로 바뀌었습니다. 시스템 지시문, 도구 정의, MCP(Model Context Protocol), 외부 데이터, 대화 이력 등 전체 컨텍스트 상태를 설계하고 관리하는 것이 새로운 핵심 역량입니다.
Reasoning 모델이 가져온 근본적 변화
패러다임 전환
OpenAI o1(2024.9), o3, DeepSeek R1(2025.1), Claude Extended Thinking(2025)의 등장으로 프롬프트 설계 원칙이 근본적으로 변했습니다. 또한 생각 외의 모델 성능으로 인해 저에게 연락주신 분들이 계셨는데 Reasoning/Effort 관련이라고 생각합니다.
Reasoning이란?
- 기존 LLM은 입력 → 다음 토큰 예측 → 반복 → 출력하며 “가장 그럴듯한 다음 단어”를 고르는 과정
- 한 번 잘못 생성하면 계속 틀림 → 처음에 잘 넣어주기 위해 Few shot, Zero Shot…
- Reasoning 모델은 단순화 시키면 Self-Consistency + CoT
- multi-step reasoning + multi-path search + verification
- 내부적으로 여러 reasoning path 생성 → 각 경로를 비교 → 최적의 답 선택
- 사람처럼 생각(문제를 분해하고 각 단계 결과를 다음 입력으로 계속 투입)하는 과정을 수행
- 한 번 잘못 생성해도 탐색 과정 중 모델이 스스로 제외시키는 것이 가능
- multi-step reasoning + multi-path search + verification
- https://developers.openai.com/api/docs/guides/reasoning
AI Agent의 기초 — ReAct 패턴
ReAct란?
ReAct(Reasoning + Acting)는 AI Agent의 사실상 표준 아키텍처입니다.
- Thought → Action → Observation 루프를 반복하는 패러다임
Thought: 사용자가 2종 수급권자의 외래 본인부담률을 물었다.
참조 표에서 2종 + 외래 조건을 찾아야 한다.
Action: lookup_table(종별="2종", 진료유형="외래", 기관="제1차")
Observation: 본인부담률 = 1,000원
Thought: 추가 조건(나이, 만성질환)을 확인해야 한다.
Action: check_exception(나이="생후 8개월", 만성질환=True)
Observation: 1세 미만 만성질환자 → 무료
Final Answer: 무료
ReAct가 중요한 이유
이번 과제는 프롬프트 엔지니어링만으로 문제를 풀었지만 실제 프로덕션에서는 외부 도구와의 연동이 필수입니다. ReAct는 이 과정을 구조화합니다.
ReAct에서는 LLM이 문제를 쪼개며, 어떤 도구를 사용해야할지 판단합니다.
- Thought(추론): 현재 상황을 분석하고 다음 행동을 계획
- Action(행동): 외부 도구/API 호출 (DB 조회, 웹 검색, 계산기 등)
- Observation(관찰): 도구의 반환값을 받아 다음 추론에 반영
에이전트 프레임워크와의 연결
LangChain, CrewAI, AutoGen 모두 ReAct 스타일 루프를 기본 구조로 구현합니다.
# LangChain ReAct Agent 개념적 구조
from langchain.agents import create_react_agent
tools = [
lookup_copayment_table, # 본인부담률 표 조회 도구
check_exception_rules, # 예외 규정 확인 도구
]
agent = create_react_agent(
llm=llm,
tools=tools,
prompt=react_prompt,
)
데이터 정제 (Step 2)
LLM에서 데이터가 갖는 의미
이번 과제의 핵심은 프롬프트 기법만이 아닙니다. 의료급여 본인부담률 표를 어떻게 가공하여 LLM에 제공하느냐 또한 중요합니다. 아무리 정교한 CoT나 Self-Consistency를 적용해도, 참조 데이터 자체가 LLM이 해석하기 어려운 형태라면 성능 한계에 부딪힙니다.
- PDF, 웹 검색 등 다양한 자료를 가져오더라도 불필요한 데이터들이 존재한다면 LLM 성능 저하 발생
같은 데이터, 다른 형식 → 다른 성능
- LLM은 더 발전하지만 주어지는 데이터 형식에 따라 성능 차이가 크게 발생
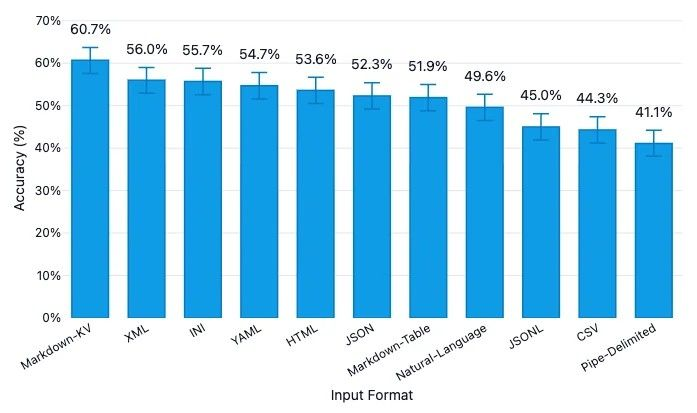
이번 과제에서의 데이터 문제
의료급여 본인부담률 표가 LLM에게 어려운 이유는 데이터 자체의 특성에 있습니다.
그럼에도 데이터 품질에 신경써야하는 이유는 다음과 같습니다.
- 이미지
- 멀티 모달이더라도 LLM은 이미지를 텍스트로 이해
- 이미지 해상도가 낮거나 표를 잘못 이해할 수 있음.
