Llamaindex Cookbook을 활용한 GenAI 기본 패턴 정리
Llamaindex와 Llama3로 RAG, Text-to-SQL, 에이전트 등 GenAI 핵심 패턴 구축 방법을 학습하고 테스트합니다. 실용적인 AI 앱 개발 방법을 익혀보세요.

개요
Llamaindex Cookbook을 활용하여 Llamaindex + Llama3를 통해 GenAI 기본 패턴에 대해 학습하고, 테스트 해보았습니다.
다음과 같은 목록으로 구성하였습니다.
- 간단한 채팅과 대화
- Basic RAG (Vector Search, Summarization)
- Advanced RAG (Routing, Sub-Questions)
- Text-to-SQL
- 구조화된 데이터 추출
- Chatting 히스토리 추가하기
- Agents
해당 환경을 테스트해보기 위해선 Python 환경과 Ollama, AWS Bedrock 엑세스 권한이 필요합니다.
Bedrock 엑세스 권한과 Python 환경이 사전에 구성되어 있다고 가정하였습니다.
Installation and Setup
!pip install llama-index
!pip install llama-index-llms-ollama
!pip install llama-index-llms-replicate
!pip install llama-index-embeddings-huggingface
!pip install llama-parse
!pip install replicate
이벤트 루프 설정
import nest_asyncio
nest_asyncio.apply()
Ollama 설정
Ollama는 오픈소스 LLM 모델을 로컬 컴퓨터에서 실행할 수 있게 도와주는 도구로, Mistral, Llama3 등 다양한 오픈소스 모델을 지원하고 있습니다.
from llama_index.llms.ollama import Ollama
llm = Ollama(model="llama3", request_timeout=120.0)
Bedrock LLM 모델 설정
from llama_index.llms.bedrock import Bedrock
import boto3
aws_region=boto3.Session().region_name
bedrock_client = boto3.client("bedrock-runtime", region_name=aws_region)
llm_bedrock = Bedrock(model="meta.llama3-8b-instruct-v1:0", client=bedrock_client, context_size=8000)
한국어 임베딩 모델 설정
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
embed_model = HuggingFaceEmbedding(model_name="intfloat/multilingual-e5-small")
Default 모델 설정
from llama_index.core import Settings
Settings.llm = llm
Settings.embed_model = embed_model
테스트 데이터 다운로드
!mkdir data
!wget "https://www.dropbox.com/scl/fi/t1soxfjdp0v44an6sdymd/drake_kendrick_beef.pdf?rlkey=u9546ymb7fj8lk2v64r6p5r5k&st=wjzzrgil&dl=1" -O data/drake_kendrick_beef.pdf
!wget "https://www.dropbox.com/scl/fi/nts3n64s6kymner2jppd6/drake.pdf?rlkey=hksirpqwzlzqoejn55zemk6ld&st=mohyfyh4&dl=1" -O data/drake.pdf
!wget "https://www.dropbox.com/scl/fi/8ax2vnoebhmy44bes2n1d/kendrick.pdf?rlkey=fhxvn94t5amdqcv9vshifd3hj&st=dxdtytn6&dl=1" -O data/kendrick.pdf
데이터 파싱하기
SimpleDirectoryReader
from llama_index.core import SimpleDirectoryReader
docs_kendrick = SimpleDirectoryReader(input_files=["data/kendrick.pdf"]).load_data()
docs_drake = SimpleDirectoryReader(input_files=["data/drake.pdf"]).load_data()
docs_both = SimpleDirectoryReader(input_files=["data/drake_kendrick_beef.pdf"]).load_data()
docs_law_books = SimpleDirectoryReader(input_files=["data/한글 4법전(헌법, 민법, 형법, 형사소송법).pdf"]).load_data()
LlamaParse
LlamaParse는 LlamaIndex 프레임워크를 사용하여 효율적인 검색 및 컨텍스트 확대를 위해 파일을 효율적으로 구문 분석하고 표현하기 위해 LlamaIndex에서 만든 API입니다.
