[MLOps] Data Pipeline Orchestration - Airflow, Perfect
데이터 오케스트레이션 툴은 복잡한 파이프라인의 종속성, 에러, 모니터링 과제를 해결합니다. 워크플로우를 자동화하여 안정적이고 효율적인 데이터 흐름을 구축할 수 있습니다.
![[MLOps] Data Pipeline Orchestration - Airflow, Perfect](https://images.unsplash.com/photo-1600443446566-c8a2e34c779b?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDN8fE9yY2hlc3RyYXRpb258ZW58MHx8fHwxNzU2MTI2MDA5fDA&ixlib=rb-4.1.0&q=80&w=1200)
개요
데이터 기반의 의사결정이 중요해지면서 수많은 데이터 파이프라인을 구축하고 운영하는 것은 기업의 핵심 과제가 되었습니다. 하지만 이 파이프라인들을 각자 관리하고 실행시키면 매우 복잡하고 방대한 작업을 필요로 합니다.
데이터 오케스트레이션 툴은 바로 이 복잡하게 얽힌 데이터 파이프라인의 흐름을 제어하는 역할을 수행하며, 전체 워크플로우를 안정적이고 효율적으로 관리합니다.
데이터 파이프라인의 도전 과제
데이터의 양과 처리 로직이 복잡해지면서 다음과 같은 도전 과제에 직면하게 됩니다.
- 복잡한 의존성 관리
- 파이프라인 간의 복잡한 의존 관계를 수동으로 관리하기 어렵습니다.
- Cronjob은 개별 작업의 실행은 가능하지만, 이러한 관계를 정의하고 관리하는 기능이 없습니다.
- 어려운 에러 추적 및 복구
- 수많은 파이프라인 중 어느 지점에서 에러가 발생했는지 즉시 파악하기 어렵습니다.
- 실패한 작업만 골라 재시도하거나 특정 기간의 데이터를 다시 처리하는 과정이 매우 번거롭습니다.
- 중앙 관리 및 모니터링의 부재
- 여러 시스템에 분산된 파이프라인들의 상태를 한곳에서 통합하여 모니터링하기 어렵습니다.
- 전체 데이터 흐름의 현황을 파악하고 병목 현상을 진단하기 복잡할 수 있습니다.
- 확장성의 한계
- 처리해야 할 데이터의 규모가 커지거나 파이프라인의 수가 증가할 때, 기존 시스템이 부하를 견디지 못하고 유연하게 대처하기 어렵습니다.
데이터 오케스트레이션 툴의 핵심 기능과 장점
데이터 오케스트레이션 툴은 위와 같은 문제들을 해결하기 위해 다음과 같은 강력한 기능들을 제공합니다.
- 워크플로우 자동화 및 종속성 관리
- 작업의 실행 순서, 스케줄, 복잡한 선후 관계 및 조건부 실행 등의 종속성을 코드로 명확하게 정의하고 자동으로 실행합니다. 이를 통해 사람의 개입을 최소화하고 휴먼 에러를 방지합니다.
- 견고한 오류 처리와 재시
- 내장된 오류 처리 메커니즘을 통해 특정 작업이 실패했을 경우, 설정된 정책에 따라 자동으로 재시도를 실행합니다. 이를 통해 일시적인 네트워크 문제나 시스템 오류로부터 파이프라인의 안정성을 보장합니다.
- 중앙화된 모니터링과 로깅
- 모든 파이프라인의 실행 상태, 성공, 실패 여부를 하나의 대시보드에서 실시간으로 추적할 수 있습니다. 또한, 각 작업 단계별로 상세한 로그를 제공하여 문제 발생 시 원인을 신속하게 파악하고 디버깅할 수 있도록 돕습니다.
- 수평적 확장성과 병렬 처리
- 대규모 데이터 처리나 수많은 동시 작업이 필요할 때, 여러 노드(컴퓨터)를 추가하여 작업을 분산 처리(수평적 확장)할 수 있습니다.
- 백필(Backfill) 지원
- 데이터 처리 로직에 버그가 있었거나 특정 기간의 데이터가 누락되었을 때, 간단한 명령어로 과거 특정 기간의 데이터를 지정하여 파이프라인을 다시 실행할 수 있습니다.
- 원활한 외부 시스템 통합
- 데이터베이스, 클라우드 스토리지(S3, GCS), 메시지 큐 등 다양한 데이터 소스 및 시스템과 쉽게 연동할 수 있는 확장 기능(Provider, Plugin)을 제공하여 유연한 데이터 생태계를 구축할 수 있습니다.
대표적인 툴: Airflow & Perfect
가장 널리 알려진 오픈소스 데이터 오케스트레이션 툴 중 하나는 Airflow입니다.
