[AI] General Deep Learning and Machine Learning Modeling
기본적인 ML/DL 내용을 정리하였습니다.
![[AI] General Deep Learning and Machine Learning Modeling](https://images.unsplash.com/photo-1511629091441-ee46146481b6?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDV8fERlZXBMZWFybmluZ3xlbnwwfHx8fDE3NTM3NDU0OTd8MA&ixlib=rb-4.1.0&q=80&w=1200)
DeepLearning
딥러닝은 실제 우리의 뇌의 작동 원리를 기반으로 두고 있습니다.GPU는 컴퓨터 화면의 모든 픽셀을 한 번에 생성하기 위해 엄청난 규모의 병렬처리를 가능하게 합니다.동시에 뉴럴 네트워크는 병렬화에 용이하고 GPU를 사용할 수 있으며, 개별 뉴런은 GPU를 모델로 아주 간단히 처리합니다.하지만 프로그래밍 단위에서 GPU를 사용하여 병렬처리를 하기 위해선 일종의 프레임워크가 필요합니다.
Tensorflow를 많이 사용하곤 하는데 Keras라는 구글에서 만든 프레임워크도 사용하곤 합니다.이 외로 아마존에서는 아파치기반 MXNET을 사용합니다.
Types of Neural Networks
Feed-Forward Neural Network
정보는 입력 노드에서 숨겨진 레이어(있는 경우)를 거쳐 출력 노드로 한 방향으로 이동합니다. 네트워크에는 사이클이나 루프가 없습니다.수많은 뉴런 층이 겹겹이 쌓여있고 맨 위에서 기능을 입력하면 맨 아래에서는 분류 예측이 나오는 가장 직설적인 종류입니다.
- 사용 사례: 기본 분류 작업, 회귀 작업.
Convolution Neural Networks(CNN)
이미지와 같은 그리드형 토폴로지로 데이터를 처리하도록 설계되었습니다. 사용 사례: 이미지 인식, 비디오 분석, 이미지 분류
Recurrent Neural Networks(RNN)
스스로 피드백되어 네트워크에 루프를 생성하는 연결이 있습니다. 아키텍처를 통해 이전 입력의 '메모리'를 유지할 수 있어 순차 데이터에 이상적입니다. 예측이나 질서가 있는 일을 처리할 수도 있고, 문장의 단어 순서를 이해하고 관계를 파악하여 문장을 완성하거나 다른 언어로 번역할 수 있게 됩니다.장단기 메모리(Long Short-Term Memory, LSTM)과 기존 RNN과 관련된 그래디언트 소멸 문제를 해결하여 모델이 긴 입력 시퀀스의 종속성을 훨씬 더 효과적으로 캡처할 수 있도록 설계된 Gated Recurrent Unit(Gated Recurrent Unit)를 사용합니다.
- 사용 사례: 자연어 처리(NLP), 음성 인식, 시계열 분석.
Activation Functions(활성함수)
활성화 함수는 뉴런이나 노드 내부에 있는 기능으로 단순히 뉴런에 입력된 모든 정보를 요약해서 다음 뉴런 층으로 어떤 정보를 보낼지 결정하는 역할을 합니다. 즉 이러한 활성화 함수들은 모델의 출력, 정확도 및 계산 효율성을 결정합니다.
활성화 함수의 유형
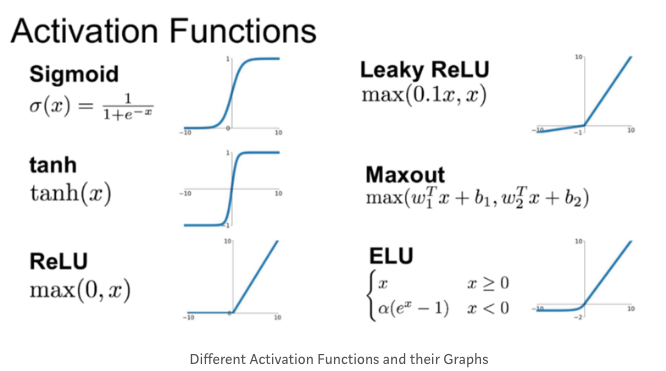
Linear activation functions(선형 활성화 함수)
아무 기능도 하지않습니다. 출력으로 들어온 걸 단순히 반영하는 역할을 하게되어 학습을 할 수 없고 역전파(backpropagation)가 불가능합니다.
역전파(backpropagation)란
역전파는 신경망의 예측 오류를 기반으로 가중치를 업데이트하는 데 계산적으로 효율적인 수단을 제공하기 때문에 깊은 신경망 훈련에 있어 필수적입니다. 역전파 없이는 많은 계층과 매개변수를 가진 심층 네트워크를 훈련하는 것이 어려울 것이며, 대안적인 방법의 계산 비용은 너무 높을 것입니다.
정방향 전달을 반복적으로 적용하여 예측을 수행하고, 손실을 계산한 다음, 역전파를 사용하여 가중치를 업데이트함으로써 신경망은 데이터에서 학습하고 예측을 개선할 수 있습니다. 이 과정은 신경망이 만족스러운 성능을 달성할 때까지 여러 에포크(또는 훈련 데이터를 통한 패스)에 걸쳐 반복됩니다.굳이 여러 레이어를 가질 필요없습니다.
Binary step function
이진법 함수로 안들어오면 아무 것도 안내보내고 들어오면 양적 값을 출력합니다.
다중 분류를 감당할 수 없어 단순히 켜거나 끌 수 밖에 없다는 단점이 있습니다.
Non-linear activation function(비선형 활성화 함수)
입력과 출력 사이에 복잡한 매핑을 만들 수 있습니다. 이를 통해 층마다 전달할 정보가 많아지며 비선형성이 함수들은 직선이 아니며, 데이터에 있는 비선형 관계를 모델링할 수 있습니다. 대부분의 비선형 활성화 함수는 미분 가능하며, 이는 역전파와 같은 기울기 기반 최적화 방법을 가능하게 하는 핵심입니다.
역전파를 통해 연쇄 미분 규칙을 사용하여 기울기를 효율적으로 계산합니다. 이를 통해 네트워크의 가중치와 편향을 조정하여 실제 출력과 예측 출력 간의 차이를 최소화할 수 있습니다.더 많은 레이어는 네트워크에 더 많은 매개변수(가중치와 편향)를 제공하여, 데이터로부터 학습할 수 있는 용량을 증가시킵니다. 더 높은 용량을 가진 네트워크는 더 복잡한 함수를 모델링하고 데이터셋의 미묘한 패턴을 포착할 수 있습니다.깊은 네트워크는 단순 네트워크에 비해 복잡한 함수를 더 적은 단위로 효율적으로 표현할 수 있습니다. 주어진 성능 수준에서, 깊은 네트워크는 단순 네트워크에 비해 지수적으로 적은 뉴런을 필요로 할 수 있습니다.
- Sigmoid or Logistic Function: 0과 1 사이의 값을 출력하므로 이진 분류 작업에 대한 확률을 예측해야 하는 모델에 유용합니다. 그러나 Vanishing Gradient(좌측이나 우측으로 계속 뻗어나갈 때 변화를 확인할 수 없는) 문제가 발생합니다.
- Hyperbolic Tangent: 시그모이드와 비슷하지만 -1과 1 사이의 값을 출력합니다. 0 중심이므로 일반적으로 시그모이드 함수에 비해 숨겨진 레이어에 더 좋습니다.
Rectified Linear Unit (ReLU) Function
대규모 데이터셋이나 복잡한 모델에서 삼각법에 비해 훨씬 단순하게 계산하여 빠르게 결과를 도출할 수 있습니다.기울기가 0에 가까워지면 가중치가 매우 느리게 업데이트되어 학습과정이 늦어지고 신경망이 수렵하기 어려운데 ReLu는 그것을 방지할 수 있습니다.빠르고 효율적임에도 0 혹은 마이너스 값을 선택할 떄 다시 선형함수로 반복된다는 단점이 있습니다.
Leaky ReLu
약간의 기울기를 만들어 선형 함수 문제를 해결
Softmax
다중 분류 문제의 마지막 출력 계층으로 one-hot encoding된 분류라면 마지막 출력 층에 Softmax가 활성화 함수로 적용됩니다.마지막 층에서 나온 결과물을 취합해 각 분류의 확률로 변환합니다. 하지만 레이블을 하나 이상 생산할 수 없으며 어떤 사진에 대해 여러 개의 레이블을 지정할 수 없습니다.
활성함수 선택하기
Softmax: 하나의 물체에 대한 분류를 고르려 할 경우 사용
- Hyperbolic Tangent, : RNN같은 반복 신경망
- ReLu → 더 나은 것을 원한다면
- Leaky ReLu → 부족하면 PReLu or Maxout을 사용합니다
- Swish: 40개 이상의 심층 신경망을 가진 경우
CNN(Convolutional neural network)
데이터에서 어떤 패턴이나 기능을 찾는데 데이터의 정확한 위치를 모른다고 할 때 CNN이 데이터를 스캔해 패턴을 찾아주게 됩니다.단순히 이미지에 국한되지않고 데이터 내에서 Feature가 어디에 위치할지 모르는 어떤 종류의 문제에도 사용될 수 있습니다.ex) 이미지에서 특정 물건이나 사인을 찾기 / 기계 번역과 자연어 처리(명사, 동사 등 문장을 분석하거나 감성 분석에 사용할 수 있습니다.)
동작방식
뇌가 망막에서 이미지를 처리하는 방식에서 힌트를 얻습니다.눈이 작동하는 방식은 각각의 뉴런 그룹이 시각의 특정영역을 담당하여 뉴런들이 눈에 보이는 것에 반응하는 것 입니다.망막에서 들어오는 이미지를 차단하고 눈으로 보는 시야의 특정 부분을 처리하는 특수한 뉴런 집단이 있습니다.
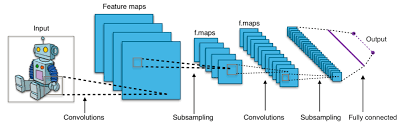
콘볼루션이라고 하는 작은 영역이 데이터를 필터하고, 이 필터를 통해 이미지 전체를 훑으며 살펴보도록 움직여 전체 이미지에 대한 이해를 형성하는 구조를 가지고 있습니다. 이미지를 개별 프로세싱을 위해 서로 겹쳐진 작은 필드로 쪼개는 방식입니다.필터를 주입하고 선을 합쳐서 형태를 만들 수 있습니다. 계속해서 작은 덩어리로 쪼개서 조합하고 패턴을 찾아 신경망에서 더 복잡하고 높은 수준으로 분석합니다.특정 부분을 처리하는 수용 필드가 이미지를 스캔하고 겹쳐서 엣지를 찾아냅니다.가장 낮은 레이어에서는 정지 표지판의 가장자리와 선만 알아본 뒤, 더 높은 레이어에서 정지판의 모양을 파악하여 동작합니다. 이때 색상이 있는 데이터는 RGB값을 필요로 하기 때문에 모든 걸 3배로 곱해서 계산할 필요가 있습니다.역전파 알고리즘을 통해 학습을 수행합니다.
