[OpenSearch] OpenSearch 기능 Deep dive
OpenSearch의 구성과 검색, 분석 대시보드, 이상 탐지, 시각화까지 모든 내용을 한번 정리하였습니다.
![[OpenSearch] OpenSearch 기능 Deep dive](https://images.unsplash.com/photo-1533746228171-962520811097?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDN8fExlbnN8ZW58MHx8fHwxNzUzNzQ2NTg4fDA&ixlib=rb-4.1.0&q=80&w=1200)
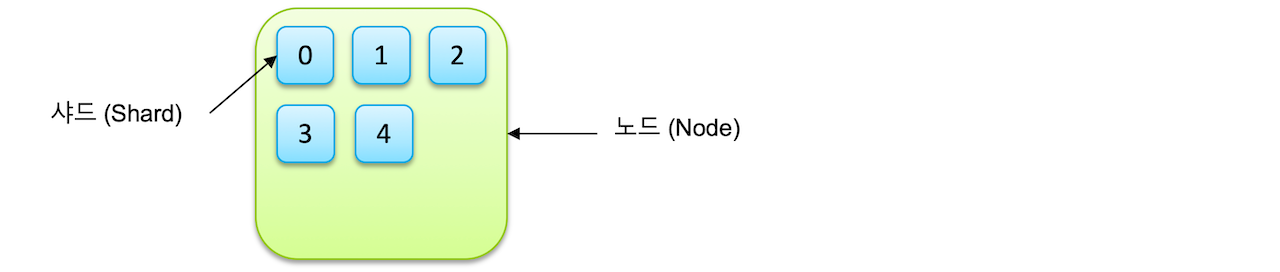
인덱스
단일 데이터 단위를 도큐먼트(Document)라고 하며, 이러한 도큐먼트를 모아놓은 집합을 인덱스(Index)라고 합니다.
샤드와 노드
- 노드: 노드는 OpenSearch 클러스터의 일부인 단일 서버(물리적 또는 가상)입니다. 노드는 데이터를 보유하고 클러스터의 인덱싱 및 쿼리 프로세스에 참여합니다. 클러스터에는 하나 이상의 노드가 있을 수 있습니다.
- 샤드: 샤드는 클러스터 데이터의 하위 집합입니다. OpenSearch의 각 인덱스는 샤드로 나누어져 데이터가 여러 노드에 분산될 수 있습니다. 새로운 인덱스를 생성할 때 인덱스를 몇 개의 shard로 나누어 저장할 것인지 저장할 수 있습니다.
인덱스는 기본적으로 샤드 단위로 분리되고 각 노드에 분산되어 저장이 됩니다. 샤드는 이후 루씬의 단일 검색 인스턴스의 단위로 사용됩니다.샤드는 OpenSearch에서 데이터 저장 및 관리의 기본 단위입니다.
- 도큐먼트 및 인덱스: 도큐먼트는 개별 데이터 조각이고 인덱스는 유사한 문서의 모음인 최상위 수준에서 데이터의 논리적 구조를 나타냅니다.
- 샤드: 인덱스의 물리적 표현 역할을 하여 여러 노드에 걸쳐 데이터 배포 및 병렬 처리를 가능하게 합니다.
- 노드 및 클러스터: 데이터가 저장되는 물리적 인프라를 나타냅니다. 노드는 개별 서버이고, 클러스터는 데이터를 효율적으로 관리하고 저장하기 위한 이러한 노드의 집합적인 조직입니다.
샤드 유형
- 기본 샤드: 데이터가 처음 기록되는 원본 샤드입니다. 각 인덱스에는 하나 이상의 기본 샤드가 있습니다.
- 복제 샤드: 기본 샤드의 복사본입니다. 복제본 샤드는 중복성을 제공하여 내결함성에 도움이 되고 시스템의 읽기 성능을 향상시킵니다.
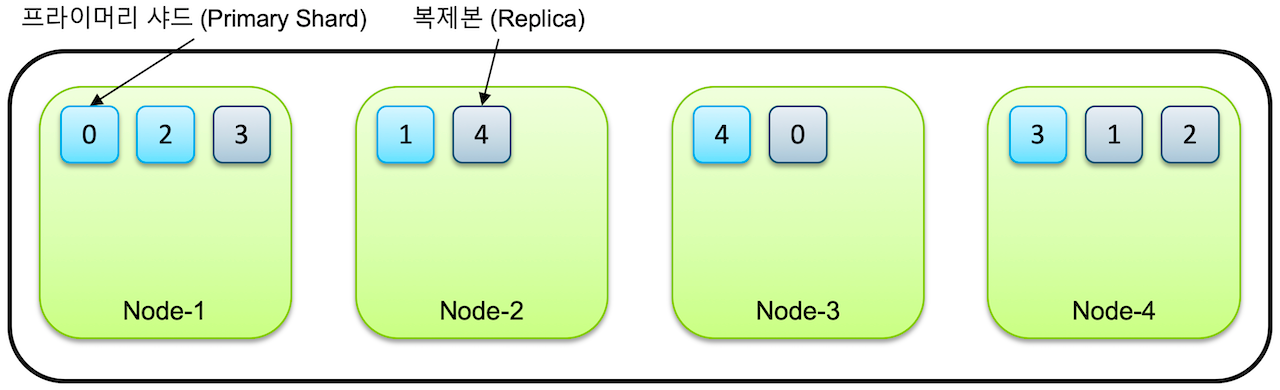
인덱스가 5개의 샤드로 구성어 있고, 클러스터가 4개의 노드로 구성되어 있다고 가정하면 각각 5개의 프라이머리 샤드와 복제본, 총 10개의 샤드들이 전체 노드에 골고루 분배되어 저장됩니다.같은 샤드와 복제본은 동일한 데이터를 담고 있으며 반드시 서로 다른 노드에 저장이 됩니다.샤드1이 노드1에 저장되었다면 샤드1 복제본은 샤드1을 제외한 곳에 저장됩니다.따라서 노드 하나가 유실되어도 어딘가에 복제본이 저장되있기 때문에 전체 데이터를 유지할 수 있게 됩니다.
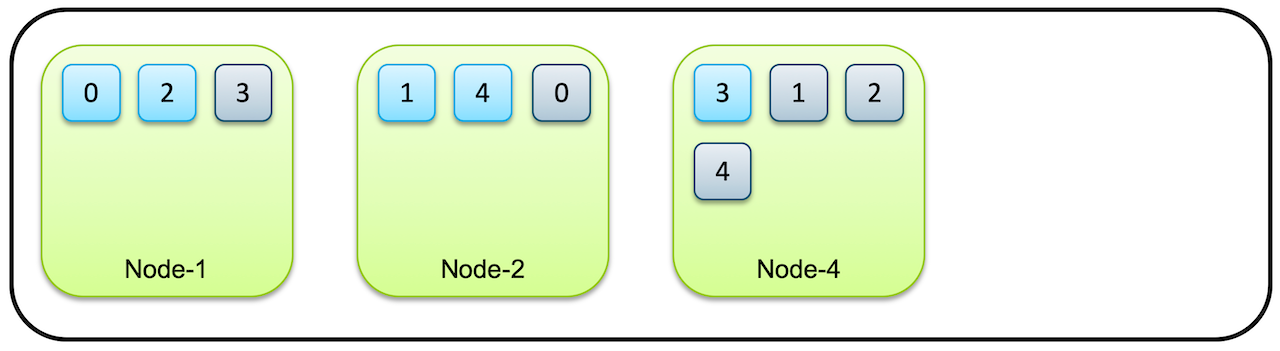
다중 데이터 노드에 대한 요구 사항
기본 샤드와 복제본 샤드가 동일한 데이터 노드에 상주할 수 없다는 규칙은 데이터 가용성과 복원력을 보장합니다. 기본 노드와 복제본이 모두 동일한 노드에 있고 해당 노드에 장애가 발생한 경우 데이터를 전혀 사용할 수 없습니다. OpenSearch는 기본 및 복제본 샤드를 여러 노드에 분산함으로써 한 노드가 다운되더라도 복제본 샤드가 있는 다른 노드가 계속 데이터를 제공할 수 있도록 하여 고가용성을 보장합니다.
다양한 유형의 노드
OpenSearch는 클러스터 내의 노드에 대해 다양한 역할을 지원하므로 워크로드에 따라 전문화가 가능합니다.
- 마스터 적격(전용 리더) 노드: 클러스터를 제어하는 마스터 노드로 선출될 수 있는 노드입니다.
마스터 노드를 지정하지 않으면 데이터 노드에서 적절한 풀을 생성하여 마스터 노드를 지정하게 됩니다.
인덱스의 메타 데이터, 샤드의 위치와 같은 클러스터 상태(Cluster Status) 정보를 관리하는 노드의 역할을 수행하며 마스터 노드의 역할을 수행할 수 없다면 클러스터는 작동이 정지됩니다. - 데이터 노드: 이 노드는 데이터를 저장하고 검색, 집계 등 데이터 관련 작업을 실행합니다.
- 수집 노드: 이 노드는 문서를 색인화하기 전에 사전 처리합니다.
- 조정(클라이언트 혹은 쿼리) 노드: 이 노드는 클라이언트의 요청을 적절한 데이터 노드로 라우팅한 다음 결과를 집계합니다.
시사점
복제본을 적절하게 배치하려면 최소 2개의 데이터 노드가 필요하다는 점은 고가용성을 염두에 두고 OpenSearch 클러스터를 설계하는 것의 중요성을 강조합니다. 소규모 배포의 경우에도 데이터 노드가 두 개 이상 있으면 데이터 손실을 방지하고 노드 하나에 장애가 발생하더라도 애플리케이션이 계속 제대로 작동하도록 할 수 있습니다. 이 설정은 데이터 가용성과 시스템 복원력이 가장 중요한 프로덕션 환경에 매우 중요합니다.
네트워크
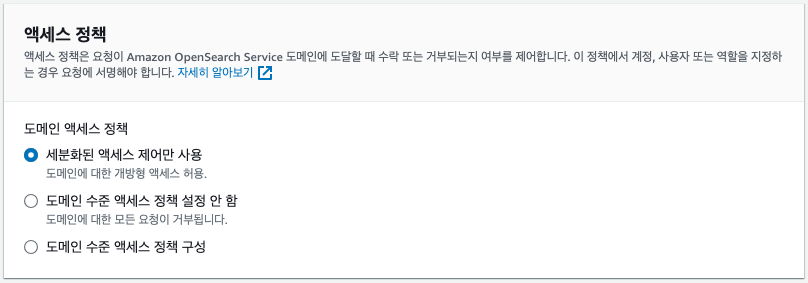
엑세스 정책
FGAC(Fine-grained Access Control)는 이름에서 알 수 있듯이, 도메인에 대한 세부 보안 규칙을 구현하여 특정 사용자 또는 역할이 문서 또는 필드 수준까지 (보거나 볼 수 없도록) 제어할 수 있습니다. 활성화 하는 경우, 이런 작업을 하기위한 마스터 사용자 계정을 지정해야 합니다.
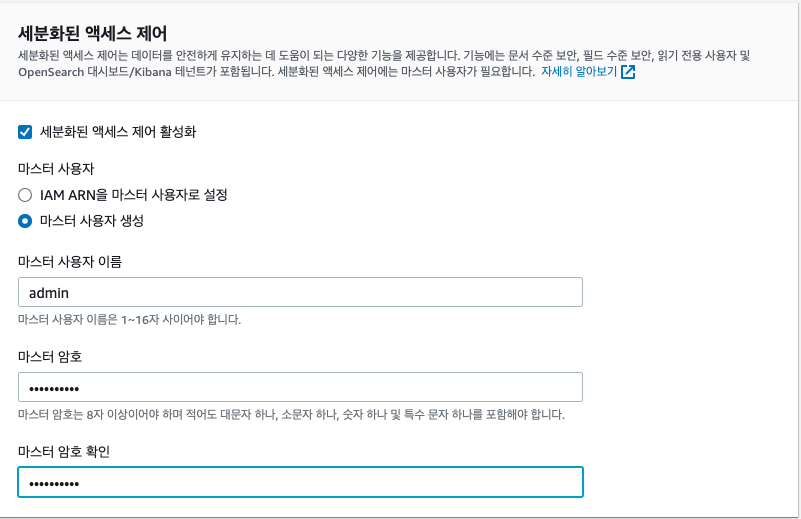
데이터 저장 단위 계산하기
도메인에서 100GiB의 데이터가 사이즈가 예상된다면 복제본 샤드를 수용하기 위해 200GiB를 사용할 수 있는지 확인해야 합니다. 즉, 3개의 데이터 노드가 있는 경우 각각 약 67GiB를 저장해야 합니다.
