[AWS] AWS 기반 데이터 파이프라인 서비스 정리
스트림과 배치 처리의 차이를 이해하고, Kinesis, Glue, Athena 등 다양한 AWS 데이터 서비스를 활용하여 효율적인 데이터 파이프라인을 구축하는 방법을 알아봅니다.
![[AWS] AWS 기반 데이터 파이프라인 서비스 정리](https://images.unsplash.com/photo-1507823690283-48b0929e727b?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDR8fHBpcGVsaW5lfGVufDB8fHx8MTc1NDIyNjIwOXww&ixlib=rb-4.1.0&q=80&w=1200)
개요
AWS 데이터 분석 파이프라인을
스트림과 배치의 차이
스트림과 배치를 구분하는 많은 특징들이 있지만, 학자들이 대표적으로 구분하는 방식은 데이터의 범위가 고정되어 있는지 (bounded), 고정되어 있지 않은지 (unbounded) 를 기준으로 삼고 있습니다.
배치 시스템은 대규모의 데이터를 고정된 시간 범위(특정 시간대) 안에 있는 ‘유한’ 데이터에 사용하는 시스템으로 보고, 스트림 프로세싱은 시간 범위가 고정되어 있지 않은 ‘무한’ 대의 데이터를 처리하는 것을 목표로 합니다.
따라서 배치는 스냅샷을 통해 지연시간이 높지만 대량의 데이터를 처리하는데 목적을 두고 있습니다. 스트림의 경우 지연시간이 낮고 연속적인 데이터를 처리하는데 목적이 있습니다.
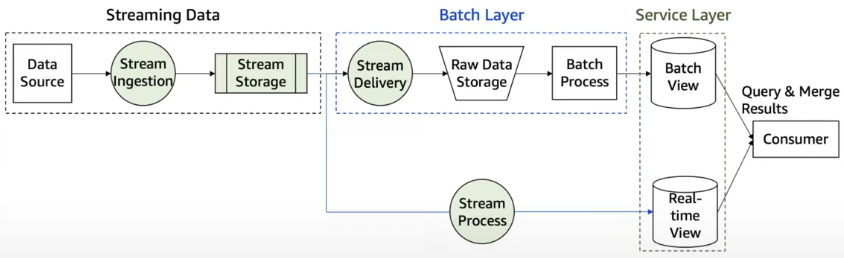
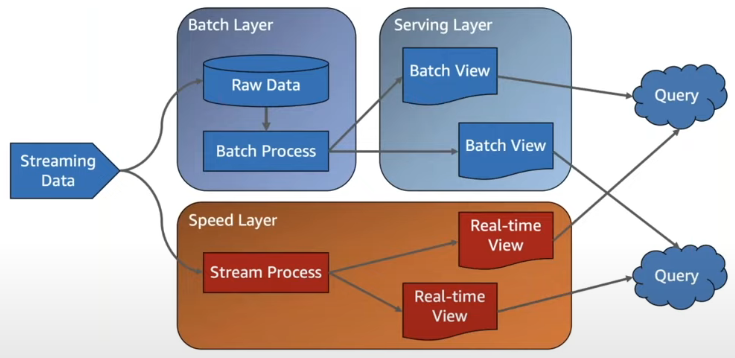
Data ingest
데이터의 권한 관리를 단순화하는 AWS Lake Formation 사용하기 - OpsNow
Kinesis
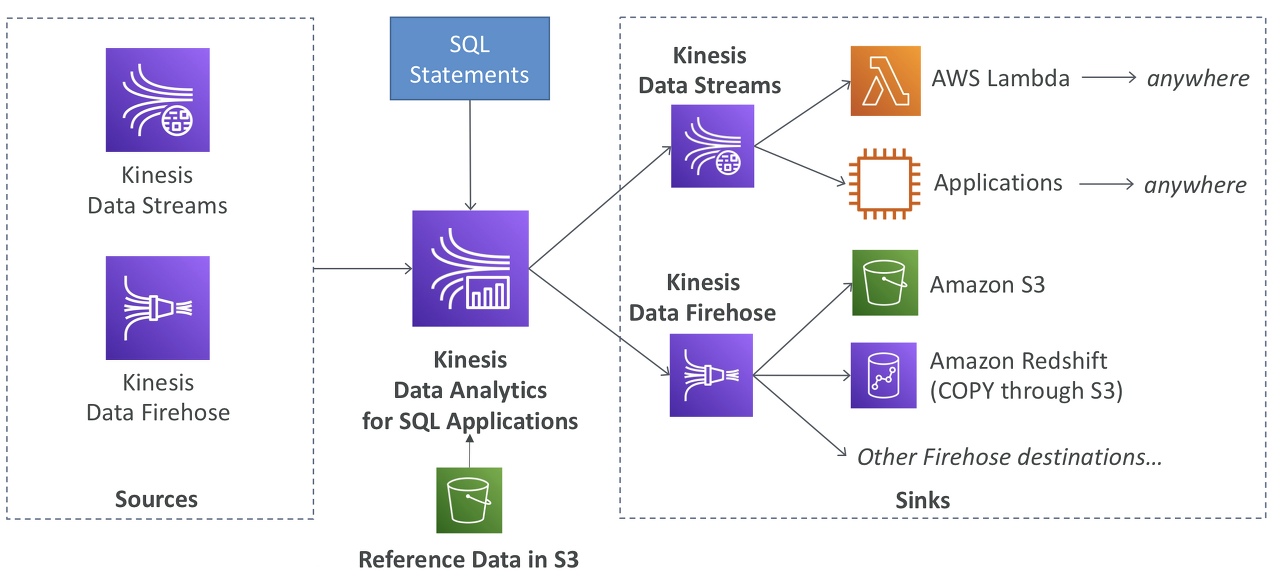
| 기능 | Kinesis Data Stream(저장) | Kinesis Data Firehose(로드와 전달) |
| 주요 용도 | 실시간 데이터 스트리밍 수집 및 저장 | 스트리밍 데이터를 캡처, 변환 및 AWS 데이터 스토어로 로드 |
| 데이터 처리 | 사용자 정의 데이터 처리를 허용 | 선택적 변환을 사용하여 자동으로 데이터 로드 |
| 관리 | 수동 확장 및 프로비저닝 필요(샤드) | 자동 확장 기능을 갖춘 완전 관리형 |
| 데이터 보존 | 24시간 ~ 7일 동안 보관되는 데이터 | 데이터를 저장하지 않고 지정된 목적지 직접 전달 |
Kinesis vs SQS ordering
프로듀서(producer)와 컨슈머(consumer)가 서로 메시지를 전달하는 디커플링
- 최소 메시지 크기는 1바이트(1자)입니다. 최대값은 262,144바이트(256KB)
- 데이터의 순서 보장의 어려움(SQS FIFO)
- 연속적인 MapReduce(여러 노드에 태스크를 분배하는 방법)가 불가능
- 병렬 소비는 불가능

Kinesis & MSK 정리
Apache Kafka용 Amazon 관리형 스트리밍(MSK)
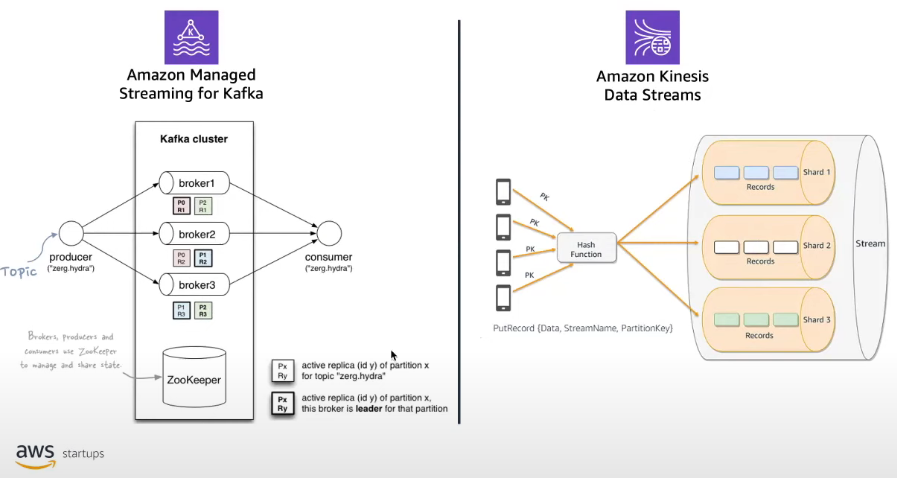
- 아키텍처: Amazon MSK는 클라우드에서 Apache Kafka 클러스터의 설정 및 운영을 단순화하는 관리형 서비스입니다. MSK의 Kafka 클러스터는 데이터 파티션을 관리하는 여러 브로커로 구성됩니다.
- Zookeeper: Zookeeper는 Kafka에서 중요한 역할을 합니다. 클러스터의 브로커 상태를 관리하고 파티션에 대한 리더 선택 및 클러스터 메타데이터 유지 관리와 같은 작업을 수행합니다. MSK에서 AWS는 Kafka 브로커와 함께 Zookeeper 노드를 관리하여 사용자의 복잡성을 최소화할 수 있도록 관리형 서비스를 제공하고 있습니다.