CNN with Keras / Tensorflow
소스 데이터가 적당한 크기와 형태인지 확인해야합니다.(가로 * 세로 * 컬러채널)흑백이미지라면 사진의 모든 지점에서 흑백 사이의 회색 스케일 값을 측정하여 단일 값으로 사용할 수 있습니다.하지만 컬러 이미지라면 세 개의 컬러 채널이 있어 더 복잡한 연산이 필요합니다.
Kears에서는 콘볼루션 신경망을 다룰 때 사용할 수 있는 특수한 층이 있으며 Conv2D 레이어 유형은 2D 이미지에서 실제 콘볼루션을 합니다. Conv1D와 Conv3D도 이용 가능하며 일차원의 데이터(텍스트)같은 경우에 사용되거나 3D 부피 측정 데이터를 다루는 레이어에서도 사용 가능하며 가능성이 넓습니다.Keras에서 또 다른 층은 MaxPooling2D이며 1D와 3D로 변형되었으며 데이터의 크기를 줄이는 것이 목적입니다.이미지를 축소시켜 처리 부하를 줄이는 한 가지 방법입니다.
Conv2D → MaxPooling2D → Dropout → Flatten → Dense → Dropout → Softmax중요한건 데이터를 처리하고 잘라내서 관리 할 수 있는 수준으로 줄이는 과정입니다.
- Conv2D (합성곱 계층)
- 역할: 이미지에서 공간적 특징(예: 가장자리, 모양, 질감)을 추출합니다.
- 작동 방식: 입력 이미지 위를 작은 필터(또는 커널)가 이동하며, 필터와 이미지의 각 지역 간의 점곱을 계산하여 특징 맵을 생성합니다. 이 계층은 이미지의 공간적 계층 구조를 유지하면서 특정 특징을 활성화시킵니다.
- MaxPooling2D (최대 풀링 계층)
- 역할: 특징 맵의 크기를 줄이고, 중요한 특징을 강조하여 모델의 과적합을 줄이는 동시에 계산량을 감소시킵니다.
- 작동 방식: 특징 맵을 작은 영역으로 나누고, 각 영역에서 최대값을 선택하여 새로운, 축소된 특징 맵을 생성합니다. 이 과정은 데이터의 중요한 특징은 유지하면서 크기를 줄입니다.
- Dropout
- 역할: 모델의 과적합을 방지합니다.
- 작동 방식: 학습 과정에서 무작위로 선택된 뉴런을 일시적으로 비활성화(0으로 설정)하여, 모델이 특정 뉴런에 지나치게 의존하는 것을 방지합니다. 이는 모델의 일반화 능력을 향상시킵니다.
- Flatten
- 역할: 다차원의 특징 맵을 1차원 벡터로 변환합니다.
- 작동 방식: 이 단계는 합성곱 및 풀링 계층을 거친 후의 다차원 출력을 완전 연결 계층(Dense)으로 전달하기 위해 필요합니다. 이를 통해 모델이 공간적 특징을 기반으로 결정을 내릴 수 있게 합니다.
- Dense (완전 연결 계층)
- 역할: 하나 또는 여러 개의 완전 연결 계층이 특징들을 결합하여 분류 또는 회귀와 같은 최종 결정을 내립니다.
- 작동 방식: 모든 입력 뉴런이 다음 계층의 모든 뉴런과 연결되어 있으며, 이 계층은 문제에 맞게 특징들을 학습하여 최종 출력에 도달합니다.
- Dropout
- 역할 및 작동 방식: 이 단계에서도 동일하게 모델의 과적합을 방지하기 위해 사용됩니다. 완전 연결 계층 후에 적용되어, 과적합의 위험을 줄입니다.
- Softmax
- 역할: 분류 문제에서 최종 출력 계층으로 사용되며, 각 클래스에 대한 확률 분포를 출력합니다.
- 작동 방식: 출력값을 확률로 변환하여, 각 클래스가 입력 이미지에 속할 확률을 나타냅니다. 이는 다중 클래스 분류 문제에서 각 클래스에 대한 예측의 확률을 제공합니다.
이러한 단계를 거쳐, CNN은 이미지에서 중요한 특징을 추출하고, 이를 기반으로 이미지를 분류하거나 다른 작업을 수행할 수 있습니다. 이 구조는 매우 유연하며, 다양한 종류의 이미지 처리 작업에 적용될 수 있습니다.
하이퍼파라미터란
하이퍼파라미터는 머신러닝과 딥러닝 모델의 구성 및 학습 과정을 제어하는 데 사용되는 외부 설정 값입니다. 이들은 모델의 성능에 큰 영향을 미칠 수 있으며, 학습 과정에서 자동으로 결정되지 않고, 사용자에 의해 사전에 설정되어야 합니다. 하이퍼파라미터 튜닝은 모델의 성능을 최적화하는 중요한 과정 중 하나입니다.여기 몇 가지 주요 하이퍼파라미터의 예와 그들이 머신러닝/딥러닝 모델에서 수행하는 역할을 설명합니다:
- 학습률(Learning Rate)
- 모델 가중치의 업데이트 속도를 결정합니다. 너무 높으면 학습 과정에서 발산할 수 있고, 너무 낮으면 학습이 너무 느리거나 지역 최소값에 갇힐 수 있습니다.
- 배치 크기(Batch Size)
- 한 번의 학습 단계에서 모델에 제공되는 데이터 샘플의 수입니다. 크기가 크면 학습이 안정적이지만 메모리 요구사항이 증가하고, 작으면 업데이트가 더 자주 발생하여 학습이 불안정해질 수 있습니다.
- 에포크 수(Epochs)
- 전체 학습 데이터 세트를 모델이 학습하는 횟수입니다. 너무 많은 에포크는 과적합을 유발할 수 있고, 너무 적은 에포크는 충분한 학습이 이루어지지 않을 수 있습니다.
- 네트워크 구조(Network Architecture)
- 레이어의 수, 유닛(뉴런)의 수 등 모델의 구조를 결정합니다. 모델의 복잡성과 처리할 수 있는 특징의 양에 영향을 미칩니다.
- 드롭아웃 비율(Dropout Rate)
- 과적합을 방지하기 위해 학습 중에 무작위로 선택된 뉴런을 비활성화하는 비율입니다. 0에 가까우면 드롭아웃 없음을 의미하고, 1에 가까우면 모든 뉴런을 드롭아웃함을 의미합니다.
- 정규화 파라미터(Regularization Parameters)
- 모델의 가중치에 대한 정규화 항을 추가하여 과적합을 방지합니다. 예를 들어, L1 또는 L2 정규화는 가중치의 절대값 또는 제곱값에 비례하는 항을 손실 함수에 추가합니다.
하이퍼파라미터를 적절히 설정하는 것은 모델의 성능을 극대화하기 위해 중요하며, 이 과정은 종종 시행착오를 통해 이루어집니다. 그리드 탐색(Grid Search), 랜덤 탐색(Random Search), 베이지안 최적화(Bayesian Optimization)와 같은 자동화된 튜닝 기법을 사용하여 최적의 하이퍼파라미터를 찾을 수 있습니다.
- 전산 작업에 집중되어 있습니다
- CPU, GPU, 메모리 요구 사항이 매우 높습니다.
콘볼루션 신경망
CNN이 특정 유형의 문제에 대해 최적의 토폴로그와 매개변수를 찾기 위해 많은 연구가 진행되고 있습니다.하나의 숨겨진 신경망인척 그 안엔 여러 개의 신경망을 만들 수 있습니다.
- LeNet-5 → 필적 인식
- AlexNet → 이미지 분류에 적합 레넷보다 깊은 신경망
- GoogLeNet → 콘볼루션이 인셉션과 합쳐질 수 있어 최적화 되었습니다.
- ResNet → 스킵 연결을 통해 성능을 유지하고 퍼셉트론 계층간 특별한 요청을 통해 가속도가 높아집니다.
퍼셉트론은 입력(features)에 대해 가중치(weight)를 곱하고, 그 결과들을 합한 다음, 활성화 함수(activation function)을 통과시켜 출력(output)을 생성합니다.
퍼셉트론 계층
- 입력 벡터(Input Vector): 이는 모델에 입력되는 실제 데이터 포인트입니다. 각 입력은 특정한 특징(feature)을 나타냅니다.
- 가중치(Weights)와 편향(Bias): 각 입력에는 해당 입력의 중요도를 나타내는 가중치가 할당됩니다. 편향은 입력이 없을 때(즉, 모든 입력이 0일 때)의 출력을 조절하는 역할을 합니다. 가중치와 편향은 학습 과정에서 조절됩니다.
- 가중 합(Weighted Sum): 입력 벡터의 각 성분과 해당 가중치의 곱의 총합에 편향을 더한 값입니다. 이는 모델의 예측을 결정하기 전의 중간 단계를 나타냅니다.
- 활성화 함수(Activation Function): 가중 합의 결과를 입력으로 받아, 특정 임계값을 기준으로 출력을 결정합니다. 가장 간단한 활성화 함수는 단계 함수(step function)인데, 이는 입력이 임계값보다 클 때 1을, 그렇지 않을 때는 0을 출력합니다. 이를 통해 퍼셉트론은 입력 데이터를 두 클래스 중 하나로 분류할 수 있습니다.
퍼셉트론 학습 규칙은 매우 간단합니다. 모델의 예측이 실제 값과 다를 경우, 가중치는 입력과 오차에 비례하여 조정됩니다. 이 과정을 반복하면서 모델은 점차적으로 최적의 가중치를 찾아가게 됩니다.
RNN
데이터 시퀀스를 위한 것으로, 시간 순서로 정렬된 타임 시리즈 데이터를 처리하는데 사용할 수 있습니다.대표적인 타임 시리즈 데이터로는 웹 로그, 센서 로그, 주식 거래 등이 있습니다.시퀀스가 꼭 시간에만 일치시키는 것은 아니며 연속적인 동작이나 순서를 설정할 수 있습니다.
- 언어
언어 속 문장은 단순히 단어의 연속과 집합으로 기계 번역이나 문장 조합에 RNN을 적용하거나 이미지를 위한 캡션을 만들 수 있습니다.한 문장에서 단어의 순서가 중요하다는 것을 보여주는 예시입니다. → 단어의 조합이 문맥없이 보는 것 보다 많은 의미를 내포하기 때문입니다.