데이터 워크로드 구분하기
샤드로 분할하는 것은 쿼리 처리 및 인덱싱에 병렬성을 적용하는 방법입니다. 샤드 크기와 요청 처리 대기 시간 사이에는 밀접한 관계가 있습니다. 샤드에 데이터가 많을수록, 쿼리에 있는 용어가 더 많이 일치할수록 샤드가 수행해야 하는 작업이 많아집니다. 기본 샤드가 많을수록, 상대적으로 데이터가 적은 더 작은 샤드라는 것을 의미하며 쿼리에 대한 더 많은 병렬 처리의 이점을 얻고 싶을 때 선호합니다.샤드가 클수록 노드 간 네트워킹이 줄어들기 때문에, 매치된 결과를 작게 유지할 수 있도록 쿼리 필터링이 있는 워크로드에 적합합니다.
대체로 검색 워크로드에는 더 작은 샤드(10GiB부터 30GiB까지)를 사용하고 로그 워크로드에는 더 큰 샤드(30GiB부터 50GiB까지)를 사용해야 합니다. 160GiB의 데이터 세트가 있는 경우 해당 데이터를 단일 샤드에 저장하면 안 됩니다. 인덱스에 대한 보다 합리적인 샤드 수는 4(40GiB/샤드) 또는 5(32GiB/샤드)일 수 있습니다.
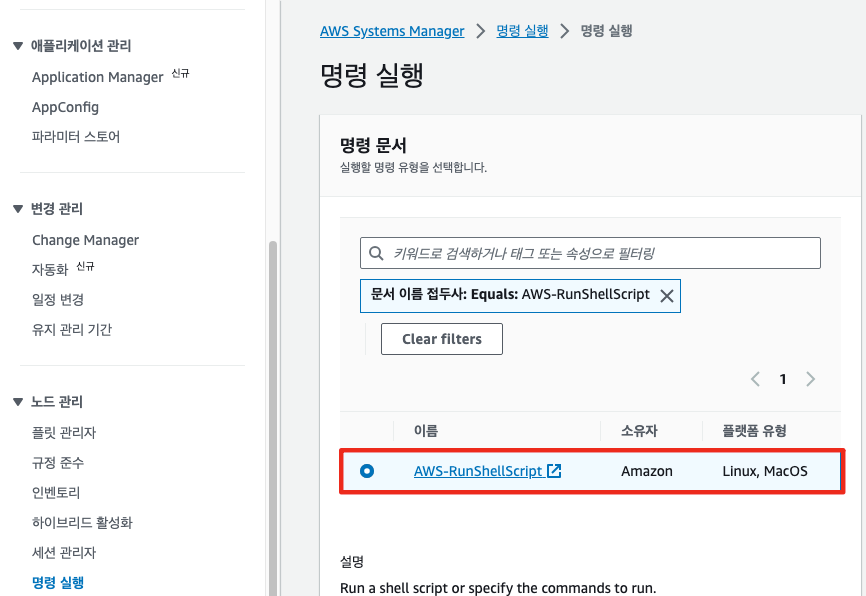
Domain 접근하기
Amazon OpenSearch Service 도메인이 생성되고 사용할 준비가 되면 공용 인터넷에서 도메인에 도달하기 위한 트래픽 경로를 생성해야 합니다.프라이빗 VPC 서브넷에 Amazon OpenSearch Service 도메인을 생성했으므로 인터넷을 통한 직접적인 통로가 없습니다. 액세스 권한을 부여하려면 HTTP 프록시(nginx)를 사용하여 요청을 신규 도메인으로 전달합니다.
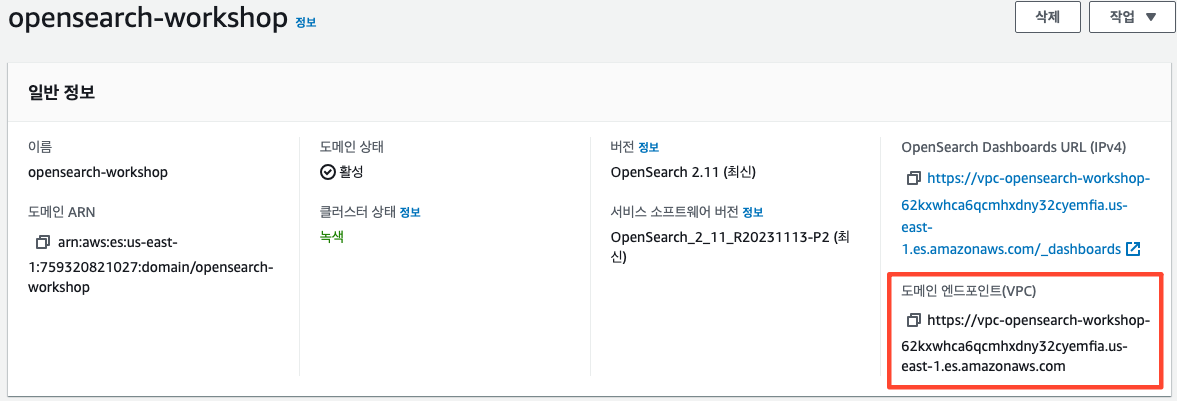
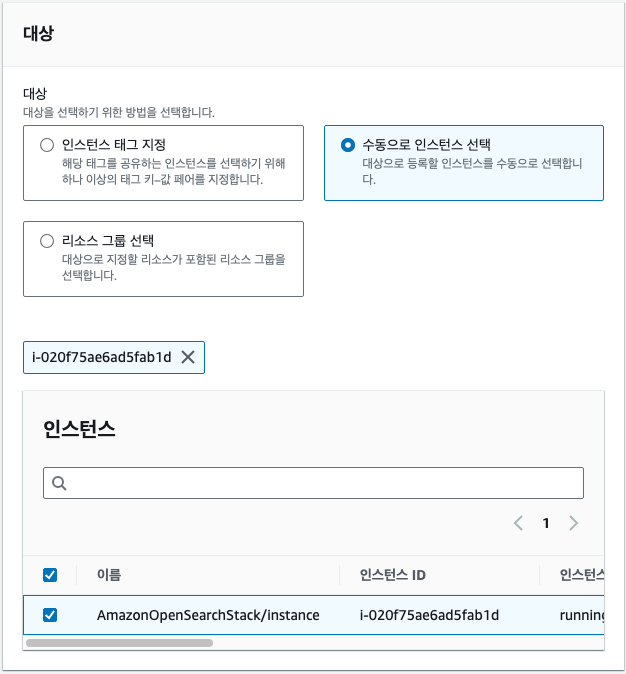
configupdate <OpensearchDomainEndpoint>
검색 & 분석
Index와 Data 설정
PUT /my-movie-index
{
"settings": {
"index": {
"number_of_shards": 3,
"number_of_replicas": 1
}
}
}
GET my-movie-index
------------------------------------
{
"acknowledged": true,
"shards_acknowledged": true,
"index": "my-movie-index"
}3개의 샤드와 1개의 복제본이 있는 my-movie-index라는 인덱스가 생성됩니다.
데이터 채우기
데이터 생성
여러 명령을 배치로 수행하기 위해서 _bulk API를 사용해야합니다._bulk API로 index, create, update, delete의 동작이 가능하며 delete를 제외하고는 명령문과 데이터문을 한 줄씩 입력하여야 합니다._bulk API 요청은 일반적으로 두 줄에 걸쳐 하나의 작업을 정의합니다: 첫 번째 줄은 작업 메타데이터를 정의하고, 두 번째 줄은 실제 문서 데이터입니다.
{"index": {"_index": "my-movie-index"}}
{
"directors": ["Joseph Gordon-Levitt"],
"release_date": "2013-01-18T00:00:00Z",
"rating": 7.4,
"genres": ["Comedy", "Drama"],
"image_url": "http://ia.media-imdb.com/images/M/MV5BMTQxNTc3NDM2MF5BMl5BanBnXkFtZTcwNzQ5NTQ3OQ@@._V1_SX400_.jpg",
"plot": "A New Jersey guy dedicated to his family, friends, and church, develops unrealistic expectations from watching porn and works to find happiness and intimacy with his potential true love.",
"title": "Don Jon",
"rank": 1,
"running_time_secs": 5400,
"actors": ["Joseph Gordon-Levitt", "Scarlett Johansson", "Julianne Moore"],
"year": 2013
}데이터 쿼리하기
매개변수 없이 검색 API를 실행하면 필터링 없이 인덱스에서 결과를 제공합니다. 검색 필터가 제공하지 않으면 모든 문서가 검색 결과에 포함됩니다.
GET /my-movie-index/_search방금 검색한 데이터는 다음 두 단계에서 수행됩니다.
- 쿼리 단계 - 이 단계에서는 쿼리가 각 샤드에서 로컬로 실행되고 일치하는 문서 ID가 쿼리 노드로 반환됩니다. 쿼리 노드는 이러한 레코드를 병합하고 정렬된 목록을 만듭니다.
- 패칭 단계 - 이 단계에서 쿼리 노드는 ID에서 실제 데이터를 가져와 클라이언트에 반환합니다.
Opensearch 검색 과정(참고)OpenSearch에서 쿼리를 실행할 때 여러분은 엔드포인트로 요청을 보내고, 이는 라운드 로빈 형식으로 OpenSearch 클러스터의 데이터 노드에 요청됩니다. 한 노드가 요청을 받으면, 이를 해당 쿼리에 대한 코디네이터 노드라고 하며 요청된 인덱스에 대한 샤드를 저장하는 실제 데이터 노드에서 데이터 검색을 시작합니다. 코디네이터 노드는 쿼리되는 인덱스와 관련된 데이터를 갖고 있을 수도 있고 갖고있지 않을 수도 있습니다.
쿼리 요청이 들어오면 조정 노드가 해당 쿼리 요청을 담당하게 됩니다.
쿼리 문을 다시 데이터 노드로 날려 데이터를 취합하고 반환하는 역할을 수행합니다.
Term 쿼리
term 쿼리는 검색어와 정확히 일치하는 문서를 반환합니다.
GET my-movie-index/_search
{
"query": {
"term": {
"directors.keyword": {
"value": "James Franco"
}
}
}
}OpenSearch는 간단한 URL 기반 쿼리 구문과 더 복잡한 REST 기반 JSON 인터페이스를 지원합니다.
GET /my-movie-index/_search?q=franco_.keyword 참고
원본 문서(데이터)를 보면 directors 필드는 있지만 directors.keyword 필드는 없다는 것을 알 수 있습니다. 어떻게 된 것일까요?? OpenSearch에 문서를 넣으면 OpenSearch는 필드를 자동 감지하고 해당 필드를 _mapping_합니다. _mapping_은 인덱스의 필드에 적용되는 스키마입니다. 문자열 값이 있는 필드의 경우 OpenSearch에는 텍스트를 다르게 취급하는 2가지 핵심 유형이 있습니다.
text 필드는 문자열의 단어를 완전히 구문 분석하고 처리합니다. keyword 필드는 정확한 일치를 위해 문자열을 그대로 둡니다. OpenSearch가 문자열 필드를 감지하면 필드 자체를 text 유형(완전히 구문 분석됨)으로 매핑하고 _.keyword_로 하위 필드, 즉 keyword 유형을 생성합니다. keyword 필드의 개별 단어는 일치시킬 수 없으며 대소문자를 포함한 전체 문자열만 일치시킬 수 있습니다.
정리하면 James Franco 데이터에서 James와 Fanco를 전부 나눠 저장하는 방식이 있고 하위에keyword로 따로 분류하여 정확인 문자열을 그대로 저장합니다.
특정 Keyword(용어) 쿼리
- Term 쿼리 - 용어를 정확히 일치시키려는 경우 이 쿼리 계열을 사용합니다.
keyword필드와 함께 용어 쿼리를 자주 사용합니다. - Match 쿼리 - 긴 텍스트에서 매칭하고 특히 OpenSearch의 관련성을 사용하여 결과를 정렬할 때 이 쿼리 계열을 사용합니다.
text필드와 함께 이러한 쿼리를 가장 자주 사용합니다.
