[Parser] UpstageLayoutAnalysisLoader 를 활용한 문서 파싱
UpstageDocumentParser를 사용하여 PDF를 분석하였습니다. 이를통해 이미지, 그래프를 분석하고 다각도 분석을 수행할 수 있도록 구성합니다.
![[Parser] UpstageLayoutAnalysisLoader 를 활용한 문서 파싱](https://images.unsplash.com/photo-1607434472257-d9f8e57a643d?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDJ8fFBhcnNpbmd8ZW58MHx8fHwxNzU0MDA1ODUxfDA&ixlib=rb-4.1.0&q=80&w=1200)
개요
UpstageLayoutAnalysisLoader 는 Upstage AI에서 사용할 수 있는 문서 분석 도구로 단락, 표, 그림, 주석, 수식 등 문서 내 여러 요소를 구조에 맞게 파악하며 순서대로 배열해 최종 HTML 형식으로 반환합니다.
자세한 내용은 아래 포스트에서 확인할 수 있습니다.
- https://www.content.upstage.ai/blog/business/introducing-layout-analysis
- https://www.upstage.ai/pricing?utm_source=console.upstage.ai&utm_medium=referral&utm_term=Pricing&utm_content=:nav-left
UpstageLayoutAnalysisLoader
사용하기 위해선 UPSTAGE_API_KEY 발급이 필요합니다. 현재 LangChain과 통합되어 사용 가능하며 한글로 지원되는 문서 분석 도구 중 매우 좋은 성능을 보여주고 있습니다.
- https://console.upstage.ai/home
- https://python.langchain.com/v0.2/docs/integrations/document_loaders/upstage/
- https://api.python.langchain.com/en/latest/layout_analysis/langchain_upstage.layout_analysis.UpstageLayoutAnalysisLoader.html
다만 무료로 지원되는 방식은 아닙니다.

문서와 테스트 데이터는 다음과 같습니다
UpstageLayoutAnalysisLoader Documents
구현
요구 사항은 다음과 같습니다.
최대 파일 크기가 정해져있으며, 파일 당 페이지 수도 최대 100페이지를 지원합니다.
in DocumentSupported file formats: JPEG, PNG, BMP, PDF, TIFF, HEICMaximum file size: 50MBMaximum number of pages per file: 100 pages (For files exceeding 100 pages, the first 100 pages are processed. If you want to process more than 100 pages, please use the asynchronous API)Maximum pixels per page: 100,000,000 pixels. For non-image files, the pixel count is determined after converting to images at a standard of 150 DPI.Supported character sets: Alphanumeric, Hangul, and Hanja are supported. Hanzi and Kanji are in beta versions, which means they are available but not fully supported.
자격 증명을 가져옵니다.
import os
from langchain_upstage import UpstageLayoutAnalysisLoader
os.environ["UPSTAGE_API_KEY"] = "YOUR_API_KEY"
# upstage_api_key = os.getenv("UPSTAGE_API_KEY")
Langchain과 통합된 UpstageLayoutAnalysisLoader를 사용하는 경우 해당 데이터의 포맷이 Langchain Document 형식으로 지정되어 출력됩니다.
file_name = "output_type_html"
loader = UpstageLayoutAnalysisLoader(
file_path,
split="page",
output_type="html",
exclude=["header", "footer"]
)
docs = loader.load()
"('id', None)","('metadata', {'page': 2})","('page_content', '2024 KB 부동산 보고서: 2024년 주택시장 진단과 전망 Executive Summary 1 \\uf06e 2024년 주택시장 하향 안정 전망, 금리와 공급, 그리고 정책 3대 변수 주목 주택경기가 상승과 하락을 반복하면서 주택 경기의 불확실성이 확대되고 있으나. 완만한 하향 조정\\n가능성이 큰 상황이다. 매수 수요 위축으로 주택 매매 거래량이 급감하면서 향후 주택 경기에 대한 부정적\\n시각이 팽배하다. 무엇보다 여전히 높은 금리가 부담으로 작용하고 있다. 주택 경기 불황기에 고금리\\n부담은 주택 수요를 크게 위축시킬 수밖에 없기 때문이다. 다만 주택시장의 주요 변수들의 상황에 따라\\n소폭 반등 혹은 하락폭 확대 등의 방향이 정해질 것으로 보인다. 2024년 주택시장의 주요 변수는 공급과 금리다. 급격하게 위축된 주택 공급이 단기간에 증가하기는\\n쉽지 않으나 정부의 공급 시그널이 지속된다면 일정 부분 해소가 될 가능성이 있다. 