[Neo4j] 외부 데이터셋을 활용한 GraphDB 간단 테스트
간단하게 GraphDB를 테스트해보고 정리하였습니다.
![[Neo4j] 외부 데이터셋을 활용한 GraphDB 간단 테스트](https://images.unsplash.com/photo-1523961131990-5ea7c61b2107?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDcwfHxHcmFwaHxlbnwwfHx8fDE3NTQwMDQ4Njd8MA&ixlib=rb-4.1.0&q=80&w=1200)
개요
이전 문서에서는 기본 데이터셋을 활용하여 구현하였습니다.
이번 문서에서는 Kaggle에서 데이터를 다운로드하여 테스트해보려고 합니다.
15,000 Music Tracks - 19 Genres (w/ Spotify Data)
이 데이터셋은 1923년부터 2023년까지 1세기에 걸친 음악 역사를 아우르는 3,083명의 아티스트의 15,150개 클래식 히트곡을 포괄적으로 수집한 것입니다. 이 다양한 데이터셋은 19개의 구별되는 장르로 나뉘어 있어, 다양한 시대와 스타일에 걸친 대중음악의 진화를 보여줍니다. 데이터셋의 각 트랙은 Spotify 오디오 특성으로 풍부해져, 음향 특성, 리듬, 템포 및 기타 음악적 특징에 대한 상세한 통찰을 제공합니다. 이는 이 데이터셋을 트렌드 탐색과 장르 비교를 위한 귀중한 자료로 만들 뿐만 아니라, 다양한 시대와 장르에 걸쳐 클래식 히트곡을 정의하는 음향적 특성을 분석하는 데에도 유용하게 합니다
| Track | Artist | Year | Duration | Time_Signature | Danceability | Energy | Key | Loudness | Mode | Speechiness | Acousticness | Instrumentalness | Liveness | Valence | Tempo | Popularity | Genre | |
| 0 | Hey Jack Kerouac | 10,000 Maniacs | 1987 | 206413 | 4 | 0.616 | 0.511 | 6 | -15.894 | 1 | 0.0279 | 0.03840 | 0.000000 | 0.1500 | 0.604 | 132.015 | 40 | Alt. Rock |
| 1 | Like the Weather | 10,000 Maniacs | 1987 | 236653 | 4 | 0.770 | 0.459 | 1 | -17.453 | 1 | 0.0416 | 0.11200 | 0.003430 | 0.1450 | 0.963 | 133.351 | 43 | Alt. Rock |
| 2 | What's the Matter Here? | 10,000 Maniacs | 1987 | 291173 | 4 | 0.593 | 0.816 | 9 | -7.293 | 1 | 0.0410 | 0.00449 | 0.000032 | 0.0896 | 0.519 | 99.978 | 12 | Alt. Rock |
| 3 | Trouble Me | 10,000 Maniacs | 1989 | 193560 | 4 | 0.861 | 0.385 | 2 | -10.057 | 1 | 0.0341 | 0.15400 | 0.000000 | 0.1230 | 0.494 | 117.913 | 47 | Alt. Rock |
| 4 | Candy Everybody Wants | 10,000 Maniacs | 1992 | 185960 | 4 | 0.622 | 0.876 | 10 | -6.310 | 1 | 0.0305 | 0.01930 | 0.006840 | 0.0987 | 0.867 | 104.970 | 43 | Alt. Rock |
15,000 Music Tracks - 19 Genres (w/ Spotify Data)
총 18개의 컬럼을 가지며 각 컬럼은 다음과 같습니다.
- Track: 노래 제목
- Artist: 아티스트 이름
- Year: 발매 연도
- Duration: 노래 길이
- Time_Signature: 박자 (예: 4/4)
- Danceability: 춤추기 강도
- Energy: 에너지 레벨
- Key: 음악의 키
- Loudness: 음량
- Mode: 장조/단조
- Speechiness: 말하는 정도
- Acousticness: 어쿠스틱 사운드 정도
- Instrumentalness: 악기 사운드 정도
- Liveness: 라이브 공연 느낌 정도
- Valence: 긍정적인 분위기 정도
- Tempo: 템포 (BPM)
- Popularity: 인기도
- Genre: 장르
GraphDB(Neo4j) custom 데이터셋 테스트
Neo4j 생성
Your own data를 선택하고 생성합니다.