Term의 keyword 와 Match text 차이OpenSearch는 analysis 라고 하는 프로세스로 text 필드의 문자열을 처리합니다. 분석하는 동안 OpenSearch는 텍스트를 세그먼트(segment)화 하여 개별 용어(term) 를 추출합니다.용어를 공백으로 구분된 단어로 생각할 수 있지만 일부 언어, 예를 들어 일본어, 한국어와 같은 아시아 언어에는 더 복잡하고 상황 인지가 필요한 세분화된 내용이 있습니다. OpenSearch는 용어의 스트림을 추가로 처리하여 구성 가능한 변환 세트를 적용하고, 불용어(stop word) 라는 일반적인 단어를 제거하고, 단어를 공통 어간 형식으로 줄이고, 동의어를 추가하고, 소문자로 변환하는 등의 작업을 수행합니다.Standard analysis 과정은 단순히 공백으로 단어를 분할하거나 소문자로 단어를 변경하는 작업을 진행합니다.
이 과정을 통해 문서에 특정 부분만 검색할 수 있는 키워드 기반 쿼리를 사용할 수 있게 됩니다.
GET my-movie-index/_search
{
"query": {
"term": {
"title": "transformers"
}
}
}
POST my-movie-index/_search
{
"query": {
"simple_query_string": {
"query": "Transformers",
"fields": ["title"]
}
}
}
# result > 대소문자 구분없이 검색
...
"title": "Transformers",
..._analyze API를 통해 OpenSearch가 어떻게 데이터를 변환하는지 확인할 수 있습니다.
GET my-movie-index/_analyze
{
"analyzer": "default",
"text": ["Transformers"]
}
// {
// "tokens": [
// {
// "token": "transformers",
// "start_offset": 0,
// "end_offset": 12,
// "type": "<ALPHANUM>",
// "position": 0
// }
// ]
// }Boolean 쿼리
bool 쿼리는 복합 쿼리 클래스의 구성원으로 여러 term과 match 쿼리를 혼합하여 일치 항목을 결합하는 방법에 대한 로직을 제공합니다. bool 쿼리는 절을 그룹화하고 혼합하기 위한 구문을 제공합니다. must, should, must_not 및 should_not 블록에 여러 절을 가질 수 있습니다. should 쿼리는 논리적 OR 조건이고 must 쿼리는 논리적 AND 조건입니다.
should(or) 조건문 예시
# 장르가 action
# 제목이 matrix
# 배우가 reeves
# 셋 중 하나가 포함되어 있으면 출력됩니다.
GET /my-movie-index/_search
{
"query": {
"bool": {
"should": [
{
"match": {
"genres": "action"
}
},
{
"match": {
"title": "matrix"
}
},
{
"match": {
"actors": "reeves"
}
}
]
}
}
}출력 결과에는 몇 가지 유의할 사항이 있습니다.
should일치 항목 중 하나 이상이 true인 검색 결과가 426개 있었습니다.- 결과 집합의 맨 위에 정렬된 문서는
score값이 가장 높은 문서였습니다. 이 경우 문서는 3가지should조건 모두와 일치합니다. - 시리즈의 다른 영화는 모든 조건을 충족하더라도 각각 2위와 3위를 기록했습니다. 이 경우 OpenSearch는 첫 번째 문서의
title이 원하는 쿼리와 더 근접하게 일치한다고 간주하므로 결과의 점수가 더 높습니다. 다른 영화의 점수는 거의 동일하지만 첫 번째 영화보다 순위가 낮습니다.
특정 문서가 받은 점수의 이유를 이해하려면 explain 쿼리 를 수행할 수 있습니다. 쿼리 결과를 검토하는 가장 간단한 방법은 검색 쿼리에 explain=true를 추가하는 것입니다. 여기서 Explain 결과는 반환된 문서에 추가됩니다. (또는 \["explain": "true"\] 를 쿼리의 JSON 본문에 추가할 수 있습니다.)
GET /my-movie-index/_search?explain=true
{
"query": {
"bool": {
"should": [
{
"match": {
"genres": "action"
}
},
{
"match": {
"title": "matrix"
}
},
{
"match": {
"actors": "reeves"
}
}
]
}
}
}OpenSearch에서 스코어를 측정하는 방법
OpenSearch는 Okapi BM25 라는 기본 스코어링 함수를 사용합니다. 이 (일반적으로 Term Frequency / Inverse Document Frequency 또는 TF / IDF)는 본질적으로 통계입니다. 개별 용어는 전체 말뭉치(IDF)에서 얼마나 드문지에 비례하는 점수 값을 받습니다. 문서는 일치하는 용어 점수에 해당 용어가 문서에 나타나는 횟수(TF)를 곱하여 점수를 받습니다.
....
"_explanation": {
"value": 12.041015,
"description": "sum of:",
"details": [
{
"value": 1.0838069,
"description": "weight(genres:action in 98) [PerFieldSimilarity], result of:",
"details": [
{
"value": 1.0838069,
"description": "score(freq=1.0), computed as boost * idf * tf from:",
"details": [
{
"value": 2.2,
"description": "boost",
"details": []
},
{
"value": 1.2243615,
"description": "idf, computed as log(1 + (N - n + 0.5) / (n + 0.5)) from:",
"details": [
{
"value": 150,
"description": "n, number of documents containing term",
"details": []
},
{
"value": 511,
"description": "N, total number of documents with field",
"details": []
}
]
},
{
"value": 0.40236443,
"description": "tf, computed as freq / (freq + k1 * (1 - b + b * dl / avgdl)) from:",
"details": [
{
"value": 1,
"description": "freq, occurrences of term within document",
"details": []
},
{
"value": 1.2,
"description": "k1, term saturation parameter",
"details": []
},
{
"value": 0.75,
"description": "b, length normalization parameter",
"details": []
},
{
"value": 4,
"description": "dl, length of field",
"details": []
},
{
"value": 3.037182,
"description": "avgdl, average length of field",
"details": []
}
]
}
]
}
]
},
{
"value": 6.444957,
"description": "weight(title:matrix in 98) [PerFieldSimilarity], result of:",
"details": [
{
"value": 6.444957,
"description": "score(freq=1.0), computed as boost * idf * tf from:",
"details": [
{
"value": 2.2,
"description": "boost",
"details": []
},
{
"value": 5.8328595,
"description": "idf, computed as log(1 + (N - n + 0.5) / (n + 0.5)) from:",
"details": [
{
"value": 1,
"description": "n, number of documents containing term",
"details": []
},
{
"value": 511,
"description": "N, total number of documents with field",
"details": []
}
]
},
{
"value": 0.5022452,
"description": "tf, computed as freq / (freq + k1 * (1 - b + b * dl / avgdl)) from:",
"details": [
{
"value": 1,
"description": "freq, occurrences of term within document",
"details": []
},
{
"value": 1.2,
"description": "k1, term saturation parameter",
"details": []
},
{
"value": 0.75,
"description": "b, length normalization parameter",
"details": []
},
{
"value": 2,
"description": "dl, length of field",
"details": []
},
{
"value": 2.6046968,
"description": "avgdl, average length of field",
"details": []
}
]
}
]
}
]
},
{
"value": 4.5122514,
"description": "weight(actors:reeves in 98) [PerFieldSimilarity], result of:",
"details": [
{
"value": 4.5122514,
"description": "score(freq=1.0), computed as boost * idf * tf from:",
"details": [
{
"value": 2.2,
"description": "boost",
"details": []
},
{
"value": 4.734247,
"description": "idf, computed as log(1 + (N - n + 0.5) / (n + 0.5)) from:",
"details": [
{
"value": 4,
"description": "n, number of documents containing term",
"details": []
},
{
"value": 511,
"description": "N, total number of documents with field",
"details": []
}
]
},
{
"value": 0.43323112,
"description": "tf, computed as freq / (freq + k1 * (1 - b + b * dl / avgdl)) from:",
"details": [
{
"value": 1,
"description": "freq, occurrences of term within document",
"details": []
},
{
"value": 1.2,
"description": "k1, term saturation parameter",
"details": []
},
{
"value": 0.75,
"description": "b, length normalization parameter",
"details": []
},
{
"value": 7,
"description": "dl, length of field",
"details": []
},
{
"value": 6.2485323,
"description": "avgdl, average length of field",
"details": []
}
]
}
]
}
]
}
]
}must(and) 조건문 예시
GET /my-movie-index/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"genres": "action"
}
},
{
"match": {
"title": "matrix"
}
},
{
"match": {
"actors": "reeves"
}
}
]
}
}
}Range 쿼리
- 보다 큼:
gt - 보다 작음:
lt - 크거나 같음:
gte - 작거나 같음:
lte
GET my-movie-index/_search
{
"query": {
"range": {
"year": {
"gt": 2014,
"lt": 2016
}
}
}
}- 쿼리 결합
GET my-movie-index/_search
{
"query": {
"bool": {
"must": [
{
"range": {
"year": {
"gt": 2014,
"lt": 2016
}
}
},
{
"match": {
"genres": "action"
}
}
]
}
}
}Boost 쿼리
OpenSearch는 점수 알고리즘을 사용하여 문서를 반환하기 전에 점수를 매기고 정렬합니다. boosting 을 사용하여 특정 카테고리에 점수에 영향을 줄 수 있습니다.
필드를 부스트하면 해당 필드에서 일치하는 용어의 점수에 부스트 계수를 곱합니다.# 부스팅 없는 쿼리입니다.
GET my-movie-index/_search
{
"query": {
"multi_match": {
"query": "horror",
"fields": ["title","plot"]
}
}
}
# 부스트를 넣은 쿼리입니다.
GET my-movie-index/_search
{
"query": {
"multi_match": {
"query": "horror",
"fields": ["title^2","plot"]
}
}
}실제 쿼리를 실행하면 출력 결과의 순서가 바뀌어있다는 것을 확인할 수 있습니다.
Function Score 쿼리
rating 필드가 소스 문서에 존재하지 않는 경우 문서의 점수에 0이 곱해집니다 결과 집합의 맨 아래로 이동됩니다.해당 쿼리를 실행하면 Rating field가 0인 값과 스코어가 있는 값을 확인할 수 있습니다.이 쿼리에서는 score를 기반으로 sort 키워드를 사용하여 점수별로 결과를 오름차순 으로 정렬하여 결과 집합을 반전시켜 출력합니다.
POST my-movie-index/_search
{
"query": {
"function_score": {
"query": {
"multi_match": {
"query": "horror",
"fields": [
"title"
]
}
},
"functions": [
{
"field_value_factor": {
"field": "rating",
"missing": 0
}
}
]
}
},
"sort": [
{
"_score": {
"order": "asc"
}
}
]
}Aggregation 쿼리
집계는 특정 필드의 값을 그룹화하여 요약된 값을 계산합니다. 쿼리에 사용할 수 있는 다양한 유형의 집계가 있습니다.OpenSearch의 다양한 집계 유형은 분석을 할 수 있도록 도와줍니다. 시간, 키워드 필드의 문자열 값 및 숫자를 기준으로 버킷팅할 수 있습니다.숫자 집계는 min, max, average, sum 등과 같은 조합 함수를 지원합니다. Pipeline 집계를 사용하면 집계의 출력을 다른 집계로 보낼 수 있습니다.# 해당 쿼리에서는 결과값을 생략하고 집계 결과만 반환하고 있습니다.
GET my-movie-index/_search
{
"aggs": {
"term_agg": {
"terms": {
"field": "genres.keyword"
}
}
},
"size": 0
}
- 집계 결과를 중첩하여 확인할 수 있습니다.
GET my-movie-index/_search
{
"aggs": {
"year": {
"aggs": {
"genre": {
"terms": {
"field": "genres.keyword",
"order": {
"_key": "asc"
}
}
}
},
"terms": {
"field": "year"
}
}
},
"size": 0
}Discover
Discover 메뉴는 유연한 UI를 통해 데이터를 드릴 다운으로 분석할 수 있습니다.