- 표 형식
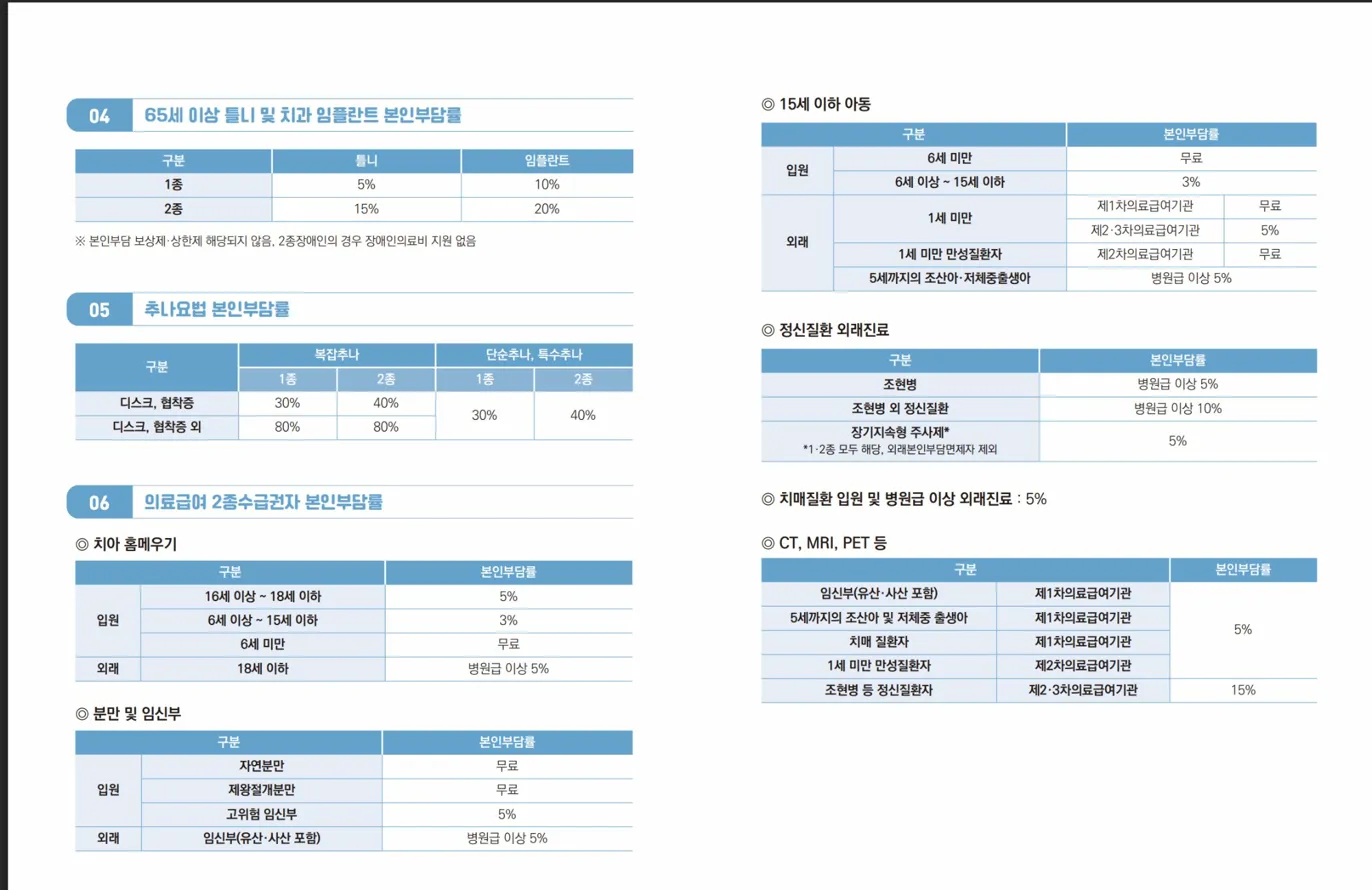
이러한 표, 이미지를 어떻게 처리할 것인지 AI 성능에 있어 매우 중요합니다.
- https://huggingface.co/PaddlePaddle/PaddleOCR-VL-1.5
- 이러한 것들을 처리, 추출하기 위한 특화 모델들도 존재(OCR, Vision Language Model -VLM)
이후 RAG 과제에 있어 참고해보시는 것을 권장드립니다. → 데이터 추출을 위한 AI와 답을 생성하기 위한 AI
![[AI Agent] RAG overview(3주차)](https://images.unsplash.com/photo-1766162357668-d41a4af974df?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDE5fHxDb250ZXh0fGVufDB8fHx8MTc3NDYxNzU3OXww&ixlib=rb-4.1.0&q=80&w=960)
![[AI Agent 과정 1기] LLM 기초 정리](https://images.unsplash.com/photo-1677442135703-1787eea5ce01?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDh8fEFJJTIwQWdlbnR8ZW58MHx8fHwxNzc0MDUwNDA2fDA&ixlib=rb-4.1.0&q=80&w=960)
![[LLM] VLM으로 표를 정확히 추출하기](https://images.unsplash.com/photo-1623667322051-18662ce6334c?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDl8fHBkZnxlbnwwfHx8fDE3NzIzNzMzODN8MA&ixlib=rb-4.1.0&q=80&w=960)
![[SageMaker] SageMaker Jumpstart를 사용한 LLM Fine Tuning - Supervised fine tuning (SFT)](https://images.unsplash.com/photo-1648652678596-d3873bd0c157?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDQ2fHxTdXBlcnZpc2VkfGVufDB8fHx8MTc1MzgzMTg2Mnww&ixlib=rb-4.1.0&q=80&w=960)