무엇보다 금리가 주요\\n변수가 될 것이다. 기준금리 인하 시기와 인하 폭에 따라 주택 수요는 영향을 받을 수밖에 없기 때문이다.\\n한편, 수요 위축으로 거래가 급감한 상황에서 실수요자 금융 지원, 관련 규제 완화 등 수요 회복을 위한\\n정부 정책도 중요한 변수가 될 전망이다. \\uf06e 7대 이슈를 통해 바라보는 2024년 주택시장 1 역대 최저 수준이 지속되고 있는 주택 거래\\n 주택 매매 거래는 2022년에 이어 2년 연속 침체. 총선 이후 정책 불확실성 해소와 금리 인하로 인한 회 복 가능성이 있으나 일부 지역 수요 쏠림 현상과 금리 인하 속도가 더딜 경우 회복세는 제한적일 전망\\n 2 주택공급 급격한 감소로 인한 공급 부족 가능성\\n 분양물량과 함께 장기적인 주택 공급 기반인 인허가물량까지 급감. 청약 수요 위축으로 분양 지연이 장기 화될 가능성이 높? 가운데 정부의 공급 정책 구체화가 매우 중요\\n 3 노후계획도시 특별법과 재건축 시장 영향\\n 2023년 말 국회를 통과한 「노후계획도시 특별법」 시행? 앞두고 당초 51곳이었던 대상 지역이 108곳으 로 확대. 단기적 효과는 제한적이나 사업진행이 구체화되면 시장 영향도 커질 것\\n 4 전세 수요 아파트 집중, 입주물량 부족으로 가격 상승 가능성 확대\\n 비아파트 전세 사기와 보증금 미반환 이슈 등으로 아파트로 전세 수요가 집중되는 가운데 수도권? 중심 으로 아파트 입주물량이 크게 감소함에 따라 다시 전세가격 상승세가 확대될 가능성이 존재\\n 5 주택 경기에 최대 화두로 부각되는 금리 인하 가능성\\n 금리 인하에 따른 매수 심리 회복에 대한 기대감이 높아지고 있지만 가계 부채 관리 강화와 경기 불확실 성 확대 등이 존재하는 시장에서 금리 인하 시기와 인하폭이 관건\\n 6 주택경기 위축에도 늘어나는 주택담보대출\\n 주택담보대출 증가세는 다소 둔화될 것으로 전망되나 가계부채에 대한 우려가 지속될 경우 매수세 회복? 위한 적극적인 정책 추진에는 제약 요인이 될 것\\n 7 주택시장 안정화를 위한 정책 기조 지속, 완화 폭이 핵심\\n 주택 공급시장 관리와 거래 활성화가 정부 정책의 가장 큰 화두이며, 규제 완화 기조는 2024년에도 지속 되는 데 반해 수요 지원? 제한적일 전망 1')","('type', 'Document')"
"('id', None)","('metadata', {'page': 3})","('page_content', '2024 KB 부동산 보고서: 2024년 주택시장 진단과 전망 Executive Summary 2 \\uf06e 주택 매매시장 하락 전망 우세, 부동산 투자 선호도 하락 • 2024 년 주택 매매가격 지난해에 이어 올해도 하락 전망 우세, 높은 금리가 가장 큰 부담 부동산시장 전문가와 공인중개사, 자산관리전문가(PB)를 대상으로 한 설문 조사 결과, 2024년 전국 주택\\n매매가격은 하락세가 이어질 것이라는 전망이 우세하였다. 다만 시장 급락에 대한 우려는 다소 완화된\\n것으로 보인다. 상승에 대한 전망이 2023년 대비 크게 증가했기 때문이다(전문가 21%p, 공인중개사\\n17%p, PB 13%p 증가). 매매가격 하락요인으로는 높은 금리에 따른 이자부담이 가장 중요한 이유로\\n조사되었다. • 2024 년 주택 전세가격, 비수도권은 하락 전망이 우세하나 수도권 전망은 엇갈려 2024년 전국 주택 전세가격에 대해 전문가의 53%, 공인중개사의 61%가 하락을 전망하였다. 하락폭에\\n대해서는 3% 이하가 될 것이라는 의견이 많았다. 다만 2023년 하락 전망이 압도적으로 우세했던 것과\\n달리 2024년에는 상승과 하락 전망에 격차가 크지 않았다. 지역별로 수도권에서는 주택 전세가격이\\n상승과 하락 의견이 엇갈렸으나 비수도권에서는 하락 전망이 우세하였다. • 경기 회복을 위해서는 금리 인하와 대출 규제 완화가 중요 변수 주택 경기 회복을 위해 필요한 핵심 정책으로 전문가와 공인중개사, PB 모두 금리 인하를 꼽았다.\\n다음으로 주택담보대출 지원, LTV·DSR 등 금융 규제 완화가 필요하다는 의견이 많았다. 특히 공인중개사\\n그룹에서 금리와 대출 관련 정책의 필요성을 높게 평가하였다. 이는 현재 주택시장 침체가 수요 감소에\\n따른 영향이 크며 수요 회복 여부가 향후 시장 흐름을 결정할 핵심 요인이라는 인식이 반영된 결과로\\n풀이된다. • 투자 유망 부동산으로 아파트 분양과 신축 아파트, 재건축 전문가, 공인중개사, PB는 공통적으로 2024년 투자 유망 부동산으로 아파트 분양과 신축 아파트,\\n재건축을 꼽았다. 아파트 분양과 신축 아파트는 지난해 비해 선호도가 높아졌으며, 재건축은 꾸준히 투자\\n유망 부동산으로 주목을 받을 것으로 보인다. 전문가는 아파트 분양(28%), 공인중개사는 신축\\n아파트(23%), PB는 재건축(27%)을 1순위 투자유망 부동산으로 꼽았다. • 고자산가는 투자 자산으로 예금과 채권을 선호, 부동산 경기 위축 및 고금리로 부동산 선호도는 하락 PB 대상 설문조사에서 고자산가가 선호하는 투자 자산은 예금(29%), 채권(24%), 부동산(23%) 순으로\\n나타났다. 부동산은 2017년 조사 이래 고자산가들이 가장 선호하는 투자 자산 부동의 1위 자리를 지켜\\n왔으나 부동산시장이 위축되고 고금리 상황이 지속되면서 순위가 하락하였다. • 부동산 세무에 대한 상담 수요가 가장 높으며, 보유 부동산 처분에 대한 관심도 증가 고자산가의 2023년 부동산 관련 상담 및 자문 1위는 지난해에 이어 부동산 세무(40%)가 차지했는데,\\n이는 여전히 높은 부동산 세금 부담 때문으로 판단된다. 이어서 수익형 부동산 구입(23%)과 보유 부동산\\n처분(22%)에 관한 상담이 주를 이루었다. 2')","('type', 'Document')"
...