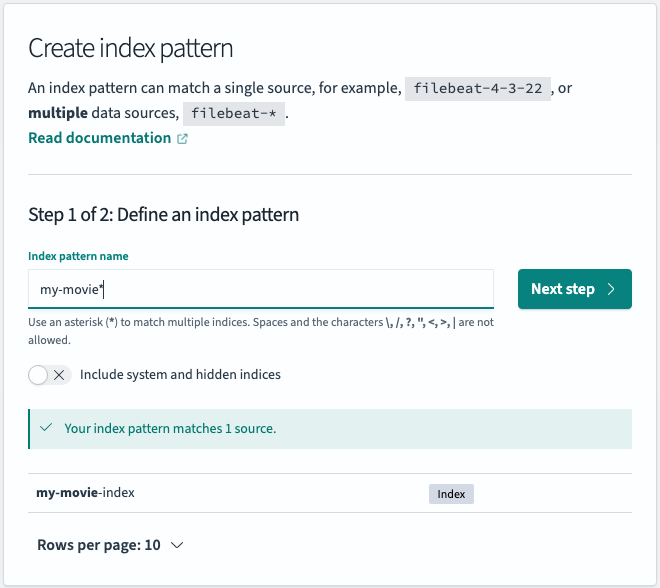
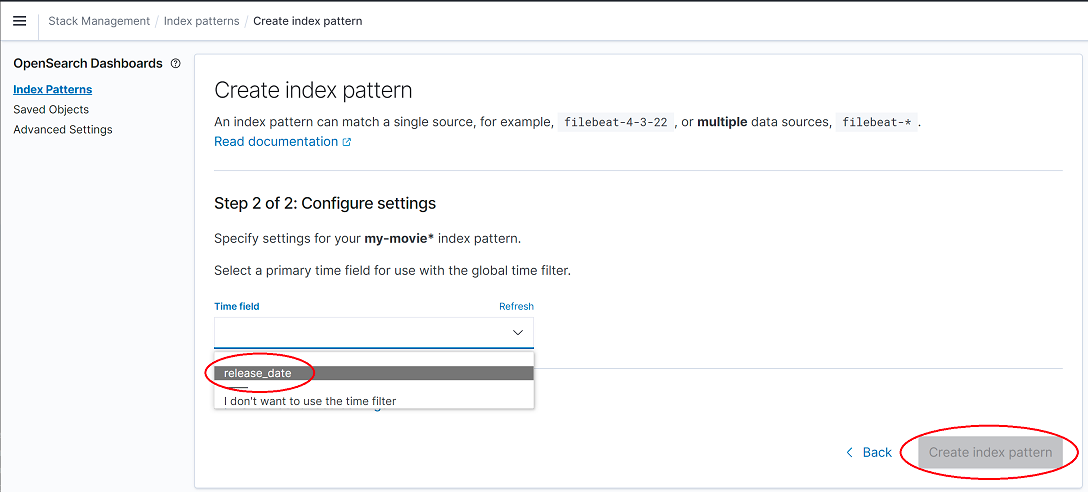
다시 discover 메뉴로 돌아갑니다.
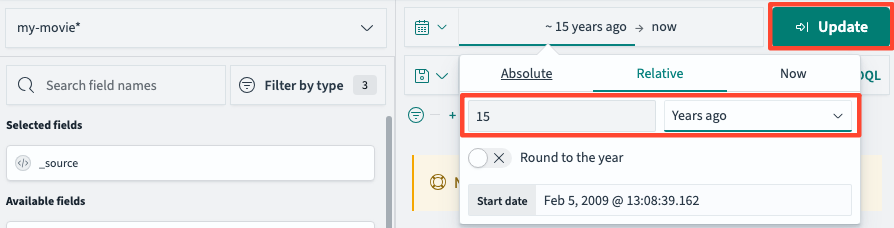
히스토그램을 통해 데이터를 시간 순으로 시작적으로 확인할 수 있습니다.
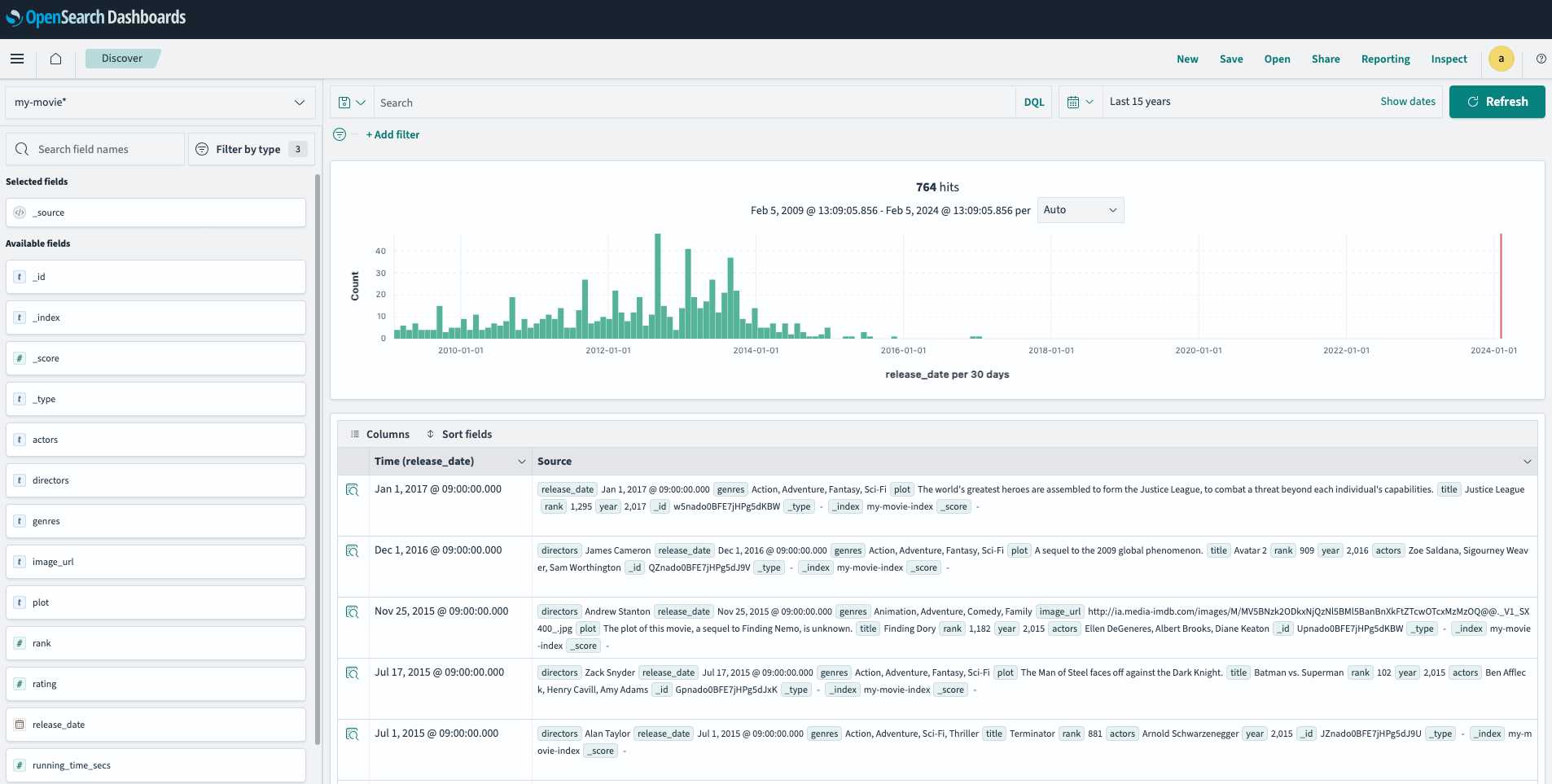
단어 검색, 특정 카테고리 검색과 특정 필터를 걸어 검색이 가능합니다.franco
directors: franco
NOT genres: [drama, action, comedy]
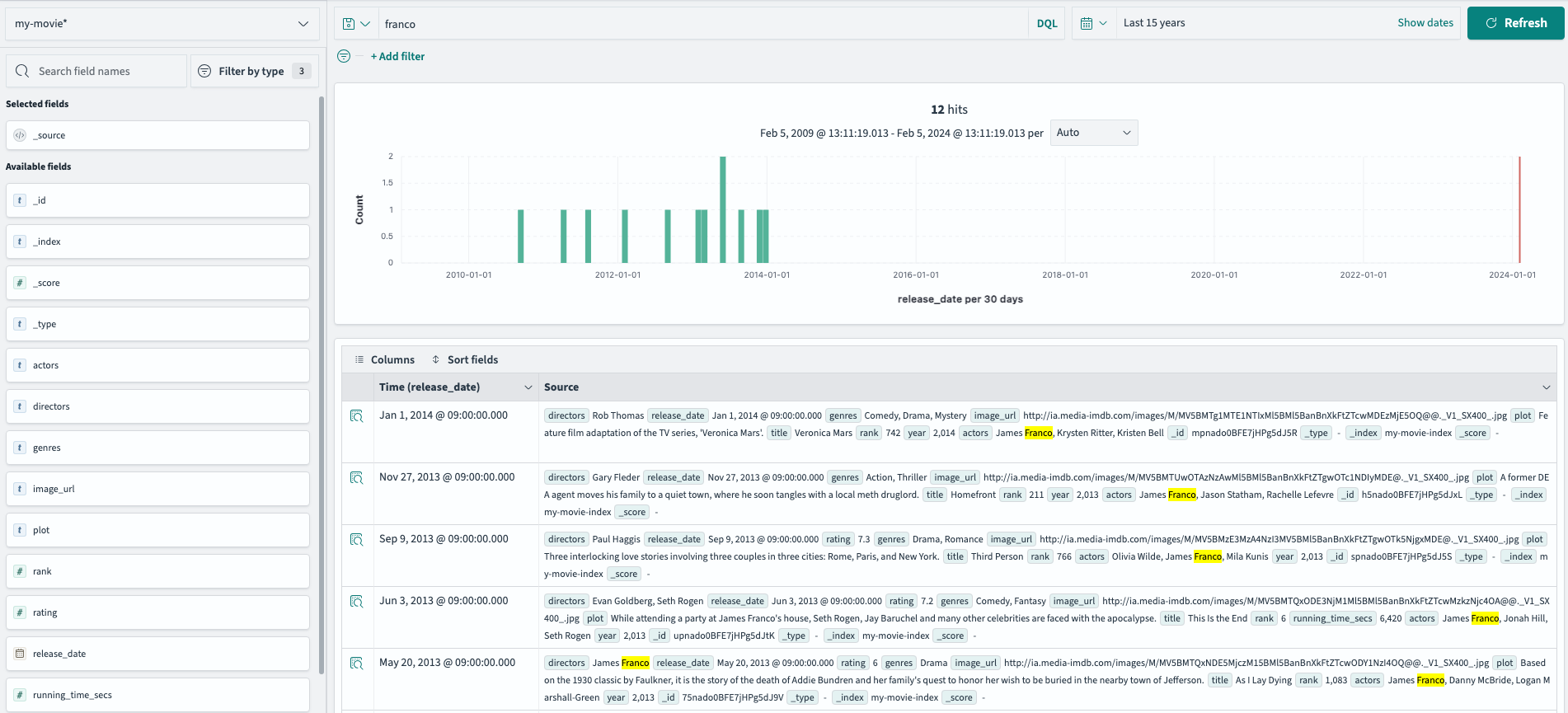
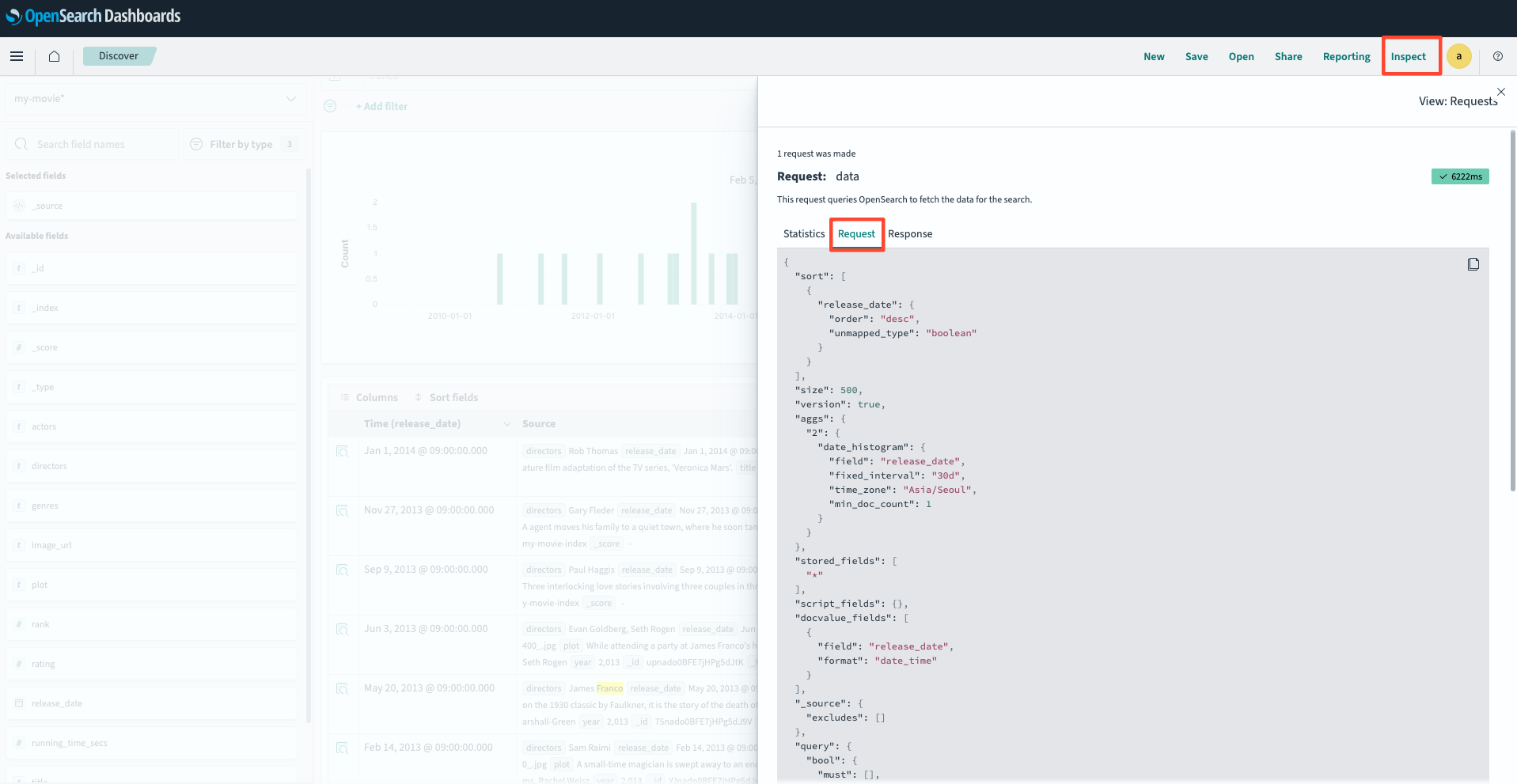
Inspect > Request를 통해 실제 쿼리로 가져와 Devtool로 실행하여 테스트도 가능합니다.