- 음악
음악도 텍스트와 비슷해서 단어나 글자의 연속성 대신 음표의 연속성을 볼 수 있습니다.기존의 음악을 재순환 신경망을 통해 확장할 수 있습니다. 과거의 음악 중 좋았던 부분만 패턴으로 학습할 수 있고 전체적인 음악의 구성을 학습할 수도 있습니다.
Recurrent neuron
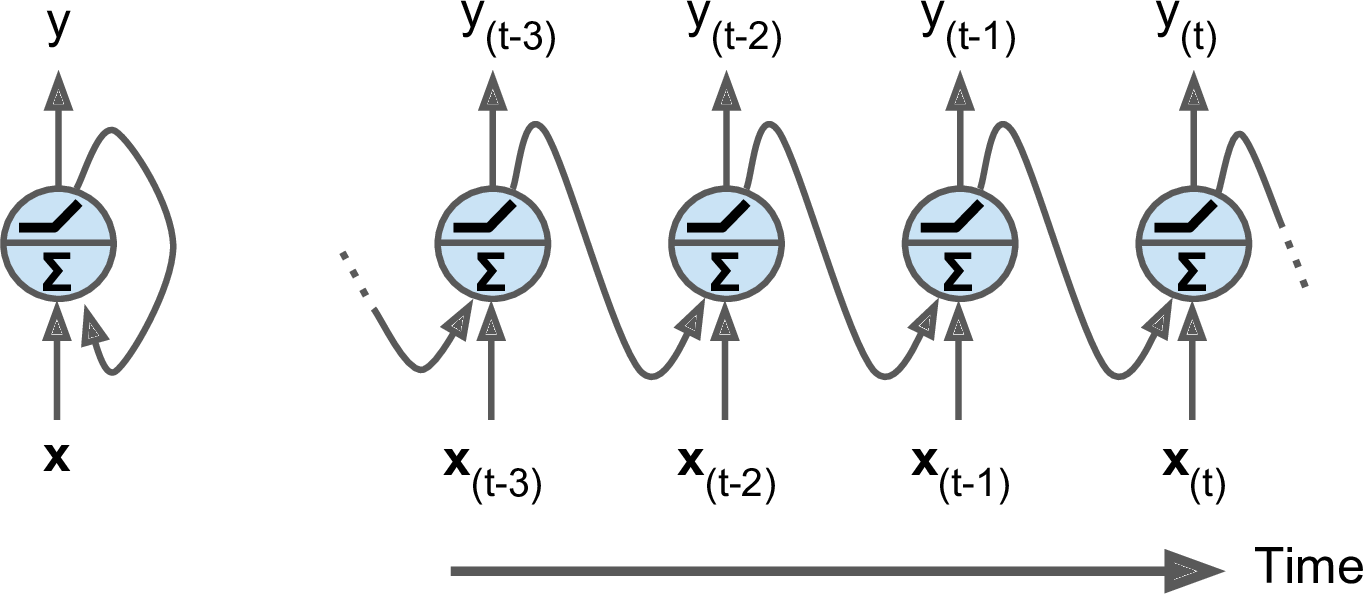
인공 뉴런과 같지만 큰 차이점은 작은 루프가 둘러 싸고 있는 좌측의 형태와 유사합니다.훈련 단계를 거치면서 훈련 데이터가 신경망의 이전 계층에서 입력된 정보일 수도 있습니다.모든 입력값을 합산한 후 활성화 함수를 적용할 수 있습니다. 일반적으로 탄젠트 함수를 적용하여 시간이 흐르면서 일부 정보를 부드럽게 유지하는게 좋기 때문입니다.이렇게 활성화 함수를 적용시켜 나온 출력값을 같은 뉴런에 다시 입력합니다.
이걸 계속 실행하게 되면 새로운 데이터가 들어와도 이전 뉴런에서 출력된 결과들과 잘 섞여 반복되게 됩니다.이를 통해 뉴런에서 과거 행동이 미래의 행동과 학습 방식에 영향을 줄 수 있습니다.우측의 형태를 확인해보면 병렬적으로 뉴런이 계속해서 실행되고 실행되면서 이전 단계의 결과물과 새로 들어오는 출력물들을 합산하게 됩니다.
이러한 각각의 단계에서 이전 결과물을 기억하고 다음 결과물을 받아들이는 뉴런을 메모리 셀이라고 합니다.메모리 셀은 시퀀스 데이터를 처리할 때 이전 정보를 기억하고 이를 다음 단계의 결정에 활용하기 위해 설계된 네트워크의 핵심 구성 요소로 사용되며 각 시간 단계에서 입력과 이전 단계의 출력(상태)을 받아 현재 단계의 출력과 새로운 상태를 생성하는 역할을 하게 됩니다.
메모리 셀의 특징으로는 최근의 행동이 현재의 시간 단계에 더 영향을 미친다는 점입니다.가로로 스케일 아웃될 수 있으며 뉴런을 늘리면 늘릴 수록 복잡한 패턴을 학습할 수 있게 됩니다.
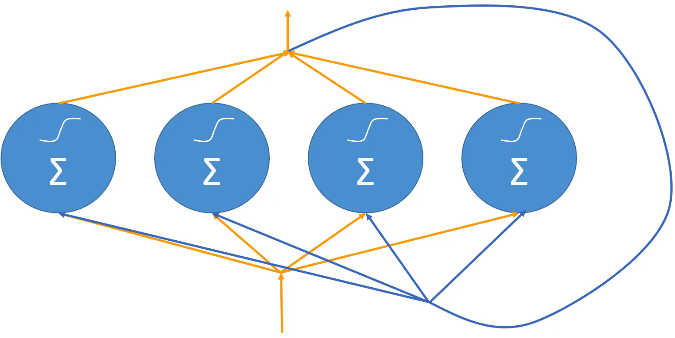
RNN topologies
RNN이 다룰 수 있는 대표적인 네 가지 조합이 있습니다.
- Sequence-to-Sequence
입력값이 시간 시리즈나 데이터 시퀀스라면 동일한 시간 시리즈나 데이터 시퀀스 출력도 얻을 수 있습니다.히스토리를 통한 미래의 주식 가격을 예측하는 경우 사용될 수 있습니다.
- Sequnce-to-Vector
다층 퍼셉트론을 통해 예측했던 이전 벡터의 정적 상태와 시퀀스를 혼합하여 매치할 수 있으며, Seq2Vecto 방식을 설명됩니다. 데이터 시퀀스로 시작하면 시퀀스를 분석하여 어떤 상태의 스냅샷을 생성할 수 있습니다.문장의 단어, 문맥을 보고 문장이 전하는 감정이 대표적입니다.
- Vector-to-Sequence
벡터에서 시퀀스로 갈 수도 있습니다.정적 벡터인 이미지를 취해 해당 벡터에서 시퀀스를 생성합니다. 이를 통해 이미지 벡터에 캡처된 컨텍스트를 일련의 단어로 디코딩합니다. 이미지에 있는 내용을 텍스트로 라벨링하는 것을 의미합니다.
- Encoder - Decoder
Sequence → vector → Sequence를 통해 암호기와 해독기가 서로 정보를 주고받을 수 있습니다.시퀀스를 벡터 표현 같은 문장의 의미를 구체화한 다음 새 시퀀스 단어로 바꾸는 과정입니다.대표적인 기계 번역 과정으로, 단어의 순서를 만들고 임베딩 레이어(컴퓨터용 단어 사전)라는 걸 만들게 되는데 문장의 의미를 구체화하는 벡터입니다. 이후 새로운 단어의 순서를 만들어 출력하게 됩니다.
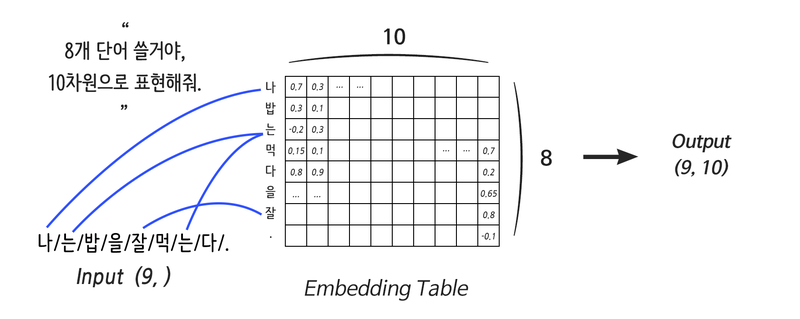
벡터란?
딥 러닝에서 "벡터"라는 개념은 기본이며 다양한 모델과 애플리케이션에서 광범위하게 사용됩니다. 이 맥락에서 벡터는 본질적으로 신경망과 같은 계산 모델이 처리할 수 있는 형식으로 데이터를 나타낼 수 있는 숫자 배열입니다. 벡터는 딥러닝 시스템에서 정보를 표현하고 조작하기 위한 기본 구성 요소 역할을 합니다. 개념과 그 의미를 더 자세히 살펴보겠습니다.
데이터 표현
- 인코딩 정보: 벡터는 실제 세계의 정보를 딥 러닝 모델이 이해하고 작업할 수 있는 형식으로 인코딩하는 데 사용됩니다. 예를 들어 자연어 처리(NLP)에서는 원-핫 인코딩이나 단어 임베딩과 같은 기술을 사용하여 단어나 문장을 벡터로 표현할 수 있습니다. 이미지 처리에서 이미지는 픽셀 값의 벡터(더 정확하게는 텐서)로 표현될 수 있습니다.
- 특징 및 차원: 벡터의 각 요소는 데이터 포인트의 특징으로 간주될 수 있습니다. 벡터의 차원은 특징의 수에 해당합니다. 예를 들어, 단어 임베딩을 사용하여 300차원 벡터 공간에 표현된 단어는 300개의 특징을 가지며, 각각은 단어의 의미론적 표현에 기여합니다.
작업 및 변환
- 벡터 연산: 딥 러닝은 선형 대수학에 크게 의존하며 벡터에는 덧셈, 뺄셈, 스칼라 곱셈과 같은 다양한 연산이 적용됩니다. 이러한 작업은 벡터의 표현을 수정하거나 여러 벡터의 정보를 결합할 수 있습니다.
- 변환: 신경망에서 벡터는 레이어를 통해 변환됩니다. 이러한 변환에는 가중치(벡터에 가중치 행렬을 곱함), 편향 추가 및 비선형 활성화 함수 적용이 포함될 수 있습니다. 이러한 변환의 목적은 데이터 내의 복잡한 패턴과 관계를 학습하는 것입니다.