해당 데이터에서도 마찬가지로 이미지 데이터와 관련된 출력 형식을 찾아볼 수 없습니다. 따라서 커스텀하게 사용하여 구현하였습니다.
Custom api call
로드할 문서의 파일명을 작성합니다.
file_name = "230530 국토부_전세사기피해자 지원 및 주거안정에 관한 특별법_리플릿"
import os
import re
import json
import requests
from pathlib import Path
from bs4 import BeautifulSoup, Tag
from pdf2image import convert_from_path
class LayoutAnalyzer:
def __init__(self, file_name):
current_dir = Path.cwd()
self.api_key = os.getenv("UPSTAGE_API_KEY")
self.dataset_dir = Path(current_dir / 'dataset')
self.file_path = self.dataset_dir / file_name
self.dataset_dir.mkdir(exist_ok=True)
def upstage_layout_analysis(self):
"""
레이아웃 분석 API 호출
:param file_path: 분석할 PDF 파일 경로
:return: 생성된 JSON 파일 경로
"""
# 파일 존재 및 타입 확인
if not self.file_path.with_suffix('.pdf').exists():
raise FileNotFoundError(f"파일을 찾을 수 없습니다: {self.file_path.with_suffix('.pdf')}")
# API 요청 보내기
with open(self.file_path.with_suffix('.pdf'), "rb") as file:
response = requests.post(
"<https://api.upstage.ai/v1/document-ai/layout-analysis>",
headers={"Authorization": f"Bearer {self.api_key}"},
data={"ocr": False},
files={"document": file},
exclude=["header", "footer"]
)
# 응답 처리
if response.status_code == 200:
json_path = self.file_path.with_suffix('.json')
with open(json_path, "w", encoding='utf-8') as f:
json.dump(response.json(), f, ensure_ascii=False, indent=2)
return str(json_path)
else:
raise ValueError(f"예상치 못한 상태 코드: {response.status_code}")
@staticmethod
def normalize_coordinates(bbox, page_width, page_height, json_width=1241, json_height=1754):
"""
PDF의 표준화된 크기에 따라 실제 좌표를 계산합니다.
정규화된 데이터를 통해 JSON에서 제공하는 좌표를 실제 PDF 페이지의 픽셀 위치로 변환합니다.
"""
normalized = []
for point in bbox:
normalized.append(int(point['x'] * page_width / json_width))
normalized.append(int(point['y'] * page_height / json_height))
return normalized
def extract_images_and_tables(self):
"""
이미지, 테이블 캡쳐를 위해 저장된 데이터 위치와 출력 데이터 위치를 지정합니다.
d
"""
# 출력 디렉토리 생성
output_dir = self.dataset_dir / "extracted_images" / self.file_path.stem
os.makedirs(output_dir, exist_ok=True)
# PDF를 이미지로 변환
pages = convert_from_path(self.file_path.with_suffix('.pdf'), 300)
# JSON 데이터 로드
with open(self.file_path.with_suffix('.json'), 'r', encoding='utf-8') as f:
data = json.load(f)
# 추출할 요소 처리
for element in data['elements']:
if element.get('category') in ['figure', 'table'] and 'bounding_box' in element:
page_num = element['page'] - 1 # 페이지 번호는 1부터 시작하므로 0부터 시작하는 인덱스로 변환
if 0 <= page_num < len(pages):
page_image = pages[page_num]
page_width, page_height = page_image.size
# Bounding box 좌표 추출 및 정규화
bbox = element['bounding_box']
normalized_coords = self.normalize_coordinates(bbox, page_width, page_height)
# 좌표 추출
left = min(normalized_coords[0::2])
top = min(normalized_coords[1::2])
right = max(normalized_coords[0::2])
bottom = max(normalized_coords[1::2])
# 이미지 크롭
cropped_image = page_image.crop((left, top, right, bottom))
# RGB 모드로 변환
cropped_image = cropped_image.convert('RGB')
# 파일 이름 생성
file_name = f"page_{element['page']}__{element['category']}_{element['id']}.png"
output_path = os.path.join(output_dir, file_name)
# 크롭된 이미지 저장
cropped_image.save(output_path, "PNG")
print(f"Saved {element['category']} {element['id']}: {output_path}")
print("Image and table extraction complete.")
def execute_layout_analysis(self):
# 레이아웃 분석 수행
json_path = self.upstage_layout_analysis(self.file_path.with_suffix(".pdf"))
return json_path
analyzer = LayoutAnalyzer()
result = analyzer.upstage_layout_analysis()
analyzer.execute_capture()
다음을 실행하면 전체 PDF가 json 출력되어 아래 형식으로 생성됩니다.
또한 각 PDF 파일에 있는 여러 엘리먼트(요소)들은 아래 카테고리들로 변환되어 HTML 요소도 추가됩니다.