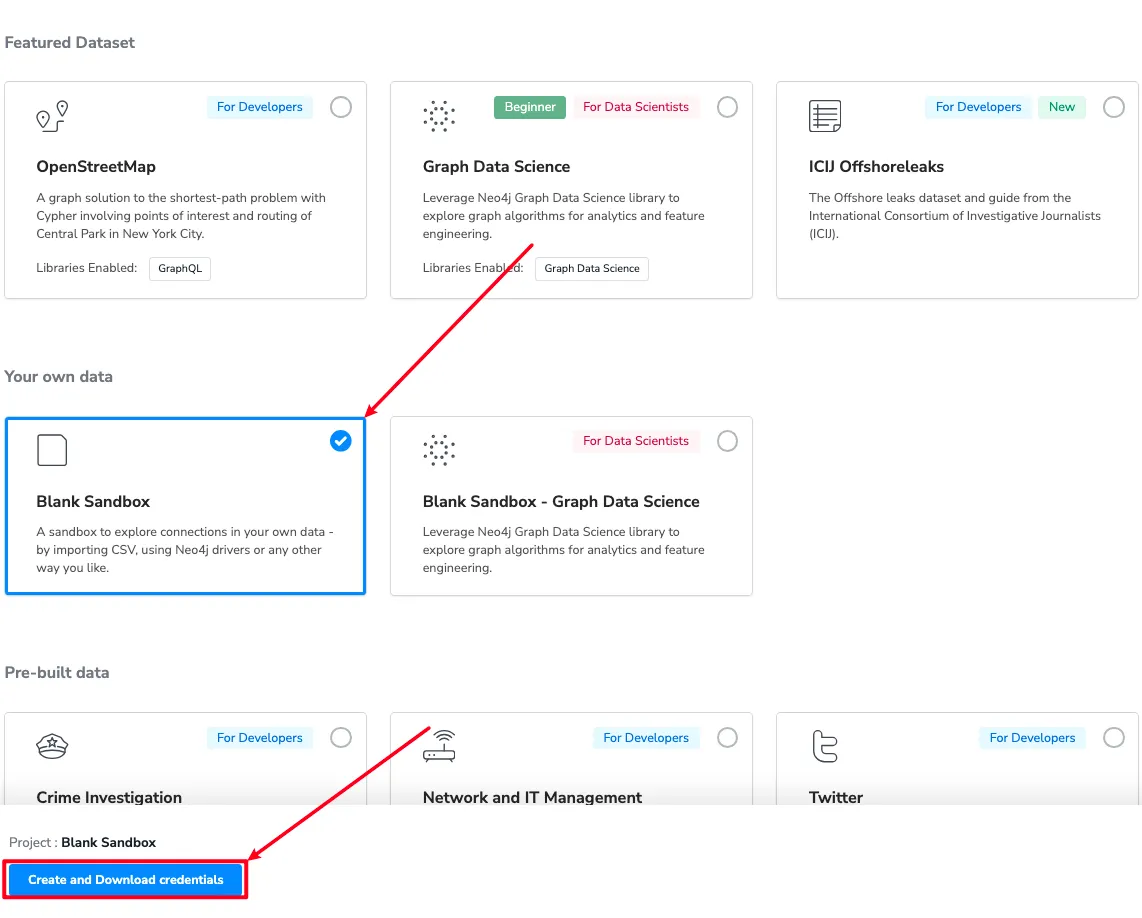
데이터 연결하기
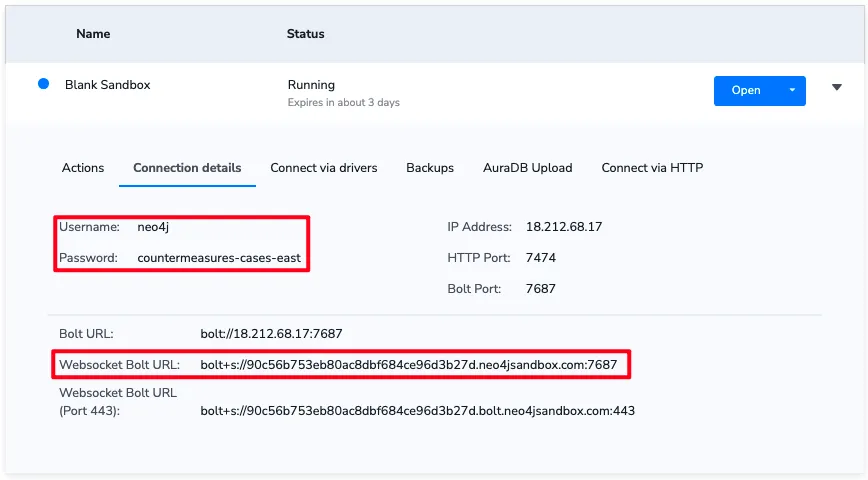
Neo4j에서는 web workspace를 지원하고 있으므로 해당 페이지에 접근하여 연결할 수 있습니다.
