[AI/ML] Qwen3 VL 8B SFT LoRA Fine Tuning 가이드
LoRA를 활용하여 Qwen3-VL-8B을 건설현장 균열 이미지 데이터셋(2,057개)으로 효율적으로 파인튜닝하고 SageMaker vLLM으로 배포하는 전체 파이프라인을 확인합니다
![[AI/ML] Qwen3 VL 8B SFT LoRA Fine Tuning 가이드](https://images.unsplash.com/photo-1764477122486-5006de4bd62f?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDIwfHxtb2RlbCUyMHR1bmluZ3xlbnwwfHx8fDE3Njk4NDY4NDZ8MA&ixlib=rb-4.1.0&q=80&w=1200)
개요
Vision-Language Model(VLM)을 도메인 특화 태스크에 적용하려면 파인튜닝이 필요할 수 있습니다.
하지만 8B 이상의 대형 모델을 Full Fine-Tuning하기에는 GPU 메모리와 학습 시간이 부담됩니다.
본 실험에서는 LoRA(Low-Rank Adaptation)를 활용하여 Qwen3-VL-8B 모델을 효율적으로 파인튜닝합니다. 건설현장 균열 이미지 분석을 예시 태스크로 사용하며, 핵심은 VLM에 LoRA를 적용하는 방법과 학습 파이프라인 구성입니다.
파인튜닝이 적합한 사례는 다음과 같습니다(참고)
| 상황 | 예시 | 이유 |
|---|---|---|
| 도메인 특화 용어 | 의료 영상(CT, MRI), 건설 균열, 반도체 결함 | 일반 모델이 전문 용어를 모릅니다 |
| 특정 출력 포맷 | JSON, XML, 정해진 스키마 | 프롬프트만으로 일관성 유지가 어렵습니다 |
| 비공개 데이터 | 사내 문서, 제품 이미지 | 학습 데이터에 없는 정보입니다 |
| 높은 정확도 요구 | 불량 검출, 품질 검사 | 범용 모델은 80%대, 파인튜닝 시 95%+ 가능합니다 |
주의사항: 파인튜닝은 양질의 라벨링 데이터가 필요하고, 학습에 GPU 리소스와 시간이 소요됩니다. 단순한 태스크라면 프롬프트 엔지니어링이나 Few-shot 학습을 먼저 시도하십시오.
Dataset
현재 문서에서는 **건물 균열 탐지 이미지 (고도화)- SOC 시설물 균열패턴 이미지 데이터]**를 참고했습니다. AI-Hub 데이터셋의 Sample 데이터를 통해 파인 튜닝을 수행합니다.
전체 데이터보단 Sample 데이터셋을 통해 간략하게 구축했습니다.
AWS 리소스 구성
| 리소스 | 설명 |
|---|---|
| EC2 인스턴스(AMI) | Deep Learning OSS Nvidia Driver AMI GPU PyTorch 2.5.1 (Ubuntu 22.04) |
| Security Group | SSH(22), JupyterLab(8888) 포트 허용 (특정 IP만) |
| IAM Role | SSM 접근 + S3 Full Access |
| SSH Key Pair | RSA 4096비트 키 자동 생성 |
| EBS 볼륨 | gp3 타입, 종료 시 자동 삭제 |
Conda 환경설정
name: sagemaker-vllm
channels:
- conda-forge
- defaults
dependencies:
- python=3.11
- pip
- ipykernel
- pip:
- sagemaker>=2.200.0
- boto3>=1.34.0
- huggingface-hub>=0.20.0
- requests>=2.31.0
- python-dotenv>=1.0.0
Qwen3 VL Fine Tuning 수행하기
환경 설정
필요한 환경 변수를 지정합니다.
import os, json, random, torch, boto3, tarfile
from pathlib import Path
from PIL import Image
from tqdm import tqdm
from dotenv import load_dotenv
from transformers import Qwen3VLForConditionalGeneration, AutoProcessor, TrainingArguments, Trainer, TrainerCallback
from peft import LoraConfig, get_peft_model, TaskType
from datasets import Dataset
load_dotenv()
os.environ["PYTORCH_CUDA_ALLOC_CONF"] = "expandable_segments:True"
MODEL_ID = os.getenv("MODEL_ID", "Qwen/Qwen3-VL-8B-Instruct")
S3_BUCKET = os.getenv("S3_BUCKET", "<YOUR_BUCKET_NAME>")
S3_PREFIX = os.getenv("S3_PREFIX", "<BUCKET_PREFIX>")
S3_DATA_PREFIX = "fine-tuning/data/construction-crack"
DATA_DIR = Path.cwd() / "data" / "construction-crack"
IMAGE_DIR = DATA_DIR / "images"
LABEL_DIR = DATA_DIR / "labels"
OUTPUT_DIR = Path.cwd() / "output"
OUTPUT_DIR.mkdir(exist_ok=True, parents=True)
Jupyter Lab으로 직접 업데이트하거나 S3에 업로드 한 후 다운로드 받습니다.