{
"api": "1.1",
"billed_pages": 8,
"elements": [
{
"bounding_box": [
{
"x": 250,
"y": 331
},
{
"x": 986,
"y": 331
},
{
"x": 986,
"y": 630
},
{
"x": 250,
"y": 630
}
],
"category": "heading1",
"html": "<h1 id='0' style='font-size:14px'>전세사기피해자<br>지원 및 주거안정에<br>관한 특별법</h1>",
"id": 0,
"page": 1,
"text": "전세사기피해자\\n지원 및 주거안정에\\n관한 특별법"
},
{
"bounding_box": [
{
"x": 272,
"y": 754
},
{
"x": 986,
"y": 754
},
{
"x": 986,
"y": 1270
},
{
"x": 272,
"y": 1270
}
],
"category": "figure",
"html": "<figure><img id='1' alt=\\"\\" data-coord=\\"top-left:(272,754); bottom-right:(986,1270)\\" /></figure>",
"id": 1,
"page": 1,
"text": ""
},
{
"bounding_box": [
{
"x": 187,
"y": 160
},
{
"x": 455,
"y": 160
},
{
"x": 455,
"y": 204
},
{
"x": 187,
"y": 204
}
],
"category": "heading1",
"html": "<h1 id='2' style='font-size:22px'>1. 특별법 지원대상</h1>",
"id": 2,
"page": 2,
"text": "1. 특별법 지원대상"
},
{
"bounding_box": [
{
"x": 425,
"y": 266
},
{
"x": 839,
"y": 266
},
{
"x": 839,
"y": 298
},
{
"x": 425,
"y": 298
}
],
"category": "paragraph",
"html": "<p id='3' data-category='paragraph' style='font-size:16px'>< 전세사기피해자등 결정을 위한 4가지 요건 ></p>",
"id": 3,
"page": 2,
"text": "< 전세사기피해자등 결정을 위한 4가지 요건 >"
},
{
"bounding_box": [
{
"x": 175,
"y": 346
},
{
"x": 744,
"y": 346
},
{
"x": 744,
"y": 373
},
{
"x": 175,
"y": 373
}
],
"category": "paragraph",
"html": "<p id='4' data-category='paragraph' style='font-size:14px'>➊ 주택의 인도와 주민등록(전입신고)을 마치고 확정일자를 갖춘 경우</p>",
"id": 4,
"page": 2,
"text": "➊ 주택의 인도와 주민등록(전입신고)을 마치고 확정일자를 갖춘 경우"
},
...
}
실제 테이블과 이미지는 아래와 같이 캡쳐되며 PDF 내에서 bounding box를 통해 출력할 수 있습니다.
단 해당 PDF의 width, height를 고려하여 계산되어야하며 코드는 다음과 같습니다.
@staticmethod
def normalize_coordinates(bbox, page_width, page_height, json_width=1241, json_height=1754):
"""
PDF의 표준화된 크기에 따라 실제 좌표를 계산합니다.
정규화된 데이터를 통해 JSON에서 제공하는 좌표를 실제 PDF 페이지의 픽셀 위치로 변환합니다.
"""
normalized = []
for point in bbox:
normalized.append(int(point['x'] * page_width / json_width))
normalized.append(int(point['y'] * page_height / json_height))
return normalized

테이블과 표까지 잘 캡쳐되는 것을 확인할 수 있으나 RAG 구조 상 이를 활용하기 위해선 이미지 형식이 아닌 텍스트 형식으로의 변환이 필요합니다. 따라서 이를 해결하기 위해 이미지와 관련된 설명까지 첨부하여 이미지, 표에 대한 설명을 작성할 수 있도록 구성이 필요하며 문서 전처리를 위한 추가적인 구성이 필요합니다.
하지만 단순한 이미지 분석만으로는 불가능하다고 생각되며 이미지를 정확히 분석하기 위해선 해당 이미지의 내용 뿐만 아니라 이미지 전후로 작성된 문맥 또한 매우 중요하기때문에 정확한 RAG 구조와 성능 향상을 위해 해당 이미지를 처리하기 위한 방식을 추가하였습니다.
LLM 파이프라인
UpstageLayoutAnalysisLoader 을 거쳐 PDF를 여러 엘리먼트로 파싱하였지만 해당 이미지가 무엇을 의미하는지는 출력되지 않았습니다. 따라서 LLM 파이프라인을 추가하여 이미지에 대한 설명과 텍스트를 추가할 수 있도록 하였습니다.
pdf 문서를 UpstageLayoutAnalysisLoader 로 구성하였고 해당 데이터를 통해 이미지와 테이블을 만드는 작업까지 진행하였습니다. 해당 데이터를 LLM을 거쳐 데이터를 추가한 뒤 최종적인 Document를 생성하고 이를 청킹하여 page content로 Document를 검색 가능한 형태로 생성하는 것이 최종 목표입니다.
Figure, Table 주변 데이터 추출
각 이미지, 테이블 별 설명을 추가하기 위해서 엘리먼트 전후 2개 이내의 텍스트와 데이터를 추출합니다. 이때 연속적인 테이블이나 이미지가 있다면 해당 테이블 또한 포함되어 그룹화되고 그룹화된 컨텍스트에 전후 2개의 텍스트를 추출하여 이미지 설명에 포함합니다.