- 데이터 처리: Kafka에서는 데이터가 토픽 단위로 구성됩니다. 생산자는 주제에 데이터를 쓰고 소비자는 토픽에서 읽습니다. 병렬 처리가 가능하도록 각 토픽을 여러 파티션으로 분할할 수 있습니다. 파티션 내의 데이터는 순서가 지정되어 있으며 따로 순서를 변경할 수 없습니다.
- 확장성 및 파티션 관리: Kafka에서 확장하려면 더 많은 브로커를 추가하고 파티션을 다시 할당해야 합니다. 효율적인 확장을 위해서는 파티션 수와 브로커 수 간의 균형이 중요합니다. MSK에서는 각 브로커와 브로커의 스토리지를 조정할 수 있지만 스토리지를 줄이는 것과 브로커를 줄이는 것은 불가능하기 때문에, 클러스터를 설계할 때는 브로커, 토픽, 파티션 수를 고려하여 신중한 계획이 필요합니다.
- 이벤트 처리: Kafka 및 MSK에서는 데이터 단위를 메시지 또는 이벤트라고 합니다.
Amazon Kinesis 데이터 스트림
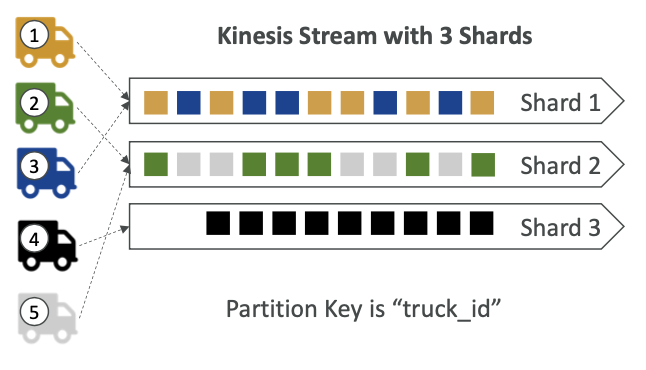
- 아키텍처: Kinesis Data Streams는 실시간 데이터 스트리밍을 위해 설계된 대규모 확장 가능한 AWS 서비스입니다. 여러 개의 샤드로 구성되어 스트리밍을 중심으로 구성됩니다.
- 샤드: Kinesis 스트림의 각 샤드는 일련의 데이터 레코드입니다. 레코드가 스트림에 추가되면 해시 함수를 통해 샤드를 결정하는 파티션 키를 기반으로 샤드에 할당됩니다. 이렇게 하면 들어오는 순서에 따라 같은 샤드로 보낼 수 있고 순서대로 쓰여지기 때문에 샤드 내에서 데이터 순서가 보장됩니다.
- 확장성: Kinesis는 샤드 수를 조정하여 입력 및 출력 용량을 확장할 수 있는 유연성을 제공합니다. 샤드를 분할하거나 병합하여 동적으로 확장할 수 있습니다.
- 데이터 처리: MSK와 유사하게 Kinesis는 데이터를 실시간으로 처리합니다. 소비자는 각 샤드의 데이터를 독립적으로 읽고 처리할 수 있습니다.
- Zookeeper와의 비교: Kafka와 달리 Kinesis는 Zookeeper를 사용하지 않습니다. Kinesis의 용량 모드에 따라 샤드와 샤드 내부 데이터를 내부적으로 확장하여 관리합니다.
주요 차이점
- 관리: MSK는 관리형 서비스긴 하지만 각 파티션과 브로커에 대한 이해와 처리량에 따른 효율적인 설계가 필요한 반면 Kinesis는 AWS의 완전 관리형 스트리밍 서비스로 샤드에 대한 관리와 이해만 필요합니다.
- 확장성: Kinesis는 MSK의 파티션 및 브로커 관리에 비해 샤드 관리 측면에서 더 간단한 확장성을 제공합니다.
- 복잡성: MSK는 Zookeeper의 필요성과 더욱 복잡한 파티셔닝 및 브로커 관리로 인해 더욱 복잡합니다. Kinesis는 단순한 구조로 스트리밍 관리 및 확장을 단순화합니다.
- 처리량과 데이터 보존: Kinesis가 최대 365일까지 데이터 보존을 지원하는 반면 MSK는 영구적인 데이터 보존을 지원하지만 브로커와 데이터의 볼륨에 영향을 받습니다.
Kinesis Data firehose
Amazon Kinesis Data Firehose 주요 특징
- 주요 용도: Kinesis Data Firehose는 실시간 스트리밍 데이터를 캡처하고, 필요에 따라 변환하여 AWS의 다양한 데이터 스토어로 직접 로드하는 데 사용됩니다. 이는 데이터 분석, 보고 및 기타 처리를 위해 필요한 데이터를 효율적으로 전송하는 데 중점을 둡니다.
- 데이터 처리: Firehose는 선택적으로 데이터를 변환할 수 있는 기능을 제공합니다. 예를 들어, 스트리밍 데이터를 Amazon S3, Redshift, Elasticsearch Service 등으로 전송하기 전에 데이터 형식을 변경하거나 필요한 데이터를 추출할 수 있습니다.
- 관리: Kinesis Data Firehose는 완전 관리형 서비스로, 사용자는 스트림을 수동으로 확장하거나 관리할 필요가 없습니다. 서비스는 자동으로 확장되며, 사용자는 쉽게 데이터 전송 및 처리 규모를 조정할 수 있습니다.
- 데이터 보존: Firehose는 데이터를 중간 저장하지 않고 지정된 목적지로 직접 전달합니다. 이는 Kinesis Data Streams와 달리 데이터를 일정 기간 동안 보존하지 않는다는 것을 의미합니다. 스트리밍 데이터는 지정된 데이터 스토어로 바로 전송됩니다.
Resharding
- Kinesis Scaling, Resharding and Parallel Processing
- Using the Kinesis Client Library - Amazon Kinesis Data Streams
SQS vs Kinesis/MSK
Amazon SQS(Simple Queue Service)는 안정성과 확장성이 뛰어난 관리형 메시지 대기열 서비스이지만, 실시간 데이터 스트리밍을 위해 설계된 Amazon Kinesis Data Streams 및 Amazon Managed Streaming for Kafka(MSK)와는 다른 특성을 가지고 있습니다. SQS가 실시간 스트리밍 서비스에 가장 적합하지 않은 이유는 다음과 같습니다.
1. 처리량
- SQS: 높은 처리량과 안정적인 메시지 전달을 위해 설계되었지만 실시간 스트리밍에 필요한 지속적인 대용량 데이터 수집 및 처리가 반드시 필요한 것은 아닙니다.
- Kinesis/MSK: 두 서비스 모두 수천 개의 데이터 소스를 동시에 처리할 수 있는 기능을 갖춘 대용량 데이터 스트리밍을 위해 특별히 구축되었습니다.
2. 데이터 보존
- SQS: SQS의 메시지는 사용된 후 삭제됩니다. SQS는 장기간 메시지를 저장하지 않습니다.
- Kinesis/MSK: 지정된 기간(예: Kinesis는 최대 365일 허용) 동안 데이터를 저장할 수 있는 데이터 보존 정책을 제공하여 재처리 및 지연 처리를 가능하게 합니다.
3. 순서 및 파티셔닝
- SQS: 표준 대기열은 최소 한 번 전달을 제공하지만 주문을 보장하지는 않습니다. FIFO(선입선출) 대기열은 순서를 제공하지만 처리량 제한이 있습니다.
- Kinesis/MSK: 데이터가 샤드 또는 파티션 내에서 정렬되도록 파티션 키를 제공하여 훨씬 더 큰 규모에서 정렬된 처리를 지원합니다.
4. 소비자 상쇄
- SQS: 소비자 오프셋을 유지하지 않습니다. 메시지가 소비되고 삭제되면 다시 처리할 수 없습니다.
- Kinesis/MSK: 소비자는 오프셋을 관리하여 특정 지점에서 스트림을 재생하거나 재처리할 수 있으므로 데이터 소비 방식에 유연성을 제공합니다.
5. 스트림 처리
- SQS: 본질적으로 스트림 처리 프레임워크 및 애플리케이션용으로 설계되지 않았습니다.
- Kinesis/MSK: 복잡한 실시간 분석을 위해 스트림 처리 프레임워크(예: Apache Flink, Apache Spark, AWS Lambda)와 쉽게 통합됩니다.
6. 다중 소비자
- SQS: 각 메시지는 일반적으로 단일 소비자에 의해 소비됩니다.
- Kinesis/MSK: 각각 독립적으로 스트림을 처리할 수 있는 여러 소비자 및 소비자 그룹을 지원합니다.
7. 확장성 및 성능
- SQS: 확장 가능하지만 지속적으로 높은 처리량을 처리하는 수집에 대해 Kinesis 및 MSK와 동일한 수준의 성능을 제공하도록 설계되지 않았습니다.
- Kinesis/MSK: 높은 수집 속도를 처리하고 실시간 분석에 적합한 짧은 지연 시간 처리를 제공하도록 설계되었습니다.
8. 내구성 및 신뢰성
- SQS: 높은 내구성을 제공하지만 메시지 전달 의미 체계가 보장된 메시지 순서 및 정확히 한 번 처리가 필요한 애플리케이션의 요구 사항과 일치하지 않을 수 있습니다.
- Kinesis/MSK: 주문 및 배송에 대한 강력한 보장과 함께 내구성 있는 데이터 스토리지를 제공합니다.