다양한 타입과 데이터 변환을 지원하며, 현재 무료로 사용할 수 있습니다.
API Key 발급받기
# .env 파일에서 환경 변수를 로드하기 위한 코드
import os
from dotenv import load_dotenv
# .env 파일 로드
load_dotenv()
# 환경 변수 가져오기
llama_index_parse_key = os.getenv("LLAMA_INDEX_PARSE_KEY")
한글 법전은 약 258페이지로 구성되어 Parsing하는데 대략 5분정도 소요되었습니다.
from llama_parse import LlamaParse
docs_kendrick = LlamaParse(api_key=llama_index_parse_key, result_type="text").load_data("./data/kendrick.pdf")
docs_drake = LlamaParse(api_key=llama_index_parse_key, result_type="text").load_data("./data/drake.pdf")
docs_both = LlamaParse(api_key=llama_index_parse_key, result_type="text").load_data("./data/drake_kendrick_beef.pdf")
docs_law_books = LlamaParse(api_key=llama_index_parse_key, result_type="text").load_data("./data/한글 4법전(헌법, 민법, 형법, 형사소송법).pdf")
기본 구조 및 채팅
response = llm.complete("Drake와 Kendrick 중 누가 더 좋아?")
print(response)
하지만 위와 같은 complete로 질의하게 된다면 답변 생성까지 아무런 반응을 얻을 수 없게 됩니다. 따라서 이번에는 바로 반응을 받을 수 있게 stream 방식으로 생성할 수 있습니다.
stream_response = llm.stream_complete(
"너는 drake 팬이야. 왜 kendrick보다 drake가 좋은지 설명해줘"
)
for t in stream_response:
print(t.delta, end="")
LLM에게 역할을 지정하고 해당 LLM과 대화하듯이 사용할 수도 있습니다.
from llama_index.core.llms import ChatMessage
messages = [
ChatMessage(role="system", content="너는 Kendrick의 영향을 받은 한국인이야. 한국어 답변만 생성해줘"),
ChatMessage(role="user", content="한국어 Verse를 작성해줘"),
]
response = llm.chat(messages)
print(response)
# # 계속해서 대화를 이어나가기 위해 새로운 응답을 messages 리스트에 추가
# messages.append(ChatMessage(role="assistant", content=response.content))
# # 예시로 또 다른 질문 추가
# messages.append(ChatMessage(role="user", content="Tell me about your latest album."))
# # 세 번째 응답 생성
# response = llm.chat(messages)
# print("Kendrick:", response.content)
# # 대화를 이어나가기 위해 또다시 응답을 messages 리스트에 추가
# messages.append(ChatMessage(role="assistant", content=response.content))
Basic RAG(Vector Search, Summarization)
Retriever with Vector Search
from llama_index.core import VectorStoreIndex
# 문서 데이터 임베딩 및 벡터 인덱스 생성
index = VectorStoreIndex.from_documents(docs_law_books, show_progress=True)
# 벡터 인덱스를 검색할 수 있는 쿼리 엔진 구성
query_engine = index.as_query_engine(similarity_top_k=3)
연관된 데이터가 잘 나오는지 확인해볼 수 있습니다.
response1 = query_engine.retrieve("명예훼손과 관련된 법을 알려줘")
print("연관도: ", response1[0].score)
print("연관도: ", response1[0].text)
print("----------------------------------------------------")
response2 = query_engine.retrieve("절도죄에 대해 설명해줘")
print("연관도2: ", response2[0].score)
print("연관도2: ", response2[0].text)

로컬 머신 성능에 따라 들어가는 문장과 출력되는 문장의 제한이 있기 때문에, 정확도는 낮습니다.
response = query_engine.query("한국어로 대답할 것. 명예훼손 관련된 법안을 설명해줘.")
print(response)
------------------------------------
In Korean:
명예훼손에 대한 법안은 다음과 같습니다.