학습 및 기능 공간
- 학습 가중치: 딥 러닝에는 일부 손실 함수를 최소화하기 위해 신경망의 가중치(매개변수)를 조정하는 작업이 포함됩니다. 이러한 가중치는 종종 벡터나 행렬로 초기화됩니다. 학습 프로세스는 네트워크가 입력을 출력에 정확하게 매핑할 수 있도록 이러한 벡터를 조정합니다.
- 고차원 공간: 벡터를 사용하면 데이터를 고차원 공간에 표현할 수 있습니다. 이러한 공간에서 딥 러닝 모델은 서로 다른 클래스를 구분하는 최적의 초평면을 찾거나 데이터의 복잡한 관계를 인코딩하여 복잡한 패턴을 구별하는 방법을 학습할 수 있습니다.
임베딩 및 잠재 공간
- 임베딩: 임베딩은 유사한 항목이 벡터 공간에서 서로 가까운 점에 매핑되는 조밀한 벡터 표현입니다. 예를 들어 단어 임베딩은 단어 간의 의미적 유사성을 포착합니다.
- 잠재 공간: 딥 러닝 모델, 특히 자동 인코더 및 생성적 적대 신경망(GAN)과 같은 생성 모델은 저차원 잠재 공간에서 데이터를 표현하는 방법을 학습합니다. 이 공간의 벡터는 생성, 압축 또는 특징 추출과 같은 작업에 사용할 수 있는 데이터의 본질 또는 "잠재" 특징을 포착합니다.
요약하자면, 벡터는 딥 러닝의 중요한 요소로, 데이터를 표현하고, 조작하고, 학습할 수 있는 다양하고 효율적인 방법을 제공합니다. 이를 통해 모델은 복잡한 패턴을 이해하고 생성할 수 있으므로 딥 러닝을 이미지 인식, 자연어 이해부터 추천 시스템 및 그 이상에 이르기까지 광범위한 애플리케이션을 위한 강력한 도구로 만들 수 있습니다.
Training RNN
훈련하는 동안 모든 레이어를 통해 데이터를 역추적해야합니다.시간이 지남에 따라 훈련해야할 신경망이 점점 더 깊어지고, 이미 깊어진 신경망에서 더 깊게 만드는 비용은 훨씬 커집니다.
BPTT (Backpropagation Through Time)
이를 방지하기 위해 BPTT를 사용하며, 순차 데이터와 관련된 작업을 수행하도록 RNN을 교육하여 시간이 지남에 따라 복잡한 패턴을 학습할 수 있도록 하는 방식입니다.훈련 시간에 상한도를 주어 제한된 시간 단위로 제한합니다.앞서 RNN을 구축할 때 이전 단계의 데이터가 시간이 지남에 따라 희석될 수 있다고 했습니다.현재 시간의 데이터를 더 가중치 있게 다루기 때문인데 오래된 행동이 새 행동보다 중요하다면 문제가 생길 수 있습니다.대표적으로 단어에서 앞 부분의 단어가 뒤 단어보다 중요하게 되어버리는 문제가 발생할 수 있습니다.
LSTM Cell(Long Short-Term Memory Cell)
단기적 상태와 장기적 상태를 분리하여 유지하는 기법입니다.중요한건 최신 데이터에 특별대우를 하고싶지 않다는 것입니다.최적화 작업은 GRU 세포라고 불리는 LSTM 위에 이루어져 구성되며 모델에 성능과 훈련 기간에 따라 성능을 절충해야 합니다.
Modern Natural Language Processing(NLP)
Transformer
Transformer는 "Self-Attention"이라는 메커니즘을 사용하여 입력 데이터의 각 부분의 중요성을 저울질 하는 방식입니다.입력과 출력 간의 전역 종속성을 끌어내므로 입력 시퀀스에서 서로 다른 단어의 중요성을 서로 비교하여 가중치를 부여할 수 있습니다. 단어를 인코딩할 때 문장의 다른 부분에 얼마나 집중해야 하는지를 나타내는 점수를 계산합니다. 이 메커니즘을 통해 모델은 동일한 문장의 다른 단어와 관련하여 단어의 컨텍스트를 캡처할 수 있으므로 문장 구조와 의미에 대한 이해가 크게 향상됩니다.기계 번역, 텍스트 요약, 최근에는 GPT(Generative Pretrained Transformer)와 같은 대규모 언어 모델의 중추로 사용됩니다. 가장 큰 차이점은 모든 단어를 동시에 처리할 수 있다는 점입니다.이를 기반으로한 다양한 모델들이 만들어져 있으며 대표적으로 BERT, RoBERTa, T5, GPT-2가 있습니다.Knowledge Distillation(지식 증류)라는 걸 사용해서 압축하여 모델의 크기를 줄일 수 있습니다.
BERT(BiDirectional Encoder Representations from Transformers)
Transformer 아키텍처 프레임워크 내에서 "양방향 인코더" 개념을 도입하여 선형 또는 단방향 방식(왼쪽에서 오른쪽 또는 오른쪽에서 왼쪽)으로 데이터를 처리하는 기존 모델과 달리 BERT의 양방향 접근 방식을 사용하면 시퀀스의 지정된 토큰에 대해 양방향(왼쪽 및 오른쪽)에서 동시에 컨텍스트를 고려할 수 있습니다.
양방향성의 의미
- 향상된 문맥 이해: BERT는 각 단어의 전체 맥락을 고려함으로써 다양한 문맥에서 단어의 뉘앙스와 의미를 더 잘 이해할 수 있습니다. 이를 통해 질문 답변, 명명된 엔터티 인식 및 감정 분석과 같은 광범위한 NLP 작업의 성능이 향상됩니다.
- 다운스트림 작업에 대한 적용 가능성: 사전 훈련 중에 학습된 양방향 컨텍스트는 특정 다운스트림 작업에 맞게 미세 조정될 때 BERT를 매우 효과적으로 만듭니다. 사전 훈련된 모델은 상대적으로 적은 작업별 데이터로 정제할 수 있는 언어에 대한 풍부한 이해를 갖추고 있습니다.
- 어텐션 메커니즘: BERT의 양방향 특성은 Transformer 인코더의 자체 어텐션 메커니즘을 통해 구현됩니다. 인코더의 각 계층에서 self-attention을 통해 모델은 각 단어를 인코딩할 때 문장에 있는 다른 모든 단어의 중요성을 평가할 수 있습니다. 이는 각 단어의 인코딩이 전체 문장 컨텍스트에 의해 알려짐을 의미합니다.
Transfer Learning
NLP 모델의 경우 매우 크고 복잡하기 때문에 매번 다시 훈련하는데 어려움이 있으며, 엄청난 연산력이 필요하게 됩니다.이를 해결하기 위해 transfer learning(전이 학습)을 사용하여 미리 훈련된 모델을 사용할 수 있게 조정하며 미리 훈련된 모델을 사용할 수 있도록 도와줍니다.
전이학습
전이 학습은 하나의 문제를 해결하면서 얻은 지식을 활용하고 이를 다른 관련 문제에 적용하는 머신 러닝 및 딥 러닝 분야의 강력한 기술입니다. 이 접근 방식은 대량의 데이터를 사용할 수 있는 작업과 다소 유사한 작업에서 모델을 교육하기 위한 데이터 양이 제한된 시나리오에서 특히 유용합니다.
전이 학습의 작동 방식
전이 학습의 핵심은 사전 훈련된 모델(대규모 벤치마크 데이터 세트에서 훈련된 모델)을 가져와 다르지만 관련된 작업에 맞게 용도를 변경하는 것입니다. 전이 학습과 관련된 일반적인 단계는 다음과 같습니다.
- 사전 훈련된 모델: 대규모 데이터 세트에 대해 사전 훈련된 모델로 시작합니다. 예를 들어, 이미지 인식의 맥락에서 ImageNet 데이터 세트에 대해 훈련된 모델은 일반적으로 시작점으로 사용됩니다.
- 특성 추출: 사전 훈련된 모델을 사용하여 새 데이터세트에서 특성을 추출합니다. 여기에는 모델을 통해 데이터를 전달하고 중간 레이어 중 하나의 출력을 기능 세트로 사용하는 작업이 포함됩니다. 모델이 광범위한 데이터에서 패턴을 식별하는 방법을 학습했기 때문에 이러한 특징은 좋은 표현으로 추정됩니다.
- 모델 수정: 새 작업에 맞게 모델을 수정합니다. 이는 일반적으로 모델의 최종 레이어를 새 작업에 맞게 조정된 새 레이어로 교체하는 것을 의미합니다. 이렇게 수정하는 이유는 신경망의 초기 레이어가 작업 전반에 적용할 수 있는 일반적인 특징(예: 이미지의 가장자리 또는 텍스처)을 캡처하는 반면, 최종 레이어는 작업에 더 구체적이기 때문입니다.
- 미세 조정: 선택적으로 새 작업에서 모델을 미세 조정합니다. 여기에는 새 데이터 세트에서 모델(또는 그 일부)을 교육하는 작업이 포함됩니다. 새 데이터 세트의 크기와 새 작업과 원래 작업의 유사성에 따라 모델의 모든 레이어를 미세 조정하거나 새로 추가된 레이어만 미세 조정하도록 선택할 수 있습니다.
전이 학습의 이점
- 효율성: 전이 학습은 사전 학습된 모델의 기존 계산을 활용하므로 기계 학습 모델을 개발하는 데 필요한 계산 비용과 시간을 크게 줄일 수 있습니다.
- 성능: 전이 학습을 통해 개발된 모델은 원래 훈련된 대규모 데이터 세트에서 얻은 지식을 활용하므로 상대적으로 작은 데이터 세트로도 높은 정확도를 달성할 수 있는 경우가 많습니다.
- 접근성: 대규모 모델을 처음부터 교육할 리소스가 없는 개인과 조직이 고급 기계 학습 기능에 액세스할 수 있도록 해줍니다.
전이 학습의 응용
전이 학습은 다음을 포함한 다양한 도메인에 성공적으로 적용되었습니다.
- 이미지 인식: 사전 훈련된 모델을 활용하여 특정 객체나 장면을 인식하는 모델의 정확도를 향상합니다.
- 자연어 처리(NLP): 대규모 텍스트 말뭉치에 대해 사전 훈련된 모델을 시작하여 감정 분석, 번역, 텍스트 요약과 같은 작업을 위한 언어 모델을 개선합니다.
- 음성 인식: 일반적인 음성에 대해 훈련된 모델을 적용하여 특정 어휘나 억양을 인식합니다.
요약하면, 전이 학습은 기존 모델을 새롭지만 유사한 작업에 적용하여 모델 성능과 효율성을 향상시켜 기존 모델의 유용성을 극대화하는 기술입니다.요즘엔 Hugging Face라고 하며 이미 훈련된 많은 모델들이 저장되어있고 불러와 실행할 수 있습니다.수천 개의 NLP 모델을 그냥 불러올 수 있습니다.