결론적으로 SQS는 클라우드 애플리케이션의 구성 요소를 분리하기 위한 강력한 대기열 서비스이지만 Kinesis Data Streams 및 MSK와 같은 실시간 데이터 스트리밍 서비스가 처리하도록 구축된 패턴 및 사용 사례에 최적화되어 있지 않습니다. 처리량, 데이터 보존, 주문 보장 및 처리 기능에 대한 고려 사항을 포함하여 워크로드의 특정 요구 사항을 기반으로 이러한 서비스를 선택해야 합니다.
Amazon SQS
SQS는 스트리밍 서비스에 포함되지 않았는데 데이터 수집과 분석 관점에서 앞선 스트리밍 서비스와 큰 차이가 있습니다.
- 메시지 크기와 처리량: SQS는 메시지 크기가 최소 1바이트에서 최대 256KB로 제한되어 있으며, 초당 최대 3000개의 메시지를 처리할 수 있습니다.Kinesis Data Stream은 최대 쓰기 용량은 1MB와 읽기 용량은 2MB까지,MSK의 경우 최대 10MB까지 지원합니다.
- 데이터 순서와 병렬 소비: 다른 스트리밍 서비스들은 데이터의 순서를 보장하며, 여러 컨슈머가 동시에 데이터를 소비할 수 있도록 데이터를 그룹화하여 관리합니다. 반면, SQS는 데이터의 순차적 처리를 보장하는 FIFO(Frist In, First Out) 큐를 제외하고는 이러한 병렬 소비를 기본적으로 지원하지 않습니다.
- 데이터 저장: SQS는 최대 14일간 데이터를 보존하며 컨슈머가 처리하지 않으면 데이터는 소실된다는 단점이 있습니다.
따라서 SQS는 애플리케이션간 미들웨어로 간단한 메시지 전달, 작업 분배, 서비스 간의 비동기 통신 등 용도로 더 적합합니다.
데이터 레이크 인프라 & 관리
스키마와 데이터만 있으면 분석이 가능함 비정형 데이터를 정형화하여 원하는 정보를 얻는 것을 데이터분석
자연어 처리(NLP), 시각적 데이터 같은 이미지 처리를 통해 의미있는 정보를 추출
Lake Formation
- 데이터 레이크 생성을 돕는데 데이터 레이크란 데이터 분석을 위해 모든 데이터를 한곳으로 모아주는 중앙 집중식 저장소
- 데이터 레이크 생성을 수월하게 해주는 완전 관리형 서비스
- 데이터 검색, 정제, 변환 주입을 돕는다
- 복잡한 수작업을 자동화하고 기계학습 변환 기능으로 중복제거를 수행
- 정형 데이터와 비졍형 데이터 소스를 결합가능하며 블루 프린트를 제공한다
- 내장된 블루 프린트는 데이터를 데이터 레이크로 이전(마이그레이션)하는 것을 도와준다
- S3, RDS, NoSQL DB등을 지원
- 데이터를 한 곳에서 처리하는 것 외에도 행,열수준의 세분화된 엑세스 제어를 할 수 있다
- Glue위에서 작동하지만 직접 상호작용하지는 않는다
레이크 포메이션
중앙화된 권한 → 사용자가 볼 수 있는 데이터를 제어할 수 있다는게 핵심 IAM으로 권한 관리가 불가능함
따라서 보안 정책을 한 곳에서 설정할 수 있다는게 큰 이유이며 그게 아니라면 각 서비스마다 설정이필요함
- 주입된 데이터는 모두 중앙 S3 버킷에 저장되지만 행렬 수준 보안과 엑세스 제어는 Lake Formation에서 수행됨
- Lake Formation에 연결하는 서비스는 읽기 권한이 있는 데이터만 볼 수 있다
Amazon Lake Formation 기본 개념
- 데이터 레이크 정의: 다양한 형식의 데이터를 중앙 집중식 저장소에 모아 데이터 분석을 용이하게 하는 시스템입니다.
- 완전 관리형 서비스: 데이터 레이크의 생성을 간소화하고 관리 수월하게 해주는 완전 관리형 서비스입니다.
- 데이터 처리 기능: 데이터 검색, 정제, 변환, 주입을 돕습니다. 복잡한 수작업을 자동화하고 기계학습 변환 기능으로 중복제거를 수행하며 데이터 준비 과정을 자동화합니다.
- 데이터 소스의 다양성: 정형 데이터와 비정형 데이터 소스 모두를 지원하며, AWS S3, RDS, NoSQL DB 등과 같은 다양한 데이터 소스와 통합될 수 있습니다.
- 블루 프린트 기능: 내장된 블루 프린트를 통해 데이터를 데이터 레이크로 이전하는 과정을 간소화합니다.
Amazon Lake Formation의 보안 및 접근 제어
- 중앙화된 권한 관리: 데이터에 대한 접근 제어를 중앙에서 관리할 수 있게 해줍니다. 이게 안된다면 각 서비스에 데이터 읽기 권한과 쓰기 권한을 설정해야합니다.
- 행, 열 수준의 엑세스 제어: 데이터를 한 곳에서 처리하면서도 행과 열 수준에서 세분화된 접근 제어가 가능합니다.
이를 통해 Lake Formation에 연결된 서비스는 중앙에 설정된 권한에 따라 데이터를 읽을 수 있습니다.
- AWS IAM과의 차이: Lake Formation의 보안 정책은 AWS IAM과 다르게 동작합니다. Lake Formation은 데이터 레이크 내의 데이터에 대한 접근을 더 세분화하여 관리할 수 있습니다.
결론
Amazon Lake Formation은 데이터 레이크 구축과 관리를 간소화하는 데 중점을 둔 서비스입니다. 이는 데이터의 중앙화, 다양한 데이터 소스의 통합, 그리고 세분화된 보안 및 접근 제어 기능을 통해 데이터 분석 및 기계학습 프로젝트를 효율적으로 지원합니
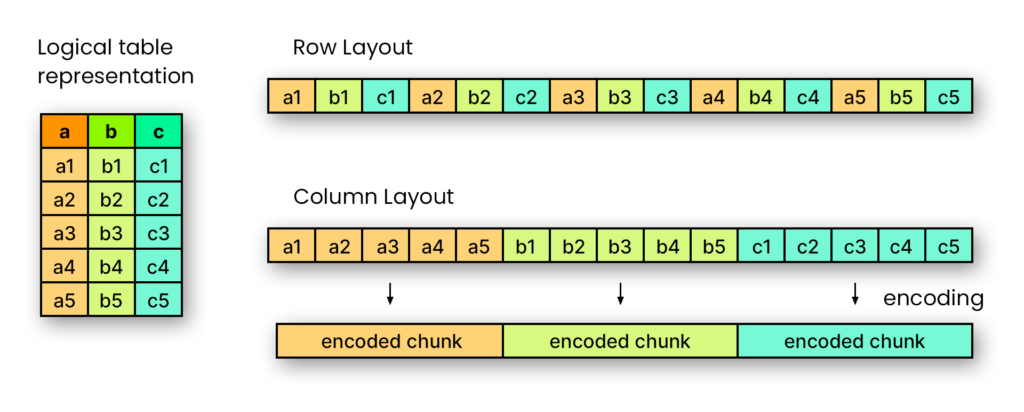
Parquet
데이터 분석에서 사용되는 파일로로 Column(열) 기반으로 저장됩니다. 반대로 행 기반 저장 방식은 데이터 입출력이 빈번한 방식에 효과적으로 사용
열(Column) 형식에서는 한 열의 값이 서로 옆에 저장되어 일반적으로 매우 효율적인 인코딩이 가능하므로 파일 크기는 일반적으로 행(row) 중심 파일보다 작습니다.
OLTP 워크로드는 데이터 조작을 선호하므로 행 형식을 사용하는 반면, OLAP 워크로드는 열 형식을 사용합니다.
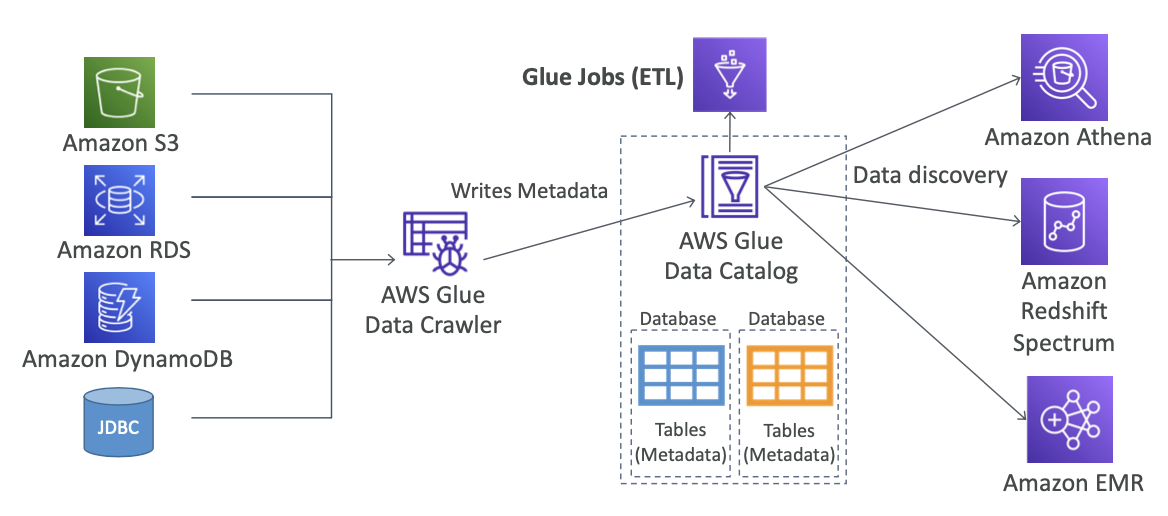
Glue

⇒ 서버리스기반 Spark style
- 추출과 변환, 적재하는 ETL 서비스(Extract, Transform, Load)
- 데이터 분석 하려는 사용자가 여러 소스의 데이터를 쉽게 검색, 준비, 이동, 통합할 수 있도록 하는 서버리스 데이터 통합 서비스
- 분석을 위해 데이터 준비 변환에 매우 유용
AWS Glue Data Catalog
증가하는 데이터 볼륨을 관리하고 활용하는 데 따른 문제를 해결하기 위해 만들어진 방식으로 메타데이터를 저장하고 구성하는 중앙 집중식 시스템을 제공하여 데이터 검색, 거버넌스 및 규정 준수를 촉진하는 역할을 합니다.