# S3에서 데이터 다운로드 (폴더가 없거나 비어있으면 실행)
if not IMAGE_DIR.exists() or not any(IMAGE_DIR.iterdir()):
DATA_DIR.mkdir(parents=True, exist_ok=True)
!aws s3 sync "s3://{S3_BUCKET}/{S3_DATA_PREFIX}/images/" "{IMAGE_DIR}/" --quiet
!aws s3 sync "s3://{S3_BUCKET}/{S3_DATA_PREFIX}/labels/" "{LABEL_DIR}/" --quiet
데이터 변환 함수
JSON 라벨 → VLM 학습용 대화 형식 변환을 수행합니다
CRACK_KO = {
"reticular crack": "망상균열", "crack": "균열", "damage": "손상", "leak": "누수",
"rebar": "철근노출", "material separation": "재료분리", "efflorescence": "백화",
"detachment": "박리", "spalling": "스폴링", "exhilaration": "들뜸"
}
def convert_crack_data(json_path: Path) -> dict | None:
try:
data = json.loads(json_path.read_text(encoding="utf-8"))
except:
return None
img_info = data.get("image", {})
annotations = img_info.get("annotations", [])
img_path = IMAGE_DIR / img_info.get("name", "")
if not annotations or not img_path.exists():
return None
img_w, img_h = img_info.get("width", 1920), img_info.get("height", 1080)
by_type = {}
for ann in annotations:
label = ann.get("label", "")
if label in CRACK_KO:
by_type.setdefault(label, []).append(ann.get("points", []))
defects, all_pts = [], []
for ctype, polys in by_type.items():
pts = [p for poly in polys for p in poly]
all_pts.extend(pts)
positions = []
for poly in polys:
if not poly:
continue
cx = sum(p[0] for p in poly) / len(poly)
cy = sum(p[1] for p in poly) / len(poly)
v = "상단" if cy < img_h/3 else "하단" if cy > img_h*2/3 else "중앙"
h = "좌측" if cx < img_w/3 else "우측" if cx > img_w*2/3 else "중앙"
positions.append(f"{v} {h}".replace("중앙 중앙", "중앙부"))
total_len = sum(
int(sum(((poly[i+1][0]-poly[i][0])**2 + (poly[i+1][1]-poly[i][1])**2)**0.5
for i in range(len(poly)-1)))
for poly in polys if len(poly) > 1
)
main_pos = max(set(positions), key=positions.count) if positions else "중앙부"
defects.append({
"type": ctype,
"type_ko": CRACK_KO[ctype],
"count": len(polys),
"location": main_pos,
"total_length_px": total_len
})
defects.sort(key=lambda x: x["count"], reverse=True)
if all_pts:
xs, ys = [p[0] for p in all_pts], [p[1] for p in all_pts]
spread_ratio = ((max(xs)-min(xs)) * (max(ys)-min(ys))) / (img_w * img_h)
spread = "넓게 분포" if spread_ratio > 0.15 else "중간 범위" if spread_ratio > 0.05 else "국소적"
else:
spread = "국소적"
response = json.dumps({
"total_defects": len(annotations),
"spread": spread,
"defect_types": list(by_type.keys()),
"defects": defects
}, ensure_ascii=False)
return {
"id": json_path.stem,
"image": str(img_path),
"conversations": [
{"from": "human", "value": "<image>\n이 이미지에서 콘크리트 결함을 분석해주세요."},
{"from": "gpt", "value": response}
]
}
데이터는 다음과 같이 변환됩니다.
{
"id": "GDM014_2023_01_00_001_117007",
"image": "/home/ubuntu/workspace/data/construction-crack/images/GDM014_2023_01_00_001_117007.jpg",
"conversations": [
{
"from": "human",
"value": "<image>\n이 이미지에서 콘크리트 결함을 분석해주세요."