제227조에서는 사자의 명예를 훼손한 범죄에 대하여는 그 친족 또는 자손이 고소할 수 있습니다. 또한, 피해자의 명시한 의사에 반하여 공소를 제기할 수 없는 사건에서 처벌을 희망하는 경우도 있습니다. 이러한 경우에는 피의자신문과 참여자를 통해 검찰청수사관 또는 서기가 참여하게 하여야 합니다.
또한, 고소는 제1심 판결선고 전까지 취소할 수 있습니다. 또한, 고소를 취소한 자는 다시 고소하지 못합니다. 이러한 법안은 명예훼손에 대한 처벌을 규제하는 데 있어 중요합니다.
참고 - 임베딩 모델 테스트
영어로 테스트 해보면 조금 더 정확하게 나오는 것을 확인할 수 있습니다.
from llama_index.core.evaluation import SemanticSimilarityEvaluator
evaluator = SemanticSimilarityEvaluator()
# This evaluator only uses `response` and `reference`, passing in query does not influence the evaluation
# query = 'What is the color of the sky'
response = "The sky is typically blue"
reference = """The color of the sky can vary depending on several factors, including time of day, weather conditions, and location.
During the day, when the sun is in the sky, the sky often appears blue.
This is because of a phenomenon called Rayleigh scattering, where molecules and particles in the Earth's atmosphere scatter sunlight in all directions, and blue light is scattered more than other colors because it travels as shorter, smaller waves.
This is why we perceive the sky as blue on a clear day.
"""
result = await evaluator.aevaluate(
response=response,
reference=reference,
)
print("Score: ", result.score)
print("Passing: ", result.passing) # default similarity threshold is 0.8
---------------------------------------------------------------------------
Score: 0.7690120531299893
Passing: True # 기준점을 정해 유사도를 비교하여 검색 퀄리티를 유지할 수 있습니다.
Basic RAG (Summarization)
Ollama가 Local에서 구성되어 동작하므로, 약 10분 정도 소요됩니다.
from llama_index.core import SummaryIndex
summary_index = SummaryIndex.from_documents(docs_both)
summary_engine = summary_index.as_query_engine()
response = summary_engine.query("Given your assessment of this article, who won the beef?")
print(str(response))
Advanced RAG(Routing, Sub-Question)
Routing은 특정 쿼리나 요청을 적절한 처리 경로로 보내는 과정을 의미합니다.
고객 지원 챗봇이 다양한 주제(예: 기술 지원, 판매 문의, 일반 질문)에 대해 다른 데이터베이스를 가지고 있는 경우, 라우팅을 통해 각각의 질문을 적절한 데이터베이스로 보낼 수 있습니다.
- 질문: "내 주문이 언제 도착하나요?"
- 라우팅: 이 질문은 주문 추적 시스템으로 라우팅되어야 합니다.
- 질문: "새로운 제품에 대한 정보가 있나요?"
- 라우팅: 이 질문은 마케팅 데이터베이스로 라우팅되어야 합니다.
Sub-Question은 복잡한 질문을 더 작고 관리하기 쉬운 여러 개의 하위 질문으로 나누는 것을 의미합니다.
질문을 세부적으로 나눠 각각의 서브 질문에 대해 개별적으로 응답을 생성한 후, 이를 종합하여 최종 응답을 만듭니다.
- 질문: "인공지능의 역사와 현재 발전 방향에 대해 설명해 주세요."
- 서브 질문 1: "인공지능의 역사에 대해 설명해 주세요."
- 서브 질문 2: "현재 인공지능의 발전 방향에 대해 설명해 주세요."
각 서브 질문에 대해 개별적으로 답변한 후:
- 응답 1: "인공지능은 1950년대부터 시작되었으며, 초기에는…"
- 응답 2: "현재 인공지능은 딥러닝, 강화학습 등 다양한 분야에서 발전하고 있습니다…"
이 두 응답을 종합하여 최종 응답을 생성합니다.
