AWS 데이터 엔지니어링을 위한 AI/ML
AWS 데이터 엔지니어링 서비스(Data Pipeline, Batch, DMS, Step Functions 등)로 데이터 이동, 처리, 마이그레이션, 워크플로우를 효율적으로 구축하세요.

AWS Data Pipeline
데이터를 한 곳에서 다른 곳으로 옮기는 서비스입니다.
ETL이 대표적이며 시험에 나올만한 아키텍쳐만 정리하였습니다.
- 목적지로 s3, RDS, DynamoDB, Redshift, EMR 등이 있습니다.
- 작업 종속성을 관리하기 위해 데이터 파이프라인을 사용합니다.
- 실제 ETL은 데이터 파이프라인에서 발생하지 않고 데이터 파이프라인의 ec2를 실행하여 작업하게 됩니다.
- 오케스트레이션 서비스로 실패에 대해 재시도와 알림을 주는 여러 기능들이 있습니다.
- 온프레미스 데이터 소스도 사용 가능합니다.
- 고가용성입니다.
Data Pipeline example
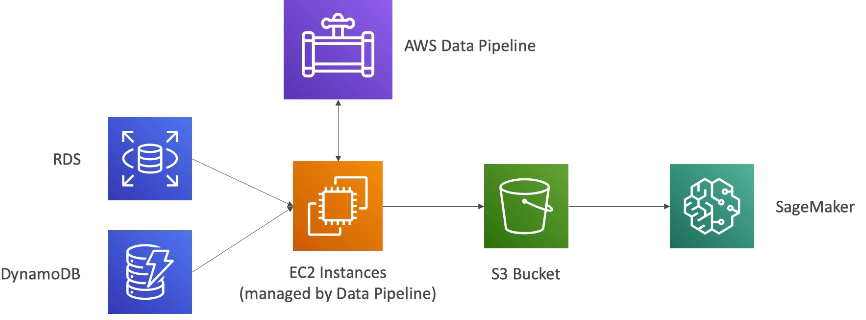
AWS Data Pipeline vs. Glue
Glue
- Glue ETL - Aparche Spark code, Scala, Python 기반의 ETL 작업을 포커스합니다.
- Glue ETL - 리소스를 관리하고 구성하는 수고가 필요없습니다.
- Data Catalog는 데이터를 다른 서비스에서 사용 가능하게 만들어줍니다. (Athena, Redshfit)
- AWS가 관리하기 때문에 환경을 통제하거나 리소스를 조절하는게 어렵습니다.
Data Pipeline
- 오케스트레이션 서비스로 실제 실행되지않아 코드와 코드 자체를 실행하는 컴퓨팅 리소스 환경을 훨씬 더 통제할 수 있습니다.
- 모든 리소스가 사용자의 계정 내에서 생성되기 때문에 EC2 혹은 EMR 같은 서비스로 직접 접근이 가능합니다.
정리하면 둘 다 ETL 서비스이지만 Glue는 데이터 변환을 해주는 ETL 서비스로써 Apache Spark에 훨씬 집중되어있습니다. 반면 Data Pipeline은 오케스트레이션 서비스로 사용자의 ec2나 EMR 인스턴스 환경에서 실행됩니다.
AWS Batch
Docker 이미지 기반 배치 작업을 실행하는 서비스입니다.
- 스팟 인스턴스를 통한 동적인 프로비저닝이 가능합니다.
- 배치 구성은 작업의 양, 요구사항을 기반으로 최적의 인스턴스 유형을 계산합니다.
- 클러스터를 관리할 필요없이 완전 관리형 서버리스 서비스입니다.
- ec2 인스턴스를 사용한만큼만 비용을 지불하게 됩니다.
- CloudWatch Events를 이용해서 배치작업을 스케쥴할 수 있습니다.
- AWS Step Function을 사용하여 배치 작업을 조율할 수 있습니다.
AWS Batch VS Glue
Glue
- Apache Spark 기반 Code, Scala 혹은 Python 기반 ETL 작업에 포커스 되어있습니다.
- ETL작업을 위해 리소스를 구성하거나 관리할 필요가 없습니다.
- 데이터 카탈로그를 통해 다른 곳에서도 데이터를 사용할 수 있게 만들어줍니다.
Batch
- Docker image에 어떤 작업을 넣든 상관없이 ETL 뿐만 아니라 일괄처리 방식이면 사용될 수 있습니다.