코드는 다음과 같습니다.
import json
from pathlib import Path
from dataclasses import dataclass
@dataclass
class ImageDocument:
id: int
page: int
image_path: Path # 이미지 파일의 경로
context: str # 이미지와 관련된 컨텍스트 정보
def get_surrounding_text(elements, start_index, end_index, n=2):
"""
주어진 범위의 요소 주변 텍스트를 추출하는 함수
:param elements: 전체 요소 리스트
:param start_index: 시작 인덱스
:param end_index: 종료 인덱스
:param n: 앞뒤로 추출할 텍스트 요소의 개수
:return: 이전 텍스트, 사이 텍스트, 이후 텍스트
"""
before_start = max(0, start_index - n) # 이전 텍스트의 시작 인덱스 (음수 방지)
after_end = min(len(elements), end_index + n + 1) # 이후 텍스트의 종료 인덱스 (범위 초과 방지)
# 각 범위에서 텍스트 요소만 추출
before = [el['text'] for el in elements[before_start:start_index] if 'text' in el]
between = [el['text'] for el in elements[start_index:end_index+1] if 'text' in el]
after = [el['text'] for el in elements[end_index+1:after_end] if 'text' in el]
return before, between, after
# JSON 파일 읽기
with open(json_path, 'r', encoding='utf-8') as file:
data = json.load(file)
# 'elements' 리스트 가져오기
elements = data['elements']
image_documents = [] # ImageDocument 객체들을 저장할 리스트
i = 0
while i < len(elements):
# Figure 또는 Table 요소를 만났을 때 처리
if elements[i].get('category') in ['figure', 'table']:
start_index = i
end_index = min(i + 2, len(elements) - 1) # 최대 2개의 범위 내에서 검색
# 연속된 Figure 또는 Table 요소 찾기
while end_index > start_index and elements[end_index].get('category') not in ['figure', 'table']:
end_index -= 1
# 주변 텍스트 추출
before_texts, between_texts, after_texts = get_surrounding_text(elements, start_index, end_index)
# 컨텍스트 문자열 생성 시작
context = ""
# 발견된 Figure 또는 Table 요소들에 대해 ImageDocument 생성
for idx in range(start_index, end_index + 1):
element = elements[idx]
if element['category'] in ['figure', 'table']:
# 이미지 파일 경로 생성
image_path = image_dir / f"page_{element['page']}__{element['category']}_{element['id']}.png"
# 전체 컨텍스트 문자열 구성 및 정규화
full_context = context + "\\n"
full_context += "이전 텍스트:\\n" + "\\n".join(f"- {text}" for text in before_texts) + "\\n\\n"
if between_texts:
full_context += "사이 텍스트:\\n" + "\\n".join(f"- {text}" for text in between_texts) + "\\n\\n"
full_context += "이후 텍스트:\\n" + "\\n".join(f"- {text}" for text in after_texts)
# ImageDocument 객체 생성 및 리스트에 추가
image_document = ImageDocument(id=element['id'], page=element['page'],image_path=image_path, context=full_context)
image_documents.append(image_document)
i = end_index # 다음 검색 시작 위치를 현재 그룹의 끝으로 설정
i += 1 # 다음 요소로 이동
# 이후 image_documents 리스트를 사용하여 각 이미지에 대한 처리 수행 가능
출력은 다음과 같습니다.
Image Path: /Users/byeongjuchoi/ML/LLM/langchain_UpstageLayoutAnalysisLoader/dataset/extracted_images/2024 KB 부동산 보고서_최종/page_1_figure_0.png
Context:
Figure (id: 0):
이전 텍스트:
사이 텍스트:
-
이후 텍스트:
- 2024 KB 부동산 보고서: 2024년 주택시장 진단과 전망
- Executive Summary 1
--------------------------------------------------
Image Path: /Users/byeongjuchoi/ML/LLM/langchain_UpstageLayoutAnalysisLoader/dataset/extracted_images/2024 KB 부동산 보고서_최종/page_2_table_7.png
Context:
Table (id: 7):
이전 텍스트:
- 2024년 주택시장의 주요 변수는 공급과 금리다. 급격하게 위축된 주택 공급이 단기간에 증가하기는
쉽지 않으나 정부의 공급 시그널이 지속된다면 일정 부분 해소가 될 가능성이 있다. 무엇보다 금리가 주요
변수가 될 것이다. 기준금리 인하 시기와 인하 폭에 따라 주택 수요는 영향을 받을 수밖에 없기 때문이다.
한편, 수요 위축으로 거래가 급감한 상황에서 실수요자 금융 지원, 관련 규제 완화 등 수요 회복을 위한
정부 정책도 중요한 변수가 될 전망이다.