},
{
"from": "gpt",
"value": "{\"total_defects\": 5, \"spread\": \"국소적\", \"defect_types\": [\"detachment\"], \"defects\": [{\"type\": \"detachment\", \"type_ko\": \"박리\", \"count\": 5, \"location\": \"하단 우측\", \"total_length_px\": 595}]}"
}
]
}
데이터 변환 및 분할 (8:1:1)
학습용으로 사용할 데이터와 검증, 테스트 용으로 사용할 데이터를 분리합니다.
data = [r for f in tqdm(list(LABEL_DIR.glob("*.json")), desc="Converting") if (r := convert_crack_data(f))]
print(f"Converted: {len(data)}")
random.seed(42)
random.shuffle(data)
n = len(data)
train_data, val_data, test_data = data[:int(n*0.8)], data[int(n*0.8):int(n*0.9)], data[int(n*0.9):]
print(f"Train: {len(train_data)}, Val: {len(val_data)}, Test: {len(test_data)}")
Converting: 100%|██████████| 2057/2057 [00:00<00:00, 8930.00it/s]
Converted: 2057
Train: 1645, Val: 206, Test: 206
모델 로드 + LoRA 설정
아래 각 키워드를 간략하게 정리했습니다.
- Flash Attention
- 거대한 N×N attention 행렬을 블록 단위로 나눠서 SRAM에서 계산해서 중간 결과를 HBM에 저장하지 않음으로써 메모리 왕복을 줄이는 최적화 기법입니다. 연산량은 동일하지만 SRAM ↔ HBM I/O가 줄어들어 2~4배 빨라지게 됩니다.
- LoRA (Low-Rank Adaptation)
- 파라미터 정보
r: 표현력 조절 (작으면 단순, 크면 복잡하지만 과적합 위험)lora_alpha: LoRA 변화량 스케일링 (alpha/r 비율로 영향력 조절)lora_dropout: 과적합 방지 (일부 뉴런 랜덤 비활성화)bias: "none"이면 bias 학습 안 함 (메모리 절약)task_type: CAUSAL_LM = 다음 토큰 예측 태스크
target_modules: Attention + MLP 레이어 선정
- 파라미터 정보
processor = AutoProcessor.from_pretrained(
MODEL_ID,
trust_remote_code=True,
min_pixels=256*28*28, # 최소 이미지 해상도: 200K pixels (메모리 효율)
max_pixels=1280*28*28, # 최대 이미지 해상도: 1M pixels (품질-메모리 균형)
)
model = Qwen3VLForConditionalGeneration.from_pretrained(
MODEL_ID,
torch_dtype=torch.bfloat16, # bf16: L40S 최적화, fp16 대비 수치 안정성 향상
device_map="auto", # 자동 GPU 배치
trust_remote_code=True,
attn_implementation="flash_attention_2", # FlashAttention2: 메모리 40% 절감, 속도 2배
)
model.gradient_checkpointing_enable() # 메모리 절약 (속도 약간 감소, VRAM 30-40% 절감)
# LoRA 설정: 전체 파라미터의 ~2%만 학습 → 메모리 효율적
lora_config = LoraConfig(
r=64, # rank: 높을수록 표현력 증가, 메모리 사용 증가 (권장: 32-128)
lora_alpha=128, # scaling factor: alpha/r = 2 (일반적으로 r의 1-2배)
lora_dropout=0.05, # 과적합 방지 (0.05-0.1 권장)
bias="none", # bias 학습 안함 (메모리 절약)
task_type=TaskType.CAUSAL_LM,
target_modules=[ # Qwen3-VL의 주요 attention + MLP 레이어
"q_proj", "k_proj", "v_proj", "o_proj", # attention
"gate_proj", "up_proj", "down_proj" # MLP (feed-forward)
]
)
model = get_peft_model(model, lora_config)
model.print_trainable_parameters() # 예상: ~2% trainable (약 160M / 8B)
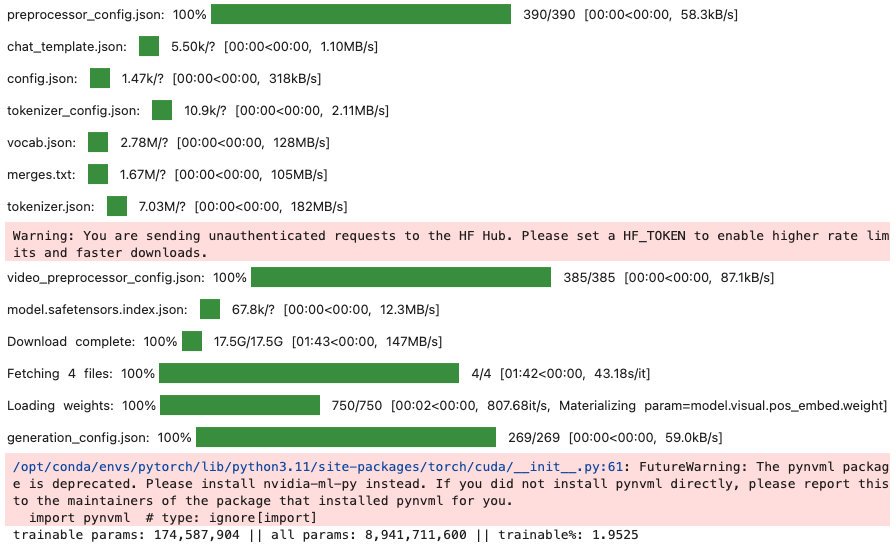
모델 LoRA가 설정된 것을 확인할 수 있습니다.