Hugging Face
세이지메이커와 통합하여 딥러닝 컨테이너(DLC)를 통해 실행되며 그대로 사용하거나 사용 케이스에 맞게 미세 조정을 할 수 있습니다.
BERT Example
미리 훈련된 데이터를 사용하는게 아닌 여러분만의 훈련 데이터가 있다면 해당 단어를 토큰화해야합니다. 이를 통해 BERT가 원래 훈련받은 형식과 같은 포맷으로 사용할 수 있지만, 가장 어려운 부분이기도 합니다.너무 높은 학습횟수를 설정하면 데이터가 과적합될 수 있으니 적절한 학습이 필요합니다.
Transfer Learning 접근방식(fine-tuning)
사전 학습된 모델을 미세 조정하려면 대규모의 일반 데이터 세트에서 이미 학습된 모델로 시작한 다음 더 작은 작업별 데이터 세트에서 해당 모델을 추가로 학습(또는 파인튜닝)하는 작업이 포함됩니다. 이 프로세스를 통해 모델은 일반 데이터 세트에서 학습된 기능과 지식을 조정하여 특정 작업을 잘 수행할 수 있습니다.
파인튜닝
- 사전 훈련된 지식 활용: 사전 훈련된 모델은 초기 대규모 데이터세트에서 얻은 지식을 가져옵니다. 여기에는 종종 문제 공간이나 영역에 대한 광범위한 표현이 포함됩니다(예: 다양한 텍스트의 다양한 텍스트). NLP 작업을 위한 언어).
- 특정 작업에 적응: 더 작은 작업별 데이터 세트에 대한 학습 프로세스를 계속함으로써 모델은 처음부터 시작하지 않고도 대상 작업의 뉘앙스와 특정 기능을 학습합니다. 이는 작업별 데이터 세트가 너무 작아 처음부터 매우 효과적인 모델을 훈련할 수 없거나 계산 리소스가 제한적인 경우에 특히 유용합니다.
- 점진적 개선: 작업별 데이터 세트에 대한 교육은 일반적으로 초기 교육에 비해 낮은 학습률로 수행됩니다. 이 접근 방식은 모델이 획득한 귀중한 지식을 유지하는 동시에 특정 작업에 대한 성능을 미세 조정하도록 조정하는 데 도움이 됩니다.
- 사전 훈련된 지식을 잃지 않음: 미세 조정의 목표는 사전 훈련된 지식을 덮어쓰는 것이 아니라 이를 기반으로 구축하는 것입니다. 모델이 새 데이터에서 학습하는 동안 사전 훈련된 귀중한 기능을 잃지 않도록 하기 위해 학습률의 신중한 선택, 정규화 방법 사용, 때로는 모델의 레이어를 선택적으로 동결하는 등의 기술이 사용됩니다.
추가적으로 모델 위에 훈련 가능한 레이어를 추가할 수 있지만 기존 레이어가 새로운 데이터로 예측하는 방법을 학습시켜야합니다.따라서 자주 볼 수 있는 방식은 기존의 frozen model을 가져다가 세밀하게 조정해서 자신의 데이터셋을 훈련하는 방식입니다.만약 훈련 데이터가 많은데 모델 자체에 신경쓴다면 훈련 이전의 데이터는 버리고 다시 시작할 수 있으며, 물론 그에 맞는 컴퓨팅 파워가 필요하게 됩니다.
Tuning Neural Networks(신경망 튜닝)
시험 및 실제 환경에서 가장 중요한 부분으로 신경망 학습, 결과 출력에 중요한 영향을 미치게 됩니다.
Learning Rate
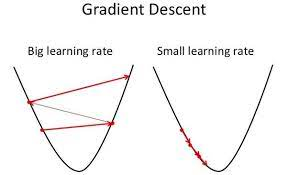
신경망은 경사 하강법 (Gradient descent)라는 기법을 통해 학습합니다.딥러닝의 학습률은 훈련 중 손실 기울기와 관련하여 네트워크의 가중치를 조정하는 정도에 영향을 미치는 중요한 하이퍼 매개변수입니다. 본질적으로 이는 손실 함수를 최소화하려고 시도하면서 최적화 프로세스 중에 취하는 단계의 크기를 결정합니다.학습률의 값은 학습 과정의 속도와 품질에 직접적인 영향을 미칩니다. 너무 학습률을 큰 값으로 하는 경우 속도를 빠르게 할 순 있지만 적절한 지점을 지나쳐 학습이 제대로 안되고 오류가 많이 발생하고 너무 작은 값으로 하게되면 적절한 지점을 찾는데 오래 걸리고 많은 비용이 들게 됩니다. 따라서 적절한 값으로 설정해서 시간과 비용 사이에 정확한 지점(수렴)을 찾는게 중요합니다.
학습률은 하이퍼파라미터의 한 가지 예시로 딥 러닝 모델을 훈련할 때 중요한 결과를 미치게 됩니다.
Batch Size
신경망의 배치 크기는 모델의 내부 매개변수(가중치)가 업데이트되기 전에 처리할 훈련 샘플 수를 지정하는 중요한 하이퍼 매개변수입니다. 이는 훈련 프로세스에서 중요한 역할을 하며 모델의 수렴 속도, 메모리 사용량 및 잠재적으로 최종 성능에 영향을 미칩니다. 배치 크기의 영향을 이해하면 신경망을 보다 효과적으로 조정하는 데 도움이 될 수 있습니다.
Batch size는 손실 함수(정답값과 예측값의 오차를 계산해주는 함수)의 최솟값을 찾는 방식에서 중요한 역할을 합니다.그렇다면 작은 배치 크기가 왜 로컬 최솟값을 벗어날 수 있다는 건지?→ 배치가 작을수록 배치가 클수록 가중치가 더 자주 업데이트됩니다. 각 업데이트는 교육 데이터의 다양한 하위 집합을 고려합니다.
즉, 업데이트 방향이 더 다양해지고 모델이 로컬 최소값을 벗어나는 데 도움이 될 수 있습니다.최적화의 맥락에서 탐색은 매개변수 공간의 더 넓은 부분을 검색하는 것을 의미하는 반면, 활용은 로컬 영역에서 검색을 구체화하는 데 중점을 둡니다. 경사 추정의 분산이 높을수록 모델이 매개변수 공간의 더 넓은 영역을 탐색할 수 있으므로 작은 배치 크기는 탐색 방향으로 기울어집니다. 이는 로컬 최소값이 더 널리 퍼져 있는 복잡한 모델 및 손실 환경에서 특히 유용할 수 있습니다.
Batch Size 정리
대규모 배치 크기
- 정확한 기울기 추정: 대규모 배치는 기울기에 대한 보다 정확한 추정을 제공하여 최적화 프로세스에서 안정적이고 정확한 단계로 이어집니다. 이는 손실 함수를 최소화하기 위한 일관된 진전을 이루는 데 유리할 수 있습니다.
- 로컬 최소값에 대한 편향 가능성: 정확한 추정으로 인해 최적화가 로컬 최소값에 정착할 가능성이 더 높습니다. 모델은 더 큰 표본의 범위 내에서 최적인 것처럼 보이지만 전체적으로는 최고가 아닐 수 있는 솔루션을 찾을 수 있습니다.
- 솔루션으로서의 노이즈: 학습 프로세스에 노이즈를 도입하면(예: 더 작은 배치 또는 기타 기술을 통해) 최적화 프로세스를 추진하여 더 많은 매개변수 공간을 탐색함으로써 모델이 이러한 로컬 최소값을 탈출하는 데 도움이 될 수 있습니다.
소규모 배치 크기
- 잦은 업데이트: 배치가 작을수록 업데이트가 더 자주 발생하므로 매개변수 공간에서 더 다양한 단계를 수행하여 모델이 로컬 최소값을 잠재적으로 벗어날 수 있습니다. 이는 모델이 "탐색"할 기회가 더 많고 더 전역 최소값을 향한 더 나은 경로를 찾을 수 있는 것으로 볼 수 있습니다.
- 계산 비용: 소규모 배치는 로컬 최소값을 피하는 데 도움이 될 수 있지만 계산 비용이 증가한다는 단점이 있습니다. 각 업데이트는 대규모 일괄 업데이트보다 계산 집약도가 낮지만 총 업데이트 수(따라서 총 계산)는 상당히 높을 수 있습니다. 이로 인해 벽시계 시간 측면에서 매우 작은 배치에 대한 학습이 느려질 수 있습니다. 특히 대규모 배치의 병렬 처리가 더 효율적인 하드웨어에서는 더욱 그렇습니다.
- 불안정성 가능성: 소규모 배치로 인해 발생하는 노이즈는 학습 과정의 불안정성을 초래할 수도 있습니다. 손실을 최소화하기 위한 모델의 경로는 더 불규칙할 수 있으며, 학습률 및 기타 하이퍼파라미터를 주의 깊게 관리하지 않으면 수렴하는 데 시간이 더 오래 걸리거나 심지어 분기될 수도 있습니다.
요약하자면, 올바른 배치 크기를 선택하는 것은 학습의 안정성과 효율성, 사용 가능한 계산 리소스 간의 균형을 맞추는 것입니다. 대규모 배치는 더 안정적이지만 로컬 최소값에 갇힐 수 있는 반면, 작은 배치는 이러한 최소값을 벗어날 수 있지만 계산 리소스가 증가하고 잠재적인 불안정성이 발생합니다. 최적의 배치 크기는 특정 문제, 모델 아키텍처 및 계산 환경에 따라 달라지는 경우가 많습니다.
에포크(Epoch)
에포크는 전체 데이터셋이 모델을 통해 한 번 전체적으로 처리되는 과정을 말합니다. 하나의 데이터를 몇번 쥐어짜는지를 의미합니다.대부분의 딥러닝 학습 과정에서는 여러 에포크에 걸쳐 학습이 이루어집니다.
Recap
- 작은 배치 크기는 로컬 최솟값에 갇히지 않는 경향이 있습니다. > 계산 효율성 측면에서 덜 효율적일 수 있지만 최적화 과정에서 손실 함수의 표먼을 탐색하게 하면서 지역 최소값에 덜 민감해지고 전역 최솟값을 찾을 수 있는 가능성이 높아집니다.
- 큰 배치 크기는 로컬 최솟값에 갇힐 수 있습니다.
- 학습률이 높으면 더 나은 솔루션을 찾을 수 있습니다.
- 학습률이 낮으면 훈련시간이 늘어납니다.