- 7대 이슈를 통해 바라보는 2024년 주택시장
사이 텍스트:
- 1 역대 최저 수준이 지속되고 있는 주택 거래
주택 매매 거래는 2022년에 이어 2년 연속 침체. 총선 이후 정책 불확실성 해소와 금리 인하로 인한 회 복 가능성이 있으나 일부 지역 수요 쏠림 현상과 금리 인하 속도가 더딜 경우 회복세는 제한적일 전망
2 주택공급 급격한 감소로 인한 공급 부족 가능성
분양물량과 함께 장기적인 주택 공급 기반인 인허가물량까지 급감. 청약 수요 위축으로 분양 지연이 장기 화될 가능성이 높? 가운데 정부의 공급 정책 구체화가 매우 중요
3 노후계획도시 특별법과 재건축 시장 영향
2023년 말 국회를 통과한 「노후계획도시 특별법」 시행? 앞두고 당초 51곳이었던 대상 지역이 108곳으 로 확대. 단기적 효과는 제한적이나 사업진행이 구체화되면 시장 영향도 커질 것
4 전세 수요 아파트 집중, 입주물량 부족으로 가격 상승 가능성 확대
비아파트 전세 사기와 보증금 미반환 이슈 등으로 아파트로 전세 수요가 집중되는 가운데 수도권? 중심 으로 아파트 입주물량이 크게 감소함에 따라 다시 전세가격 상승세가 확대될 가능성이 존재
5 주택 경기에 최대 화두로 부각되는 금리 인하 가능성
금리 인하에 따른 매수 심리 회복에 대한 기대감이 높아지고 있지만 가계 부채 관리 강화와 경기 불확실 성 확대 등이 존재하는 시장에서 금리 인하 시기와 인하폭이 관건
6 주택경기 위축에도 늘어나는 주택담보대출
주택담보대출 증가세는 다소 둔화될 것으로 전망되나 가계부채에 대한 우려가 지속될 경우 매수세 회복? 위한 적극적인 정책 추진에는 제약 요인이 될 것
7 주택시장 안정화를 위한 정책 기조 지속, 완화 폭이 핵심
주택 공급시장 관리와 거래 활성화가 정부 정책의 가장 큰 화두이며, 규제 완화 기조는 2024년에도 지속 되는 데 반해 수요 지원? 제한적일 전망
이후 텍스트:
- 1
- 2024 KB 부동산 보고서: 2024년 주택시장 진단과 전망
--------------------------------------------------
Image Path: /Users/byeongjuchoi/ML/LLM/langchain_UpstageLayoutAnalysisLoader/dataset/extracted_images/2024 KB 부동산 보고서_최종/page_4_table_29.png
Context:
Table (id: 29):
이전 텍스트:
- 수도권 주택시장 전반적 침체, 강남권 등 선호 지역 상대적 강세
- 과거와는 달리 높은 기준금리와 주택 매매가격, DSR 규제 등으로 매수자들의 구매 여력은 회복되지
못하고 있으나, 2023년 이후 정부의 다양한 규제 완화로 매도자들의 기대 심리는 높아지고 있다. 재건축
규제 완화, 광역급행철도(GTX, Great Train Express) 개통 등에 따라 지역별로 호재가 존재하며 부동산
PF대출 부실, 전세보증금 반환 문제 등 전반적인 주택 경기 위축 요소들도 상존하고 있다.
사이 텍스트:
- 구분 지역명 주요 이슈
서울 한강 이남 강남구 정부 규제 완화와 주택 수요 집중으로 긍정적 기대감 유지
서초구 높? 분양가에도 청약 수요는 많으나 진행 중인 정비사업? 차별화 예상
송파구 전세가격 하락에 영향? 줄 수 있는 대규모 단지 입주 예정
양천구 재건축 사업 진행? 긍정적이나 토지거래허가구역으로 매매시장 위축 지속
서울 한강 이북 마포구 지역 내에서 매수세 변화가 나타나면서 지역간 매매가격 격차 확대
용산구 한남뉴타운 사업 진행? 양호하나 여전히 큰 매도자와 매수자 간 간극
성동구 대기 수요는 많으나 실제 매수 가담 여부가 중요한 요소로 작용할 것
수도권 위례 위례선 개통 예정과 위례신사선 착공 지연으로 긍정적·부정적 요인이 혼재
과천 지식정보타운의 본격적인 입주와 교통 개발로 지역 확대
동탄 교통 개선과 반도체 관련 수요보다 수도권 주택시장 및 금리 영향이 클 전망
이후 텍스트:
- 상업용 부동산시장
- 고금리와 경기 불확실성 확대 영향으로 2023년 상업용 부동산시장은 거래량이 크게 감소하고 평균
매매가격 역시 하락하였다. 거래량 감소와 함께 매매가격이 하락하면서 2023년 상업용 부동산 거래총액은
2022년 대비 34.8% 감소했다.
--------------------------------------------------
Image Path: /Users/byeongjuchoi/ML/LLM/langchain_UpstageLayoutAnalysisLoader/dataset/extracted_images/2024 KB 부동산 보고서_최종/page_8_figure_68.png
Context:
Figure (id: 68 - 70):
이전 텍스트:
- 2022년 하반기부터 주택 경기가 크게 위축되면서 주택 매매가격? 2023년 전국 기준 4.6% 하락하
였다. 이는 외환위기 직후인 1998년(12.4% 하락) 이후 최대 하락폭이다. 2021년 매매가격이 15.0%
상승하면서 과열 양상? 보이던 주택 경기가 불과 2년 만에 급락세로 돌아선 것이다. 지역별로는 대구
와 대전? 제외한 전국 대다수 지역에서 2022년 대비 하락폭이 크게 확대되었다.
- 그 림Ⅰ-1. 주택 매매가격 변동률 추이
사이 텍스트:
-
- 그림Ⅰ-2. 지역별 주택 매매가격 변동률(2022~2023년)
-
이후 텍스트:
- 자료: KB국민?행
- 자료: KB국민?행
--------------------------------------------------
Image Path: /Users/byeongjuchoi/ML/LLM/langchain_UpstageLayoutAnalysisLoader/dataset/extracted_images/2024 KB 부동산 보고서_최종/page_8_figure_70.png
Context:
Figure (id: 68 - 70):
이전 텍스트:
- 2022년 하반기부터 주택 경기가 크게 위축되면서 주택 매매가격? 2023년 전국 기준 4.6% 하락하
였다. 이는 외환위기 직후인 1998년(12.4% 하락) 이후 최대 하락폭이다. 2021년 매매가격이 15.0%
상승하면서 과열 양상? 보이던 주택 경기가 불과 2년 만에 급락세로 돌아선 것이다. 지역별로는 대구
와 대전? 제외한 전국 대다수 지역에서 2022년 대비 하락폭이 크게 확대되었다.
