[AI] vLLM 특징 및 구성 정리
vLLM을 활용해 효율적인 LLM 서빙 환경을 구축하는 과정과 핵심 기술을 정리했습니다. 메모리 최적화 원리를 살피고 실제 배포 시 발생한 이슈 해결 사례를 통해 안정적인 운영 노하우를 공유합니다.
개요
프로젝트에서 vLLM 기반의 환경 구축을 진행했습니다.
진행하는데 있어 구성했던 설정과 간단한 vLLM의 특징을 정리했습니다.
vLLM이란?
우선 vLLM은 빠르고 쉽게 LLM을 서빙 및 추론하기 위해 사용하는 라이브러리로 많이 사용됩니다. 빠르고 쉽게 처리하기 위한 핵심 특징이 존재하는데 정리하면 다음과 같습니다.
- Efficient management of attention key and value memory with PagedAttention
- Continuous batching of incoming requests
- Speculative decoding
- Chunked prefill
- …
외에도 양자화 등 다양한 옵션들이 있지만 핵심적인 내용 위주로 간단하게 정리했습니다.
1. PagedAttention
PagedAttention을 정리하려면 우선 KV Cache를 알아야합니다.
KVCache(KeyValue Cache)는 이전 토큰들의 Key/Value 값을 메모리에 저장해 중복 계산을 피하는 방식입니다. 하지만 KVCache는 단순 적용하기엔 문제가 있습니다.
문제는 시퀀스(하나의 생성 작업)마다 maxlength의 공간을 할당하는 것입니다. 만약 maxlength가 2048인데 실제 토큰은 500 토큰만 생성하더라도 2048의 공간을 점유하게 됩니다. 따라서 아래처럼 빈 공간(1024)을 활용할 수 없었습니다.
[요청A 2048][요청B 2048][ 빈공간(1024) ][요청C 2048]
vLLM은 위 문제를 PagedAttention으로 해결했습니다. PagedAttention은 가상 메모리의 페이징 기법으로 메모리에서 연속적인 공간을 할당해야하는 문제를 해결했습니다.
[AA][BB][AA][CC][BB][AA][CC][BB]
요청A → 블록 0, 2, 5
요청B → 블록 1, 4, 7
요청C → 블록 ...
메모리 공간의 낭비를 줄여 KVCache를 더 많이 사용할 수 있게함으로써 성능을 향상했습니다.
2. Continuous Batching
Continuous Batching은 기존의 Static Batching을 최적화한 방법입니다.
기존 Batch는 하나의 작업 단위(A,B,C)가 들어왔을 때 각각의 크기가 다르다면 가장 크기가 큰 작업단위가 끝날 때까지 다음 작업을 처리하지 못한다는 점이 있었습니다. Straggler, Head-of-Line Blocking으로 불리기도 하며 리소스를 더 사용할 수 있음에도 불구하고 작업이 지연되는 문제가 생깁니다.
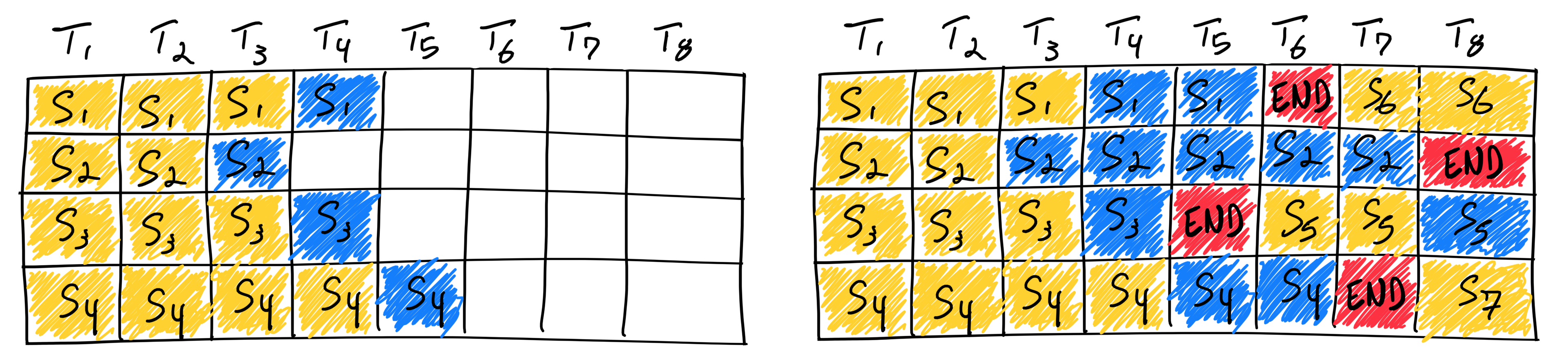
Continuous batching은 이를 해결한 방법으로 끝나는 자리에 즉시 새 요청을 삽입하여 GPU 유휴 시간을 최소화하고 처리량을 대폭 향상한 방식입니다.