연결에는 Websocket Bolt가 필요하며 Username과 Password를 입력하면 연결됩니다.
연결되면 상단에 연결된 샌드박스 환경이 표시되며 Drag & Drop으로 데이터를 불러올 수 있습니다.
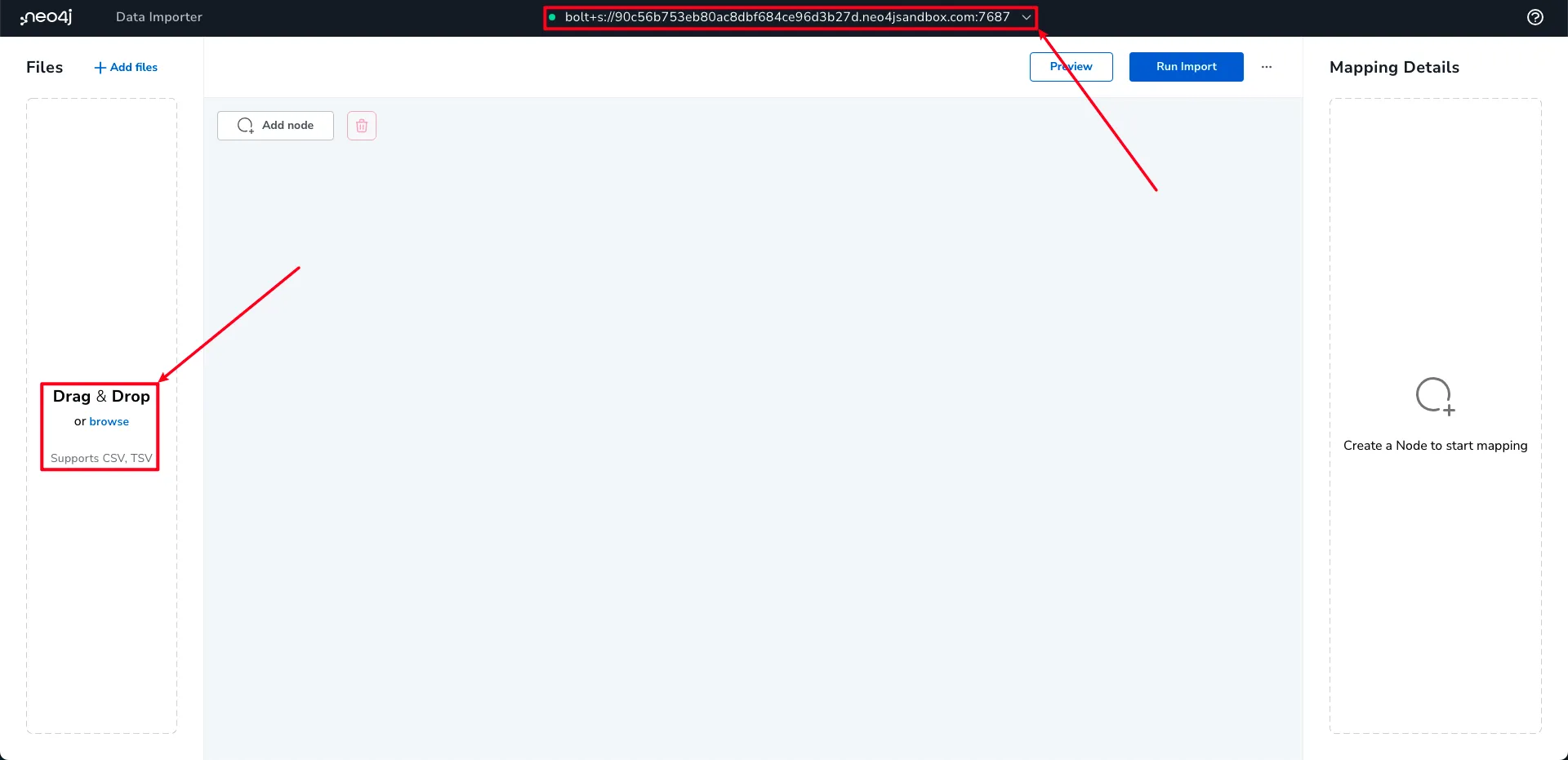