Routing
from llama_index.core.tools import QueryEngineTool, ToolMetadata
# 벡터 인덱스를 검색할 수 있는 쿼리 엔진 구성 - Vector Search
vector_tool = QueryEngineTool(
index.as_query_engine(),
metadata=ToolMetadata(
name="vector_search",
description="Useful for searching for specific facts.",
),
)
# 벡터 인덱스를 검색할 수 있는 쿼리 엔진 구성 - Summarization
summary_tool = QueryEngineTool(
index.as_query_engine(response_mode="tree_summarize"), # 문서를 작은 부분으로 나눠 각 부분을 요약하고, 요약을 다시 결합하여 전체 문서에 대한 요약을 생성
metadata=ToolMetadata(
name="summary",
description="Useful for summarizing an entire document.",
),
)
사용자의 질문에 따라 올바른 쿼리를 실행하기 위해 다음과 같은 Router Query Engine을 등록합니다.
from llama_index.core.query_engine import RouterQueryEngine
query_engine = RouterQueryEngine.from_defaults(
[vector_tool, summary_tool], select_multi=False, verbose=True # verbose > 상세 정보를 출력하도록 합니다.
)
response = query_engine.query(
"Tell me about the song meet the grahams - why is it significant"
)
print(response)
-----------------------------------------------------------------------------
Selecting query engine 0: Since the question asks about specific facts related to the song 'Meet the Grahams', it's more likely that the correct answer is (1) Useful for searching for specific facts..
The "Meet the Grahams" artwork is a full picture that Kendrick teased earlier on "6.16 in LA". It shows Maybach gloves, a shirt, receipts, and prescription bottles, including one for Ozempic prescribed to Drake. This artwork serves as a visual representation of the beef between Kendrick Lamar and Drake, highlighting the personal nature of their feud. The song itself is significant because it marks the beginning of Kendrick's aggressive response to Drake's perceived disses, setting the tone for the subsequent diss tracks that would follow in the coming days.
복잡한 질문을 하위 질문으로 나누기
drake_index = VectorStoreIndex.from_documents(docs_drake, show_progress=True)
drake_query_engine = drake_index.as_query_engine(similarity_top_k=3)
kendrick_index = VectorStoreIndex.from_documents(docs_kendrick, show_progress=True)
kendrick_query_engine = kendrick_index.as_query_engine(similarity_top_k=3)
벡터 인덱스를 검색할 수 있는 쿼리 엔진 구성
from llama_index.core.tools import QueryEngineTool, ToolMetadata
drake_tool = QueryEngineTool(
drake_index.as_query_engine(),
metadata=ToolMetadata(
name="drake_search",
description="Useful for searching over Drake's life.",
),
)
kendrick_tool = QueryEngineTool(
kendrick_index.as_query_engine(),
metadata=ToolMetadata(
name="kendrick_summary",
description="Useful for searching over Kendrick's life.",
),
)
from llama_index.core.query_engine import SubQuestionQueryEngine
import json
query_engine = SubQuestionQueryEngine.from_defaults(
[drake_tool, kendrick_tool],
llm=llm_bedrock, # llama3-70b
verbose=True,
)
response = query_engine.query("Which albums did Drake release in his career?")
print(response)
print(response)
--------------------------------------------------------------------------
Generated 1 sub questions.
[drake_search] Q: What albums has Drake released?
[drake_search] A: Based on the provided context, Drake has released several albums throughout his career, including:
1. Thank Me Later (2010)
2. Take Care (2011)
3. Nothing Was the Same (2013)
4. Views (2016)
5. Scorpion (2018)
6. Certified Lover Boy (2021)
7. Honestly, Nevermind (2022)
8. For All the Dogs (2023)
Please note that this list only includes information provided in the given context and may not be an exhaustive list of Drake's albums.
생성된 답변.