Data Collator(배치로 변환)
# 데이터 Collator: 이미지 + 텍스트를 모델 입력 형태로 변환
class CrackDataCollator:
def __init__(self, processor, max_length=1024): # JSON 응답은 ~500 tokens, 1024 충분
self.processor = processor
self.max_length = max_length
self.assistant_start = "<|im_start|>assistant"
def __call__(self, features):
texts, images = [], []
for item in features:
# 이미지 로드 (실패 시 빈 이미지로 대체)
try:
img = Image.open(item["image"]).convert("RGB")
except:
img = Image.new("RGB", (224, 224), "white")
# 대화 형식 변환
messages = []
for conv in item["conversations"]:
role = "user" if conv["from"] == "human" else "assistant"
content = conv["value"]
if "<image>" in content:
messages.append({
"role": role,
"content": [
{"type": "image", "image": img},
{"type": "text", "text": content.replace("<image>\n", "")}
]
})
else:
messages.append({
"role": role,
"content": [{"type": "text", "text": content}]
})
texts.append(self.processor.apply_chat_template(
messages, tokenize=False, add_generation_prompt=False
))
images.append(img)
# 토큰화 + 패딩
batch = self.processor(
text=texts,
images=images,
padding=True,
truncation=True,
max_length=self.max_length,
return_tensors="pt"
)
# 레이블 생성: assistant 응답 부분만 학습 (이전 토큰은 -100으로 마스킹)
labels = batch["input_ids"].clone()
assistant_ids = self.processor.tokenizer.encode(
self.assistant_start, add_special_tokens=False
)
for i in range(len(labels)):
input_ids = batch["input_ids"][i].tolist()
# assistant 시작 위치 찾기
for j in range(len(input_ids) - len(assistant_ids) + 1):
if input_ids[j:j+len(assistant_ids)] == assistant_ids:
labels[i, :j+len(assistant_ids)] = -100 # 프롬프트 부분 마스킹
break
# 패딩 토큰도 마스킹
labels[labels == self.processor.tokenizer.pad_token_id] = -100
batch["labels"] = labels
return batch
input_ids: shape=torch.Size([1, 1024]), dtype=torch.int64
attention_mask: shape=torch.Size([1, 1024]), dtype=torch.int64
pixel_values: shape=torch.Size([3772, 1536]), dtype=torch.float32
image_grid_thw: shape=torch.Size([1, 3]), dtype=torch.int64
labels: shape=torch.Size([1, 1024]), dtype=torch.int64
- input_ids + pixel_values → 모델 → output(logits) → labels와 비교 → loss → 역전파 → 학습
input_ids: 텍스트 토큰 ID (실제 모델 입력)attention_mask: 패딩 위치 마스크 (1=실제 토큰, 0=패딩) → 균일한 길이로 만듦pixel_values: 이미지 패치 (모델 입력)image_grid_thw: 이미지 그리드 정보 (temporal, height, width)labels: 정답 토큰 (-100=loss 계산 제외, 토큰ID=loss 계산 대상) → 출력과 비교하며 loss 계산- 정답 토큰에 얼마나 높은 확률을 줬는지로 loss 계산
Fine Tuning 수행하기
class S3CheckpointCallback(TrainerCallback):
def __init__(self, bucket: str, prefix: str):
self.bucket, self.prefix = bucket, prefix
self.s3 = boto3.client("s3") if bucket else None
def on_save(self, args, state, control, **kwargs):
if not self.s3:
return
ckpt_dir = Path(args.output_dir) / f"checkpoint-{state.global_step}"
if not ckpt_dir.exists():
return
s3_prefix = f"{self.prefix}/checkpoints/checkpoint-{state.global_step}"
for file in ckpt_dir.rglob("*"):
if file.is_file():
s3_key = f"{s3_prefix}/{file.relative_to(ckpt_dir)}"
self.s3.upload_file(str(file), self.bucket, s3_key)
S3로 Checkpoint를 저장할 수 있게 Callback을 구성합니다.