Airflow는 DAG(Directed Acyclic Graph, 방향성 비순환 그래프) 라는 핵심 개념을 사용하여 워크플로우를 정의합니다. 각 작업(Task)과 그들 사이의 실행 순서 및 의존 관계를 그래프 형태로 명확하게 표현합니다.
- 방향성(Directed): 데이터의 처리 흐름이 어디서 시작해서 어디로 향하는지 명확한 방향을 가집니다.
- 비순환(Acyclic): 작업 흐름이 다시 시작점으로 돌아오는 무한 루프에 빠지지 않도록 구조적으로 보장합니다.
이 DAG 설계도를 통해 사용자는 어떤 작업들이 순차적으로 실행되어야 하고, 어떤 작업들이 동시에 병렬로 처리될 수 있는지 한눈에 파악할 수 있으며, 전체 파이프라인을 체계적으로 시각화하고 관리할 수 있습니다.
Airflow는 이 DAG를 기반으로 풍부한 UI, 강력한 스케줄링 및 모니터링 기능을 제공하여 복잡한 데이터 워크플로우를 안정적으로 운영할 수 있도록 지원합니다.
Airflow Demo
from airflow import DAG
from airflow.operators.dummy import DummyOperator
from airflow.operators.python import PythonOperator
from airflow.utils.dates import days_ago
from airflow.operators.email import EmailOperator
import random
import time
# Function to generate random IoT data
def generate_iot_data(**kwargs):
data = []
for _ in range(60): # 60 seconds x 5 minutes = 300 readings (1 every second)
data.append(random.choice([0, 1]))
time.sleep(1) # simulate 1-second intervals
return data
# Function to aggregate the IoT data
def aggregate_machine_data(**kwargs):
ti = kwargs['ti']
data = ti.xcom_pull(task_ids='getting_iot_data')
count_0 = data.count(0)
count_1 = data.count(1)
aggregated_data = {'count_0': count_0, 'count_1': count_1}
return aggregated_data
# Email content generation
def create_email_content(**kwargs):
ti = kwargs['ti']
aggregated_data = ti.xcom_pull(task_ids='aggrigate_machine_data')