- 이미지가 있는한 배치 작업을 실행가능합니다.
- S3 버킷을 정리한다거나 S3 버킷에서 스크립트를 실행해 특정 작업을 하는 경우 유용할 수 있습니다.
- 리소스는 사용자의 계정에서 생성되며 사용자의 ec2 인스턴스를 Batch 서비스에서 관리합니다.
- ETL과 관련없는 작업인데 배치 기반이라면 AWS Batch를 사용할 수 있습니다.
Glue에서 중요한건 데이터를 모아 변형한 다음 다른 곳으로 적재하거나 보강할 수 있다는 것입니다.
AWS DMS - Database Migration Service
온프레미스 데이터베이스를 AWS로 마이그레이션할 수 있게 해주는 서비스입니다.
- 스스로 복구가 가능하며, 탄력적으로 운영이 가능합니다.
- 소스DB는 마이그레이션 중 사용가능합니다.
- 소스와 타겟 모두 동일 엔진 뿐만 아니라 다른 엔진이라도 지원합니다.
- CDC를 통한 지속적인 복제가 가능합니다.
- 복제 작업은 작업을 하는 특정 EC2 인스턴스를 생성하여 이루어지게 됩니다.
AWS DMS vs Glue
Glue
- Apache Spark 기반 Code, Scala 혹은 Python 기반 ETL 작업에 포커스 되어있습니다.
- ETL작업을 위해 리소스를 구성하거나 관리할 필요가 없습니다.
- 데이터 카탈로그를 통해 다른 곳에서도 데이터를 사용할 수 있게 만들어줍니다
DMS
- 연속적인 데이터 복제입니다 > Glue는 배치형
- 어떤 종류의 데이터도 변환하는 작업을 하지 않습니다. 따라서 ETL 요구사항이 있다면 수행할 수 없고 따로 작업을 구성해야합니다.
- 일단 AWS에 저장되면, Glue를 통해 변환이 가능합니다.
AWS Step Functions
- 워크플로우를 조직화하고 디자인할 수 있습니다.
- 쉽게 시각화가 가능합니다.
- 고급 에러 핸들링과 코드 외부에서 재시도 매커니즘을 갖추고 있습니다.
- 모든 오케스트레이션은 단계별 함수에 의해 관리됩니다.
- 워크플로우를 추적할 수 있습니다.
- 여러 다른 서비스에서 어떻게 반응했고 무슨 일이 있었는지 알 수 있으며, 어떻게 작동했는지 확인할 수 있습니다. 동시에 작동하지 않으면 디버깅을 할 수 있습니다.
- 임의의 시간을 기다릴 수 있으며 최대 실행 시간을 1년까지 설정할 수 있습니다.
Example
각 단계별 서비스를 호출하거나 동작에 대해 정의할 수 있습니다.
머신러닝 모델을 훈련하거나 튜닝하는 방식입니다.
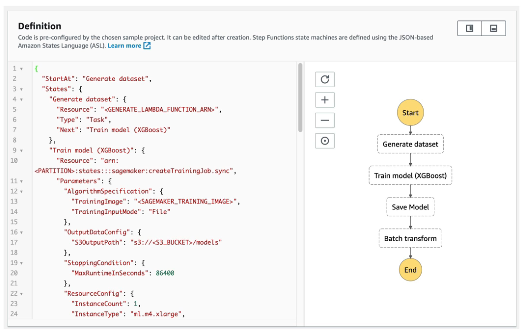
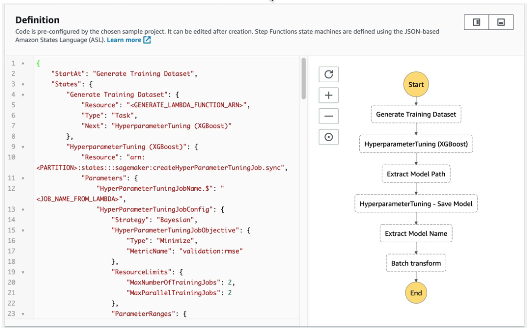
정리하면 과정을 오케스트레이션 하거나 자동화하여 연쇄적으로 작동하는 체인을 만들고자 한다면 Step Functions를 사용할 수 있습니다.