training_args = TrainingArguments(
output_dir=str(OUTPUT_DIR / "checkpoints"),
per_device_train_batch_size=4,
per_device_eval_batch_size=2,
gradient_accumulation_steps=12,
num_train_epochs=3,
learning_rate=1e-4,
lr_scheduler_type="cosine",
warmup_ratio=0.1,
weight_decay=0.01,
max_grad_norm=1.0,
gradient_checkpointing=True,
bf16=True,
optim="adamw_torch_fused",
logging_steps=10,
save_strategy="steps",
save_steps=50,
save_total_limit=2,
eval_strategy="steps",
eval_steps=50,
load_best_model_at_end=True,
metric_for_best_model="eval_loss",
greater_is_better=False,
remove_unused_columns=False,
dataloader_num_workers=4,
dataloader_pin_memory=True,
dataloader_prefetch_factor=2,
report_to="none",
seed=42,
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=Dataset.from_list(train_data),
eval_dataset=Dataset.from_list(val_data),
data_collator=CrackDataCollator(processor),
callbacks=[S3CheckpointCallback(S3_BUCKET, S3_PREFIX)],
)
torch.cuda.empty_cache()
trainer.train()
배치 및 학습 설정
per_device_train_batch_size=4: GPU당 학습 배치 크기gradient_accumulation_steps=12: 그래디언트 누적 스텝 (effective batch = 4×12 = 48)num_train_epochs=3: 전체 데이터셋 학습 반복 횟수
학습률 설정
learning_rate=1e-4: 초기 학습률 (LoRA는 1e-4~2e-4 권장)lr_scheduler_type="cosine": 학습률 스케줄러 (cosine: 부드러운 감소)warmup_ratio=0.1: 전체 스텝의 10%를 워밍업에 사용
정규화 및 안정성
weight_decay=0.01: L2 정규화 (과적합 방지)max_grad_norm=1.0: 그래디언트 클리핑 (학습 안정성)
메모리 및 성능 최적화
gradient_checkpointing=True: VRAM 절약 (속도↓, 메모리↑↑)bf16=True: bfloat16 혼합 정밀도 학습optim="adamw_torch_fused": Fused AdamW (최적화 속도 향상)
체크포인트 설정
save_steps=50/eval_steps=50: 50스텝마다 체크포인트 저장 및 평가save_total_limit=2: 최근 2개 체크포인트만 유지 (디스크 절약)load_best_model_at_end=True: 학습 종료 시 eval_loss 기준 최적 모델 로드
데이터 로딩
dataloader_num_workers=4: 데이터 로딩 병렬 워커 수dataloader_pin_memory=True: GPU 전송 최적화
학습은 다음과 같이 구성됩니다.


체크포인트가 저장되었다면 최종적으로 파인튜닝이 완료되었습니다.
테스트 데이터셋 평가하기
최종 테스트 데이터 셋으로 평가를 수행할 수 있습니다.
test_results = trainer.evaluate(eval_dataset=Dataset.from_list(test_data))
history = trainer.state.log_history
{
"train_loss": next((h["loss"] for h in reversed(history) if "loss" in h), None),
"val_loss": next((h["eval_loss"] for h in reversed(history) if "eval_loss" in h), None),
"test_loss": test_results["eval_loss"]
}

모델 저장 & 병합하기
배포를 위해 LoRA 설정 값을 S3에 병합하여 저장합니다.