카탈로그에서 가장 중요한 기능들은 얼마나 많은 데이터 소스들 (데이터 베이스, API들)과 연결을 할 수 있냐와 연결된 데이터 소스들로부터 가지고 온 메타데이터 (테이블, 컬럼, 폴더, 등등)에 대한 검색 및 관리이다.
메타 데이터란 데이터에 관한 데이터. 다른 데이터에 대한 정보를 제공하므로 특정 데이터 세트를 더 쉽게 찾고, 사용하고, 관리 가능. 예를 들어, 사진의 메타데이터에는 사진 촬영 날짜, 사용된 카메라 유형, 조리개 및 셔터 속도와 같은 설정과 같은 세부 정보가 포함.
Data Crawler를 통해 리소스에서 데이터를 가져와 ETL작업을 거쳐 다른 데이터 분석 서비스로 전달이 가능함.
- 서버리스 ETL: 서버리스로 데이터 추출(Extract), 변환(Transform), 적재(Load) 과정을 자동화합니다. 데이터 분석을 위한 데이터 준비 작업에 매우 유용하며 여러 소스의 데이터를 쉽게 검색, 준비, 이동, 통합할 수 있게 돕습니다.
- 데이터 변환에 유용: 서버리스 환경에서 Spark 스타일 처리를 제공하여, 사용자가 복잡한 인프라 관리 없이 데이터 처리 작업을 수행할 수 있습니다.
AWS Glue Data Catalog
- 메타데이터 관리: 중앙 집중식 시스템으로, 다양한 데이터 소스(데이터베이스, API 등)의 메타데이터를 저장하고 관리합니다. 이는 거버넌스, 규정 준수를 지키는데 도움을 주고 여러 데이터 소스에서도 데이터 검색을 할 수 있도록 도와주는 역할을 합니다.
- 메타데이터의 생성: 메타데이터는 '데이터에 관한 데이터'로 정의됩니다. 예를 들어, 사진의 메타데이터는 촬영 날짜, 카메라 유형, 조리개 설정 등 다른 데이터를 정의하고 기술하는 데이터로 이해할 수 있습니다.
- Data Crawler 기능: AWS Glue의 Data Crawler는 다양한 리소스에서 데이터를 자동으로 탐지하고, 메타 데이터를 추출하는 등 ETL 작업을 위해 사용할 수 있는 형식으로 변환합니다.
AWS Glue의 고려사항
- 스크립트 개발 필요성: AWS Glue는 다양한 기능을 제공하지만, 특정 사용 사례에 맞추기 위해서는 스크립트 개발이 필요할 수 있습니다.
- Spark 및 Glue 환경 이해 필요: AWS Glue는 Apache Spark를 기반으로 한 서비스입니다. 따라서 Spark의 개념(예: RDD, DataFrame) 및 Glue의 작동 방식에 대한 기본적인 이해가 필요할 수 있습니다.
정리
AWS Glue는 데이터 통합, ETL 작업, 메타데이터 관리 등을 자동화하는 서버리스 서비스입니다. 이를 통해 데이터 분석과 관련된 작업을 효율적으로 처리할 수 있으며, 특히 클라우드 환경에서의 데이터 분석에 강력한 도구로 활용됩니다. 그러나 사용자는 이 서비스의 다양한 기능과 Apache Spark에 대한 기본적인 이해가 필요할 수 있습니다.
단점
- 서비스 자체에서 굉장히 다양한 기능을 다루기때문에 Script의 개발이 필요할 수 있습니다.
- Spark(RDD(Resilient Distributed Dataset), DataFrame 및 인메모리 데이터 처리), Glue 환경에 대한 이해가 필요합니다
분석 / 배치
Athena

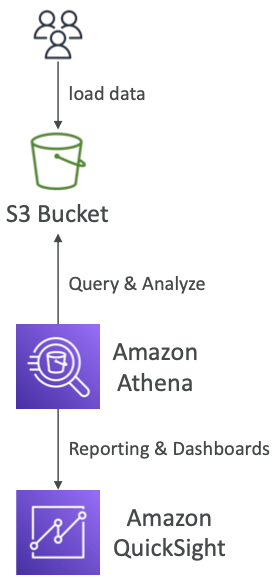
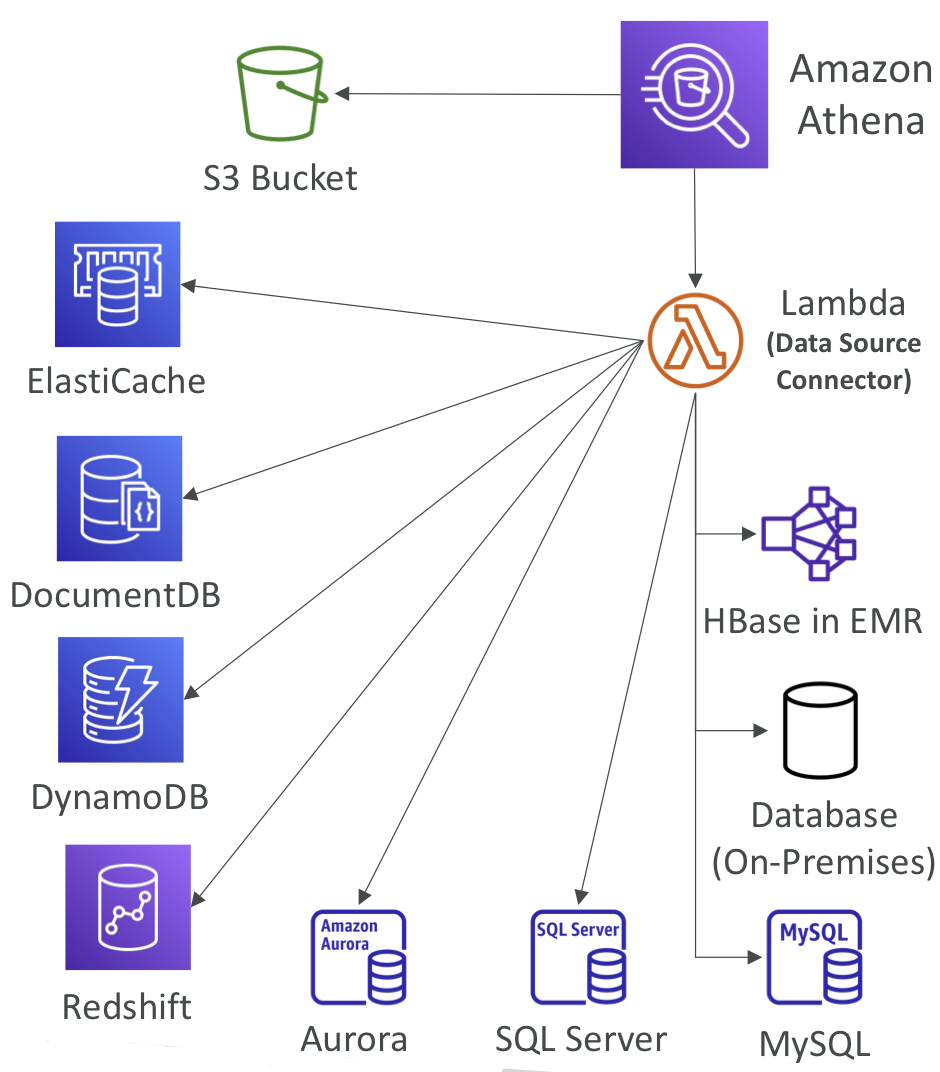

- S3 버킷에 저장된 데이터 분석에 사용하는 서버리스 쿼리 서비스
- 표준 SQL언어로 파일을 쿼리하면 서버리스로 SQL 언어를 사용하는 Presto라는 인메모리 엔진에 빌드
- 버킷의 데이터를 바로 분석가능하며 CSV, JSON, ORC, Avro, Parquet을 지원
- 가격 책정은 간단하며 스캔된 데이터의 TB당 고정 가격을 지불하기 때문에 프로비저닝이 필요 없다.