보안 & 이상 감지
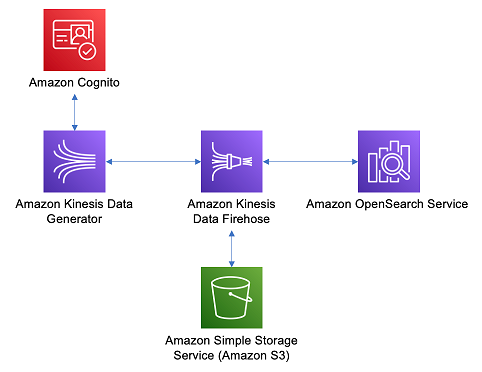
분석을 위해 웹 로그를 수집하고 Amazon OpenSearch Service의 이상 감지를 설정하여 이상 동작을 감지할 수 있습니다.해당 데이터의 세분화된 엑세스 제어를 설정하여 특정 문서 및 인덱스에 대한 차등 엑세스를 제공할 수 있습니다.
Data Pipeline 설정
- Data Pipeline 설정
- 변경사항
Stack Management에서Dashboards Management로 변경됨
- 변경사항
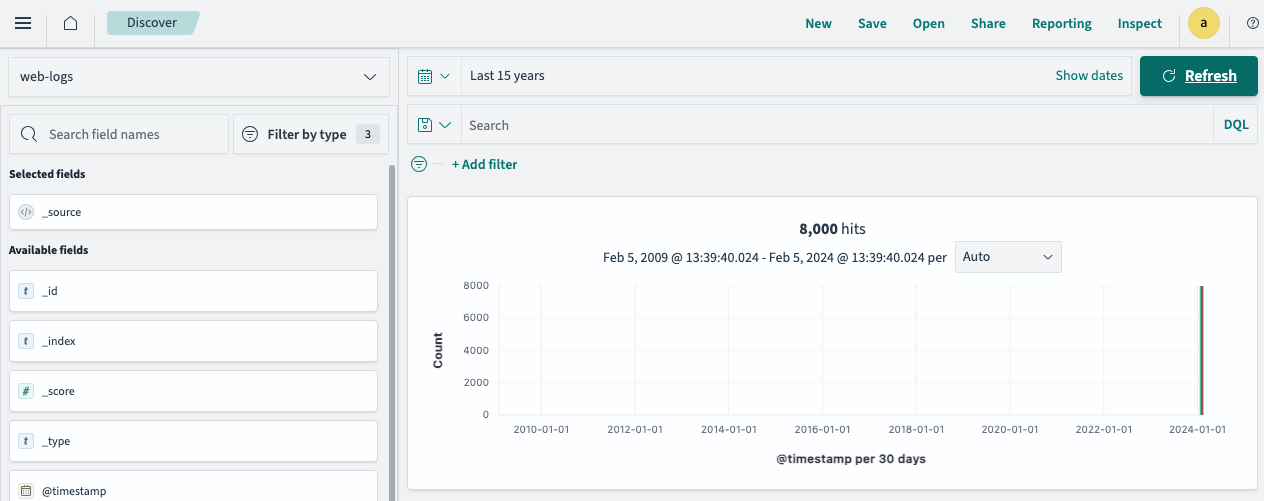
이상 감지
데이터에서 이상 탐지를 수행할 수도 있습니다. 이를 통해 OpenSearch는 시간이 지남에 따라 데이터 패턴을 '학습'하여 특정 임계값이나 경고를 미리 정의하지 않고도 잠재적으로 비정상적인 상황을 경고할 수 있습니다.로그 스트림에서 오류를 모니터링하는 감지기를 설정합니다. http 상태 코드를 사용하여 먼저 대부분의 200 상태 코드가 있는 데이터를 전송합니다. 그런 다음 200 절반과 5xx/4xx 코드 절반을 전송하도록 템플릿을 변경합니다. OpenSearch는 먼저 일반적인 대다수 200 상태 코드를 학습합니다. 오류 코드를 추가하면 이상 탐지기 트리거가 표시됩니다.
Detector 설정

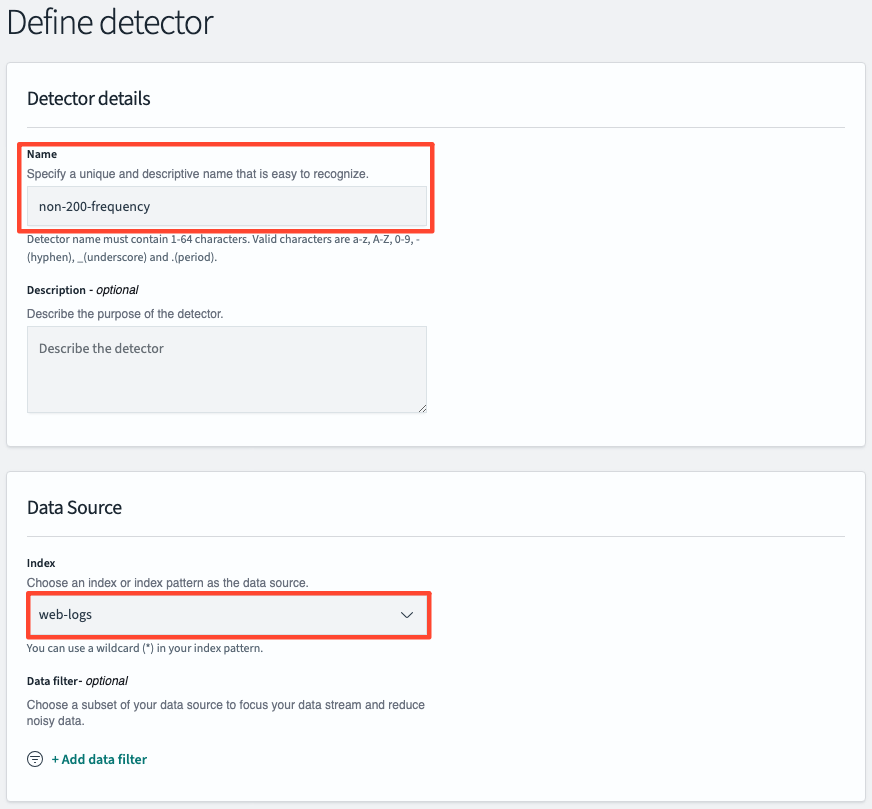
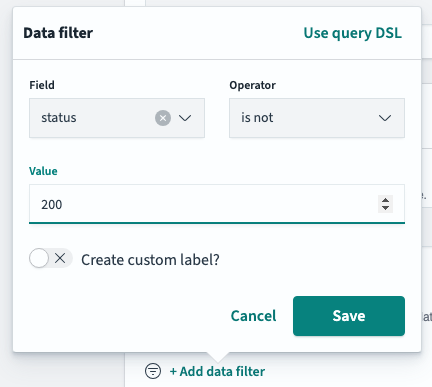
추가적인 데이터 필터 추가
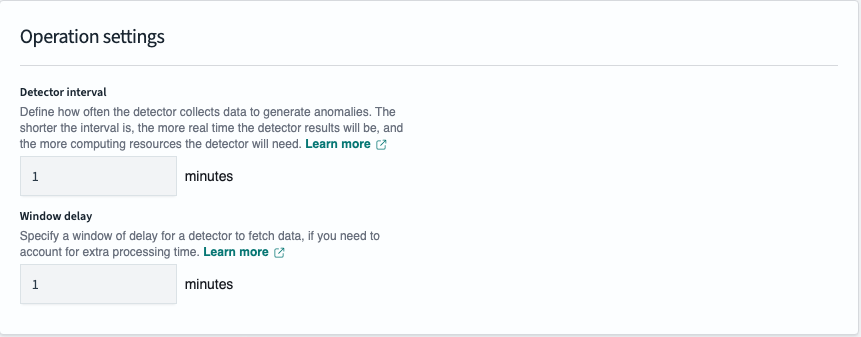
- Detector interval
- anomaly detector가 데이터를 수집하여 이상 현상을 생성하는 빈도를 정의합니다. 이것은 기본적으로 데이터를 얼마나 자주 평가할 것인지를 결정합니다.
- 1분으로 설정한 경우 1분마다 데이터를 평가합니다.
- Window Delay
- 데이터 소스에 따라 데이터가 수집되고 처리되는 데 일정 시간이 걸릴 수 있습니다.
예를 들어, 로그 데이터가 처리되고 사용 가능해지기까지 시간이 필요할 수 있습니다. Window delay를 설정함으로써, detector는 이러한 지연을 고려하여 최신 데이터를 기반으로 분석을 수행할 수 있습니다. - 탐지기가 2시에 동작한다고 가정하면 탐지기는 1시 50분부터 2시까지 마지막 10분간의 데이터를 얻으려고 시도하지만, 1분 지연으로 인해 9분의 데이터만 얻고 1시 59분부터 2시까지의 데이터를 놓친다. 창 지연을 1분으로 설정하면 간격 창이 1:49~1:59로 이동하므로 감지기는 감지기 간격 시간의 10분을 모두 차지합니다.
- 데이터 소스에 따라 데이터가 수집되고 처리되는 데 일정 시간이 걸릴 수 있습니다.
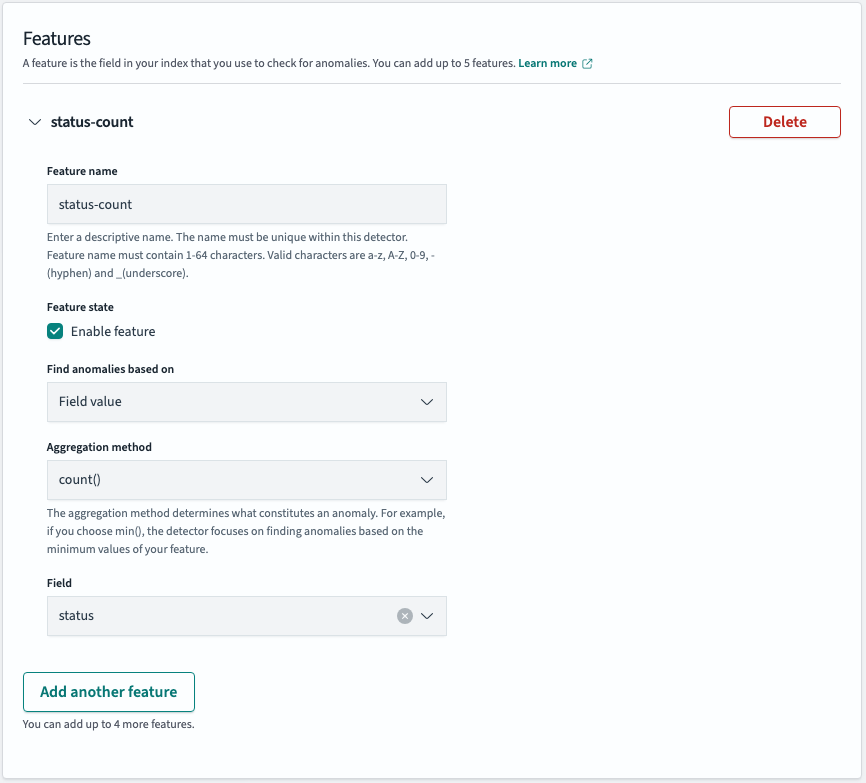
이상 여부를 탐지할 필드를 설정합니다.이후 이상 탐지기를 만들어 초기화합니다.