lora_path = OUTPUT_DIR / "lora_adapter"
lora_path.mkdir(exist_ok=True)
model.save_pretrained(str(lora_path))
processor.save_pretrained(str(lora_path))
# transformers 버그 수정: extra_special_tokens가 list로 저장되는 문제
tokenizer_config_path = lora_path / "tokenizer_config.json"
if tokenizer_config_path.exists():
config = json.loads(tokenizer_config_path.read_text())
if "extra_special_tokens" in config and not isinstance(config["extra_special_tokens"], dict):
config["extra_special_tokens"] = {}
tokenizer_config_path.write_text(json.dumps(config, indent=2, ensure_ascii=False))
tar_path = OUTPUT_DIR / "lora_adapter.tar.gz"
with tarfile.open(tar_path, "w:gz") as tar:
for f in lora_path.iterdir(): tar.add(f, arcname=f.name)
if S3_BUCKET:
s3 = boto3.client("s3")
s3.upload_file(str(tar_path), S3_BUCKET, f"{S3_PREFIX}/lora_adapter.tar.gz")
print(f"Uploaded: s3://{S3_BUCKET}/{S3_PREFIX}/lora_adapter.tar.gz")
merged_path = OUTPUT_DIR / "merged_model"
merged_path.mkdir(exist_ok=True)
merged_model = model.merge_and_unload()
merged_model.save_pretrained(str(merged_path), safe_serialization=True)
processor.save_pretrained(str(merged_path))
del merged_model
torch.cuda.empty_cache()
# S3로 직접 업로드 (압축 없음 - vLLM DLC는 S3Prefix 지원)
if S3_BUCKET:
import subprocess
s3_path = f"s3://{S3_BUCKET}/{S3_PREFIX}/merged-model/"
subprocess.run(["aws", "s3", "sync", str(merged_path), s3_path], check=True)
print(f"Uploaded: {s3_path}")
Sagemaker를 통해 Fine Tuning 모델 배포하기
환경 설정
import os
import json
import boto3
from dotenv import load_dotenv, find_dotenv
load_dotenv(find_dotenv(), override=True)
AWS_PROFILE = os.environ.get("AWS_PROFILE", "default")
DEPLOY_REGION = os.environ.get("AWS_REGION", "us-east-1")
boto_session = boto3.Session(profile_name=AWS_PROFILE, region_name=DEPLOY_REGION)
sm_client = boto_session.client("sagemaker")
s3_client = boto_session.client("s3")
runtime_client = boto_session.client("sagemaker-runtime")
sts_client = boto_session.client("sts")
account_id = sts_client.get_caller_identity()["Account"]
role = os.environ.get("SAGEMAKER_ROLE", f"arn:aws:iam::{account_id}:role/SageMakerExecutionRole")
배포를 위한 vLLM DLC 이미지는 deep-learning-containers/vllm 레포지토리를 참고합니다.
VLLM_IMAGE_URI = f"763104351884.dkr.ecr.{DEPLOY_REGION}.amazonaws.com/vllm:0.13-gpu-py312"
MODEL_ID = "/opt/ml/model"
S3_BUCKET = os.environ.get("S3_BUCKET", "bjchoi-standard-bucket-v1")
S3_PREFIX = os.environ.get("S3_PREFIX", "qwen3-vl-crack-detection")
MERGED_MODEL_S3_PATH = f"s3://{S3_BUCKET}/{S3_PREFIX}/merged-model/"
INSTANCE_TYPE = "ml.g6e.xlarge"
ENDPOINT_NAME = "qwen3-vl-crack-detection"
vLLM 서버를 설정합니다. 아래 설정을 참고.
MAX_PIXELS = 1560 * 1560
env = {
"SM_VLLM_model": MODEL_ID,
"SM_VLLM_dtype": "bfloat16",
"SM_VLLM_max_model_len": "16384",
"SM_VLLM_gpu_memory_utilization": "0.9",
"SM_VLLM_trust_remote_code": "true",
"SM_VLLM_limit_mm_per_prompt": '{"image": 4}',
"SM_VLLM_mm_processor_kwargs": f'{{"min_pixels": {256 * 28 * 28}, "max_pixels": {MAX_PIXELS}}}',
}
Best Checkpoint를 조회합니다. 모델이 수행된 결과에서도 확인 가능합니다.
best_metric→trainer_state.json파일을 참고합니다.

{
"best_global_step": 100,
"best_metric": 0.04947521910071373,
"best_model_checkpoint": "/home/ubuntu/workspace/output/checkpoints/checkpoint-100",
"epoch": 2.8737864077669903,
"eval_steps": 50,
"global_step": 100,
"is_hyper_param_search": false,
"is_local_process_zero": true,
"is_world_process_zero": true,
"log_history": [
{
"epoch": 0.2912621359223301,
"grad_norm": 1.2939338684082031,
"learning_rate": 8.181818181818183e-05,
"loss": 1.5467738151550292,
"step": 10
},
{
"epoch": 0.5825242718446602,
"grad_norm": 0.50773686170578,
"learning_rate": 9.822345875271883e-05,
"loss": 0.17489180564880372,
"step": 20
},
{
...