신경망 정규화
정규화는 기본적으로 오버 피팅을 방지하기 위한 기술입니다.훈련 데이터로 예측하는데 능숙한 모델이 있지만 새 데이터에서는 잘 되지 않습니다. 이말은 훈련 데이터의 패턴을 완전히 학습하여 훈련 데이터는 정확도가 높고 테스트 데이터나 검증 데이터의 정확도가 낮다면 오버 피팅에 걸렸다는 경고인 셈이 됩니다.정규화 기법으로 다음과 같은 방법들이 존재합니다.
모델 단순화
레이어나 뉴런이 너무 많아 데이터가 오버 피팅될 수 있습니다. 모델을 단순화함으로써 복잡한 패턴을 학습하는 능력을 줄일 수 있습니다.
Drop out
드롭아웃 레이어를 사용하여 각 훈련마다 무작위로 선택한 뉴런을 제외시키는 방법입니다. 학습이 더 많은 뉴런에 퍼지도록 만들어 특정 데이터 포인터에 과부화되는 걸 막고, 모델 별 학습 범위를 더 넓힐 수 있게 하는 방식입니다.신경망에서 뉴런을 제거시켜 복잡한 구성을 줄이고 일반화시킬 수 있도록 합니다.
일찍 멈추기
훈련 중에 사용되지 않는 별도의 데이터 세트인 검증 세트에서 모델 성능을 모니터링하고 모델이 과적합되기 전에 훈련 프로세스를 중지함으로써 이 문제를 해결합니다.

비용함수와 손실함수의 차이
- 범위: 손실 함수는 단일 데이터 포인트에 대한 예측 오류에 관한 것이고, 비용 함수는 전체 훈련 데이터 세트에 대한 모델의 총 오류에 관한 것입니다.
- 훈련에서의 사용: 경사 하강법과 같은 최적화 알고리즘은 모델 매개변수를 조정하여 비용 함수를 최소화하는 것을 목표로 합니다. 개별 데이터 포인트에 대한 손실 함수의 값은 이 전체 비용에 기여합니다.
L1 and L2 정규화(가중치 규제)
단순한 딥 러닝이 아닌 머신 러닝 전 분야에 적요되는 사항으로 두 기술의 차이점을 파악하여 언제 적용할지를 알아야합니다.L1 및 L2 정규화는 모델의 계수(가중치) 크기에 불이익을 주어 신경망을 포함한 기계 학습 모델의 과적합을 방지하는 데 사용되는 기술입니다. Weight값이 과도하게 커져서 일부 Feature에 의존하는 현상을 방지하고 데이터를 일반화할 수 있도록 하는 과정입니다.
L1 정규화(Lasso)
L1 정규화는 손실 함수에 모델의 가중치의 절대값의 합에 비례하는 항을 추가합니다. 이는 일부 가중치를 정확히 0으로 만들어, 모델이 더 간단해지고 일부 특성이 모델에 의해 완전히 무시되도록 합니다. 이러한 특성은 특성 선택(feature selection)과 관련이 있으며, 불필요한 특성을 모델에서 제거할 수 있게 해줍니다.예시: 회귀 모델에서 L1 정규화를 적용할 경우, 모델은 데이터의 중요하지 않은 특성의 가중치를 0으로 만들어, 결과적으로 중요한 특성만을 사용하여 예측을 수행하게 됩니다.
L2 정규화 (Ridge 정규화)
L2 정규화는 손실 함수에 모델의 가중치의 제곱의 합에 비례하는 항을 추가합니다. 이는 모든 가중치를 작게 만들어, 모델의 복잡도를 줄이는 효과를 가지며, 과적합을 방지하는 데 도움을 줍니다. L2 정규화는 가중치를 완전히 0으로 만들지는 않지만, 모든 가중치를 작게 유지하여 모델이 더 부드러운 예측을 하도록 합니다.예시: 회귀 모델에서 L2 정규화를 사용할 경우, 모델은 특성 간의 관계를 더욱 고려하여, 가중치가 과도하게 커지는 것을 방지함으로써 보다 일반화된 모델을 만듭니다.
차이점
L1은 특정 feature의 가중치를 0으로 만들어 feature를 선택하는 효과가 있습니다. 반면 L2 정규화는 모든 특성을 유지하지만 가중치를 줄입니다.두 방법 모두 과적합을 방지할 수 있으나, L1은 특성의 수를 줄이고, L2는 가중치의 크기를 줄임으로써 이를 달성합니다.
Vanishing Gradient Problem(기울기 소멸 문제)
Vanishing Gradient Problem(소실 그래디언트 문제)는 심층 신경망을 훈련할 때 발생하는 문제로, 신경망의 손실 함수에 대한 그래디언트가 훈련 중에 계층을 거슬러 전파(역전파)될 때 점점 더 작아지는 현상입니다. 이 문제는 신경망의 초기 계층에서 가중치가 효과적으로 업데이트되기 어렵게 만들어, 훈련 과정을 상당히 느리게 하거나 심지어 신경망이 데이터에서 복잡한 패턴을 학습하는 것이 실질적으로 불가능하게 만듭니다.기울기가 0이 된다면 해당 지점에서 도함수가 0이라는 것을 의미합니다.해당 지점에서 순간적인 변화율이 없음을 나타내며 해당 지점에서는 함수값이 증가하지도 감소하지도 않습니다.
기울기 소멸 문제를 해결하는 방법
- 다중 레벨 게층 구조를 이용
신경망을 여러 층으로 나누어 개별적으로 훈련하는 방식입니다.신경망 전체를 한 번에 훈련하는 대신 모든 계층을 함께 훈련하고 몇 단계를 반복해서 훈련하는 방식입니다.
- LSTM
Long Short-Term Memory(LSTM) 유닛과 Gated Recurrent Units(GRU)와 같은 아키텍처는 많은 계층에 걸쳐 곱셈을 통해 그래디언트가 희석되지 않고 네트워크를 통해 흐를 수 있는 게이팅 메커니즘을 가지고 있습니다.
- ReLu를 사용
양수인 입력에 대해 입력을 직접 출력하고, 그렇지 않으면 0을 출력하는 Rectified Linear Unit(ReLU) 함수는 양의 도메인에서 포화되지 않기 때문에 인기 있는 선택이 되었습니다. 이는 소실 그래디언트 문제를 완화하는 데 도움이 됩니다.
Gradient Checking
신경망 프레임워크를 개발하는 동안 제대로 계산된 값인지 확인하는 방식입니다.그래디언트 체킹은 계산 비용이 많이 드는 작업입니다. 코드나 프레임워크보다 낮은 수준에서 실행되며 신경망의 각 매개변수에 대해 비용 함수를 두 번 계산해야 하기 때문에, 일반적으로 디버깅 도구로 사용되며 정기적인 훈련 과정의 일부로는 사용되지 않습니다.
Confusion Matrix
https://bcho.tistory.com/1206
모델의 미묘한 결과를 이해할 수 있습니다.희귀병 검사의 경우 정확도는 99.9%일 수 있는데 No만 출력해도 많은 케이스가 실제 No이기 떄문입니다.
- 참 양성(True Positive, TP): 모델이 양성이라고 예측했고, 실제로도 양성인 경우.
- 참 음성(True Negative, TN): 모델이 음성이라고 예측했고, 실제로도 음성인 경우.
- 거짓 양성(False Positive, FP): 모델이 양성이라고 예측했지만, 실제로는 음성인 경우. (1종 오류 또는 가양성)
- 거짓 음성(False Negative, FN): 모델이 음성이라고 예측했지만, 실제로는 양성인 경우. (2종 오류 또는 가음성)
이 요소들을 이용해 혼동 행렬을 다음과 같이 나타낼 수 있습니다:(라벨 주의)대각선이 정확성을 확인하는데 중요한 부분입니다. 거짓 음성과 거짓 양성은 적게 나와야합니다.
| 실제값 \ 예측값 | 양성으로 예측 | 음성으로 예측 |
|---|---|---|
| 실제 양성 | TP | FN |
| 실제 음성 | FP | TN |
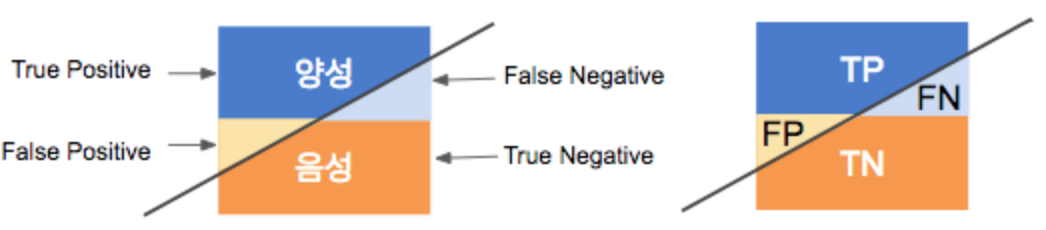
어떤 부분이 예측이고 어떤 부분이 실제인지 라벨을 잘 확인해야합니다.
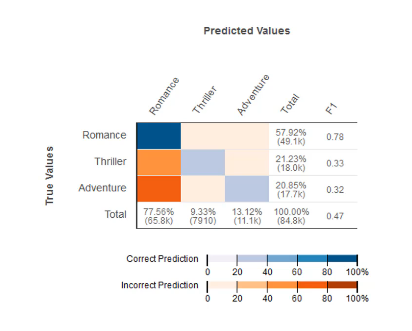
영화 카테고리 별 틀린 횟수와 맞힌 횟수입니다. > 오렌지색일 수록 많이 틀렸고, 파란색일 수록 정확히 맞췄다는 것입니다. 위 자료로 볼 때 실제 예측값은 스릴러인데 로맨스로 착각하는 경우와 어드벤쳐인데 로맨스로 착각하는 경우가 많다고 볼 수 있습니다.
| 실제 \ 예측 | Positive | Negative | 총계 |
|---|---|---|---|
| Positive | TP | FN | TP + FN |
| Negative | FP | TN | FP + TN |
| 총계 | TP + FP | FN + TN |
총계 열 (Total Column)
- 총계 열은 모델이 각 클래스(Positive, Negative)를 얼마나 자주 예측했는지를 나타냅니다. 즉, 각 열의 값들을 합산하여 얻을 수 있으며, 모델이 특정 클래스를 양성으로 예측한 총 횟수를 보여줍니다. 이는 모델의 경향성을 이해하는 데 도움이 됩니다(예: 모델이 어떤 클래스를 과다하게 예측하는 경향이 있는지).
- 모델이 Positive로 분류한 총 횟수(TP + FP)와 Negative로 분류한 총 횟수(FN + TN)를 보여줍니다.
총계 행 (Total Row)
- 총계 행은 각 실제 클래스가 데이터셋에 얼마나 자주 등장하는지를 나타냅니다. 즉, 각 행의 값들을 합산하여 얻을 수 있으며, 실제 데이터에서 각 클래스가 차지하는 비율을 보여줍니다. 이는 데이터의 분포를 이해하는 데 도움이 됩니다(예: 특정 클래스가 다른 클래스에 비해 상대적으로 더 적거나 많은지).