- 그 림Ⅰ-1. 주택 매매가격 변동률 추이
사이 텍스트:
-
- 그림Ⅰ-2. 지역별 주택 매매가격 변동률(2022~2023년)
-
이후 텍스트:
- 자료: KB국민?행
- 자료: KB국민?행
--------------------------------------------------
해당 데이터를 다시 LLM으로 넣어 앞뒤 맥락과 관련하여 해당 이미지가 무엇을 의미하는지, 어떠한 데이터를 가지고 있는지 작성합니다. 이후 텍스트 데이터를 추가하여 저장합니다.
def extract_json(text):
# JSON 부분을 추출하는 정규 표현식
json_pattern = r'\\{[\\s\\S]*\\}'
match = re.search(json_pattern, text)
if match:
return match.group()
return None
def process_images(image_documents, json_path):
gemini_flash = GeminiMultiModal(model_name="models/gemini-1.5-flash-latest")
# 기존 JSON 파일 읽기
with open(json_path, 'r', encoding='utf-8') as file:
data = json.load(file)
# 'elements' 리스트 가져오기
elements = data['elements']
for img_doc in image_documents:
# LlamaImageDocument 생성 (image_path만 사용)
llamaidex_image_document = LlamaImageDocument(image_path=str(img_doc.image_path))
prompt = f"""
context를 참조하여 해당 이미지에 대해 서술해야합니다.
context는 해당 이미지 위치의 이전, 이후, 이미지 내 사이 데이터들로 구성되어 있으며 해당 데이터들을 통해 이미지에 대하여 명확하게 서술해야합니다.
table의 경우 데이터를 가능한한 자세히 해석하고 정확한 content를 작성하여야합니다.
출력은 다음과 같습니다.
1. 이미지 내용
2. 키워드 최대 5개
JSON 형식:
{{
"content": "이미지 설명",
"keywords": ["키워드1", "키워드2", "키워드3", "키워드4", "키워드5"],
}}
JSON 형식 외 데이터는 출력하지 말아야합니다.
context:
{img_doc.context}
"""
response_multi = gemini_flash.complete(
prompt=prompt,
image_documents=[llamaidex_image_document],
)
# Parse the JSON response
json_str = extract_json(response_multi.text)
if json_str:
try:
result = json.loads(json_str)
# 해당 ID를 가진 element 찾기
for element in elements:
if element['id'] == img_doc.id:
# 기존 element에 새로운 필드 추가
element['text'] = result['content']
element['image_keywords'] = result['keywords']
break
except json.JSONDecodeError:
print(f"Failed to parse JSON for image {img_doc.id}. Skipping.")
else:
print(f"No JSON found in the response for image {img_doc.id}. Skipping.")
# 수정된 데이터를 새 JSON 파일에 저장
output_path = Path(json_path).with_name("processed_document.json")
with open(output_path, 'w', encoding='utf-8') as f:
json.dump(data, f, ensure_ascii=False, indent=2)
print(f"Results saved to {output_path}")
# 함수 호출
process_images(image_documents, json_path)
위 데이터를 통해 각 항목 별 Text가 추가되었습니다. 해당 데이터를 기반으로 RAG를 위한 데이터 전처리를 진행합니다.
{
"bounding_box": [
{
"x": 127,
"y": 591
},
{
"x": 585,
"y": 591
},
{
"x": 585,
"y": 935
},
{
"x": 127,
"y": 935
}
],
"category": "figure",
"html": "<figure><img id='68' alt=\\"\\" data-coord=\\"top-left:(127,591); bottom-right:(585,935)\\" /></figure>",
"id": 68,
"page": 8,
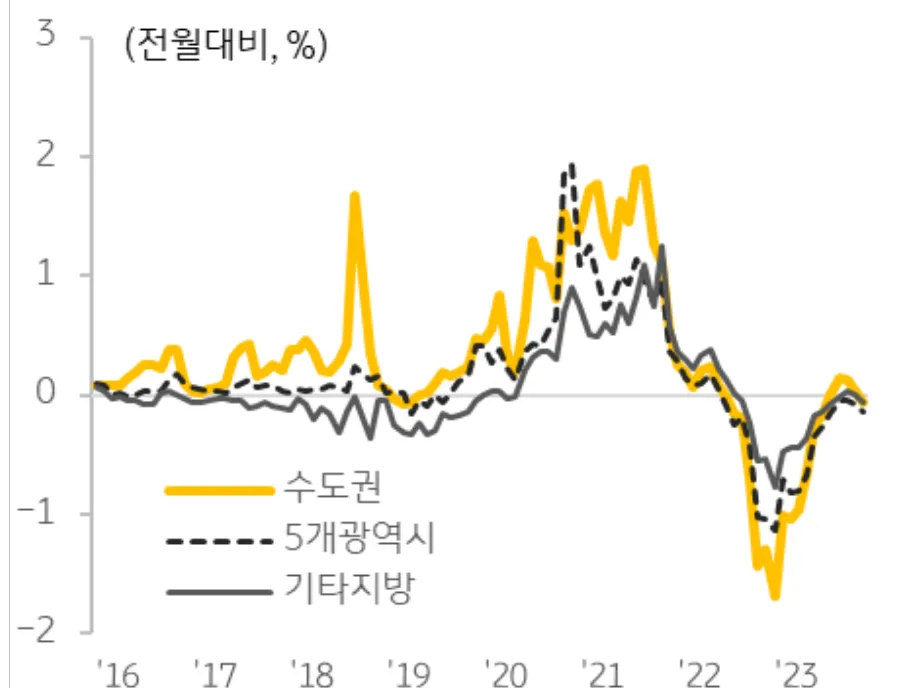
"text": "그림Ⅰ-1. 주택 매매가격 변동률 추이 그래프이다. 2016년부터 2023년까지 수도권, 5개 광역시, 기타지방의 주택 매매가격 변동률을 나타낸다. 2021년까지는 수도권의 주택 매매가격 변동률이 가장 높았고, 2022년부터는 기타지방의 주택 매매가격 변동률이 가장 낮았다.",
"image_keywords": [
"주택 매매가격",
"변동률",
"수도권",
"5개 광역시",
"기타지방"
]
},
이제 데이터를 Langchain JSONLoader 를 통해 Document로 변환하여 기타 서비스들과 통합 가능하도록 변환하겠습니다.