Drake has released several albums throughout his career, including Thank Me Later (2010), Take Care (2011), Nothing Was the Same (2013), Views (2016), Scorpion (2018), Certified Lover Boy (2021), Honestly, Nevermind (2022), and For All the Dogs (2023).
Text-toSQL
테스트용 음악, 재생 목록 및 고객에 대한 다양한 정보가 포함된 11개의 테이블이 포함된 샘플 SQLite 데이터베이스를 다운로드합니다.
!wget "https://www.sqlitetutorial.net/wp-content/uploads/2018/03/chinook.zip" -O "./data/chinook.zip"
!unzip "./data/chinook.zip"
sqlite engine 생성
from sqlalchemy import (
create_engine,
MetaData,
Table,
Column,
String,
Integer,
select,
column,
)
engine = create_engine("sqlite:///chinook.db")
Llamaindex와 sqlite 연결
from llama_index.core import SQLDatabase
sql_database = SQLDatabase(engine)
Llamaindex의 자연어를 쿼리로 변환할 수 있게 도와주는 NLSQLTableQueryEngine 구성
from llama_index.core.indices.struct_store import NLSQLTableQueryEngine
query_engine = NLSQLTableQueryEngine(
sql_database=sql_database,
tables=["albums", "tracks", "artists"],
llm=llm_bedrock,
)
응답 테스트
response = query_engine.query("What are some albums?")
print(response)
---------------------------------------------------------------------------
Based on the SQL query and response, here is a synthesized response:
Some albums that were returned from the query are:
1. "For Those About To Rock We Salute You" by the artist with ID 1.
2. "Balls to the Wall" by the artist with ID 2.
3. "Restless and Wild" by the artist with ID 2.
4. "Let There Be Rock" by the artist with ID 1.
5. "Big Ones" by the artist with ID 3.
The query returned the title and artist ID for the first 5 albums in the database. Without more context about the specific artists, I can only provide these high-level details about the album titles and associated artist IDs.
response = query_engine.query("What are some artists? Limit it to 5.")
print(response)
--------------------------------------------------------------------------
Based on the SQL query and response, here is a synthesized response:
Some artists include AC/DC, Accept, Aerosmith, Alanis Morissette, and Alice In Chains.
response = query_engine.query(
"What are some tracks from the artist AC/DC? Limit it to 3"
)
print(response)
--------------------------------------------------------------------------
Based on the SQL query and its response, here is a synthesized response to the original question:
Some tracks from the artist AC/DC are:
1. "Bad Boy Boogie" from the album "Let There Be Rock"
2. "Breaking The Rules" from the album "For Those About To Rock We Salute You"
3. "C.O.D." from the album "For Those About To Rock We Salute You"
The SQL query retrieved the top 3 track names and their corresponding album titles from the database, where the artist name was 'AC/DC'. This information has been summarized into a concise response to the original question.
실행된 쿼리 정보도 파악할 수 있습니다.
print(response.metadata["sql_query"])
---------------------------------------------------------------------------
SELECT t.Name, a.Title
FROM tracks t
JOIN albums a ON t.AlbumId = a.AlbumId
JOIN artists ar ON a.ArtistId = ar.ArtistId
WHERE ar.Name = 'AC/DC'
ORDER BY t.Name
LIMIT 3;
구조화된 데이터 추출
특정 함수를 호출했을 때 결과값을 구조화된 객체에 따라 추출되고 파싱할 수 있습니다.
LlamaIndex를 사용하여 이 과정을 쉽게 수행할 수 있으며, 아래와 같은 프로세스로 진행됩니다.
- 구조화된 객체 추출:
- LlamaIndex는
structured_predict라는 직관적인 인터페이스를 제공하여 이를 쉽게 할 수 있도록 합니다.
- LlamaIndex는
- Pydantic 클래스 정의:
- 목표로 하는 구조화된 객체를 나타내기 위해 대상 Pydantic 클래스를 정의하면 됩니다.