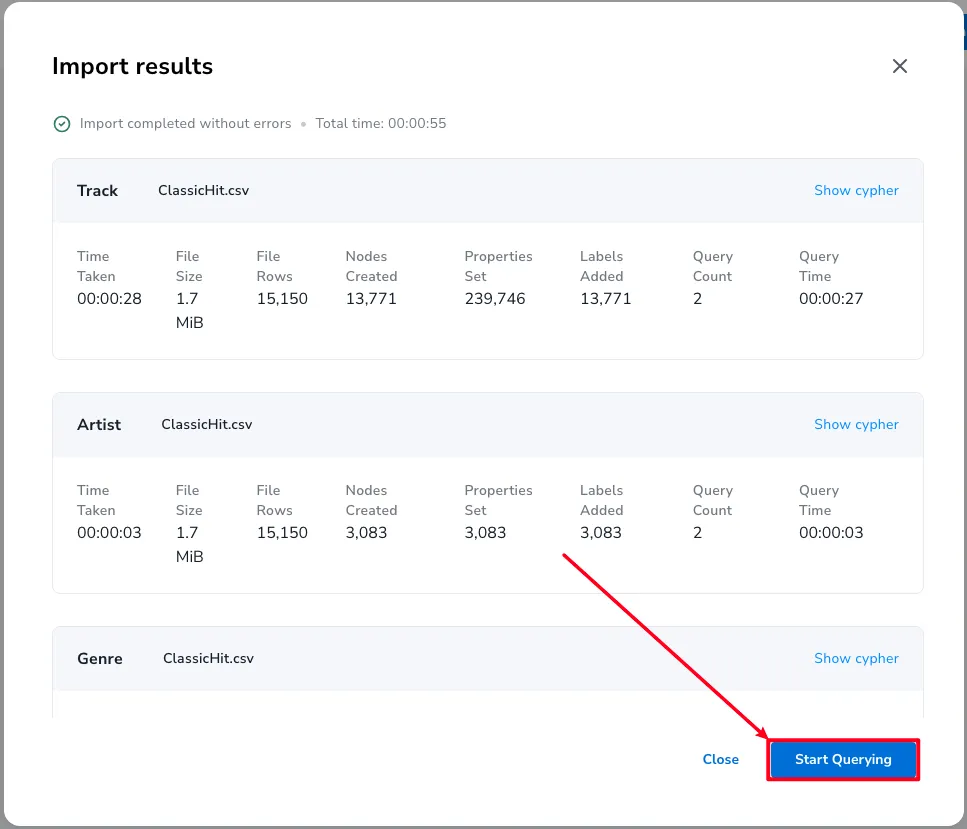
데이터를 저장했다면 그래프 모델 정의와 데이터를 노드와 관계로 매핑하여야합니다.
저는 해당 데이터를 간단하게 아래와 같은 노드와 관계로 표현하였습니다.
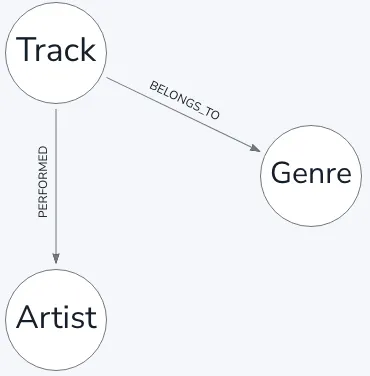
노드 생성 사이퍼입니다.