성능 최적화
- Apache Parquet과 ORC을 사용하면 성능이 크게 향상된다
- Glue등으로 CSV와 Parquet간의 데이터 전환이 가능
- 데이터를 압축하여 더 적게 검색 > 큰 파일을 사용해 오버헤드 최소화
- 데이터 분할(Partitioning)을 통해 검색하는 데이터의 양을 제한하여 성능향상
단점
대용량 쿼리나 정기적 배치 처리에는 추천되지 않습니다. Athena의 리소스를 사용자가 독점하는 방식이 아니라 Region별로 리소스를 공유됩니다.
동시 쿼리(기본적으로 20개), S3 요청 수, 시간 초과(30분), 쿼리가 처리할 수 있는 행 및 열 수, 테이블 및 쿼리의 전체 크기 측면에서 제한이 있지만 결국 트래픽이 몰리는 시간대에 메모리 부족 오류 등이 발생할 수 있기 때문입니다.
AWS Athena 개요
- 서버리스 쿼리: Amazon S3에 저장된 데이터를 분석하기 위한 서버리스 쿼리 서비스입니다. 사용자는 서버를 프로비저닝하거나 관리할 필요 없이 데이터에 직접 쿼리를 실행할 수 있습니다.
- SQL 언어 사용: 표준 SQL 언어를 사용하며 Presto라는 인메모리 분산 SQL 쿼리 엔진을 기반으로 실행되어 빠르게 데이터를 분석할 수 있습니다.
- 지원되는 파일 포맷: CSV, JSON, ORC, Avro, Parquet 등 여러 파일 포맷을 지원하며, 다양한 데이터 소스의 분석이 가능합니다.
- 간단한 가격 책정: 쿼리에 의해 스캔된 데이터 양(TB 당)에 따라 과금되며, 별도의 인프라 프로비저닝 비용은 없습니다.
성능 최적화
Athena의 쿼리 성능을 높이기 위해선 몇가지 데이터 변환 작업이 필요합니다.
- 파일 포맷의 영향: Apache Parquet 및 ORC 파일 포맷을 사용하면 쿼리 성능이 크게 향상될 수 있습니다.
- 데이터 전환: AWS Glue 등을 사용하여 CSV 파일을 Parquet 등의 더 효율적인 포맷으로 변환하는 것이 가능합니다.
- 데이터 압축과 분할: 데이터를 압축하여 저장하고, 큰 파일을 사용하여 오버헤드를 최소화할 수 있습니다. 또한, 데이터 분할(Partitioning)을 통해 쿼리가 스캔하는 데이터의 양을 제한함으로써 성능을 향상시킬 수 있습니다.
제한 및 고려사항
- 대용량 쿼리 및 배치 처리: Athena는 대용량 쿼리나 정기적인 배치 처리에는 최적화되어 있지 않을 수 있습니다. 이는 리소스가 리전별로 공유되기 때문에 발생합니다.
- 동시 쿼리와 리소스 제한: 기본적으로 Athena는 동시에 20개의 쿼리를 지원합니다. 또한, S3 요청 수, 쿼리 실행 시간 (최대 30분), 처리할 수 있는 행 및 열의 수, 테이블 및 쿼리 크기에 제한이 있습니다.
- 메모리 부족 오류 가능성: 트래픽이 집중되는 시간대에는 메모리 부족 오류 등이 발생할 수 있으므로, 이에 대한 계획이 필요합니다.
Redshift
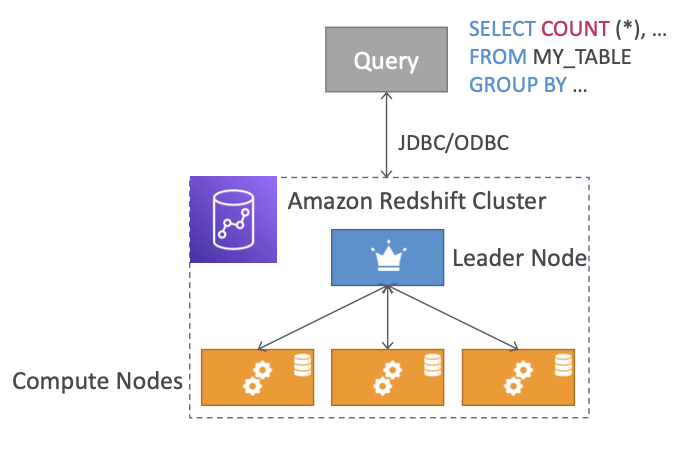
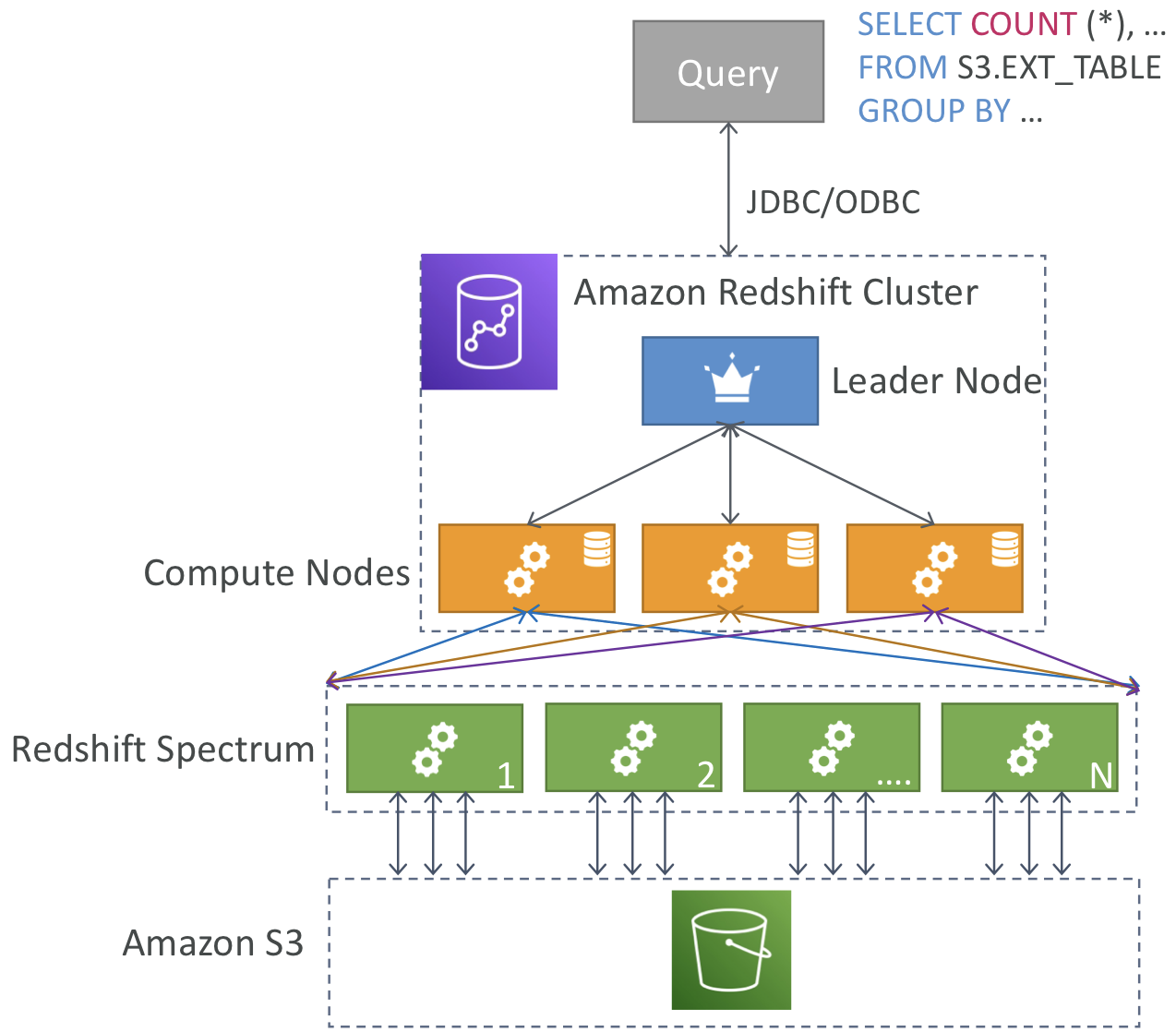
- 데이터 웨어하우징 서비스: 페타바이트 규모의 데이터 웨어하우징 서비스를 제공하며, 사용자는 대량의 데이터를 Redshift에 로드하고, 효율적으로 분석할 수 있습니다.
- OLAP(Online Analytical Processing) 지원: Redshift는 OLAP 작업에 최적화된 서비스로, 파일을 변환하고 분류하여 복잡한 분석과 데이터 웨어하우징 작업을 수행할 수 있습니다.
데이터를 웨어하우스로 가져오기 위한 ETL(추출, 변환, 로드) 솔루션과 데이터 처리를 위한 OLAP(온라인 분석 처리) 엔진이 포함
AWS Redshift는 페타바이트 규모 데이터 웨어하우징 서비스를 제공하며 데이터를 Redshift에 로드하여Redshift에서 빠르게 분석 가능
OLAP (Online Analytical Processing(분석과 데이터 웨어하우징))
하지만 모든 데이터를 넣어 활용하기엔 비용적으로 부담이 될 수 있습니다. 따라서 큰 데이터들은 s3에 넣는 경우가 많은데, s3와 연결하여 데이터를 가져올 경우엔 Redshift Spectrum이라는 전용 Amazon Redshift 서버를 통해 컴퓨팅 집약적 작업을 통해 진행 가능합니다.