return f"Aggregated IoT Data:\nCount of 0: {aggregated_data['count_0']}\nCount of 1: {aggregated_data['count_1']}"
# Default arguments for the DAG
default_args = {
'owner': 'airflow',
'start_date': days_ago(1),
'email_on_failure': False,
'email_on_retry': False,
'retries': 1,
}
# Define the DAG
with DAG(
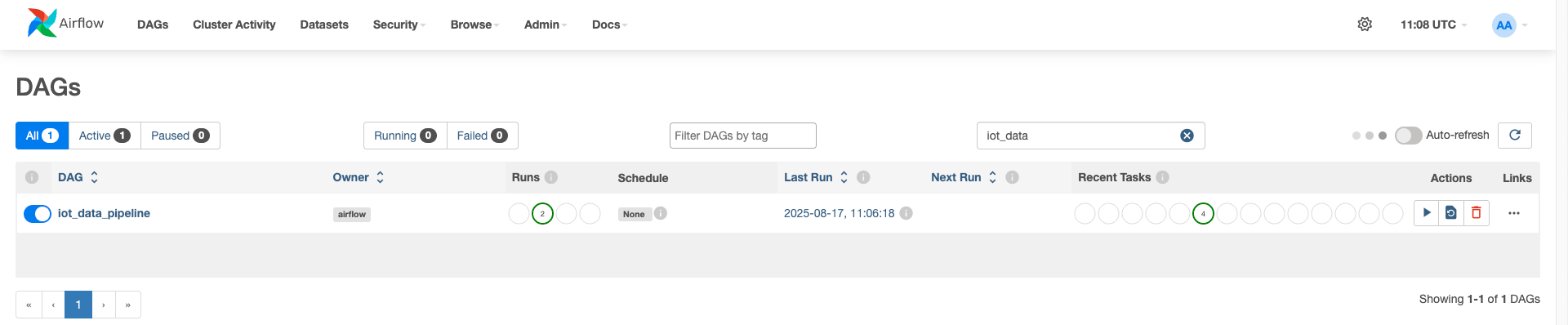
dag_id='iot_data_pipeline',
default_args=default_args,
schedule_interval=None,
catchup=False,
) as dag:
start_task = DummyOperator(task_id='start_task')
getting_iot_data = PythonOperator(
task_id='getting_iot_data',
python_callable=generate_iot_data,
)
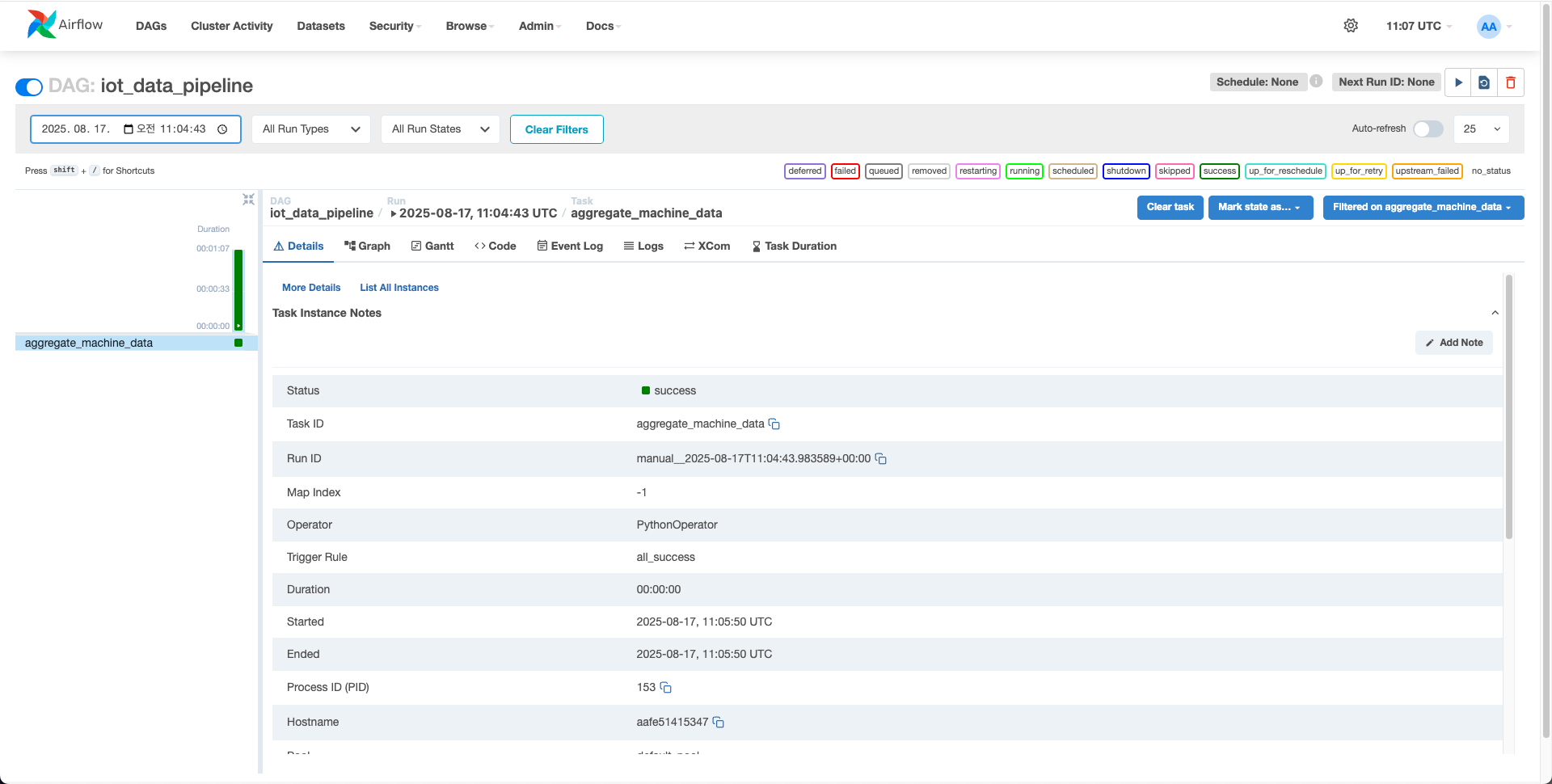
aggregate_machine_data = PythonOperator(
task_id='aggregate_machine_data',
python_callable=aggregate_machine_data,
)
end_task = DummyOperator(task_id='end_task')
# Task dependencies
start_task >> getting_iot_data >> aggregate_machine_data >> end_task
![[MLOps] Apache Airflow 기능 및 용어 정리](https://images.unsplash.com/photo-1754928661805-ae4279a97218?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDR8fGFpcmZsb3d8ZW58MHx8fHwxNzU2MTI1OTkwfDA&ixlib=rb-4.1.0&q=80&w=960)
![[AWS] AWS 기반 데이터 파이프라인 서비스 정리](https://images.unsplash.com/photo-1507823690283-48b0929e727b?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDR8fHBpcGVsaW5lfGVufDB8fHx8MTc1NDIyNjIwOXww&ixlib=rb-4.1.0&q=80&w=960)