Data Engineering Pipeline Real-Time layer
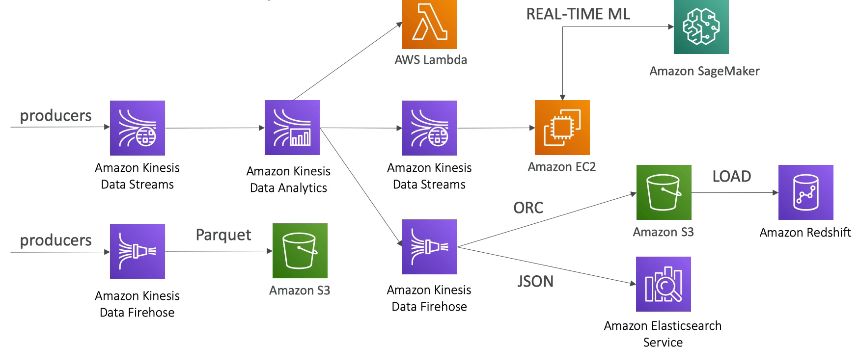
Data Engineering Pipeline Video layer
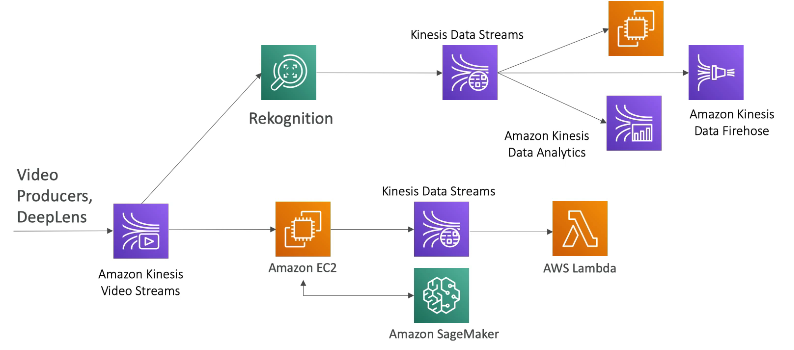
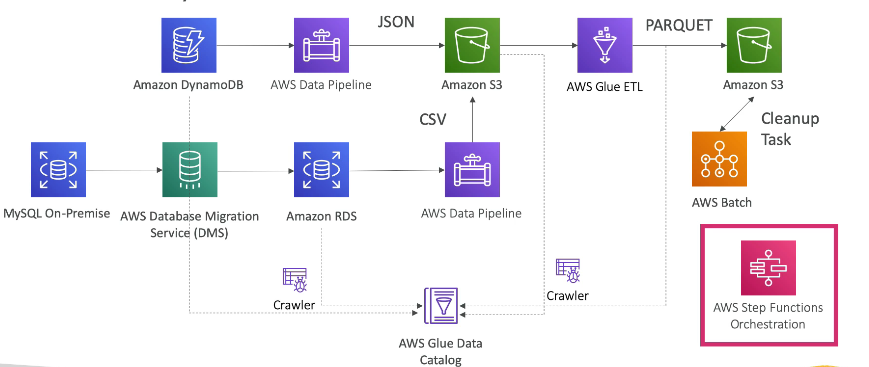
Data Engineering Pipeline Batch layer
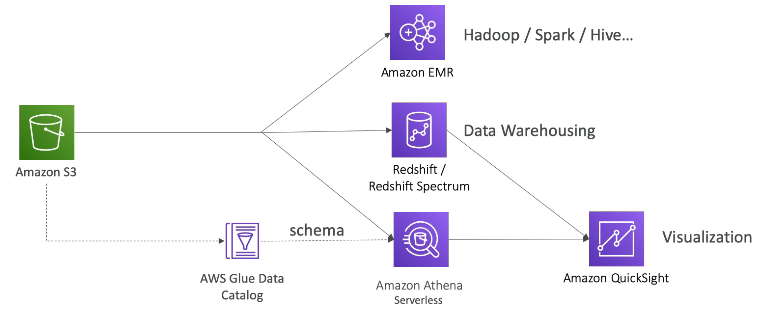
Data Engineering Pipeline Analytics layer
AWS DataSync
- 온프레미스 시스템에서 클라우드(EFS, FSx)나 S3 등으로 데이터를 마이그레이션하는 시스템입니다.
- 머신러닝으로 들어가면 훈련용으로 대량의 데이터를 s3로 전송하는데 사용할 수 있습니다.
- DataSync Agent를 통해 연결되어 데이터가 전송됩니다.