감지기가 초기화되는 동안 시간이 걸릴 수 있습니다.
"weights": [0.5,0.25,0.25],
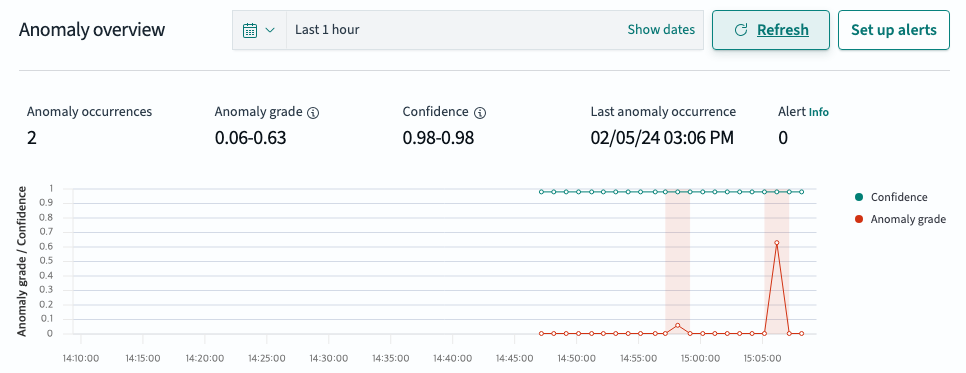
"data": ["200","404","503"]이상탐지가 되는것을 확인할 수 있습니다. 데이터의 크기를 늘리면 더 쉽게 유의미한 값을 확인할 수 있습니다.
보안과 역할
restricted-user 를 생성합니다.restricted-role을 생성하고 user와 매핑시킨 뒤 시크릿 탭으로 해당 유저의 정보로 로그인합니다.
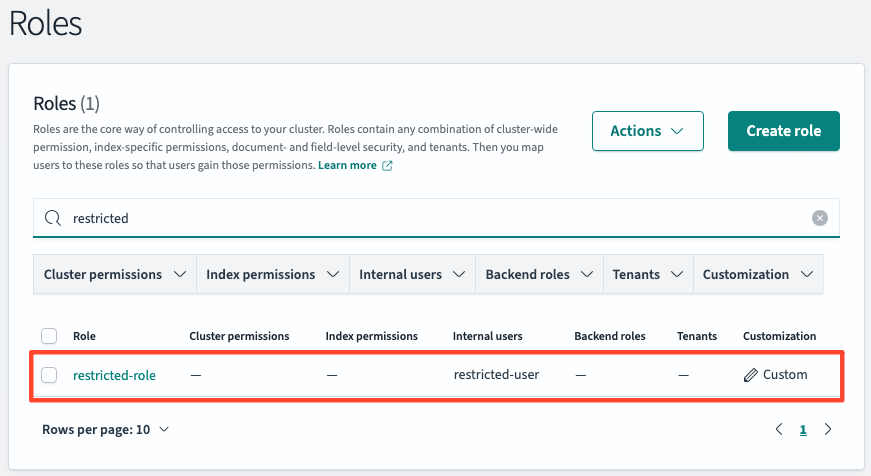
권한이 없어 데이터를 조회할 수 없다는 것을 확인할 수 있습니다.
GET _search
{
"query": {
"match_all": {}
}
}
{
"error": {
"root_cause": [
{
"type": "security_exception",
"reason": "no permissions for [indices:data/read/search] and User [name=restricted-user, backend_roles=[], requestedTenant=__user__]"
}
],
"type": "security_exception",
"reason": "no permissions for [indices:data/read/search] and User [name=restricted-user, backend_roles=[], requestedTenant=__user__]"
},
"status": 403
}권한 추가
- Edit Role
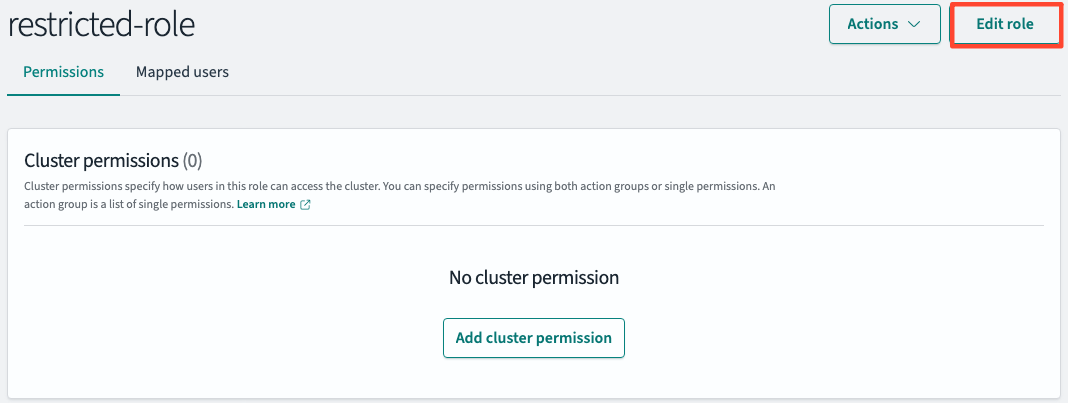
Index>web-log*/Index permissions >data-access정보를 입력하고 update합니다.
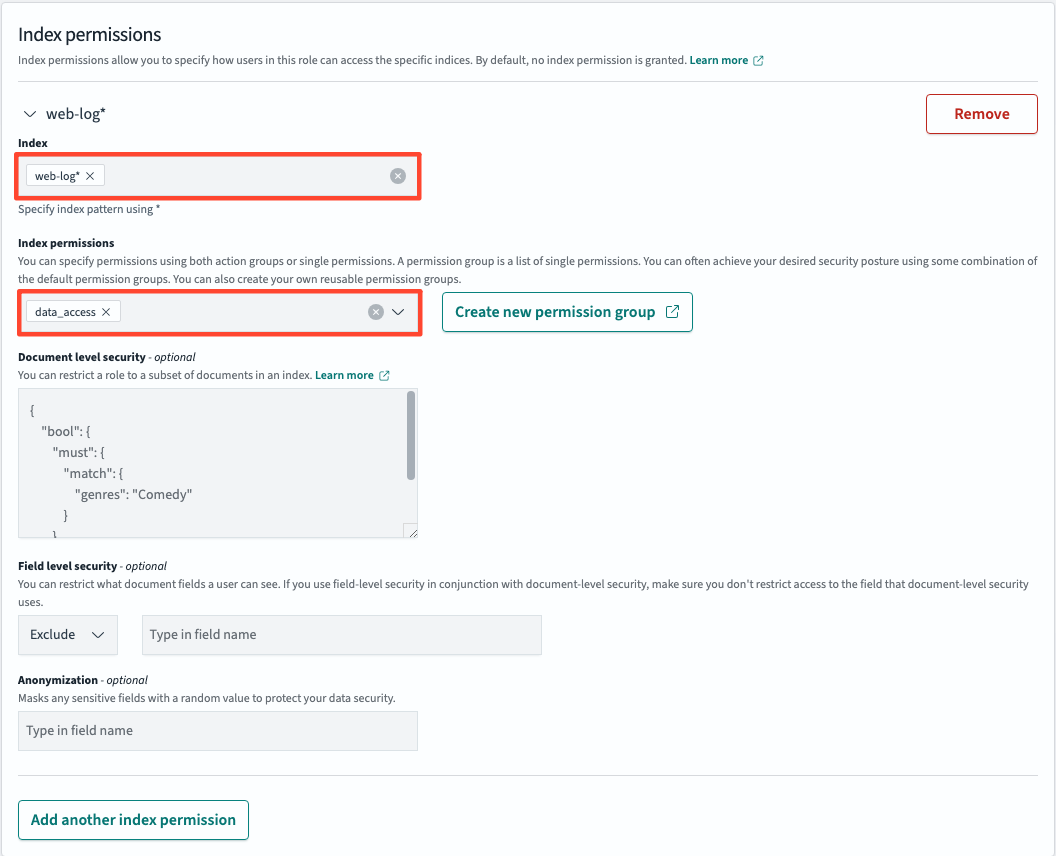
web-logs에 대한 권한을 추가했기 때문에 쿼리를 통한 데이터 조회가 가능합니다.

고급 권한
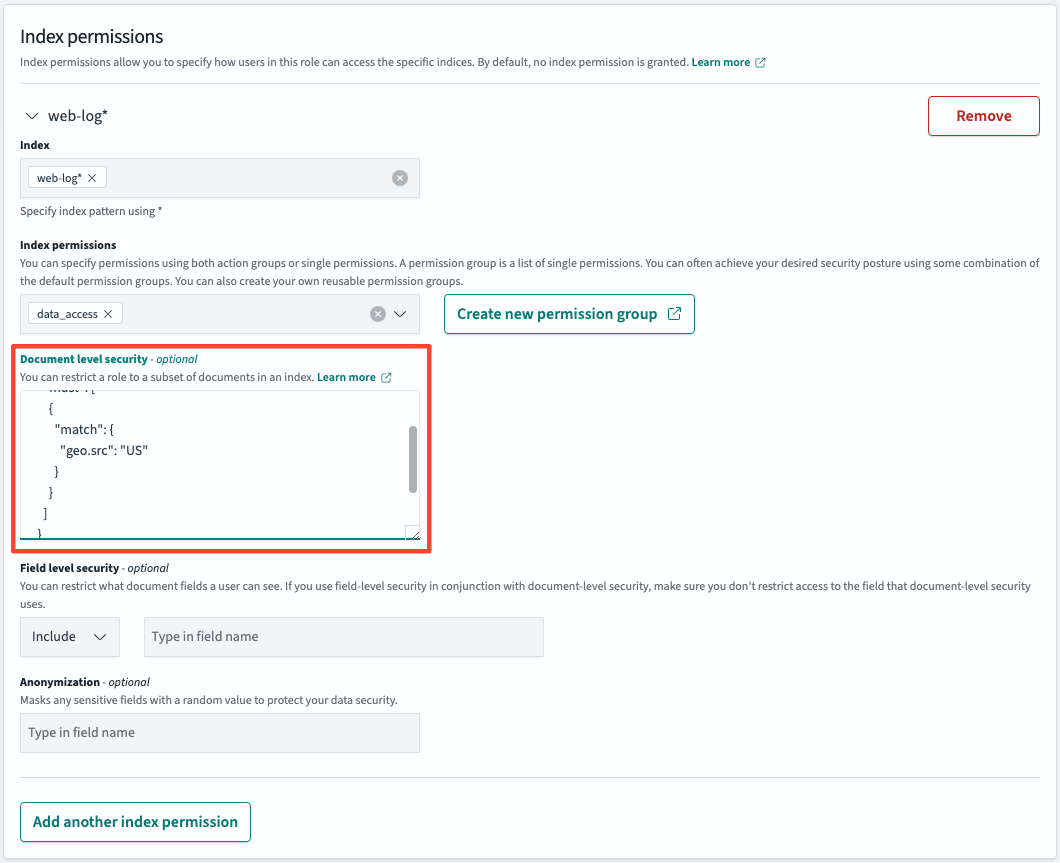
문서 수준 보안
- Document level security 섹션에 아래 데이터로 수정하고 Update합니다
{
"bool": {
"must": [
{
"match": {
"geo.src": "US"
}
}
]
}
}
- 이전에 실행했던 쿼리를 재실행합니다.