- Pydantic 클래스는 중첩될 수도 있습니다.
- 프롬프트와 객체 추출:
- 프롬프트를 주면, 해당 프롬프트를 기반으로 원하는 객체를 추출합니다.
- 이 과정은 LLM(Large Language Model)을 사용하여 수행됩니다.
- 파이프라인:
- Llama3나 Ollama와 같은 모델에는 네이티브 함수 호출 지원이 없기 때문에, 구조화된 추출은 LLM에 프롬프트를 제공하고 그 출력을 파싱하는 방식으로 수행됩니다.
from llama_index.llms.ollama import Ollama
from llama_index.core.prompts import PromptTemplate
from pydantic import BaseModel
class Restaurant(BaseModel):
"""A restaurant with name, city, and cuisine."""
name: str
city: str
cuisine: str
llm = Ollama(model="llama3")
prompt_tmpl = PromptTemplate(
"Generate a restaurant in a given city {city_name}"
)
데이터를 특정 구조에 따라 파싱되는 것을 확인할 수 있습니다.
restaurant_obj = llm.structured_predict(
Restaurant, prompt_tmpl, city_name="Tokyo"
)
print(restaurant_obj)
-------------------------------------------------------------------------
name='Sakura Tei' city='Tokyo' cuisine='Japanese'
Chatting 히스토리 추가하기
- 대화 문맥 축약:
- 사용자가 이전에 언급한 내용을 기억하고, 대화 문맥을 축약하여 효율적으로 유지합니다.
ChatMemoryBuffer를 사용하여 대화 내역을 메모리에 저장합니다.
- 문서 검색:
index.as_retriever()를 통해 미리 설정된 문서를 검색하여 사용자의 질문에 대한 관련 정보를 제공합니다.- 사용자가 특정 주제에 대해 질문할 때, 관련 문서에서 필요한 정보를 추출하여 응답합니다.
그 외로는 이전 설정과 비슷하게 진행하였습니다.
from llama_index.core.memory import ChatMemoryBuffer
from llama_index.core.chat_engine import CondensePlusContextChatEngine
memory = ChatMemoryBuffer.from_defaults(token_limit=3900)
chat_engine = CondensePlusContextChatEngine.from_defaults(
index.as_retriever(),
memory=memory,
llm=llm,
context_prompt=(
"You are a chatbot, able to have normal interactions, as well as talk"
" about the Kendrick and Drake beef."
"Here are the relevant documents for the context:\n"
"{context_str}"
"\nInstruction: Use the previous chat history, or the context above, to interact and help the user."
),
timeout= 300,
verbose=True,
)
response = chat_engine.stream_chat(
"Tell me about the songs Drake released in the beef.",
)
for token in response.response_gen:
print(token, end="")
Agents
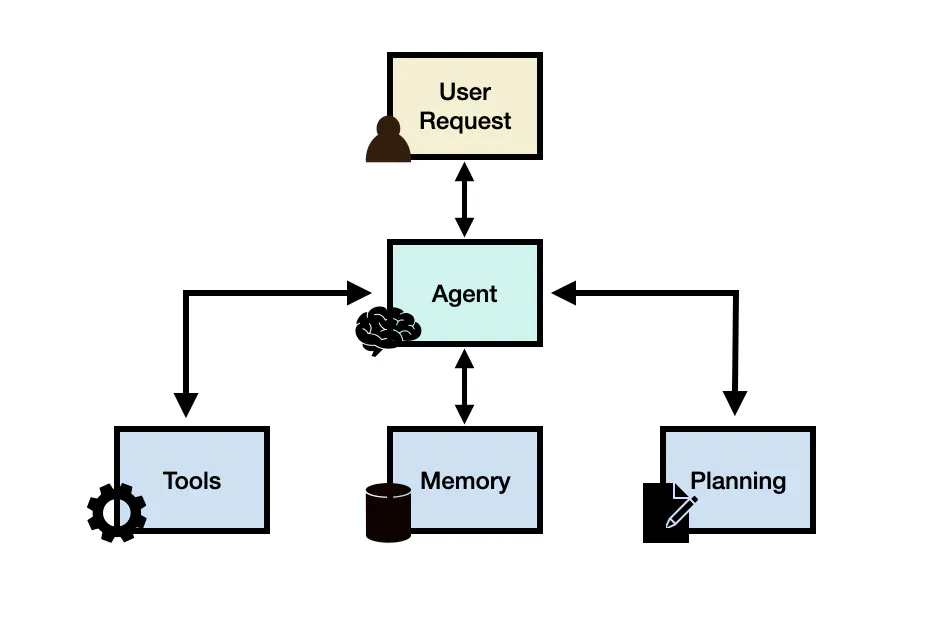
해당 문서에서는 Anthropic Haiku 모델을 사용하여 에이전트를 구축합니다. 앞서 문서들뿐만 아니라 간단한 기능에 대해 RAG 수행하는 것을 테스트하며, 다양한 기법이 존재하는 구조입니다.