장점:
- 빠른 성능: 대량의 데이터에 대한 빠른 쿼리 실행을 제공합니다.
- 확장성: 사용량에 따라 쉽게 확장 및 축소할 수 있습니다.
- 통합성: 다양한 데이터 소스 및 AWS 서비스와 쉽게 통합됩니다.
- 컬럼형 스토리지
단점:
- 비용: 대용량 데이터셋의 경우 비용이 높을 수 있습니다.
- 유지 관리: 서버리스 아키텍쳐가 아니므로 일부 관리 및 최적화가 필요할 수 있습니다.
- 복잡성: 복잡한 쿼리나 설정이 필요한 경우 사용이 어려울 수 있습니다.
분석 / 실시간
OpenSearch
역인덱스
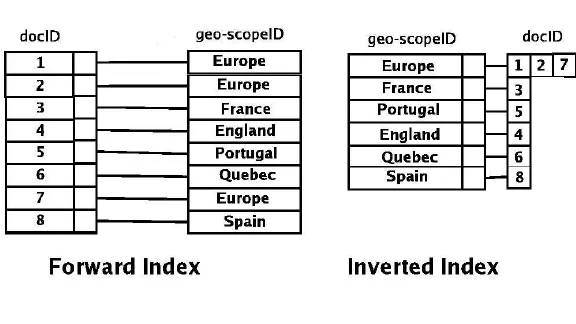

인덱스
B-트리 인덱스
- 일반적으로 사용됨: PostgreSQL, MySQL, Oracle 및 SQL Server와 같은 대부분의 관계형 데이터베이스 관리 시스템은 기본적으로 B-트리 인덱스를 사용합니다.
- 특성: B-트리는 효율적인 삽입, 삭제 및 검색 작업을 허용하는 방식으로 정렬된 데이터를 유지하는 정렬된 트리 데이터 구조입니다.
- 사용 사례: B-트리 인덱스는 동일 검색, 범위 쿼리, 정렬 작업을 포함한 광범위한 쿼리에 이상적입니다.
해시 인덱스
- 특정 용도: 해시 인덱스는 일부 데이터베이스(예: MEMORY 스토리지 엔진을 사용하는 MySQL의 특정 구성)에서 사용되며 주로 동등 검색을 위해 설계되었습니다.
- 특성: 해시 인덱스는 해시 함수를 사용하여 각 키에 대한 해시 코드를 계산하며, 이러한 코드는 항목을 빠르게 배치하고 찾는 데 사용됩니다.
- 사용 사례: 해시 인덱스는 범위 쿼리가 아닌 정확한 일치 항목을 찾는 포인트 쿼리에 매우 효율적입니다.
색인
일반적인 의미에서, 특히 데이터베이스에서 "인덱스"는 데이터 검색 작업 속도를 향상시키는 데이터 구조입니다. 일반적으로 관계형 데이터베이스의 컨텍스트에서 사용됩니다.
- 목적: 데이터베이스의 인덱스는 데이터베이스 테이블의 데이터를 빠르게 찾고 액세스하는 데 사용됩니다.
- 작동 방식: 인덱스는 데이터베이스 테이블의 하나 이상의 열에 생성됩니다. 이는 색인된 열을 기반으로 레코드의 정렬된 순서를 유지하므로 특정 정보를 빠르게 찾는 데 도움이 되는 책의 색인과 마찬가지로 더 빠른 검색 작업이 가능합니다.
- 사용 사례: 예를 들어 "Customers" 테이블의 "LastName" 열에 대한 인덱스가 있는 경우 데이터베이스는 "LastName"이 "Smith"인 모든 행을 빠르게 찾을 수 있습니다.
역방향 인덱스(역 인덱스)
"역 인덱스" 또는 "역 인덱스"는 주로 검색 엔진 및 텍스트 검색 시스템에 사용됩니다.
- 목적: 역방향 색인은 단어나 용어 등의 콘텐츠에서 해당 내용이 나타나는 문서나 문서 집합의 위치로 매핑을 저장하여 빠른 전체 텍스트 검색이 가능하도록 설계되었습니다.
- 작동 방식: 역색인에서는 각 단어나 용어가 색인화되어 해당 항목이 나타나는 문서 목록(또는 문서 내 위치)과 연결됩니다. 이는 문서에서 시작하여 그 안의 용어를 찾는 기존 색인과 반대입니다.
- 사용 사례: 예를 들어, 문서 컬렉션에서 "경제"라는 단어는 "경제"가 나타나는 문서 수(또는 문서 위치)와 함께 반전된 색인에 나열될 수 있습니다.
주요 차이점
- 방향성: 주요 차이점은 무엇이 무엇에 매핑되는지에 있습니다. 표준 색인은 데이터베이스 레코드(또는 행)에서 키 또는 용어로 매핑됩니다(예: 행에서 사람 이름으로 매핑). 반전된 인덱스는 키 또는 용어를 문서 집합의 해당 위치로 매핑합니다(예: "경제"라는 단어를 다양한 문서에서 해당 단어가 나타나는 모든 위치로 매핑).
- 사용 사례: 표준 색인은 데이터베이스에서 데이터 검색 속도를 높이는 데 사용되는 반면, 반전된 색인은 검색 엔진 및 텍스트 검색 시스템에서 효율적인 전체 텍스트 검색을 가능하게 하는 데 사용됩니다.
이미 정렬되어 있으면 빠른 시간내로 찾을 수 있다. → 자주 사용하는 값을 정렬시켜놓으면 빠르게 찾을 수 있다.
해당 칼럼에 존재하는 데이터를 완전히 다 사용할 때 의미가 있다.
인덱스는 기본적으로 이진 트리를 사용하기 때문에 이미 정렬이 되어있는 상태에서 추가, 수정, 삭제가 자주 일어나게 되면 인덱스에서도 이진트리를 계속 수정하기 때문에 성능 저하를 초래(WORM 적합)
인덱스 정리
하나의 컬럼이 키로써 정렬되어 검색에 활용됨, content 자체가 token 단위로 키가 되어 원본 key값을 검색함
OpenSearch의 장단점은 NoSQL의 일종으로 분산처리를 통해 실시간성으로 빠른 검색이 가능하다.
특히 기존의 데이터로 처리하기 힘든 대량의 비정형 데이터 검색이 가능하며 전문 검색(full text) 검색과 구조 검색 모두를 지원
검색엔진이지만 MongoDB나 Hbase와 같은 대용량 스토리지로도 활용이 가능
- 장점
- 오픈소스 기반
- 전문 검색(특정 단어 포함 검색)
- 실시간 로그 분석, 시각화가 가능하며 이상탐지와 알람 설정도 가능하다
- 정형화되지 않아도 자동으로 색인하고 검사 가능
- 여러 계층 구조의 문서로 저장이 가능하며, 계층 구조로된 문서도 한번의 쿼리로 쉽게 조회할 수 있다.
- 단점
- Elasticsearch에 비해 다른 plugin 설치가 까다롭거나 불가능하며, 제공되는 plugin만 활용해야한다
- 완전 실시간으로 동작하진 않는데 내부적으로 commit과 flush를 지원한다
- 트랜잭션 rollback을 지원하지 않는다
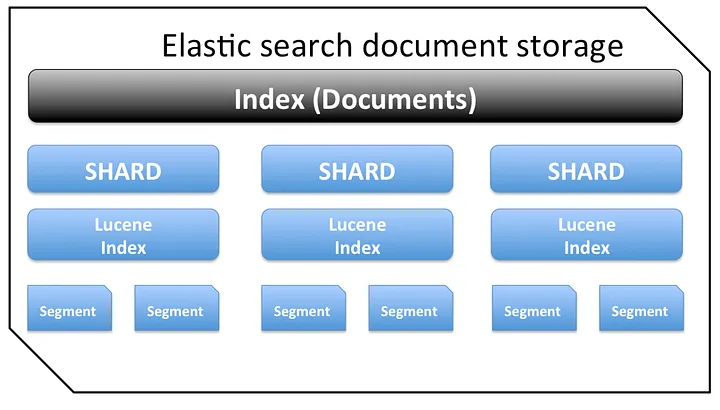
- 업데이트 명령이 올 경우 기존 문서를 삭제하고 새로운 문서를 생성한다. 이를 통해 불변성(Immutable)이라는 이점을 취한다.
- 세그먼트 단위로 불변이라고 이해하면 쉽다. 빠른 인덱싱을 위해 루씬의 세그먼트 아키텍쳐가 존재하는데, 여러 파일은 하나의 세그먼트로 이루어져있고, 이렇게 만들어진 각 세그먼트는 디스크의 단일 파일로 저장되어 있습니다. 해당 세그먼트를 수정하는데 들어가는 쓰기작업의 비용보다 삭제하고 새로 만들어 연결하는 비용이 더 효율적이기 때문에 불변성을 유지합니다.
- Lucene은 메모리 내 데이터 구조를 캐싱하기 위해 기본 OS를 활용하도록 설계되었습니다. Lucene 세그먼트는 개별 파일에 저장됩니다. 세그먼트는 변경할 수 없으므로 이러한 파일은 변경되지 않습니다. 이로 인해 캐시 친화적이게 되며 기본 OS는 더 빠른 액세스를 위해 핫 세그먼트를 메모리에 상주하게 유지합니다. 이러한 세그먼트에는 반전된 인덱스(전체 텍스트 검색용)와 문서 값(집계용)이 모두 포함됩니다.