loader = JSONLoader(
file_path=Path(json_path).with_name("processed_document.json"),
jq_schema='.elements[] | {text, category, page, keyword}',
text_content=False,
)
최종 출력 결과는 다음과 같습니다.
[...
Document(metadata={'source': '/Users/byeongjuchoi/ML/LLM/langchain_UpstageLayoutAnalysisLoader/dataset/processed_document.json', 'seq_num': 1}, page_content='{"text": "\\\\ub178\\\\ub780\\\\uc0c9\\\\uacfc \\\\ud68c\\\\uc0c9\\\\uc73c\\\\ub85c \\\\uadf8\\\\ub824\\\\uc9c4 \\\\ub3c4\\\\uc2dc\\\\uc758 \\\\uac04\\\\ub2e8\\\\ud55c \\\\uadf8\\\\ub9bc\\\\uc785\\\\ub2c8\\\\ub2e4. \\\\ub3c4\\\\uc2dc\\\\uc5d0\\\\ub294 \\\\uac74\\\\ubb3c, \\\\ub098\\\\ubb34, \\\\uad6c\\\\ub984\\\\uc774 \\\\uc788\\\\uc2b5\\\\ub2c8\\\\ub2e4.", "category": "figure", "page": 1, "keyword": null}'),
Document(metadata={'source': '/Users/byeongjuchoi/ML/LLM/langchain_UpstageLayoutAnalysisLoader/dataset/processed_document.json', 'seq_num': 2}, page_content='{"text": "2024 KB \\\\ubd80\\\\ub3d9\\\\uc0b0 \\\\ubcf4\\\\uace0\\\\uc11c: 2024\\\\ub144 \\\\uc8fc\\\\ud0dd\\\\uc2dc\\\\uc7a5 \\\\uc9c4\\\\ub2e8\\\\uacfc \\\\uc804\\\\ub9dd", "category": "heading1", "page": 2, "keyword": null}'),
Document(metadata={'source': '/Users/byeongjuchoi/ML/LLM/langchain_UpstageLayoutAnalysisLoader/dataset/processed_document.json', 'seq_num': 3}, page_content='{"text": "Executive Summary 1", "category": "heading1", "page": 2, "keyword": null}'),
...]
결론
UpstageLayoutAnalysisLoader 를 통해 문서를 엘리먼트 단위로 나누었습니다. 이렇게 나눠진 각 요소별 이미지, 테이블이 포함되어 있는 경우 해당 데이터를 검색하기 위해 텍스트와 키워드를 추출하여 검색 가능한 이미지 형태로 구현하였습니다.
해당 테스트에서는 메타데이터를 추가하지 않았지만, 이미지를 첨부할 수 있으며 이를 통한 RAG 구조에서 이미지와 관련된 분석 및 구현을 할 수 있습니다.
또한 Upstage 모델 자체가 한국 기업이 개발한 모델이다보니 Loader 자체의 성능 또한 유의미할 정도로 뛰어난 것을 확인할 수 있었습니다.
![[LLM] VLM으로 표를 정확히 추출하기](https://images.unsplash.com/photo-1623667322051-18662ce6334c?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDl8fHBkZnxlbnwwfHx8fDE3NzIzNzMzODN8MA&ixlib=rb-4.1.0&q=80&w=960)
![[RAG] 한국어 Reranker 모델을 사용하여 RAG 성능 올리기](https://images.unsplash.com/flagged/photo-1578928534298-9747fc52ec97?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDF8fFJhbmtpbmd8ZW58MHx8fHwxNzU0MTM3OTQ4fDA&ixlib=rb-4.1.0&q=80&w=960)
![[RAG] 더 나은 RAG를 위해 Retrieval pipeline 개선하기](https://images.unsplash.com/photo-1528819622765-d6bcf132f793?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDF8fHN0cmF0ZWd5fGVufDB8fHx8MTc1NDEzNzQ2Nnww&ixlib=rb-4.1.0&q=80&w=960)
![[GraphDB] GraphRAG(Neo4j)](https://images.unsplash.com/photo-1434626881859-194d67b2b86f?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDExfHxncmFwaHxlbnwwfHx8fDE3NTM4MzI1MjF8MA&ixlib=rb-4.1.0&q=80&w=960)