대표적인 상황으로는 LLM 추론 과정에서 실시간 정보를 요구하거나, 실시간으로 상호작용이 필요한 사례와 적합하며, 앞선 Routing 방식처럼 필요에 따라 인터넷에서 정보를 찾아오게 됩니다.
import json
from typing import Sequence, List
from llama_index.core.llms import ChatMessage
from llama_index.core.tools import BaseTool, FunctionTool
from llama_index.core.agent import ReActAgent
def multiply(a: int, b: int) -> int:
"""Multiple two integers and returns the result integer"""
return a * b
def add(a: int, b: int) -> int:
"""Add two integers and returns the result integer"""
return a + b
def subtract(a: int, b: int) -> int:
"""Subtract two integers and returns the result integer"""
return a - b
def divide(a: int, b: int) -> int:
"""Divides two integers and returns the result integer"""
return a / b
multiply_tool = FunctionTool.from_defaults(fn=multiply)
add_tool = FunctionTool.from_defaults(fn=add)
subtract_tool = FunctionTool.from_defaults(fn=subtract)
divide_tool = FunctionTool.from_defaults(fn=divide)
agent = ReActAgent.from_tools(
[multiply_tool, add_tool, subtract_tool, divide_tool],
llm=llm_bedrock,
verbose=True,
)
response = agent.chat("""[INST]You are a a very intelligent bot with exceptional critical thinking[/INST] What is (121 + 2) * 5?""")
print(str(response))
Thought: The current language of the user is: [INST]. I need to use a tool to help me answer the question.
Action: add
Action Input: {"a": 121, "b": 2}
Observation: 123
Thought: I will now use the multiply tool to complete the calculation.
Action: multiply
Action Input: {"a": 123, "b": 5}
Observation: 615
Thought: I can answer without using any more tools. I'll use the user's language to answer.
Answer: (121 + 2) * 5 = 615
(121 + 2) * 5 = 615
사전에 주어진 함수와 정보를 통해 LLM 스스로 생각하고 행동하여 출력을 생성합니다. 이와 같은 방식을 ReAct Prompting이라고 하며, 자세한 동작 방식과 구성은 아래 링크에서 확인할 수 있습니다.
RAG와 ReAct 통합하기
from llama_index.core import (
SimpleDirectoryReader,
VectorStoreIndex,
StorageContext,
load_index_from_storage,
)
from llama_index.core.tools import QueryEngineTool, ToolMetadata
drake_tool = QueryEngineTool(
drake_index.as_query_engine(),
metadata=ToolMetadata(
name="drake_search",
description="Useful for searching over Drake's life.",
),
)
kendrick_tool = QueryEngineTool(
kendrick_index.as_query_engine(),
metadata=ToolMetadata(
name="kendrick_search",
description="Useful for searching over Kendrick's life.",
),
)
query_engine_tools = [drake_tool, kendrick_tool]
agent = ReActAgent.from_tools(
query_engine_tools, ## TODO: define query tools
llm=llm_bedrock,
verbose=True,
)
response = agent.chat("Tell me about how Kendrick and Drake grew up")
print(str(response))
Thought: The current language of the user is: English. I need to use a tool to help me answer the question.