},
{
"epoch": 2.8737864077669903,
"eval_loss": 0.04947521910071373,
"eval_runtime": 39.1991,
"eval_samples_per_second": 5.255,
"eval_steps_per_second": 2.628,
"step": 100
}
],
"logging_steps": 10,
"max_steps": 105,
"num_input_tokens_seen": 0,
"num_train_epochs": 3,
"save_steps": 50,
"stateful_callbacks": {
"TrainerControl": {
"args": {
"should_epoch_stop": false,
"should_evaluate": false,
"should_log": false,
"should_save": true,
"should_training_stop": false
},
"attributes": {}
}
},
"total_flos": 2.4169341693100032e+17,
"train_batch_size": 4,
"trial_name": null,
"trial_params": null
}
best_checkpoint를 확인합니다.
import subprocess
import re
result = subprocess.run(
["aws", "s3", "ls", CHECKPOINT_S3_PATH],
capture_output=True, text=True
)
checkpoints = []
for line in result.stdout.strip().split("\n"):
match = re.search(r"(checkpoint-\d+)/", line)
if match:
checkpoints.append(match.group(1))
checkpoints = sorted(checkpoints, key=lambda x: int(x.split("-")[1]))
print(f"발견된 checkpoints: {checkpoints}")
BEST_CHECKPOINT = checkpoints[-1] if checkpoints else None
print(f"사용할 checkpoint: {BEST_CHECKPOINT}")
Sagemaker 모델 설정 & 배포
파인튜닝한 모델을 Sagemaker 모델로 등록합니다.
model_name = "qwen3-vl-crack-detection"
model_data_source = {
"S3DataSource": {
"S3Uri": MERGED_MODEL_S3_PATH,
"S3DataType": "S3Prefix",
"CompressionType": "None",
}
}
create_model_response = sm_client.create_model(
ModelName=model_name,
PrimaryContainer={
"Image": VLLM_IMAGE_URI,
"Environment": env,
"ModelDataSource": model_data_source,
},
ExecutionRoleArn=role,
)
엔드포인트를 생성합니다. vLLM DLC 0.13은 CUDA 12.9를 사용하므로 InferenceAmiVersion을 al2-ami-sagemaker-inference-gpu-3-1로 설정합니다.
%%time
endpoint_config_name = f"{ENDPOINT_NAME}-config"
sm_client.create_endpoint_config(
EndpointConfigName=endpoint_config_name,
ProductionVariants=[
{
"VariantName": "AllTraffic",
"ModelName": model_name,
"InstanceType": INSTANCE_TYPE,
"InitialInstanceCount": 1,
"ContainerStartupHealthCheckTimeoutInSeconds": 900,
"InferenceAmiVersion": "al2-ami-sagemaker-inference-gpu-3-1",
}
],
)
sm_client.create_endpoint(
EndpointName=ENDPOINT_NAME,
EndpointConfigName=endpoint_config_name,
)
waiter = sm_client.get_waiter("endpoint_in_service")