특정 데이터에 관한 조회 권한으로 수정하였기 때문에 조회되는 데이터가 현저히 작아진 것을 확인할 수 있습니다. 반환되는 유일한 문서는 geo.src = US인 문서이며 문서에 대한 접근 권한을 제어하기 때문에 문서 수준 보안이라고 합니다.
필드 수준 보안
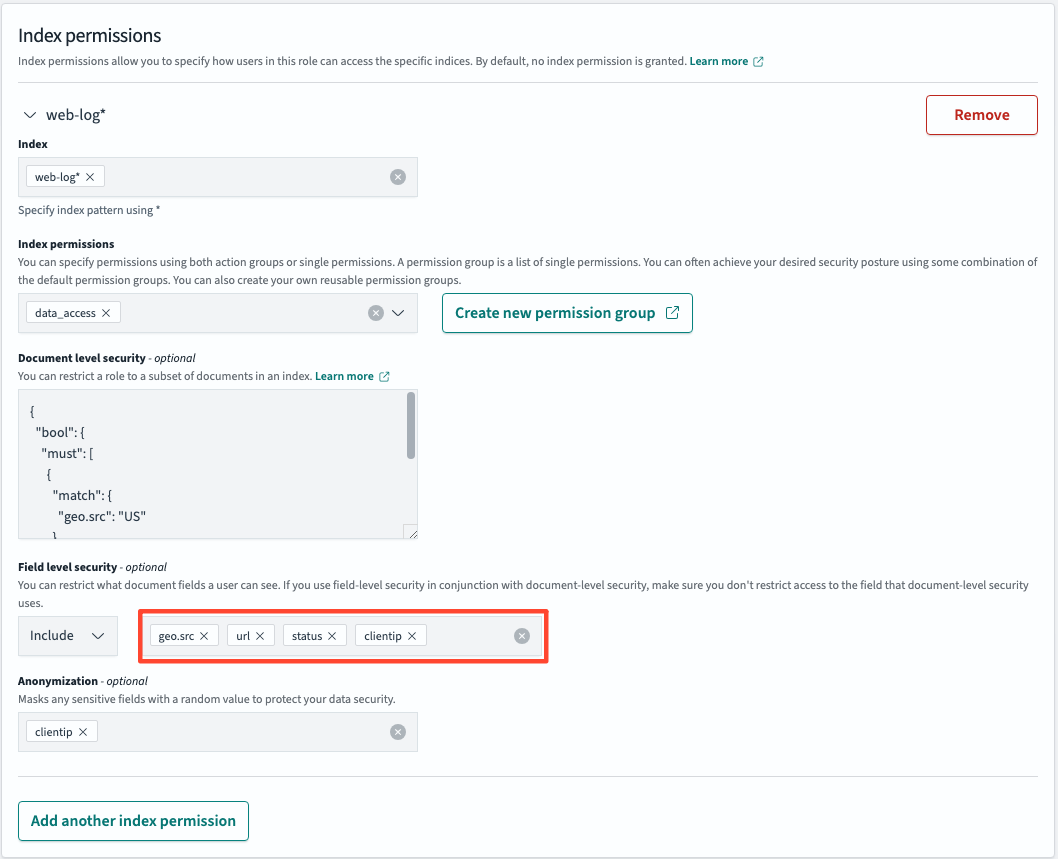
GET web-logs/_search
{
"query": {
"match_all": {}
}
}우리가 지정한 단위로 데이터가 출력되는 것을 확인할 수 있고 동시에 민감한 데이터는 암호화되어 출력되는 것을 확인할 수 있습니다. {
"_index": "web-logs",
"_id": "49648973593946054466555703840294716796745557346931965954.0",
"_score": 2,
"_source": {
"geo": {
"src": "US"
},
"clientip": "243a402b6b8a853a315d29b73ed6e4c802bb3223943486141fc6356e481dfd8c",
"url": "https://jarrell.com",
"status": 200
}
},감사 로그 모니터링
- AWS OpenSearch > 로그 > 감사 로그 선택 후 활성화를 클릭합니다.
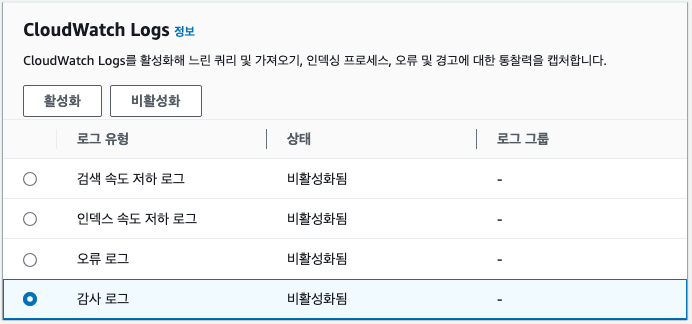
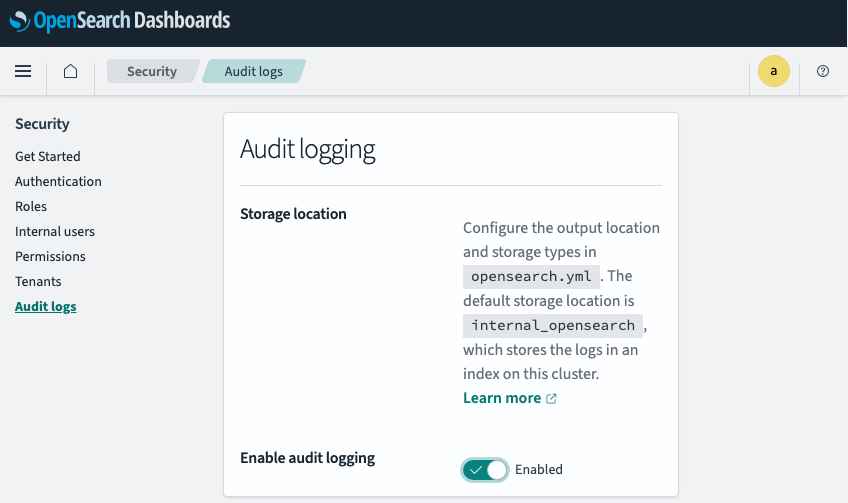
감사 로그 설정으로 넘어가면 다시 활성화를 클릭합니다.
- Opensearch Dashboards > Security > Audit logs로 이동해서 Enable audit logging 옵션을 활성화합니다.
- Compliance settings 옵션을 설정합니다.

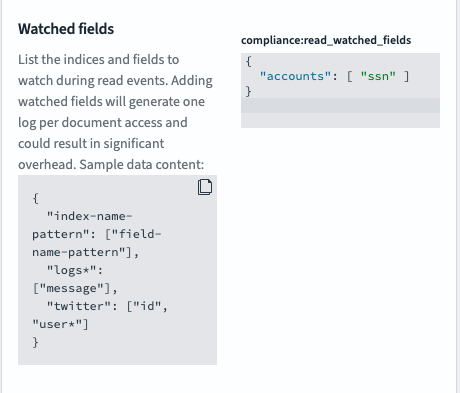
{
"accounts": [ "ssn" ]
}
compliance\:write_watched_indices에 accounts를 추가하고 save를 클릭합니다.

- 감사 로그 생성
POST accounts/_doc/sampleuser
{
"ssn": "123-456-7890",
"name": "John Doe"
}PUT accounts/_doc/sampleuser
{
"ssn": "123-456-7890",
"name": "Jane Doe"
}GET accounts/_searchCloudWatch에서 모든 로그 이벤트를 확인할 수 있습니다.
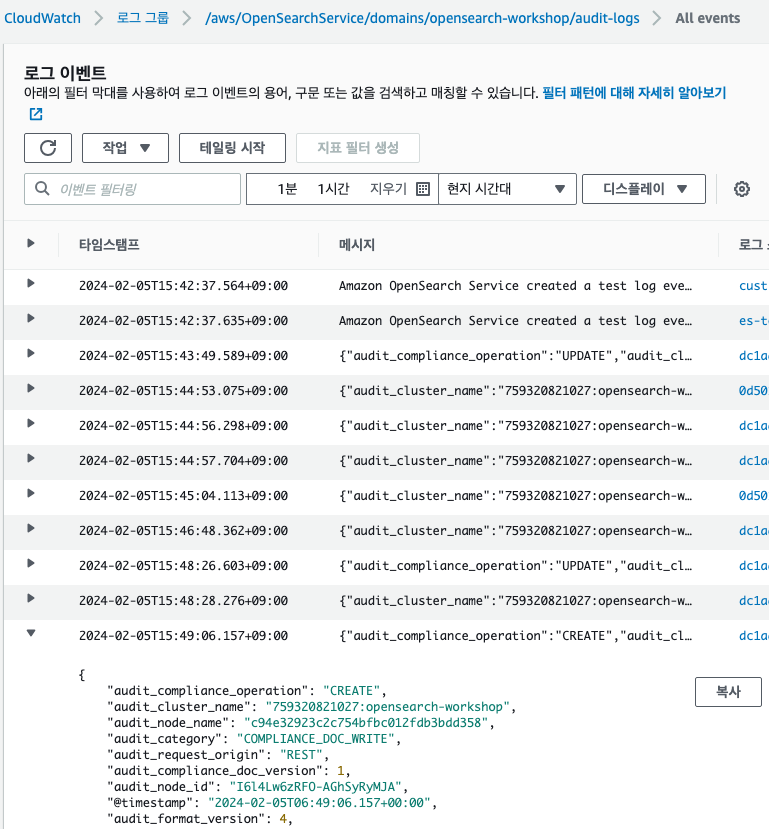
대시보드 & 시각화
- Dashboards > Create new dashboard > Create new 클릭
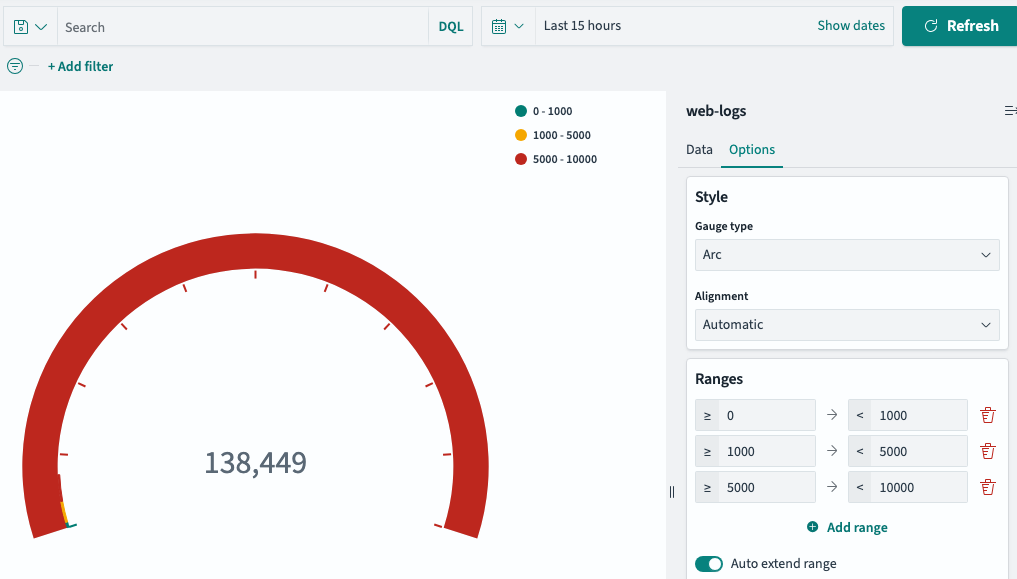
Gauage
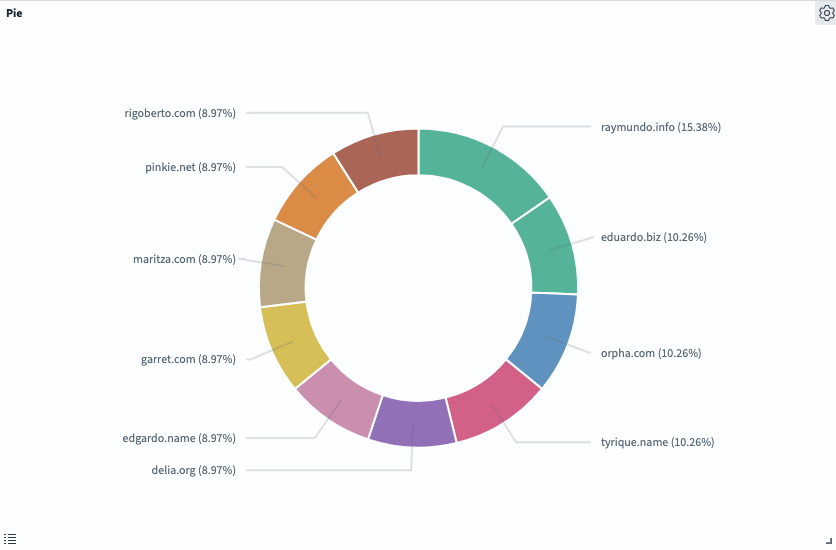
Pie
Control
Heatmap
추가적인 기능들
Highlighting
생성된 결과 집합에는 검색 요청에 지정된 pre_ 및 post_ 태그를 기반으로 하는 highlight 태그가 있습니다.일치하는 항목에 하이라이트 됩니다.