Action: kendrick_search
Action Input: {"input": "Kendrick Lamar childhood"}
Observation: Kendrick Lamar grew up in Compton, California, which was a rough neighborhood plagued by gang violence and crime. He was raised by a single mother and had a difficult upbringing, with many challenges and obstacles to overcome. Despite the challenges, Kendrick found solace in music and used it as a way to express himself and share his experiences growing up in Compton.
Thought: I still need more information about Drake's upbringing to fully answer the question.
Action: drake_search
Action Input: {"input": "Drake childhood"}
Observation: Drake, whose real name is Aubrey Graham, grew up in Toronto, Canada. Unlike Kendrick, Drake had a relatively stable upbringing. He was raised by his mother, who was a teacher, and his parents were not involved in any criminal activities. Drake attended a Jewish day school and was a child actor, starring in the Canadian teen drama "Degrassi: The Next Generation" for several years. While he faced some challenges, such as being bullied for his biracial background, Drake's upbringing was generally more privileged and stable compared to Kendrick's.
Thought: I can answer the question with the information I've gathered.
Answer: Kendrick Lamar and Drake had very different upbringings. Kendrick grew up in the tough, crime-ridden neighborhood of Compton, California, raised by a single mother and facing many challenges and obstacles. In contrast, Drake grew up in a more stable environment in Toronto, Canada, with a middle-class upbringing and a background in acting. While both artists found success in the music industry, their early life experiences were quite different.
------------------------------------------------------------------------
Kendrick Lamar and Drake had very different upbringings. Kendrick grew up in the tough, crime-ridden neighborhood of Compton, California, raised by a single mother and facing many challenges and obstacles. In contrast, Drake grew up in a more stable environment in Toronto, Canada, with a middle-class upbringing and a background in acting. While both artists found success in the music industry, their early life experiences were quite different.
다음과 같이 필요한 정보가 있다면 스스로 판단하여 검색한 뒤, 이를 조합하여 결과를 도출합니다.
ReAct 프레임워크를 사용하면 대규모언어모델이 외부 도구와 상호 작용하여 보다 신뢰할 수 있고 사실적인 응답으로 이어지는 추가 정보를 검색할 수 있는 기법으로 CoT와 ReAct를 함께 구성하여 사용하는 것은 LLM에 성능과 데이터 신뢰성에 있어 큰 이점이 있습니다.
![[AI Agent] AI Agent OT 정리](https://images.unsplash.com/photo-1558978325-66dcf73b99b0?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDF8fE9yaWVudGF0aW9ufGVufDB8fHx8MTc3MzQ1MzMwM3ww&ixlib=rb-4.1.0&q=80&w=960)
![[LLM] VLM으로 표를 정확히 추출하기](https://images.unsplash.com/photo-1623667322051-18662ce6334c?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDl8fHBkZnxlbnwwfHx8fDE3NzIzNzMzODN8MA&ixlib=rb-4.1.0&q=80&w=960)
![[RAG] 한국어 Reranker 모델을 사용하여 RAG 성능 올리기](https://images.unsplash.com/flagged/photo-1578928534298-9747fc52ec97?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDF8fFJhbmtpbmd8ZW58MHx8fHwxNzU0MTM3OTQ4fDA&ixlib=rb-4.1.0&q=80&w=960)
![[RAG] 더 나은 RAG를 위해 Retrieval pipeline 개선하기](https://images.unsplash.com/photo-1528819622765-d6bcf132f793?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDF8fHN0cmF0ZWd5fGVufDB8fHx8MTc1NDEzNzQ2Nnww&ixlib=rb-4.1.0&q=80&w=960)