waiter.wait(EndpointName=ENDPOINT_NAME, WaiterConfig={"Delay": 30, "MaxAttempts": 60})
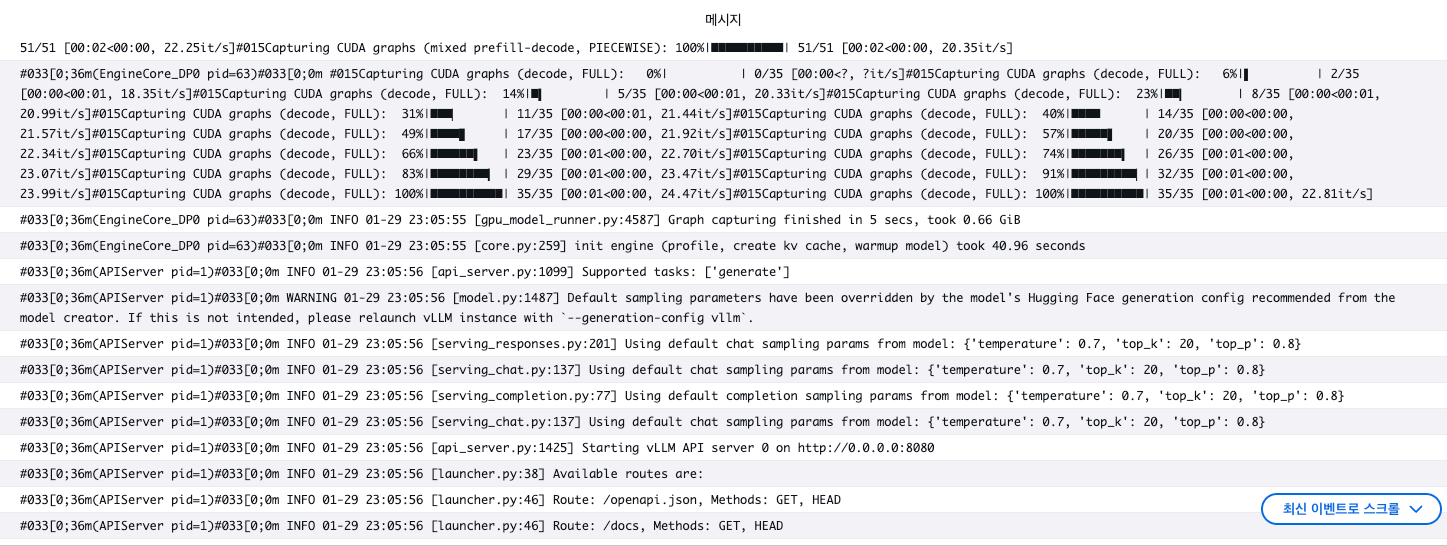
모델 배포가 완료되었습니다.
출력 확인
출력 코드는 다음과 같습니다.
import base64
import json
from pathlib import Path
def invoke_endpoint(image_path: str, prompt: str) -> dict | str:
with open(image_path, "rb") as f:
image_b64 = base64.b64encode(f.read()).decode()
ext = Path(image_path).suffix.lower()
mime_type = {"jpg": "jpeg", "jpeg": "jpeg", "png": "png"}.get(ext.lstrip("."), "jpeg")
payload = {
"model": MODEL_ID,
"messages": [
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {"url": f"data:image/{mime_type};base64,{image_b64}"}
},
{"type": "text", "text": prompt}
]
}
],
"max_tokens": 512,
"temperature": 0.7,
"repetition_penalty": 1.15,
}
response = runtime_client.invoke_endpoint(
EndpointName=ENDPOINT_NAME,
ContentType="application/json",
Body=json.dumps(payload)
)
result = json.loads(response["Body"].read())
content = result["choices"][0]["message"]["content"]
try:
return json.loads(content)
except json.JSONDecodeError:
return content
{
"total_defects": 2,
"spread": "넓게 분포",
"defect_types": [
"detachment"
],
"defects": [
{
"type": "detachment",
"type_ko": "박리",
"count": 2,
"location": [
138,
207
],
"location_ko": "(x=138, y=207) 근처",
"size": "중간 범위",
"size_ko": "중간 범위",
"shape": "불규칙적",
"shape_ko": "불규칙형"
}
]
}
결과 값을 확인하며 위 과정을 반복하여 개선합니다. 테스트 과정에서는 명시적인 프롬프트를 지정하지 않아 출력이 각기 다른 것을 확인할 수 있습니다. 더 좋은 결과물을 만들기 위해선 아래 내용 들을 고민해보는 것이 좋습니다.
- 하이퍼파라미터 튜닝: rank(r), learning rate, target modules 조합 실험
- Multi-GPU 학습: DeepSpeed/FSDP를 활용한 분산 학습 확장
- Fine-Tuning 프레임워크: Unsloth 등을 사용하여 Reinforcement learning, LoRA 기반 튜닝 간소화
- 명시적인 입출력 지정:
![[AI/ML] Qwen3-VL-4B 강화 학습(RL) 기반 파인튜닝(Unsloth) 가이드](https://images.unsplash.com/photo-1498457349504-289ee698e52c?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDZ8fFJlaW5mb3JjZW1lbnR8ZW58MHx8fHwxNzcwMTE3OTE4fDA&ixlib=rb-4.1.0&q=80&w=960)
![[SageMaker] SageMaker Jumpstart를 사용한 LLM Fine Tuning - DAFT(Domain-Agnostic Fine-Tuning)](https://images.unsplash.com/photo-1563207769-3343cb585fcb?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDZ8fHR1bmluZ3xlbnwwfHx8fDE3NTM4MzE2Mjl8MA&ixlib=rb-4.1.0&q=80&w=960)