- 6.1 역 인덱스 - Inverted Index
- 후기 서비스 AWS Opensearch 도입기
- Elasticsearch Segment
OpenSearch 도입기 확인
AWS Opensearch를 도입을 위해 후기 서비스는 CQRS 패턴을 선택하게 되었습니다. CQRS 패턴을 사용하면 Presentation 영역을 보여 주기 위하여 EventSourcing Pattern(이벤트는 한 번 발생한 이후 수정되지 않기 때문에 UPDATE나 DELETE 없이 항상 INSERT 작업만 일어납니다.)과
Materialized View Pattern(데이터 의 자체 로컬 복사본)이 언급됩니다. 후기 서비스는 이미 1억 건 가까운 데이터가 쌓인 상태여서 EventSourcing Pattern으로 변경하기는 많은 시간이 들기 때문에 Materialized View Pattern을 통한 역정규화 된 데이터를 Opensearch에 저장하기로 결정되었습니다.
OpenSearch의 장점
- 오픈소스 기반: AWS에서 유지하는 커뮤니티 기반 개발과 지원이 가능합니다.
- 확장성: 대규모 데이터셋에 대한 빠른 처리 및 분석이 가능합니다.
- 유연성: 다양한 데이터 포맷과 구조를 지원하여, 복잡한 데이터셋도 처리할 수 있습니다.
- 통합성: AWS 클라우드 환경의 다른 서비스와 쉽게 통합되어 활용할 수 있습니다.
OpenSearch의 단점
- 플러그인 제한: OpenSearch는 ElasticSearch 기반 일부 플러그인 설치가 제한적일 수 있습니다.
- 실시간성의 한계: 내부적으로 커밋(commit)과 플러시(flush) 메커니즘을 사용하기 때문에 완전한 실시간 처리는 제한적일 수 있습니다.
- 불변성(Immutable) 아키텍처: 데이터 업데이트 시 기존 문서는 삭제되고 새 문서가 생성됩니다. 이는 루씬(Lucene)의 세그먼트 아키텍처를 통해 효율적인 인덱싱을 위한 방식이지만 많은 양의 Insert/Update의 작업이 발생할 경우 아키텍쳐를 유지하기 위한 리소스가 많이 투입될 수 있습니다.
- 트랜잭션 및 롤백 부재: 트랜잭션 롤백을 지원하지 않습니다.
EMR(Elastic MapReduce)
Amazon EMR의 주요 특징
- Hadoop 기반: Hadoop 기반의 클러스터를 사용하여 대용량 데이터 처리 작업을 수행합니다.
- 다양한 프레임워크 지원: Apache Spark, HBase, Presto, Flink 등 여러 빅데이터 프레임워크와 애플리케이션을 지원합니다.
- 유연한 데이터 처리: 실시간(Spark Streaming)과 배치 처리 모두를 지원합니다.
- 자동 확장 및 스팟 인스턴스 지원: 워크로드에 따라 자동으로 클러스터를 확장할 수 있고, 비용 절감을 위해 스팟 인스턴스를 사용할 수 있습니다.
- 클러스터 구성: 클러스터는 마스터 노드, 코어 노드, 태스크 노드로 구성됩니다.
- 마스터 노드: 클러스터 관리 및 작업 조정을 담당합니다.
- 코어 노드: 데이터 처리 및 HDFS 스토리지를 제공합니다.
- 태스크 노드: 추가 처리 능력을 제공합니다.
Amazon EMR의 장단점
장점
- 확장성 및 유연성: 필요에 따라 인스턴스 수를 동적으로 조정하고, 클러스터를 사용자 정의할 수 있습니다.
- 비용 효율적: 사용한 리소스에 대해서만 비용을 지불하며, 스팟 인스턴스를 사용하여 비용을 절감할 수 있습니다.
- 사용 편의성 및 통합: 관리형 서비스로 인프라 관리 부담이 감소하며, AWS 생태계와 원활하게 통합됩니다.
- 다양한 데이터 처리 지원: 다양한 프레임워크 지원으로 광범위한 데이터 처리 요구 사항을 충족합니다.
- 보안 및 규정 준수: 데이터 보안과 규정 준수를 위한 기능을 제공합니다.
단점
- 비용 문제: 대규모 클러스터의 경우 비용이 높을 수 있습니다.
- 이해와 최적화 필요: Hadoop, Spark 등 프레임워크에 대한 이해가 필요하며, 최적화를 위한 추가 작업이 필요할 수 있습니다.
Amazon EMR은 빅데이터 분석 및 처리를 위한 강력하고 유연한 플랫폼입니다. 그러나 이를 효과적으로 활용하기 위해서는 관련 기술과 최적화 전략에 대한 이해가 필요합니다.
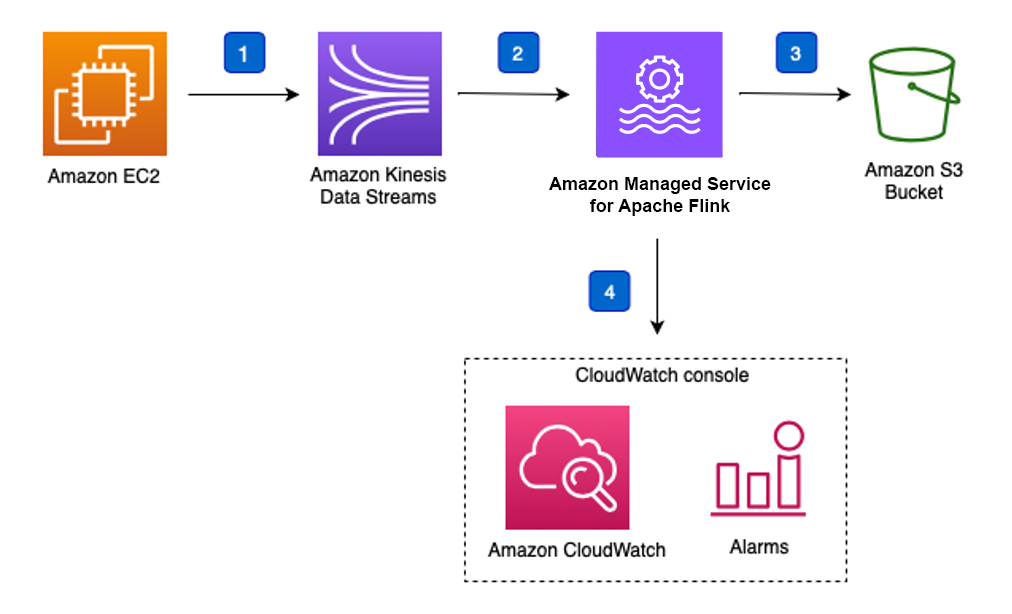
Amazon Managed Service for Apache Flink
- 기존 Kinesis Data Analytics
- 스트림 프로세싱으로 사용되며 데이터 처리만 가능
- CloudWatch 애플리케이션 모니터링과 결합하여 특정 패턴이나 이상 행동 탐지가 가능
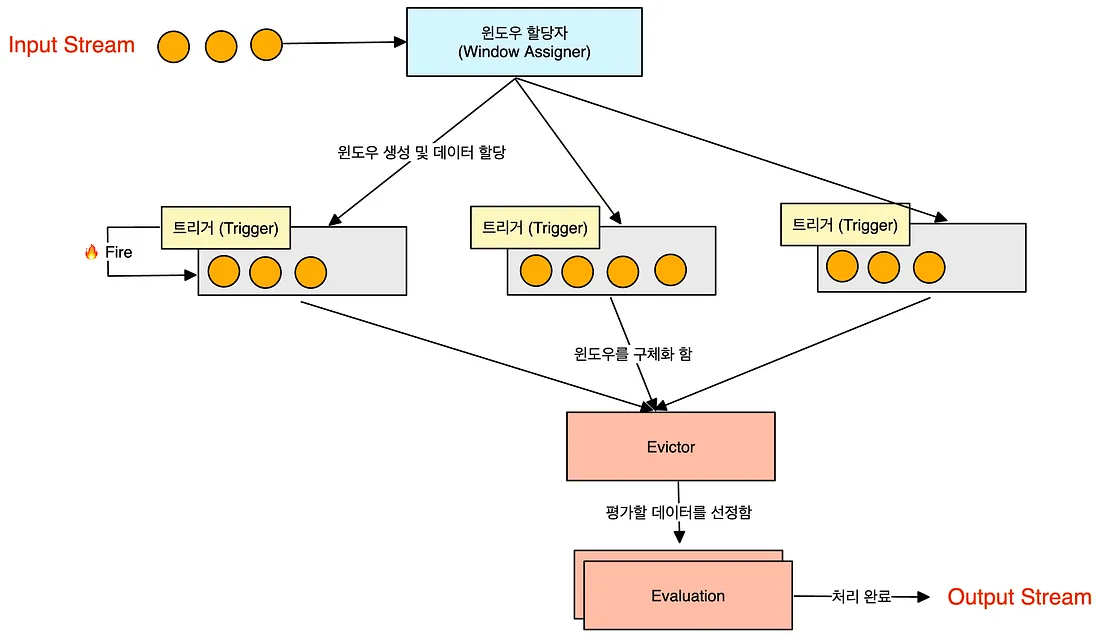
- 할당자가 key 혹은 로직에 따라 데이터를 각 윈도우에 할당함
- 하나의 윈도우는 윈도우 함수와 트리거를 가짐(특정 조건을 걸어 윈도우 트리거를 일으킬 수 있음)
파일, 디렉터리, 소켓 또는 인터넷을 통해 액세스 가능한 기타 소스를 읽고 쓸 수 있는 Apache Flink의 기본 형식 세트를 사용하여 사용자 지정 통합을 구축할 수도 있습니다.