UNWIND $nodeRecords AS nodeRecord
WITH *
WHERE NOT nodeRecord.`Track` IN $idsToSkip AND NOT nodeRecord.`Track` IS NULL
MERGE (n: `Track` { `Track`: nodeRecord.`Track` })
SET n.`Year` = toInteger(trim(nodeRecord.`Year`))
SET n.`Duration` = toInteger(trim(nodeRecord.`Duration`))
SET n.`Time_Signature` = toInteger(trim(nodeRecord.`Time_Signature`))
SET n.`Danceability` = toFloat(trim(nodeRecord.`Danceability`))
SET n.`Energy` = toFloat(trim(nodeRecord.`Energy`))
SET n.`Key` = toInteger(trim(nodeRecord.`Key`))
SET n.`Loudness` = toFloat(trim(nodeRecord.`Loudness`))
SET n.`Mode` = toLower(trim(nodeRecord.`Mode`)) IN ['1','true','yes']
SET n.`Speechiness` = toFloat(trim(nodeRecord.`Speechiness`))
SET n.`Acousticness` = toFloat(trim(nodeRecord.`Acousticness`))
SET n.`Instrumentalness` = toFloat(trim(nodeRecord.`Instrumentalness`))
SET n.`Liveness` = toFloat(trim(nodeRecord.`Liveness`))
SET n.`Valence` = toFloat(trim(nodeRecord.`Valence`))
SET n.`Tempo` = toFloat(trim(nodeRecord.`Tempo`))
SET n.`Popularity` = toInteger(trim(nodeRecord.`Popularity`));
UNWIND $nodeRecords AS nodeRecord
WITH *
WHERE NOT nodeRecord.`Artist` IN $idsToSkip AND NOT nodeRecord.`Artist` IS NULL
MERGE (n: `Artist` { `Artist`: nodeRecord.`Artist` });
Load statement
UNWIND $nodeRecords AS nodeRecord
WITH *
WHERE NOT nodeRecord.`Genre` IN $idsToSkip AND NOT nodeRecord.`Genre` IS NULL
MERGE (n: `Genre` { `Genre`: nodeRecord.`Genre` });
관계 생성 사이퍼입니다.
UNWIND $relRecords AS relRecord
MATCH (source: `Track` { `Track`: relRecord.`Track` })
MATCH (target: `Artist` { `Artist`: relRecord.`Artist` })
MERGE (source)-[r: `PERFORMED`]->(target);
UNWIND $relRecords AS relRecord
MATCH (source: `Track` { `Track`: relRecord.`Track` })
MATCH (target: `Genre` { `Genre`: relRecord.`Genre` })
MERGE (source)-[r: `BELONGS_TO`]->(target);
다음과 같이 Metal 장르를 보유한 Artist를 조회하는 Cypher문을 실행하였습니다.
조회해보았을 땐 다음과 같이 출력되는 것을 확인할 수 있었습니다.
MATCH (g:Genre {Genre: "Metal"})<-[:BELONGS_TO]-(t:Track)-[:PERFORMED]->(a:Artist)
RETURN DISTINCT a.Artist
# 리턴
...
{
"keys": [
"a.Artist"
],
"length": 1,
"_fields": [
"Eric Clapton"
],
"_fieldLookup": {
"a.Artist": 0
}
},
...
Metal 장르를 보유한 사람의 수는 171명인 것을 확인할 수 있었습니다.
MATCH (g:Genre {Genre: "Metal"})<-[:BELONGS_TO]-(t:Track)-[:PERFORMED]->(a:Artist)
RETURN COUNT(DISTINCT a) AS MetalArtistCount
# MetalArtistCount
171
앞선 문서상의 연결을 통해 어떻게 데이터를 처리하는지 간단하게 확인해보았습니다.
![[GraphDB] GraphRAG(Neo4j)](https://images.unsplash.com/photo-1434626881859-194d67b2b86f?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDExfHxncmFwaHxlbnwwfHx8fDE3NTM4MzI1MjF8MA&ixlib=rb-4.1.0&q=80&w=960)