GET my-movie-index/_search
{
"query": { "match" : { "plot" : "faulkner" }},
"highlight" : {
"pre_tags" : ["<tag1>", "<tag2>"],
"post_tags" : ["</tag1>", "</tag2>"],
"fields" : {
"plot" : {}
}
}
}Mapping
매핑은 문서와 문서에 포함된 필드가 저장되고 인덱싱되는 방식을 정의하는 프로세스입니다.각 문서는 각각 고유한 데이터 유형이 있는 필드 모음입니다. 데이터를 매핑할 때, 문서와 관련된 필드 목록이 포함되도록 매핑 정의를 생성합니다.
GET my-movie-index/_mappingFuzzy 검색
퍼지 검색은 검색어를 기반으로 유사한 용어를 포함하는 문서를 반환하는 검색 패턴입니다. 유사한 용어를 찾으려면 Levenshtein edit distance로 측정하는 방법을 따르게 됩니다.
GET my-movie-index/_search
{
"query": {
"fuzzy": {
"title": {
"value": "dark",
"fuzziness": "AUTO",
"max_expansions": 50,
"prefix_length": 0,
"transpositions": true,
"rewrite": "constant_score"
}
}
}
}텍스트 분석 및 스테밍
이 기능은 구조화되지 않은 자유 텍스트를 최적화된 구조화 형식으로 변환합니다. 이 기능은 텍스트 인덱스 및 쿼리를 개선하기 위한 것입니다.텍스트 분석은 NLP 방법을 사용하여 이러한 의미론적 관계를 생성합니다. 이러한 방법 중 하나는 토큰화로 개념 루트를 기반으로 토큰 집합의 내용을 나눕니다. 그러나 이러한 토큰에는 여전히 대소문자 구분 또는 의미론적 관계 부족과 같은 몇 가지 제한 사항이 있습니다.이러한 제한을 완화하기 위해 텍스트 분석은 스테밍 방법으로 해당 토큰을 표준화합니다. 어간 추출은 단어와 그 변종을 어근 형태로 줄여 더 넓은 용어 검색을 가능하게 하는 기술입니다. 스테밍은 데이터의 언어에 따라 달라지며 비현실적인 단어를 일반적인 용어로 생성할 수 있습니다.텍스트를 분석하여 검색시 유사한 데이터를 가져옵니다.
PUT /new-movie-index
{
"settings": {
"number_of_shards": 1,
"number_of_replicas": 1,
"analysis": {
"analyzer": {
"english_exact": {
"tokenizer": "standard",
"filter": [
"lowercase"
]
}
}
}
},
"mappings": {
"properties": {
"id": { "type": "keyword" },
"actors": {
"type": "text",
"fields": {
"keyword": { "type": "keyword" }
}
},
"directors": {
"type": "text",
"fields": {
"keyword": { "type": "keyword" }
}
},
"genres": {
"type": "text",
"fields": {
"keyword": { "type": "keyword" }
}
},
"title": { "type": "text" },
"location": { "type": "geo_point" },
"clicks": { "type": "long" },
"image_url": { "type": "keyword" },
"plot": {
"type": "text",
"analyzer": "english",
"fields": {
"exact": {
"type": "text",
"analyzer": "english_exact"
}
}
},
"price": { "type": "float" },
"purchases": { "type": "long" },
"rank": { "type": "long" },
"rating": { "type": "float" },
"release_date": { "type": "date" },
"running_time_secs": { "type": "long" },
"year": { "type": "long" }
}
}
}
POST _reindex
{
"source": {
"index": "my-movie-index"
},
"dest": {
"index": "new-movie-index"
}
}#
GET my-movie-index/_search
{
"query": {
"simple_query_string": {
"fields": [ "plot" ],
"query": "struggling"
}
}
}
GET new-movie-index/_search
{
"query": {
"simple_query_string": {
"fields": [ "plot" ],
"query": "struggling"
}
}
}Faceting
검색과 같은 사용자 인터페이스를 제공할 때, 집계를 사용하여 사용자가 결과 집합을 좁히는 데 사용할 수 있도록 제공합니다.
여러분의 애플리케이션은 일반적으로 페이지의 왼쪽에 일반적인 용어와 개수를 표시합니다. 사용자는 이 값을 클릭하여 결과 집합을 "드릴인"하여 클릭한 값을 필터링할 수 있습니다. 이를 일반적으로 패싯이라고 합니다.

POST my-movie-index/_search
{
"query": {
"match": {
"plot": "wars"
}
},
"aggs": {
"Rating Filter": {
"range": {
"field": "rating",
"ranges": [
{
"from": 1,
"to": 3
},
{
"from": 3,
"to": 6
},
{
"from": 6,
"to": 10
}
]
}
}
}
}언어 분석기
언어별 분석을 위해 미리 패키지된 플러그인을 제공합니다. 아래 명령을 실행하여 OpenSearch 도메인에 배포된 모든 플러그인을 나열할 수 있습니다.GET _cat/plugins?v
POST kr-movie-index/_doc/1
{
"plot_en" : "Faced with an enemy that even Odin and Asgard cannot withstand, Thor must embark on his most perilous and personal journey yet, one that will reunite him with Jane Foster and force him to sacrifice everything to save us all.",
"plot": "오딘과 아스가르드조차 버틸 수 없는 적에 맞서 토르는 가장 위험하고 개인적인 여정을 시작해야 합니다. 그 여정은 그를 제인 포스터와 재회시키고 우리 모두를 구하기 위해 모든 것을 희생하도록 강요할 것입니다.",
"title": "토르 : 다크 월드",
"title_en" : "Thor: The Dark World"
}
동의어 및 사전
Amazon OpenSearch Service를 사용하면 불용어 및 동의어와 같은 사용자 지정 사전 파일을 업로드하여 클러스터에서 사용할 수 있습니다. 이러한 유형의 파일에 대한 일반적인 용어는 패키지입니다. 사전 파일은 OpenSearch가 자주 사용되는 특정 단어를 무시하거나 "냉동 커스터드", "젤라토", "아이스크림"과 같은 용어를 동등하게 취급하도록 지시하여 검색 결과를 향상시킵니다.
PUT my-synonyms-index
{
"settings": {
"index": {
"analysis": {
"analyzer": {
"my_analyzer": {
"type": "custom",
"tokenizer": "standard",
"filter": ["my_filter"]
}
},
"filter": {
"my_filter": {
"type": "synonym",
# analyzers/F136422711
"synonyms_path": **<synonyms_path>**,
"updateable": true
}
}
}
}
},
"mappings": {
"properties": {
"id": { "type": "keyword" },
"actors": {
"type": "text",
"fields": {
"keyword": { "type": "keyword" }
}
},
"directors": {
"type": "text",
"fields": {
"keyword": { "type": "keyword" }
}
},
"genres": {
"type": "text",
"fields": {
"keyword": { "type": "keyword" }
}
},
"title": { "type": "text" },
"location": { "type": "geo_point" },
"clicks": { "type": "long" },
"image_url": { "type": "keyword" },
"plot": {
"type": "text",
"analyzer": "standard",
"search_analyzer": "my_analyzer",
"fields": {
"exact": {
"type": "text",
"analyzer": "standard",
"search_analyzer": "my_analyzer"
}
}
},
"price": { "type": "float" },
"purchases": { "type": "long" },
"rank": { "type": "long" },
"rating": { "type": "float" },
"release_date": { "type": "date" },
"running_time_secs": { "type": "long" },
"year": { "type": "long" }
}
}
}동의어를 가져오게 됩니다.
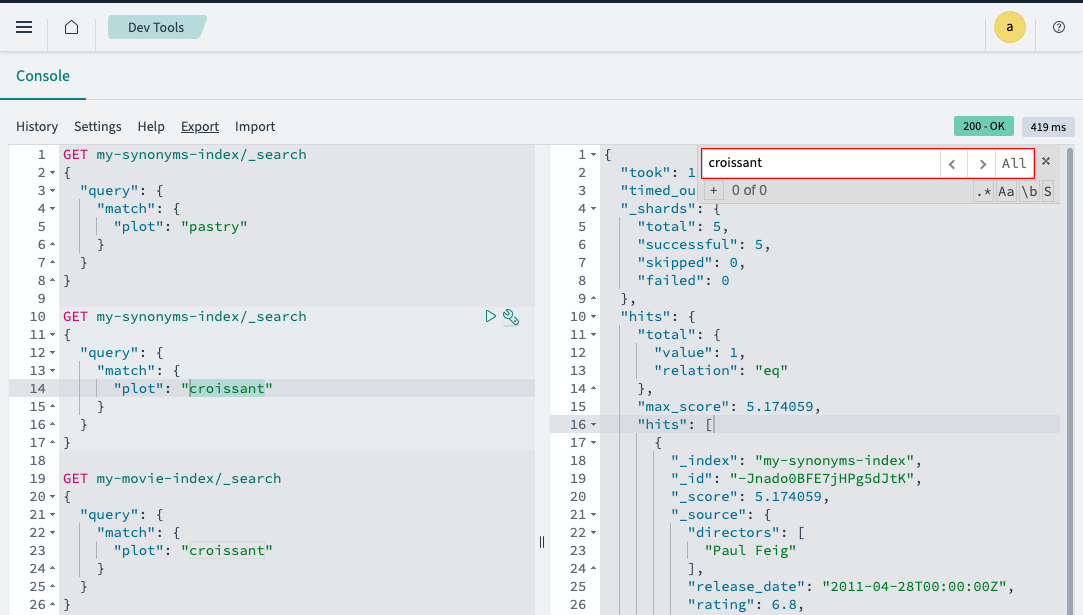
UltraWarm Nodes
UltraWarm은 Amazon S3에 데이터를 저장하는 동시에 AWS Nitro 시스템에 특별히 구축된 고도로 최적화된 노드를 사용하여 해당 데이터를 캐시, 프리페치, 쿼리합니다. 이를 통해 다음을 수행할 수 있습니다.
- 단일 Amazon OpenSearch Service 클러스터에서 최대 3PB의 데이터를 유지하면서 기존 OpenSearch 스토리지 계층에 비해 GB당 비용을 거의 90%까지 절감합니다.
- 아카이브에서 복원하는 데 몇 시간 또는 며칠을 소비할 필요 없이 최근(주), 과거(월 또는 년) 로그 데이터 모두에 대해 빠른 대화형 분석을 실행합니다.
- 대시보드 인터페이스를 통해 최근 및 과거 로그 데이터 모두에서 쉽게 쿼리하고 시각화하여 성능 문제를 신속하게 식별하고 해결할 수 있습니다.
에러
- 메시지
indices.query.bool.max_clause_count is not a valid query count value. Please enter a integer value between 1 and 2147483647 (inclusive).

고급 설정을 입력해줘야합니다.
- 도메인 에러의 경우
Dashboards URL은 특히 데이터 시각화 및 분석을 위한 사용자 친화적인 도구인 OpenSearch Dashboards 웹 인터페이스에 액세스하기 위한 것입니다. 도메인 엔드포인트는 OpenSearch 클러스터의 기능에 프로그래밍 방식으로 액세스하기 위한 것이며, OpenSearch API를 통해 데이터 조작 및 쿼리 작업을 허용합니다.
- 마우스 커서가 쿼리에 포함되어 있어야합니다.
- 중간에 504 Gateway가 뜨는 현상
-
Deleting resources associated with the old environment. - 갑자기 리소스가 정리되면서 접속이 되지 않는 현상이 발생
- System Manager Run Shell Command → 도메인 엔드포인트(VPC)를 재정의하니 해결되었습니다.
-
- 인덱스 조회문
GET my-movie-index
{
"acknowledged": true,
"shards_acknowledged": true,
"index": "my-movie-index"
}