- 다양한 커넥터 지원: 40개 이상의 커넥터가 포함되어 있어, 다양한 데이터 소스와의 통합이 가능합니다. 서비스간 통합을 쉽게 구축할 수 있습니다.
- 사용자 지정 통합: 파일, 디렉터리, 소켓 또는 인터넷을 통해 액세스 가능한 기타 소스를 읽고 쓸 수 있는 Apache Flink의 기본 형식 세트를 사용하여 사용자 지정 통합을 구축할 수도 있습니다.
- 기계 학습 통합: 분류, 클러스터링, 회귀 등 다양한 기계 학습 알고리즘을 지원하여 실시간 분석 및 처리가 가능한 애플리케이션을 만들 수 있습니다.
- AWS Glue 스키마 레지스트리와의 호환성: AWS Glue 스키마 레지스트리와의 호환으로 데이터 품질을 유지하고 예기치 않은 스키마 변경으로부터 보호할 수 있습니다.
- 스트림 처리: 실시간 스트림 데이터 처리에 최적화된 프레임워크입니다. 이는 데이터가 생성됨과 동시에 지속적으로 처리되는 환경에 적합합니다.
- 윈도우 처리: 스트림 데이터를 처리할 때 '윈도우'라는 개념을 사용합니다. 데이터는 할당자에 의해 특정 윈도우에 할당되며, 각 윈도우는 자체 함수와 트리거를 가집니다.
- CloudWatch 통합: Amazon CloudWatch와 통합되어 애플리케이션 모니터링 및 이상 행동 탐지가 가능합니다.
- 유연한 데이터 처리: Flink는 키나 로직에 따라 스트림 데이터를 다양한 방식으로 처리할 수 있습니다.
- 한 번에 정확하게 처리 (Exactly Once Processing): 처리된 레코드가 결과에 정확히 한 번만 영향을 미치도록 보장합니다. 이는 중복 데이터 없이 데이터를 처리할 수 있게 합니다.
- 상태 저장 처리: 진행 중인 계산 및 상태를 애플리케이션 스토리지에 저장합니다. 이는 애플리케이션 중단 시에도 빠른 복구와 데이터 일관성을 유지하는 데 도움이 됩니다.
- 내구성 있는 애플리케이션 백업: API를 통해 애플리케이션의 백업을 생성하고 관리할 수 있으며, 필요 시 이전 상태로 복원할 수 있습니다.
Amazon Managed Apache Flink의 장단점
장점
- 실시간 처리: 실시간 데이터 스트림 처리에 최적화되어 있어, 지연 시간이 매우 짧고 레코드를 정확히 한 번만 처리하는 것을 보장합니다. 이를 통해 중복되는 데이터 없이 데이터를 관리할 수 있게 합니다.
- 상태 저장 처리: 진행 중인 연산 및 상태를 애플리케이션 스토리지에 저장합니다. 이를 통해 애플리케이션 중단 시에도 빠른 복구와 데이터 일관성을 유지하는 데 도움이 됩니다.
- 높은 확장성: AWS 인프라상에서 운영되므로, 필요에 따라 자원을 쉽게 확장하거나 축소할 수 있고 API를 통해 애플리케이션의 백업을 생성하고 관리할 수 있습니다. 필요 시 이전 상태로 쉽게 복원할 수 있습니다.
- 강력한 데이터 처리 기능: 복잡한 스트림 처리 로직을 구현할 수 있으며, 윈도우 기반의 처리 방식은 다양한 시나리오에 유연하게 적용될 수 있습니다. 스트림 데이터를 처리할 때 '윈도우'라는 개념을 사용하는데, 데이터는 윈도우 할당자에 의해 특정 윈도우에 할당되며, 각 윈도우는 자체 함수와 트리거를 가집니다.
- 통합 및 모니터링: AWS의 다른 서비스와의 통합이 용이하며, 효과적인 모니터링과 로깅을 지원합니다.
단점
- 복잡성: Flink는 상대적으로 복잡한 스트림 처리 로직을 구현할 수 있지만, 이로 인해 학습 곡선이 높을 수 있습니다.
- 비용: 고성능의 실시간 처리가 필요한 경우 비용이 증가할 수 있습니다.
유지 관리 필요성: 관리형 서비스이기는 하지만, 성능 최적화와 애플리케이션 관리에 대한 일정 수준의 이해가 필요합니다.
데이터 시각화 & 활용
Amazon Personalize, Sagemaker, QuickSight
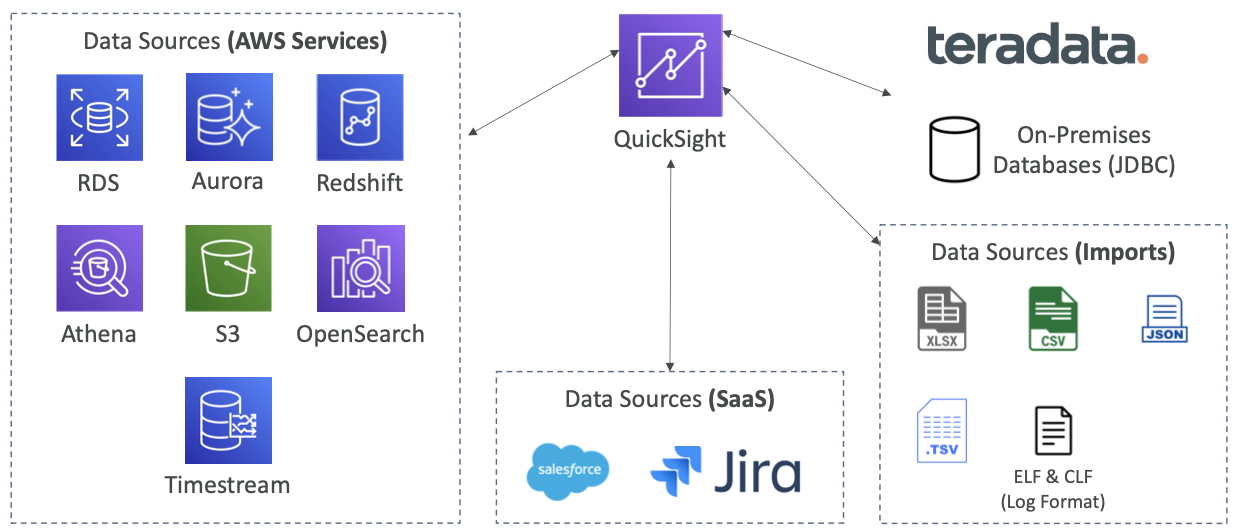
서버리스 머신 러닝 기반 BI 서비스로 대화형 대시보드 형식으로 구성되어 있습니다.
- 빠르고 자동화, 오토스케일링, 임베디드가 가능하며 세션당 비용을 지불
- 비즈니스 분석, 시각화된 정보를 통한 임시 분석 수행, 비즈니스 인사이트
- 다양한 데이터 소스에 연결 가능
- SPICE 엔진을 통해 데이터를 직접 가져올 때 인메모리 계산이 가능
- 사용자 수준의 기능을 제공(CLS - Column-Level security) 보안을 제공
Tableau, Power BI
다른 BI 도구들에 비해 저렴하지만 매우 기초적인 시각화 기능이나 제한된 기능을 가지고 있다.
AWS 서비스 혹은 AI/ML 자체와 통합시킬 수 있다는 장점이 있다.
Quick Sight test query
SELECT artist_name,
count(artist_name) AS count
FROM processed_data
GROUP BY artist_name
ORDER BY count desc
SELECT device_id,
track_name,
count(track_name) AS count
FROM processed_data
GROUP BY device_id, track_name
ORDER BY count desc
![[AWS] DynamoDB 스키마 설계 가이드](https://images.unsplash.com/photo-1554098415-788601c80aef?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDV8fFNRTHxlbnwwfHx8fDE3NjcyMzc1NDJ8MA&ixlib=rb-4.1.0&q=80&w=960)
![[MLOps] Apache Airflow 기능 및 용어 정리](https://images.unsplash.com/photo-1754928661805-ae4279a97218?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDR8fGFpcmZsb3d8ZW58MHx8fHwxNzU2MTI1OTkwfDA&ixlib=rb-4.1.0&q=80&w=960)
![[MLOps] Data Pipeline Orchestration - Airflow, Perfect](https://images.unsplash.com/photo-1600443446566-c8a2e34c779b?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDN8fE9yY2hlc3RyYXRpb258ZW58MHx8fHwxNzU2MTI2MDA5fDA&ixlib=rb-4.1.0&q=80&w=960)
![[AWS] Personalize에서 생성형 AI를 활용한 Content Generator](https://images.unsplash.com/photo-1662368864997-dd71a2f78433?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDR8fFBlcnNvbmFsaXplfGVufDB8fHx8MTc1Mzc0NzM1MHww&ixlib=rb-4.1.0&q=80&w=960)