실제 Positive인 총 경우의 수(TP + FN)와 실제 Negative인 총 경우의 수(FP + TN)를 보여줍니다.F1열 에서는 클래스당 F1 스코어가 있고 정밀 열도 있습니다.
F1 스코어
F1 점수(F1 Score)는 모델의 정밀도(Precision)와 재현율(Recall)을 조화 평균으로 계산한 값입니다. 이는 두 지표의 균형을 고려하여 모델의 성능을 평가할 때 사용되며, 특히 양성 클래스의 예측이 중요할 때 유용합니다.
재현율과 정밀도에 관해정밀도는 저네 중 정답 비율을 계산해주는 방법이며, 높을수록 정확하다고 할 수 있습니다. 하지만 잘못하면 편향되어 해석할 수 있는데, 특히 제대로 밸런스가 맞지않은 데이터엔 비적합합니다.(희귀병 환자는 일단 False)재현율은 정확도 측정시 나타날 수 있는 문제를 보완해주는 것으로, 실제 데이터에 Negative 비율이 높아 희박한 가능성으로 발생할 상황에 대해 제대로된 분류를 했는지 평가할 수 있는 지표입니다.
따라서 True가 발생하는 확률이 낮을 때 사용하면 적합합니다.
예시: 이메일 스팸 필터
상황: 당신은 이메일 서비스 제공자이고, 사용자의 이메일 중에서 스팸을 필터링하는 모델을 개발했습니다. 이 모델을 테스트하기 위해 100개의 이메일을 샘플로 사용하며, 이 중 20개가 실제 스팸이라고 가정합니다.모델 실행 결과:
- 모델이 스팸이라고 분류한 이메일이 15개 있습니다.
- 실제로 스팸인 이메일 중 10개를 모델이 정확하게 스팸(TP)으로 분류했습니다.
- 따라서, 스팸이 아닌 이메일 중 5개를 모델이 잘못 스팸(FP)으로 분류했습니다.
- 나머지 10개의 실제 스팸 이메일 중에서 모델이 스팸이 아니라고 잘못 분류한 경우(FN)도 있습니다.
이제 이 정보를 바탕으로 정밀도와 재현율을 계산해 보겠습니다.
정밀도 계산
정밀도는 모델이 스팸으로 분류한 이메일 중 실제로 스팸인 이메일의 비율입니다.정밀도=(FP)참 양성 /( 참 양성 (TP)+거짓 양성 )즉, 모델이 스팸으로 분류한 이메일 중 67%만이 실제 스팸입니다.
재현율 계산
재현율은 실제 스팸 이메일 중 모델이 스팸으로 올바르게 분류한 이메일의 비율입니다.재현율=/ 참 양성 (TP) / (참 양성 (TP)+거짓 음 (FN))즉, 실제 스팸 이메일 중 50%만이 모델에 의해 스팸으로 분류되었습니다.
모델 성능 측정하기
Confusion Metrix에서 얻을 수 있는 몇가지 지표가 있습니다.
| 실제값 \ 예측값 | 사기로 예측 | 사기 아님을 예측 |
|---|---|---|
| 사기임 | TP | FN |
| 사기아님 | FP | TN |
재현율(민감도(sensitivity))

전체 양성중에 실제로 양성으로 예측한 값입니다.얼마나 잘 예측했는지, 현실성있는지를 판단하는 지표입니다.특히 이진 분류 작업과 관련하여 분류 모델의 성능을 평가하는 데 사용되는 측정항목입니다. 모델에 의해 올바르게 식별된 실제 긍정의 비율을 측정합니다. 긍정적인 사례의 누락(예: 질병 식별 실패, 사기 거래 간과)이 심각한 결과를 초래하는 상황에서는 재현율이 매우 중요합니다.
재현율을 너무 신경쓰다보면 FN을 줄이기 위해 사기가 아님에도 사기로 예측(FP)하는 비율이 증가하게 되어 중요한 거래가 잘못 필터링 되어 사기로 간주될 수 있습니다.
정밀도(측정값이 가까운지(Correct Positive, Precision))

양성으로 예측한 값 중 실제 양성입니다모델의 긍정적인 예측의 정확성을 측정하는 지표로 거짓양성을 나타낼 때 중요한 지표로 사용됩니다.정밀도가 높으면 여러 값을 정밀하게 판단하므로 True를 Negative(FN)로 예측하는 비율이 올라갑니다.재현율과 반대로 너무 신경쓰게 되면 실제 사기인데 사기가 아님을 예측하는 FN 값이 증가할 수 있으며, 특정한 상황 > 스팸(스팸을 잘 거르지 못해도 사용자의 메시지를 차단하면 안됨)같은 상황에서 사용될 수 있습니다.ex) 의학검사, 약물검사 → 약이나 질병이 없는데 했다고하면 문제가 생기게 됩니다.민감도와 정밀도는 상충 관계가 있습니다.
민감도를 높히기 위해 임계값를 낮춰 양성 예측 비율을 높히게 되면, 무분별한 양성예측으로 정밀도가 내려가고 반대로 정밀성을 높이면 임계값이 낮아져 양성임에도 양성으로 감지되지 않을 수 있습니다.
특이성(specificity)
실제 False에서 올바르게 예측된 False의 비율입니다.

F1 Score
정확성과 정밀성의 균형을 잡는 척도로 사용됩니다.
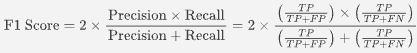
RMSE
정확도를 측정하는 것으로 사용되며 오로지 맞았는지 틀렸는지를 확인하는 지표입니다.오로지 맞고 틀렸다는 정답만을 다루며, 예측과 실제 값 사이의 정확성을 신경쓴다면 RMSE를 주로 사용합니다.
ROC Curve
ROC (Receiver Operating Characteristic) 곡선은 이진 분류 모델의 성능을 평가하는 데 사용되는 그래픽 표현입니다. 이는 분류 임계값이 변화함에 따라 이진 분류기 시스템의 진단 능력을 나타내는 도구입니다. ROC 곡선은 두 매개변수를 플롯합니다:
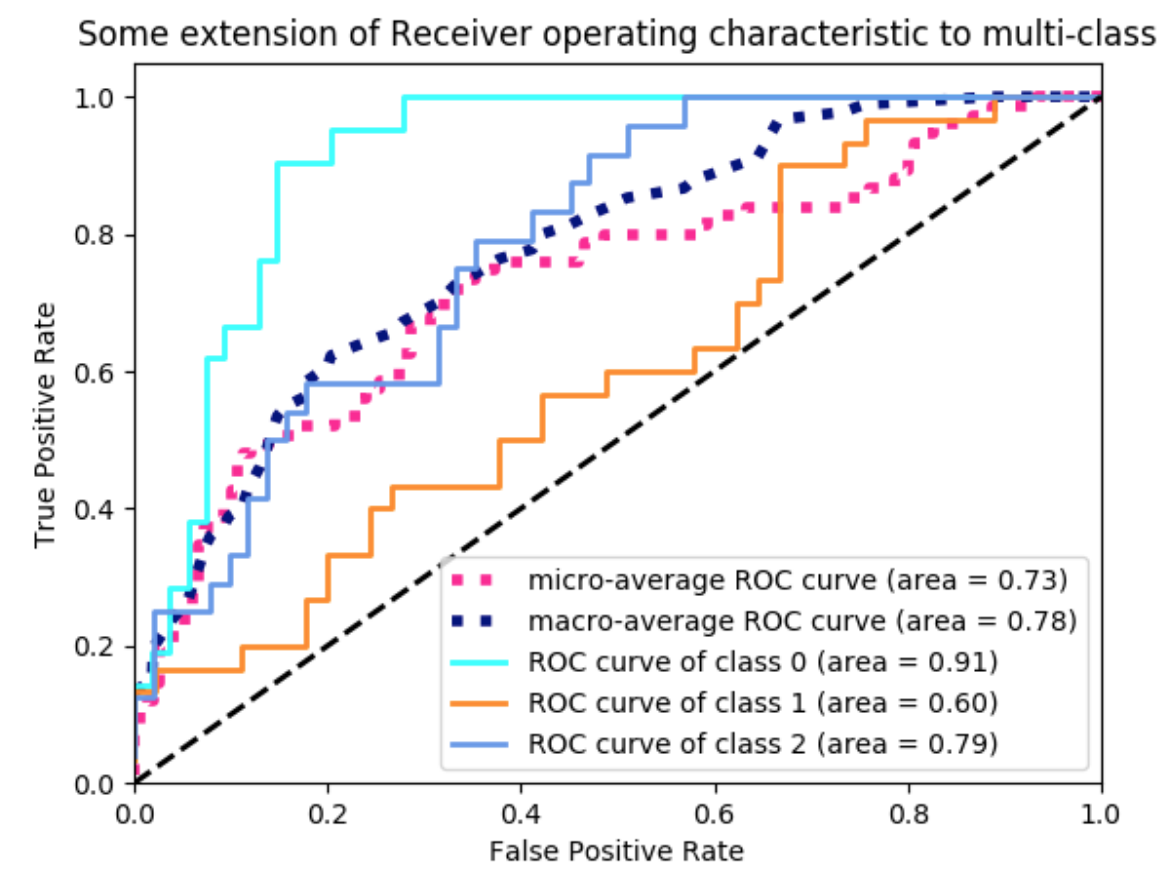
- 실제 양성 비율 (True Positive Rate, TPR), 또한 민감도 또는 재현율로 알려져 있으며, Y축에 표시됩니다.
- 거짓 양성 비율 (False Positive Rate, FPR), 특이성으로 알려져 있으며, X축에 표시됩니다. (FP / F)
이미지를 확인해보면 실제 양성 비율(Y축)이 높고 거짓 양성 비율(X축)이 낮은 그래프, 즉 왼쪽 위로 많이 기울어져있으면 기울어질수록 더 좋은 모델로 표현됩니다. ROC 곡선은 TPR과 FPR 간의 균형을 기반으로 애플리케이션의 특정 요구 사항을 가장 잘 충족하는 분류를 위한 최적의 임계값을 선택하는 데 도움이 될 수 있습니다.
해석
- 곡선: ROC 곡선은 (0,0)에서 시작하여 (1,1)에서 끝납니다. 완벽한 구별 능력을 가진 모델(양성과 음성 집단 간에 중첩이 없는 경우)은 상단 왼쪽 모서리 (0,1)을 지나는 ROC 곡선을 가지며, 이는 100% 민감도(거짓 음성이 없음)와 100% 특이도(거짓 양성이 없음)를 나타냅니다.