3. Speculative Decoding
LLM은 추론시 토큰을 하나씩 순차적으로 생성하게 됩니다. 하지만 병렬처리가 가능한 GPU에서는 매우 비효율적인 방법으로 보입니다. Speculative Decoding은 이를 해결하기 위해 Draft라는 소형 모델을 사용합니다. 소형 모델이 빠르게 토큰을 생성하면 Target 모델인 대형 모델이 앞서 생성한 토큰을 한번에 검증(forward pass)하는 방식입니다.
맞는 토큰은 통과시키고 잘못된 토큰만 재생성하여 처리하는 방식입니다. 작은 모델로 빠르게 생성하고 큰 모델로 한 번의 forward pass로 병렬 검증하는 방식으로 토큰 생성 속도를 최적화했습니다.
4. Chunked prefill
LLM의 추론은 Prefill(입력 처리), Decode(토큰 생성) 방식으로 나뉩니다.
Prefill은 입력 토큰 전체를 처리하는 단계로 Self Attention 등을 수행하며 KVCache를 생성하고 병렬처리가 가능합니다. 하지만 Decode 단계는 토큰 하나씩 순차 생성하는 단계로 앞선 KV Cache를 재활용하며 필요한 값들을 빠르게 채워갑니다.
하지만 Continuous Batching 단계 중 한 번의 큰 Prefill이 들어오게되면 해당 연산을 처리하기위해 큰 Prefill이 GPU를 오래 점유하며 응답이 지연됩니다.
Chunked prefill은 이를 해결하기 위해 큰 요청을 Chunk단위로 나눠 처리하는 방식으로 큰 요청이 들어오더라도 다른 Decode와 인터리빙이 가능하게 합니다.
환경
- AWS g6e.xlarge(L40S 48GB VRAM)
- Deep Learning OSS Nvidia Driver AMI GPU PyTorch 2.7 (Ubuntu 22.04)
vllm serve Qwen/Qwen3-VL-8B-Instruct \
--host 0.0.0.0 \
--port 8000 \
--gpu-memory-utilization 0.9 \
--max-model-len 32768 \
--trust-remote-code \
--max-num-seqs 32 \
--enforce-eager
트러블 슈팅
1. 모델이 올라가지 않는 문제
이미지 처리가 빈번하다보니 Qwen3-VL-8B-Instruct 모델을 배포했습니다.
KV Cache 등 최적화 될 것이라 생각되어 65536의 크기를 두었는데 KV Cache는 모델이 초기 올라올 때 모델의 가중치와 함께 공간을 확보해놓는다는 것을 파악했고 max-model-len 을 줄였습니다.
ValueError: The model's max seq len (65536) is larger than the maximum number of tokens that can be stored in KV cache.
이를 통해 max-model-len과 utilization 설정이 중요하다는 것을 확인했습니다.
| 상황 | 결과 |
|---|---|
| utilization 너무 낮음 | 모델 가중치 로드 실패 → 시작 안 됨 |
| max-model-len 너무 높음 | KV 캐시 풀 확보 실패 → 시작 안 됨 |
| 둘 다 보수적 | 시작은 되지만 처리량 감소 |
2. VRAM Out of Memory 문제
VL 모델의 특성상 이미지 처리가 빈번했고 생각보다 큰 이미지가 들어오는 경우가 빈번했습니다. 이를 해결하기 위해 이미지의 최대 단위를 설정했지만 저해상도로 인한 성능 저하가 발생하여 고민했습니다.
여기서 --max-num-seqs를 통해 시퀀스 단위로 할당되는 피크 메모리(KV Cache)를 제어할 수 있다는 것을 확인했습니다. 32로 제어하여 약간의 속도는 포기하더라도 안정적인 운영과 성능을 보장할 수 있게 구성했습니다.