- 회사 내부에서 S3로 데이터가 이동하는 흐름으로 생각할 수 있습니다.
MQTT
- 머신러닝과는 별개로 인터넷 프로토콜입니다.
- IoT, 사물인터넷은 센서가 사방에 있어서 항상 중앙 저장소에 엄청난 야의 데이터를 공급하는 방식입니다.
- 머신러닝 모델을 교육하는 교육자료로 사용될 수 있으며, MQTT는 IoT 표준 메시지 프로토콜로 사용되어 데이터가 신뢰할 수 있는 곳으로 갈 수 있도록 여러 기능과 통신 방식을 설정할 수 있습니다.
- 많은 센서 데이터를 머신러닝 모델로 전송하는 방법이라고 생각할 수 있습니다.
- AWS IoT 장치와 SDK가 MQTT 통신을 하는 것입니다.
- MQTT는 IoT 흐름이라고 생각할 수 있습니다.
요약
- Amazon S3: 데이터를 위한 객체 스토리지
- VPC 엔드포인트 게이트웨이: 공용 인터넷을 통하지 않고 S3 버킷에 비공개로 액세스
- Kinesis Data Streams: 실시간 데이터 스트림, 용량 계획 필요, 실시간 애플리케이션
- Kinesis Data Firehose: S3, Redshift, ElasticSearch, Splunk로 거의 실시간으로 데이터 수집
- Kinesis Data Analytics: 스트리밍 데이터에 대한 SQL 변환
- Kinesis Video Streams: 실시간 비디오 피드
- Glue 데이터 카탈로그 및 크롤러: 계정의 스키마 및 데이터 세트에 대한 메타데이터 저장소
- Glue ETL: Spark 프로그램으로서의 ETL 작업은 서버리스 Spark 클러스터에서 실행됩니다.
- DynamoDB: NoSQL 스토어
- Redshift: OLAP, SQL 언어용 데이터 웨어하우징
- Redshift Spectrum: S3의 데이터에 대한 Redshift(Redshift에서 먼저 로드할 필요 없음)
- RDS/Aurora: OLTP, SQL 언어용 관계형 데이터 저장소
- ElasticSearch: 데이터 색인, 검색 기능, 클릭스트림 분석
- ElastiCache: 데이터 캐시 기술
- 데이터 파이프라인: RDS, DynamoDB, S3 간의 ETL 작업 오케스트레이션. EC2 인스턴스에서 실행
- 배치: 배치 작업은 Docker 컨테이너로 실행됩니다. 데이터뿐만 아니라 EC2 인스턴스도 관리합니다.
- DMS: 데이터베이스 마이그레이션 서비스, 1대1 CDC 복제, ETL 없음
- 단계 기능: 워크플로 조정, 감사, 재시도 메커니즘
Frank Kane이 간략하게 언급한 내용은 다음과 같습니다.
- EMR: 관리형 Hadoop 클러스터
- Quicksight: 시각화 도구
- Rekognition: ML 서비스
- SageMaker: ML 서비스
- DeepLens: Amazon의 카메라
- Athena: 데이터의 서버리스 쿼리
![[AWS] DynamoDB 스키마 설계 가이드](https://images.unsplash.com/photo-1554098415-788601c80aef?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDV8fFNRTHxlbnwwfHx8fDE3NjcyMzc1NDJ8MA&ixlib=rb-4.1.0&q=80&w=960)
![[MLOps] Apache Airflow 기능 및 용어 정리](https://images.unsplash.com/photo-1754928661805-ae4279a97218?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDR8fGFpcmZsb3d8ZW58MHx8fHwxNzU2MTI1OTkwfDA&ixlib=rb-4.1.0&q=80&w=960)
![[MLOps] Data Pipeline Orchestration - Airflow, Perfect](https://images.unsplash.com/photo-1600443446566-c8a2e34c779b?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDN8fE9yY2hlc3RyYXRpb258ZW58MHx8fHwxNzU2MTI2MDA5fDA&ixlib=rb-4.1.0&q=80&w=960)
![[MLOps] Data Cleaning & Data Transformation](https://images.unsplash.com/photo-1499244571948-7ccddb3583f1?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDN8fFRyYW5zZm9ybWF0aW9ufGVufDB8fHx8MTc1NTAwNjQxNnww&ixlib=rb-4.1.0&q=80&w=960)