- 곡선 아래 면적 (AUC): ROC 곡선 아래 면적은 모델이 양성과 음성 클래스를 구별하는 능력의 척도입니다. AUC가 1이면 완벽한 모델을, AUC가 0.5이면 무용한 모델(랜덤 추측과 동일)을 나타냅니다.
- 임계값 선택: ROC 곡선은 TPR과 FPR 사이의 트레이드오프를 기반으로 응용 프로그램의 특정 요구 사항에 가장 잘 맞는 최적의 분류 임계값을 선택하는 데 도움을 줄 수 있습니다.
ROC 곡선은 의료 결정, 스팸 탐지, 신용 평가 등 민감도와 특이도를 균형있게 고려해야 하는 모든 이진 분류 문제에서 널리 사용됩니다. 이는 분류 모델의 성능을 평가하고, 여러 모델을 비교하며, 응용 프로그램의 요구 사항에 따라 가장 적합한 모델과 임계값을 선택하는 데 유용한 시각적 도구를 제공합니다.
P-R Curve(Precision / Recall)
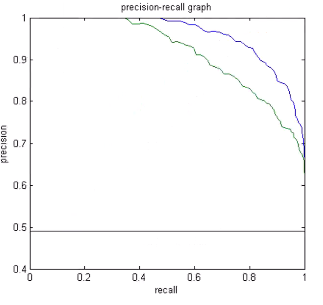
여기서는 반대로 아래 면적이 넓을 수록 좋으며 파란 곡선이 더 좋은 결과를 의미합니다.정밀도와 민감도가 둘다 높으면 높을수록 더 좋은 결과를 예측할 수 있습니다.PR 곡선은 주로 양성 클래스의 사례가 드물거나 불균형한 데이터셋에서 사용됩니다. 이 경우, 양성 클래스의 예측 성능을 더 세밀하게 분석할 필요가 있을 때 유용합니다.
PR 곡선 대 ROC 곡선
- 양성 클래스의 중요성: PR 곡선은 양성 클래스의 예측에 더 큰 중요성을 둡니다. 따라서 양성 사례가 드물거나 더 중요한 상황에서 더 유용할 수 있습니다.
- 데이터 불균형: 불균형한 데이터셋에서는 ROC 곡선이 모델의 성능을 과대평가할 수 있습니다. 이는 거짓 양성 비율이 낮은 비율로 유지되기 쉽기 때문입니다. 반면, PR 곡선은 불균형한 데이터셋에서 모델의 성능을 보다 정확하게 반영합니다.
- 모델 선택: 일반적으로, PR 곡선의 AUC가 높은 모델은 양성 클래스에 대해 더 높은 예측 능력을 가집니다. ROC 곡선의 AUC가 높은 모델은 전반적인 분류 성능이 우수합니다.
앙상블 러닝
앙상블 방법(Ensemble Method)은 여러 개별 모델(일반적으로 예측 모델이나 분류 모델)의 예측을 결합하여 단일 모델보다 더 정확한 예측을 목표로 하는 머신러닝 접근 방식입니다. 앙상블 학습의 기본 아이디어는 여러 모델의 결합이 개별 모델의 오류를 상쇄할 수 있어 전체적으로 더 강력하고 안정적인 예측 성능을 달성할 수 있다는 것입니다.앙상블 메서드의 대표적인 예로 Random forest가 있습니다.앙상블 메서드는 다수의 모델이 필요하며 같은 모델을 변형한 것일수도 있습니다. 이렇게 생성된 모델들 모두 최종 결과에 기여할 수 있습니다.따라서 결정 트리에서는 각각의 트리에 약간의 변형, 다른 임계값, 다른 훈련 데이터 모음을 이용해 생성하며 같은 문제에 대해 다수의 결정트리가 최종 결과에 영향을 미치게 됩니다.\
Bagging
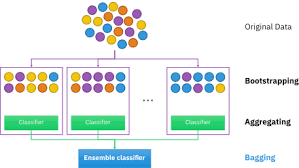
배깅(Bagging, Bootstrap Aggregating의 줄임말)은 앙상블 학습의 한 방법으로, 여러 개의 결정 트리와 같은 예측 모델을 병렬로 훈련시키고, 이들의 예측을 통합하여 전체적인 예측 성능을 향상시키는 기법입니다. 배깅은 특히 과적합(Overfitting)을 줄이고, 다양한 데이터를 적용하고 데이터의 작은 변화에 대한 모델의 안정성을 개선하는 데 효과적입니다.
그러기 위해선 무작위로 샘플링하고 교체해서 여러 훈련 세트를 만들고 다양한 모델에 적용시킵니다.
- 부트스트랩 샘플링: 훈련 데이터셋에서 복원 추출(하나의 샘플을 여러 번 선택할 수 있음)을 사용하여 여러 개의 부트스트랩 샘플을 생성합니다. 각 부트스트랩 샘플은 원래 데이터셋과 같은 크기를 가질 수 있지만, 일부 샘플은 중복되고 일부는 누락될 수 있습니다.
- 개별 모델 훈련: 각 부트스트랩 샘플에 대해 독립적으로 모델을 훈련시킵니다. 배깅에서는 같은 유형의 알고리즘을 사용하지만, 각각 다른 훈련 데이터 샘플을 사용하여 모델을 구축합니다. 일반적으로 결정 트리가 사용되지만, 다른 알고리즘도 적용 가능합니다.
- 결과의 통합: 모든 모델의 예측을 결합하여 최종 예측을 생성합니다. 회귀 문제의 경우, 이는 보통 모든 예측의 평균을 취함으로써 이루어집니다. 분류 문제의 경우, "투표" 방식을 사용하여 가장 많은 표를 받은 클래스를 최종 예측 결과로 선정합니다.
Boosting
Adaptive Boosting과 Gradient Boosting이 있습니다.여러 약한 학습기(Weak Learner)를 순차적으로 결합하여 강한 학습기(Strong Learner)를 만드는 앙상블 기법으로 개별 학습기의 성능이 매우 낮더라도 (예를 들어, 무작위 추측보다 약간 나은 수준) 여러 학습기를 적절히 조합함으로써 전체 모델의 예측 성능을 크게 향상시킬 수 있습니다.
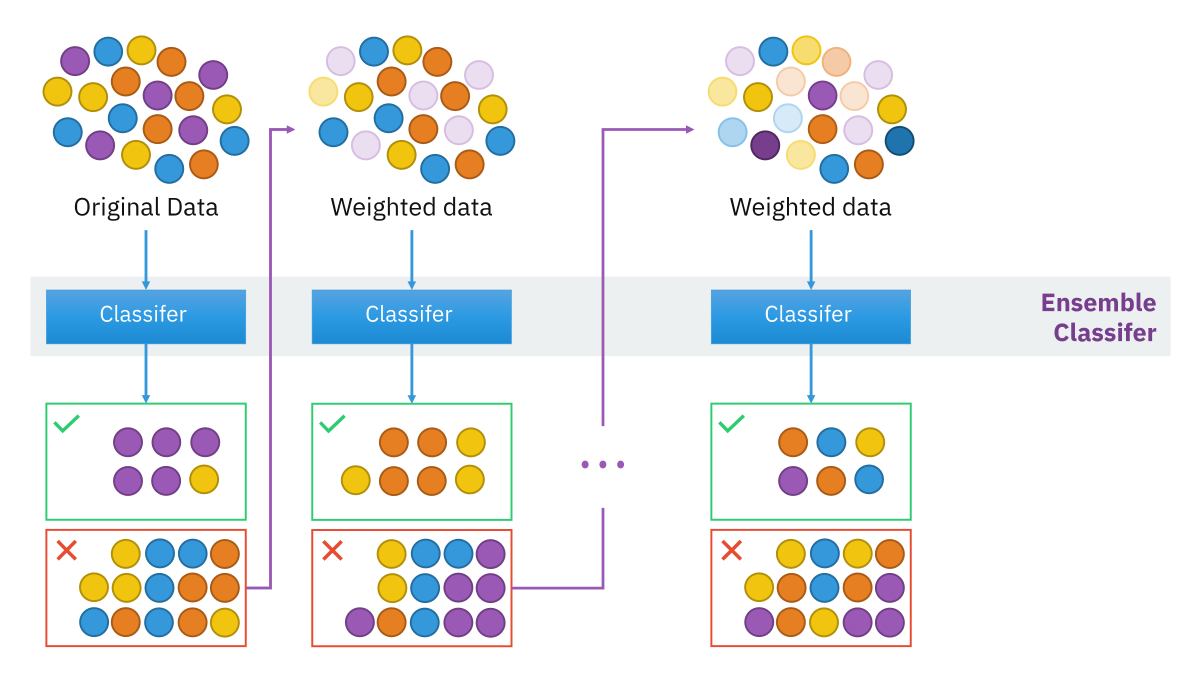
모든 데이터 포인트가 같은 가중치를 가지고 시작하여 처음 모델이 예측하면서 예측 결과로 얻은 데이터에 가중치가 부여되고 또 다음 모델에 영향을 주는 방식입니다. 이렇게 계속 학습하며 데이터에 가중치를 부여하며, 잘못 분류된 데이터에 집중하며 새로운 분류 규칙을 만드는 단계를 반복합니다.아래 이미지에서는 잘못 분류된 데이터들에 대해 가중치를 부여하고 있습니다.
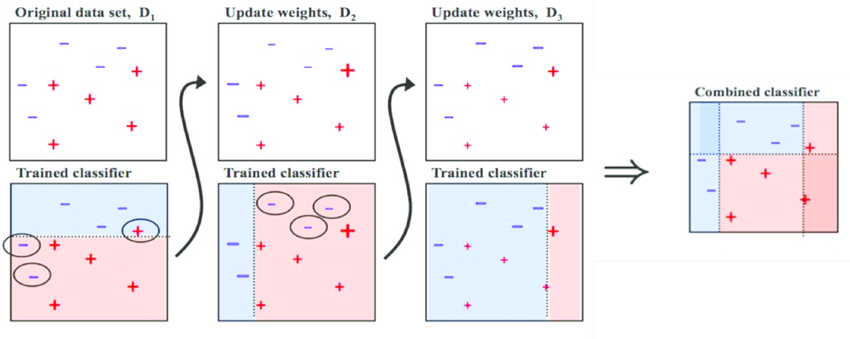
Bagging vs Boosting
- XGBoost가 현재 많이 사용되며 세이지메이커에서도 큰 비중을 차지하고 있습니다.
- 정확성을 중시한다면 Boosting이 효율적입니다.
- 과적합을 피하기 위해선 Bagging이 효율적입니다.
- Bagging은 병렬로 학습하여 속도가 더 빠르고 쉽게 병렬 처리를 할 수 있습니다.